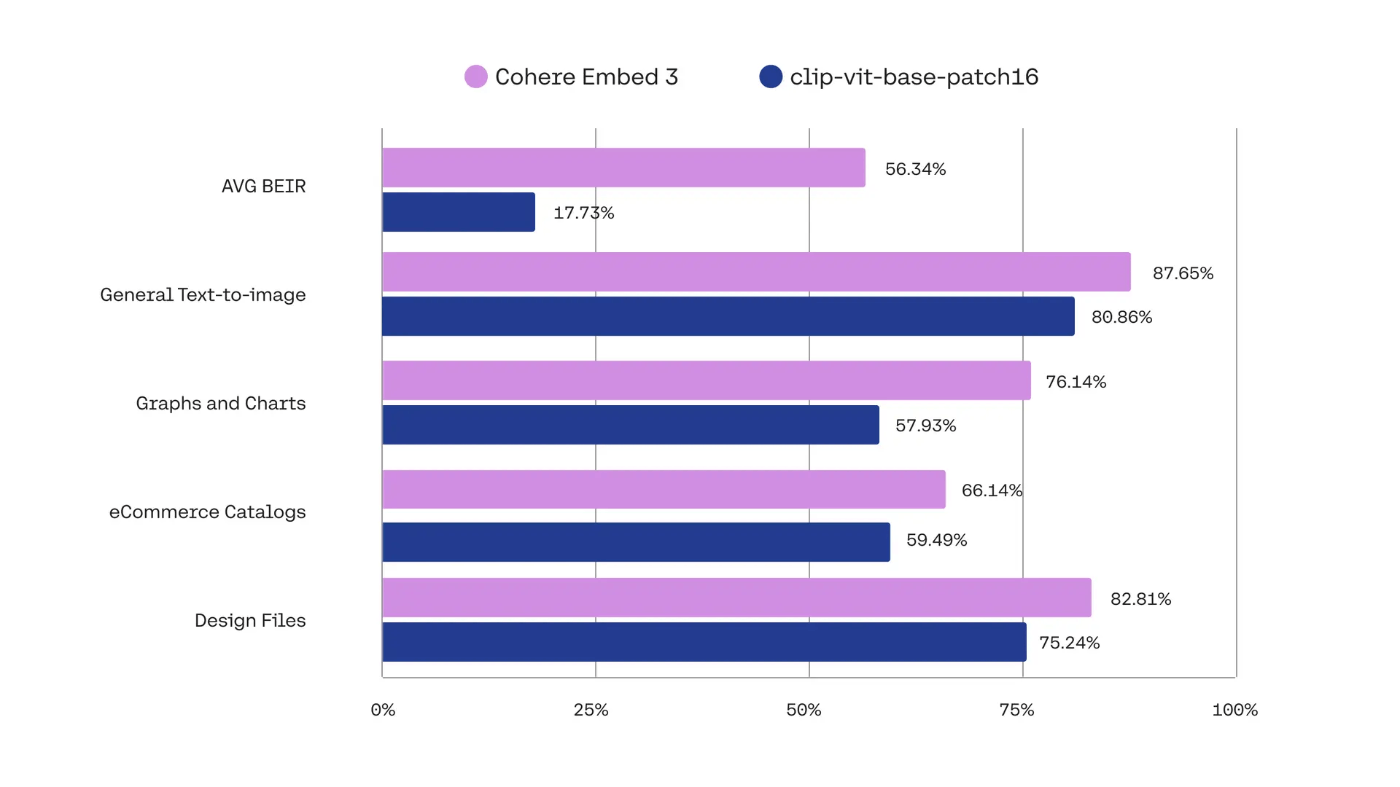
feature/rag
Late Chunking

これは何?
- Long-context embeddings を活用し、Long document に対してトークン数分の埋め込み表現を生成
- 各トークン表現を、平均プーリングによって適切なチャンク単位に集約
議論はある?
- 分割後に埋め込みを生成するアプローチに対して、周辺チャンクの依存関係を考慮できるそう

