はじめに
株式会社スマートショッピングで SRE をしているbiosugar0です。
先日、2023 年 10 月 23 日に行われた Amazon Bedrock Prototyping Camp というイベントに参加してきました。
そこでは Bedrock の紹介から始まり、Claude のハンズオン、実際にプロダクト反映を目指したプロトタイピングを行うという内容でした。
今回はその中で検証、実装した社内用の Slack bot に弊社ヘルプページを参照させる事例を紹介します。
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG)は、LLM を用いた処理において、外部のデータベースや文書と連携してより精度の高い回答を生成するためのテクニックです。
GPT-4 のような LLM は、学習に使用されたデータセットに含まれる情報しか知りません。
そのため、ユーザーの質問に対して、モデルが知っている情報しか回答できません。
しかし、ユーザーが知りたい情報は、モデルが知っている情報に限られるわけではありません。
そこでよく使われるのが、Retrieval Augmented Generation (RAG)という手法です。
Retrieval Augmented Generation (RAG)は、自然言語処理において、検索と生成の両方の長所を組み合わせたアプローチです。
これにより、モデルは外部の知識ソースを利用して、より正確で豊かな回答を生成することができます。
以下は、今回利用した RAG のプロセスを説明するシーケンス図です。
先にユーザーの質問をそのまま検索コンポーネントに渡して検索を実行し、その結果を元に回答を生成するという方法もありますが、今回はユーザーの質問を元に LLM で検索クエリを生成し、検索コンポーネントに渡して検索を実行するという方法を取りました。
ユーザーの質問が必ずしもクエリとして適切とは限らないためです。
- ユーザーからの質問: ユーザーが LLM に質問をします。
- 検索コンポーネント: LLM は検索コンポーネントを使用して、質問に関連する文書や情報を外部のデータベースから検索し、検索結果を LLM に返します。
- 回答の生成: LLM は検索コンポーネントから返された検索結果と質問を元に、詳細な回答を生成します。
- ユーザーへの回答: 生成された回答はユーザーに返されます。
このプロセスにより、RAG は外部の知識を活用して、より正確で詳細な回答を生成することができます。
今回使用した具体的な構成にすると以下のようになります。
GPT-4 と Claude 2 の二つの異なる言語モデルと、Momento Vector Index という検索コンポーネントを組み合わせた構成で弊社のヘルプページを参照させることを目指しました。
利用したコンポーネント
具体的なアプローチを説明する前に、今回利用したコンポーネントとその用途を紹介します。
LlamaIndex
LlamaIndex は、カスタムデータソースを大規模言語モデルと連携することを支援する Python のフレームワークです。
API、データベース、PDF など様々なデータソースを LLM と連携させるための便利なツールとして利用できます。
このフレームワークを利用することで、独自データを活用した Q&A やチャットボットなどのアプリケーションを構築することが可能となります。
今回は ZendeskReader を利用することで Zendesk でホストされている弊社のヘルプページを LLM に渡すのに使用しました。
GPT-4
GPT-4 は、OpenAI が開発した言語モデルです。
大規模なデータセットを使用して学習されており、様々なタスクにおいて高い性能を発揮します。
特に gpt-4 API を用いると、Function Calling と言う機能を使うことができ、指定したデータ構造で gpt-4 から拡張機能をリクエストさせることができます。
今回はこの機能を利用して、ユーザーからの質問を受け取り、検索の実施を判断、検索コンポーネントにクエリを渡す役割を担いました。司令塔的な立ち位置です。
Momento Vector Index
Momento Vector Indexは、momento 社が開発したサーバレスなベクトルストアです。
ベクトル化したデータを保存し検索する検索コンポーネントとして利用しました。
サーバレスで面倒なセットアップが不要なので、簡単に検索コンポーネントを作成することができます。
保存対象のデータをベクトル化して保存しておき、検索時にはベクトル化したクエリを用いてベクトル間の距離を計算し、近い順にデータを返します。
これを利用することで、ユーザーからの質問に関連するドキュメントを検索し、LLM に渡すことができます。
Claude 2
Bedrock はいくつかの主要な基盤モデルをサポートしていますが、今回は Anthropic 社が開発した Claude 2 を使用しました。
このモデルは日本語が使え、GPT-4 に次ぐ能力を持つと言われているモデルです。
今回はこのモデルを利用して、ドキュメントの内容とユーザーからの質問を元に、より適切な回答を生成する役割を担いました。
Claude 2 は gpt-4 が 8k までの token を生成できるのに対し、100k までの token を生成することができます。
今回のイベントで聞いたのですがパソコンの取扱説明書 346 ページが 66000 文字で 59k token なので、大抵のドキュメントへの回答に利用することができます。
そのため、今回の RAG の構成では質問に関連するドキュメントを読ませて回答する役割を担います。
そして入力に関しては 1/6 ほどという GPT-4 よりも安い価格で利用することができます。(2023/10 月現在)
実装方法
それでは、実装した RAG のフローを紹介します。
事前準備: ヘルプページのドキュメントをベクトル化して保存する
以下は、弊社のヘルプページのドキュメントをベクトル化して保存する Python コードです。
langchain と LlamaIndex を使ってヘルプページのドキュメントをベクトル化して Momento Vector Index に保存します。
