動的なデータを効率的に集計:pandasのpivot_tableとreindexの活用


この記事では、店舗ごとの「処分理由」を題材に、各店舗によって増減するデータをpandasの pivot_table を用いてカラムとして横並びにする方法を紹介します。また、reindex を用いることで歯抜けになった処分理由を保管しながら網羅性のあるデータ集計について知ることができます。
シチュエーション
あなたはある地域のエリアマネージャーをしています。担当エリアの店舗について各店舗で発生した商品の処分について理由ごとにいくら処分金額が発生しているかを横串で知り、店舗への指導材料として活用したいと考えています。
データベースには、以下のカラムを持つレコードが存在します:
-
disposal_id: 処分ID -
store_id: 店舗ID -
disposal_reason: 処分理由- ※規格化はされておらず店舗によってまちまちで、今後増減する可能性もある
-
disposal_amount: 処分金額
| disposal_id | store_id | disposal_reason | disposal_amount |
|---|---|---|---|
| 1 | 1 | REASON_A | 123 |
| 2 | 2 | REASON_A | 45 |
| 3 | 2 | REASON_A | 67 |
| 4 | 1 | REASON_B | 890 |
| .. | .. | .. | .. |
これをこんな感じにして見たいと考えています:
| store_id | REASON_A | ..B | ..C | ..D | .. |
|---|---|---|---|---|---|
| 1 | 123 | 890 | 0 | 0 | 0 |
| 2 | 112 | 0 | 0 | 0 | 0 |
| .. | 0 | 0 | 0 | 0 | 0 |
ここであなたは1つ困ったことに気付きました。処分理由が各店舗で統一されていればSQLのGROUP BY や CASE といった基本的な構文で比較的簡単に取得できるものの、不幸なことに店舗によって処分理由はまちまちであるため、たとえば「処分理由E」のような新しい理由が今後発生するかも知れません。その度に手を加えるのは骨が折れます。
解決策
幸いにもあなたはPythonが使えるしごできエリアマネージャーだったので、pandasデータフレームの pivot_table を使えばいけることに気付きました。
データベースから取得してきたという体で、代替としてdictからpandasデータフレームを用意します。
import pandas as pd
disposal_data = [{
'disposal_id': i,
'store_id': gen_store_id(),
'disposal_reason': gen_disposal_reason(),