どうやって実現する?
from transformers import AutoModel, AutoTokenizer
model_name = "jinaai/jina-embeddings-v2-base-en"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, trust_remote_code=True)
TypeChunks = list[str]
TypeSpans = list[tuple[int, int]]
def chunk_by_sentences(text: str) -> tuple[TypeChunks, TypeSpans]:
"""
Input:
text (str): "<cls> / 我輩 / は / 猫 / で / ある / 。/ 名前 / は / まだ / ない / 。/ <sep>"
Returns:
chunks (TypeChunks): ["我輩は猫である。", "名前はまだない。"]
spans (TypeSpans): [(1, 7), (7, 12)]
"""
def late_chunking(
model_output: 'BatchEncoding', span_annotation: list, max_length=None
):
token_embeddings = model_output[0]
outputs = []
for embeddings, annotations in zip(token_embeddings, span_annotation):
if (
max_length is not None
): # remove annotations which go bejond the max-length of the model
annotations = [
(start, min(end, max_length - 1))
for (start, end) in annotations
if start < (max_length - 1)
]
pooled_embeddings = [
embeddings[start:end].sum(dim=0) / (end - start)
for start, end in annotations
if (end - start) >= 1
]
pooled_embeddings = [
embedding.detach().cpu().numpy() for embedding in pooled_embeddings
]
outputs.append(pooled_embeddings)
return outputs
こんな感じで実行
>>> inputs = tokenizer(input_text, return_tensors='pt')
>>> model_output = model(**inputs)
>>> embeddings_chunks = late_chunking(model_output, [span_annotations])[0]
>>> embeddings_chunks[0].shape
(768,)
参考
Matryoshka Embedding

これは何?
- 埋め込み表現をマトリョーシカ式に複数の次元数からなる埋め込み表現に truncate する
- 学習時は各個体(特定次元数を持つ埋め込み表現)の損失を算出して合計したものを最終損失値とする

Hayato Tsukagoshi氏 - [輪講資料] Matryoshka Representation Learning, https://speakerdeck.com/hpprc/lun-jiang-zi-liao-matryoshka-representation-learning?slide=7
議論はある?
- 通常の埋め込み表現と比べると、総じて各次元数での性能は一貫して良いらしい。
Disagreement across Dimensions
- ImageNet-1K ではクラスごとに次元数に対する性能変化の傾向が異なり、性能が単調増加するクラスもあれば、そうでないクラスも見られた。

This motivated us to leverage the disagreement as well as gradual improvement of accuracy at different representation sizes by training Matryoshka Representations.
- OpenAI の
text-embedding-3-largeが生成した1万件の埋め込み表現において、各次元ごとに標準偏差をプロットするとこんな感じになる。