ドキュメントを取ってくる Loader は LlamaIndex に用意されている ZendeskReader を利用しています。
このような様々な Loader が使えるので便利ですね。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import MomentoVectorIndex
from llama_index import download_loader
zendesk_subdomain = "smartmat"
def load_index():
ZendeskReader = download_loader("ZendeskReader")
loader = ZendeskReader(zendesk_subdomain="smartmat", locale="ja")
# load data from Zendesk
docs = loader.load_langchain_documents()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=0,
)
documents = text_splitter.split_documents(docs)
be = OpenAIEmbeddings()
vector_db = MomentoVectorIndex.from_documents(
documents,
be,
index_name="zendesk_smartmat",
)
print(vector_db)
if __name__ == "__main__":
load_index()
保存を済ませたら、RAG のフローに移ります。
1. Slack との連携
Slack でユーザーからのメンションを受け取ります。
弊社では元々、OpenAI GPT-4 API を利用した TypeScript 製の Slack bot が運用されていました。
今回はこの Slack bot に機能を追加する形で、RAG を実装しました。
@slack/bolt という Slack アプリケーションフレームワークを利用しています。
詳細は本筋ではないので割愛します。
2. GPT-4 にメッセージを送信、ヘルプ検索をするか判断させる
今回の RAG のフローにおいて、まずユーザーからのメッセージを受け取るのは GPT-4 です。
GPT-4 は、ユーザーからのメッセージを受け取ると、ヘルプ検索をするかどうかを判断して自身でユーザーに返答するか、検索の指示を出します。
ヘルプ検索をする場合は、検索クエリを生成し、検索コンポーネントに渡します。
Function Calling
GPT-4 には、Function Calling という機能があり、GPT が必要と判断した場合にのみ、検索クエリを生成し、検索コンポーネントに渡すことができます。
まずは関数を定義します。この getSmartmatCloudHelp 関数は、ヘルプ検索をするための関数です。(この後中身を紹介します。)
const definedFunctions = [
{
name: "getSmartmatCloudHelp",
description:
"This function facilitates the retrieval of documentation and support materials for implementing and utilizing SmartMat Cloud(a.k.a SMC), an IoT-based inventory management service that automates and optimizes inventory tracking and operational efficiencies.",
parameters: {
type: "object",
properties: {
query: {
type: "string",
description:
"Search query for help page data, recommended in Japanese.",
},
},
required: ["query"],
},
},
];
type Function = {
[key: string]: (query: string) => Promise<any>;
};
const getSmartmatCloudHelp = async (query: string) => {
const index = "zendesk_smartmat";
// search query for help page data by Momento Vector Index
const response = await getDocument(index, query);
return response;
};
const functions: Function = { getSmartmatCloudHelp };
次に、gpt-4 が関数利用を判断するためのリクエストを送ります。messages にはユーザーからのメッセージが入ります。
const response = await openai.chat.completions.create({
model: "gpt-4",
messages,
function_call: "auto",
functions: definedFunctions, // 関数を定義したオブジェクト
stream: false,
temperature: 0.7,
});
gpt-4 が関数を利用すると判断した場合、関数名とその引数を含む JSON が返ってきます。以下のようにそれらを取り出し、関数を実行することができます。
const response = await openai.chat.completions.create(request1);
const msg_data = response.choices[0];
if (msg_data.finish_reason === "function_call") {
const fnName = msg_data.message.function_call?.name as string;
const argsstring = msg_data.message.function_call?.arguments as string;