'disposal_amount': gen_disposal_amount(),
} for i in range(all_store_id)]
disposal_df = pd.DataFrame(disposal_data)
`gen_disposal_reason` などのサンプルデータのための関数の詳細
import random
all_store_id = range(1, 10)
all_disposal_reason = ['賞味期限', '破損・汚損', 'シーズンオフ', '在庫過剰', '陳列スペース確保', '販売停止・回収命令']
def gen_store_id(start_num: int = 1, end_num: int = 9):
return random.randint(start_num, end_num)
def gen_disposal_reason():
return random.choice(all_disposal_reason)
def gen_disposal_amount(start_num: int = 1000, end_num: int = 9999):
return random.randint(start_num, end_num)
こんな感じでレコードがあることになります:

で、処分理由を横軸に置いて並べたい場合に pivot_table を使って実現することができます:
pivot = pd.pivot_table(
disposal_df,
values='disposal_amount',
index='store_id',
columns='disposal_reason',
aggfunc='sum',
fill_value=0
)
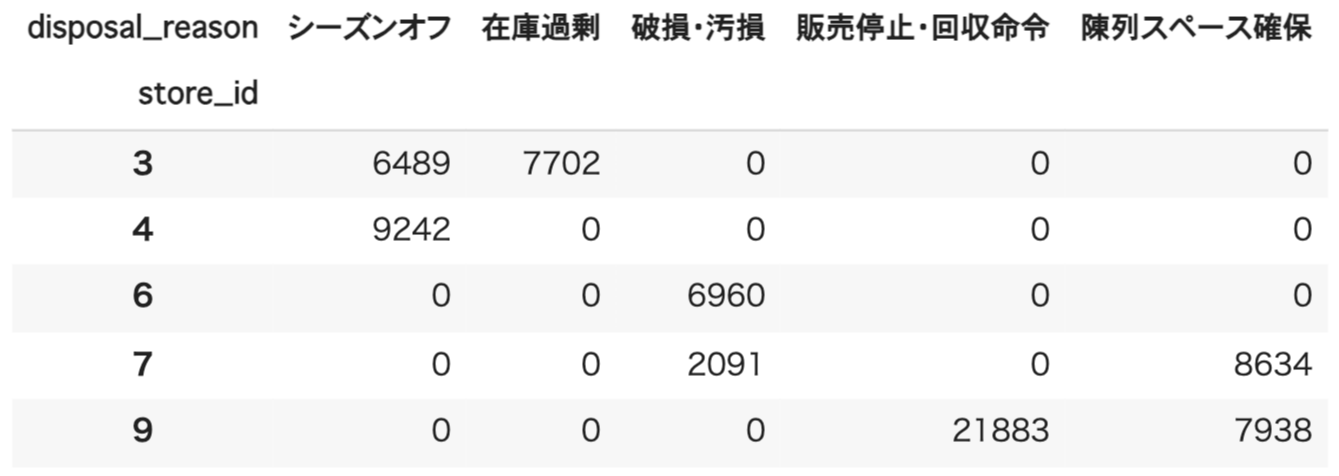
さらに、上のテーブルに対して処分の発生していない店舗や処分理由を網羅するためにre-indexを行うと、現在存在している店舗や処分理由のすべて確認することができるようになります(インデックスとは行や列を識別するための番号や文字列のラベルのこと):
pivot = pivot.reindex(
labels=pd.Series(all_store_id),
columns=all_disposal_reason,
fill_value=0
)
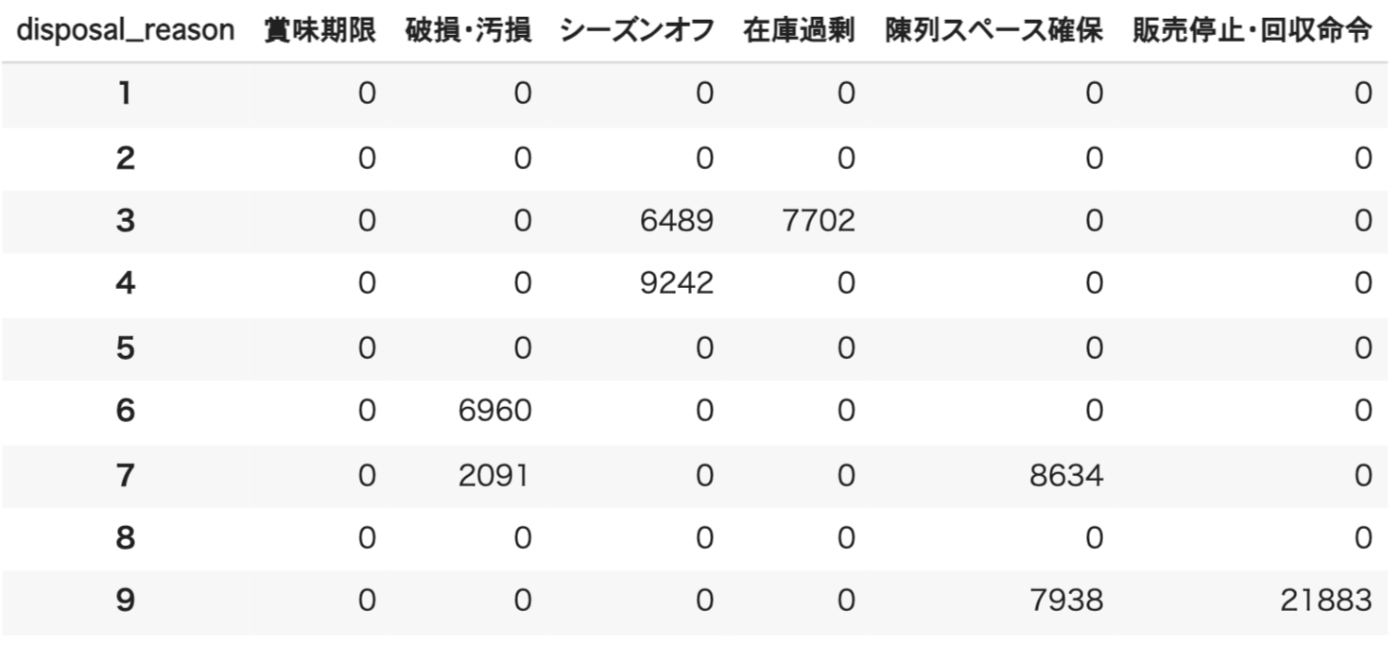
以上のような具合で、増減しうる特定の項目をカラムとして横並びにすることができました。「販売停止・回収命令」を理由に処分額がずば抜けて多い9番の店舗は災難でしたね(この物語はフィクションです)。
ちょっとでも参考になることがあればぜひLikeの方もお願いします!
また、colab上に今回紹介する実装を残しています。全体を確認したい場合はこちらをご確認ください:
Discussion