どうやって実装するの?
ここでは OpenAI API を用いた推論部のみ
# -*- coding: utf_8 -*-
from concurrent.futures import ThreadPoolExecutor
import numpy as np
import numpy.typing as npt
from openai import OpenAI
def generate_embeddings(
batch_text: list[str],
model_name="text-embedding-3-large",
client: OpenAI = OpenAI(),
dimension: int = 3072
) -> npt.NDArray[np.float64]:
response = client.embeddings.create(
input=batch_text,
model=model_name,
dimensions=dimension
)
return np.array([data.embedding for data in response.data])
def generate_matryoshka_embeddings(
batch_text: list[str],
model_name="text-embedding-3-large",
client: OpenAI = OpenAI(),
dimensions: list[int] = [64, 128, 256, 512, 1024]
) -> dict[int, npt.NDArray[np.float64]]:
with ThreadPoolExecutor(max_workers=8) as executor:
futures = []
for dimension in dimensions:
futures.append(
executor.submit(
generate_embeddings,
batch_text,
model_name=model_name,
client=client,
dimension=dimension
)
)
matryoshka_embeddings = dict()
for future in futures:
result = future.result()
matryoshka_embeddings[result.shape[1]] = result
return matryoshka_embeddings
>>> batch_text = ["hello world"]
>>> client = OpenAI()
>>> dimensions = [64, 128, 256, 512, 1024]
>>> embeddings = generate_matryoshka_embeddings(batch_text, client=client, dimensions=dimensions)
>>> embeddings[64].shape
(1, 64)
参考
- https://huggingface.co/blog/matryoshka
- https://speakerdeck.com/hpprc/lun-jiang-zi-liao-matryoshka-representation-learning
- https://weaviate.io/blog/openais-matryoshka-embeddings-in-weaviate
- https://arxiv.org/abs/2205.13147
- https://sbert.net/examples/training/matryoshka/README.html#training!
- https://sbert.net/docs/package_reference/sentence_transformer/losses.html#matryoshkaloss
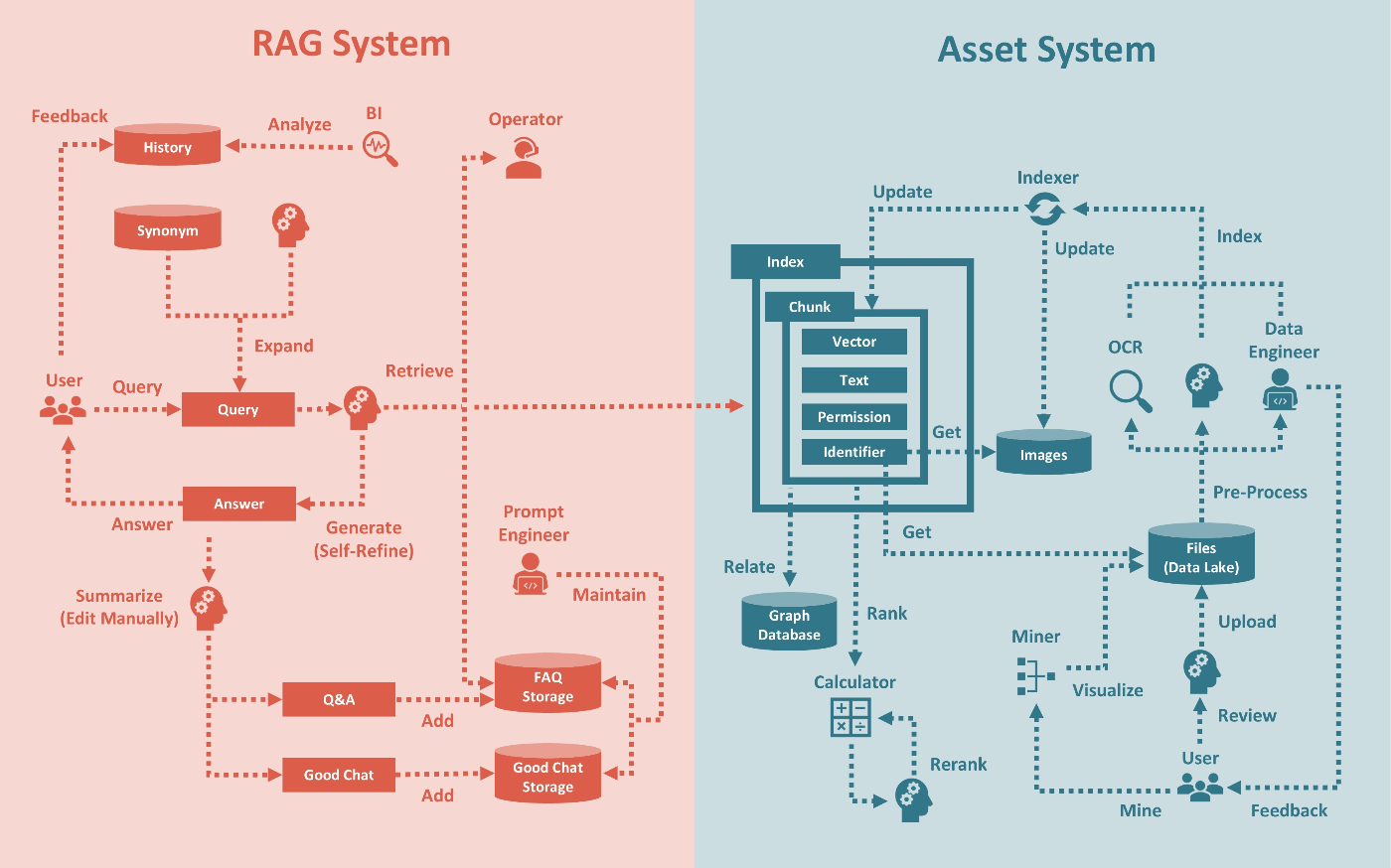
Rerank 3 Nimble
これは何?
- Cohere Rerank モデルシリーズの一つ、英語と多言語版がある
- 高い精度を維持しつつ 11.2 requests/sec と高速処理可能
- Amazon SageMaker およびオンプレミス展開でのみ利用可能
参考
BM42
これは何?
BM25