const args = JSON.parse(argsstring);
const fn = functions[fnName];
if (!fn) throw new Error(`Function ${fnName} not defined`);
const documentResult = await fn(args.query);
console.log(documentResult);
}
ここではヘルプドキュメントを検索するために GetSmartmatCloudHelp 関数に query を渡して実行しています。
3. 検索コンポーネントに検索クエリを渡す
getSmartmatCloudHelp で実行している getDocument が検索コンポーネントに検索クエリを渡す関数です。
その実装は以下のようになっています。OpenAI の embeddingsAPI を使ってベクトル化した検索クエリを Momento Vector Index に渡して検索結果を取得します。
import {
PreviewVectorIndexClient,
VectorIndexConfigurations,
CredentialProvider,
ALL_VECTOR_METADATA,
VectorSearch,
} from "@gomomento/sdk";
import { OpenAIEmbeddings } from "langchain/embeddings/openai";
const embeddings = new OpenAIEmbeddings();
const momentoClient = new PreviewVectorIndexClient({
configuration: VectorIndexConfigurations.Laptop.latest(),
credentialProvider: CredentialProvider.fromEnvironmentVariable({
environmentVariableName: "MOMENTO_API_KEY",
}),
});
export const getDocument = async (index: string, query: string) => {
try {
const queryVector = await embeddings.embedQuery(query);
const searchResponse = await momentoClient.search(index, queryVector, {
topK: 3,
metadataFields: ALL_VECTOR_METADATA,
});
if (searchResponse instanceof VectorSearch.Success) {
return searchResponse.hits() || [];
} else {
throw new Error(`Unknown response type: ${searchResponse.toString()}`);
}
} catch (error) {
console.error(error);
throw error;
}
};
これでクエリに関連するドキュメントを取得することができました。
次に、この情報を使って Claude 2 に回答を生成させます。
4. 検索結果を Claude 2 に渡す
Claude 2 は Bedrock 経由で利用することができます。
Claude を利用する時に、OpenAI の gpt と使い方が違って手間取ったので、その点を紹介します。
Function Calling のような機能は今の所ない
最初、司令塔も Claude 2 にしようかと思って検証していたのですが、Function Calling のように定義した関数用のレスポンスを返すにはプロンプトエンジニアリングを頑張らないと行けないようで、今回は断念しました。
それか LangChain の agent を使えばできるかもしれませんが、実装をなるべくシンプルにしたかったので今回は使っていません。
Bedrock にも agent 機能が来るという話もあるので、その時にまた検証してみたいと思います。
プロンプトのフォーマットが結構違う
OpenAI の gpt の API リクエストは、以下のように role と content を指定する json のリストでプロンプトを指定します。
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
一方 Claude は、json ではなく、以下のような形式でプロンプトを記述します。
-
Human:Assistant:が必須 - 質問の終わりには改行を 2 つ
\n\n入れる
Human: こんにちは。
Assistant:
このように、Human と Assistant の行を交互に入力していきます。
プロンプトの最初の行は、Human: という文字列から始まる必要があります。
OpenAI の gpt API で Bot を実装していた時は、Slack 向けに応答メッセージのフォーマットを指定する以下のようなシステムプロンプトを使っていました。
1. 応答メッセージは以下のフォーマットに従って出力してください。
- bold: "*bold*"
- italic: "_italic_"
- strikethrough: "~strikethrough~"
- code: " \`code\` "
- block quote: "> block quite"
- code block: "\`\`\` code block \`\`\`"
- ordered list: "1. item1"
- bulleted list: "* item1"
- user: "<@user_id>"
- link: "<http://www.example.com|This message *is* a link>"
2. 文中のsingle quoteの前後には必ずスペースを入れてください。
- 例: word\`code\`word -> word \`code\` word