MrMo氏, [自然言語処理/NLP] Okapi BM25についてざっくりまとめ (理論編), https://dev.classmethod.jp/articles/mrmo-ml-20200422/
BM42
- BM25 の TF 項が文書全体の統計に依存しないため semantics 要素に置換
- 具体的には Transformer の注意機構における
[CLS]のアテンション行を見る - で、複数のアテンションヘッドの値を平均する
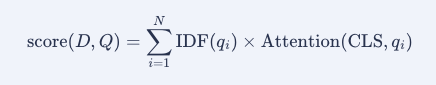
- サブワードに分割された単語は、単語内サブワードの注意重みを単純に合計する
議論はある?

参考
PyLate
これは何?
- Sentence Transformersの上に構築されたライブラリ
- 最新のColBERTモデルを用いたファインチューニング、推論、および検索を簡素化し最適化するために設計されている
参考
RAGHack
これは何?
- Microsoft による RAG 構築のイブストリーム
- Azure AI 上で RAG アプリを複数の言語(Python、Java、JS、C#)で、複数のリトリーバー(AI Search、PostgreSQL、Azure SQL、Cosmos DB)を使用して、独自のデータソースを用いて構築する方法を紹介
参考
Meta Knowledge Summary

これは何?
- 「検索して読む」から「準備して書き直し検索して読む」という代替アプローチを提案
- 文書からメタデータとQAペアを合成し、文書をクラスタリング。これらから Meta Knowledge Summaryを作成し、ユーザのクエリを MK Summary で拡張する
QAペアの合成
- 以下のプロンプトから Claude 3 Haiku を用いてメタデータと QA セットを生成
- 合成された QA は検索のみに使用される
あなたは科学者のためのアシスタントです。ユーザーからの質問が提供されます。
あなたの目標は、科学者が文献に質問を投げかけ、**それに答える準備をするための質問を生成する** ことです。
質問を生成するには、以下に提供されている [DatabaseSummary] のデータベース要約に頼ることができます。
戦略的な回答のために、**できるだけ多くの関連する質問を生成してください**(最大5つ)。
科学者は **これらの質問を使用して文献を検索する** ので、複雑な質問を少なく作るよりも、シンプルな質問を多く生成する方が望ましいです。
[ DatabaseSummary ]
{ mk_summary }
[/ DatabaseSummary ]
[ HumanQuery ]
{ user_query }
[/ HumanQuery ]
番号付きの質問のみで回答し、このフォーマットに厳密に従ってください。質問の前後に紹介文や結論文は不要です。
例:
1 …
2 …
3 …
…
N …
Meta Knowledge Summary の生成
- Claude 3 Sonnet を用いて、関心のあるメタデータでタグ付けされた一連の質問にわたる概念を要約する
参考
Large Language Models as Foundations for Next-Gen Dense Retrieval: A Comprehensive Empirical Assessment
これは何?
-
近年提案されている LLM を用いた埋め込み手法について、ドメイン内の精度、データ効率、ゼロショット一般化、長文検索、指示に基づく検索、およびマルチタスク学習を含む幅広い検索タスクについて包括的な実証研究を行った
-
LLM を用いた埋め込みについては、デコーダのみのアーキテクチャを含む LLM で、入力シーケンス内の最後のトークンのみがグローバルコンテキストにアクセスするものを指す。

-
より大きなモデルと長期間の事前学習が一貫してドメイン内の精度とデータ効率を向上させることを示し、LLMが高密度検索における多用途で効果的なバックボーンエンコーダーであるという利点を強調

参考
Ruri
これは何?
-
日本語に特化した汎用埋め込みモデル
-
以下によって学習
- LLMを用いた合成データセット作成
- 大規模な対照事前学習
- 高品質なラベル付きデータによる学習
-
塚越さん(名古屋大)が YANS2024 にて発表している
https://x.com/hpp_ricecake/status/1831310176009531703

どうやって使う?
import torch.nn.functional as F
from sentence_transformers import SentenceTransformer
QUERY_TEMPLATE = "クエリ: {query}"
PASSAGE_TEMPLATE = "文章: {passage}"
model_name = "cl-nagoya/ruri-large"
model = SentenceTransformer(model_name)
sentences = [
"クエリ: 瑠璃色はどんな色?",
"文章: 瑠璃色(るりいろ)は、紫みを帯びた濃い青。名は、半貴石の瑠璃(ラピスラズリ、英: lapis lazuli)による。JIS慣用色名では「こい紫みの青」(略号 dp-pB)と定義している[1][2]。",
"クエリ: ワシやタカのように、鋭いくちばしと爪を持った大型の鳥類を総称して「何類」というでしょう?",
"文章: ワシ、タカ、ハゲワシ、ハヤブサ、コンドル、フクロウが代表的である。これらの猛禽類はリンネ前後の時代(17~18世紀)には鷲類・鷹類・隼類及び梟類に分類された。ちなみにリンネは狩りをする鳥を単一の目(もく)にまとめ、vultur(コンドル、ハゲワシ)、falco(ワシ、タカ、ハヤブサなど)、strix(フクロウ)、lanius(モズ)の4属を含めている。",
]
embeddings = model.encode(sentences, convert_to_tensor=True)
similarities = F.cosine_similarity(embeddings.unsqueeze(0), embeddings.unsqueeze(1), dim=2)
参考
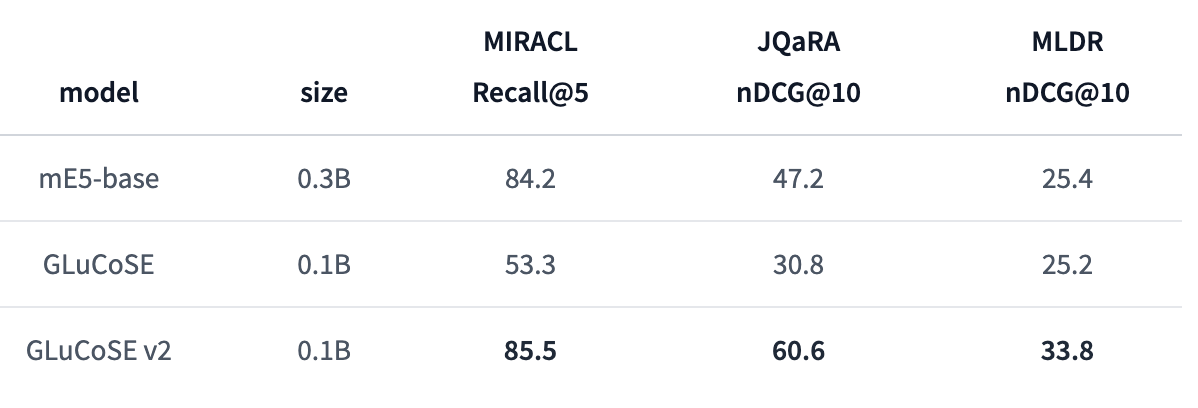
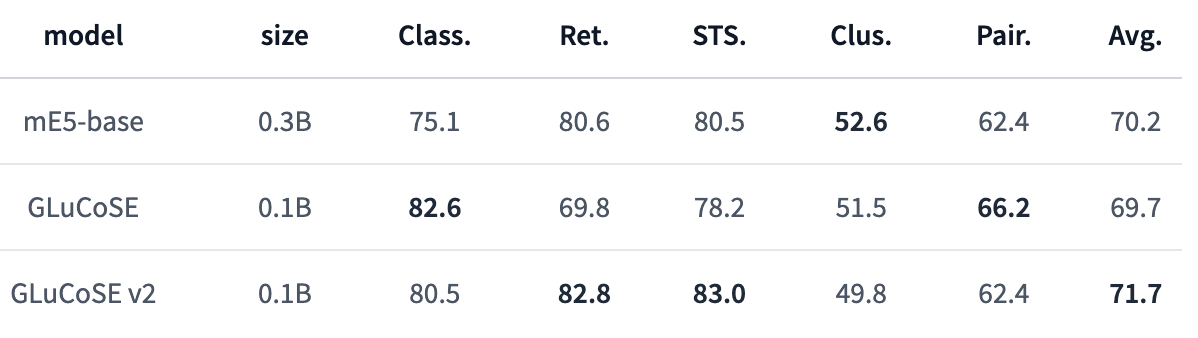
GLuCoSE v2
これは何?
- PKSHA社が開発した検索に特化した日本語文埋め込みモデル
- 知識蒸留 + 追加学習を行っている
Retrieval
JMTEB
どうやって使う?
from sentence_transformers import SentenceTransformer
QUERY_TEMPLATE = "query: {query}"
PASSAGE_TEMPLATE = "passage: {passage}"
model_name = "pkshatech/GLuCoSE-base-ja-v2"
model = SentenceTransformer(model_name)
sentences = [
'query: PKSHAはどんな会社ですか?'
'passage: 研究開発したアルゴリズムを、多くの企業のソフトウエア・オペレーションに導入しています。'
]
embeddings = model.encode(sentences)
similarities = F.cosine_similarity(embeddings.unsqueeze(0), embeddings.unsqueeze(1), dim=2)
参考
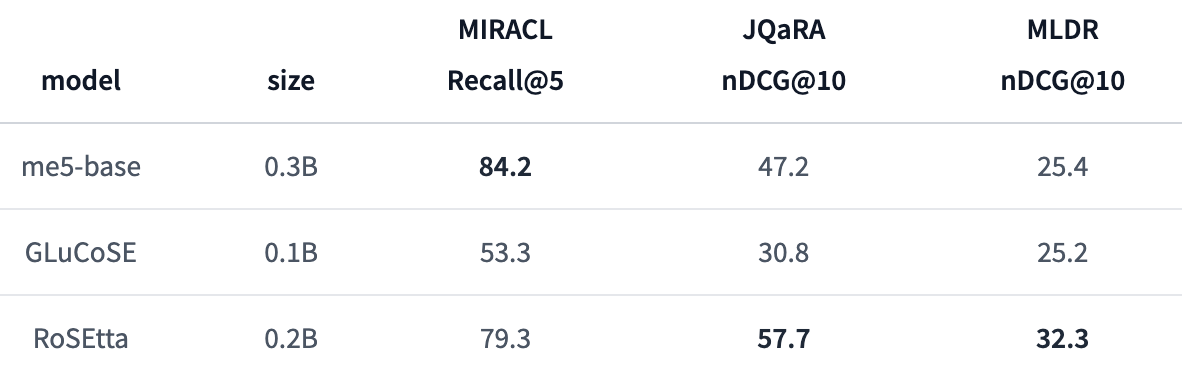
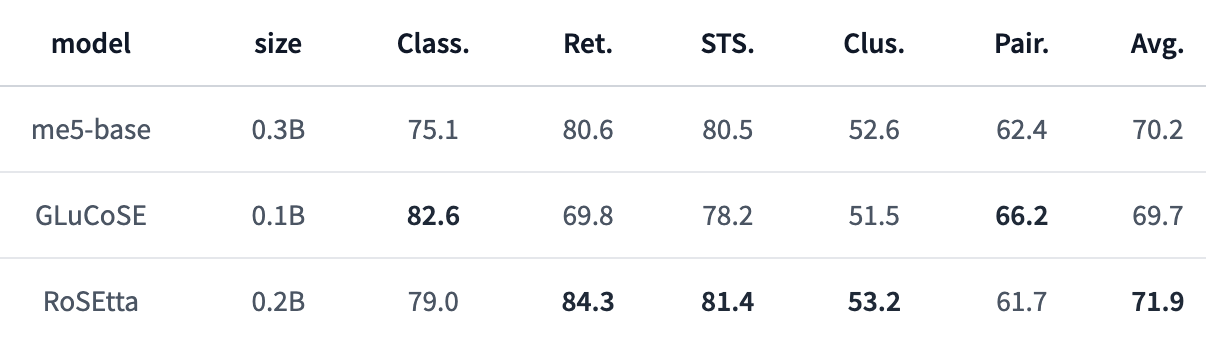
RoSEtta
これは何?
- PKSHA社が開発した長い入力系列に対応した日本語文埋め込みモデル
- 相対位置埋め込み「RoPE」を取り入れたBERT「RoFormer」に事前学習・事後学習を行い、最大1024トークンの系列を扱うことのできる日本語文埋め込みモデル
Retrieval
JMTEB
どうやって使う?
from sentence_transformers import SentenceTransformer
QUERY_TEMPLATE = "query: {query}"
PASSAGE_TEMPLATE = "passage: {passage}"
model_name = "pkshatech/RoSEtta-base"
model = SentenceTransformer(model_name)
sentences = [
'query: PKSHAはどんな会社ですか?'
'passage: 研究開発したアルゴリズムを、多くの企業のソフトウエア・オペレーションに導入しています。'
]
embeddings = model.encode(sentences)
similarities = F.cosine_similarity(embeddings.unsqueeze(0), embeddings.unsqueeze(1), dim=2)
参考
SPLADE Japanese v3
これは何?
- 日本語で学習された SPLADE モデル
MIRACL Japanese

JQaRA

どうやって使う?
from transformers import AutoModelForMaskedLM,AutoTokenizer
import torch
import numpy as np
model = AutoModelForMaskedLM.from_pretrained("aken12/splade-japanese-v3")
tokenizer = AutoTokenizer.from_pretrained("aken12/splade-japanese-v3")
vocab_dict = {v: k for k, v in tokenizer.get_vocab().items()}
def encode_query(query): ##query passsage maxlen: 32,180
query = tokenizer(query, return_tensors="pt")
output = model(**query, return_dict=True).logits
output, _ = torch.max(torch.log(1 + torch.relu(output)) * query['attention_mask'].unsqueeze(-1), dim=1)
return output
with torch.no_grad():
model_output = encode_query(query="筑波大学では何の研究が行われているか?")
reps = model_output
idx = torch.nonzero(reps[0], as_tuple=False)
dict_splade = {}
for i in idx:
token_value = reps[0][i[0]].item()
if token_value > 0:
token = vocab_dict[int(i[0])]
dict_splade[token] = float(token_value)
sorted_dict_splade = sorted(dict_splade.items(), key=lambda item: item[1], reverse=True)
for token, value in sorted_dict_splade:
print(token, value)
参考
NoiserBench
これは何?
- RAG ユースケースにおいて、7種類ノイズを付与したベンチマーク
- 論文では有害/有益なノイズの種類について調査