3. 適切な応答を返すために、追加の情報が必要な場合はなんでも質問してください。知らない場合は知らないですと答えてください。
このようなシステムプロンプトは、OpenAI の場合はリクエストのメッセージに"role":"system" の message を追加することで実現していました。
[
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "Who won the world series in 2020?" }
]
Claude の場合は Human: から始める必要があるので、以下のようにフォーマット指定を実現しました。Human と Assistant でルールの確認をしてから、質問を受け付けるようにしています。
また、Claude は XML タグを認識するようにトレーニングされているようなので、プロンプト内の構造を伝えるためにタグを使用しています。
Human: check your rule.
Assistant: <rule>
# Guideline:
[1] Precision: Thoroughly analyze the document to ensure the output content aligns accurately with the document's content.
- Avoid broad strokes, get into the details.
- Make sure the content relevance, correctness, and context.
[2] Title Inclusion: In case a URL is not provided, include the document's title in the response.
- Give users the context about what you're talking about.
[3] Natural Language Style: Craft responses using natural language styles.
- Avoid technical jargons and complex phrases.
- Use simple and common words to improve readability and comprehension.
[4] Helpful Response: As an assistant, strive to provide responses that are coherent and easy to comprehend.
- Avoid assumption or guesswork.
- Responses should be clear, concise, and correct.
[5] Language: Please use Japanese as the language for crafting responses.
- Ensure that terminology, phrases, and idioms make sense in Japanese.
[6] URL Inclusion: Always include the document's URL (taken from the 'medata.url' in the JSON) in the generated response.
- This is for traceability and easy future reference.
[7] Admitting Unawareness: If you're unsure about something, acknowledge it in your response.
<example1>
Human: text_1 について教えてください。
Human: <function_result>{"result":[{"id":"unique_id_1","distance":0.8285017013549805,"metadata":{"title":"title_1","url":"https://example_url.com/1","text":"text_1","updated_at":"2023-10-20T07:41:38Z","id":14491831242649}},{"id":"unique_id_
2","distance":0.8225529193878174,"metadata":{"title":"title_2","url":"https://example_url.com/2","updated_at":"2023-10-20T07:34:00Z","text":"text_2","id":14491908904345}},{"id":"unique_id_3","distance":0.8198807239532471,"metadata":{"title":"title_3","url":"https://example_url.com/3","text":"text_3","updated_at":"2023-04-11T04:51:56Z","id":14688433210521}}]}</function_result>
Assistant: はい。text_1 です。詳しくは <https://example_url.com/1> をご覧ください。
</example1>
<example2>
Human: text_4 について教えてください。
Human: <function_result>{"result":[{"id":"unique_id_1","distance":0.8285017013549805,"metadata":{"title":"title_1","url":"https://example_url.com/1","text":"text_1","updated_at":"2023-10-20T07:41:38Z","id":14491831242649}},{"id":"unique_id_2","distance":0.8225529193878174,"metadata":{"title":"title_2","url":"https://example_url.com/2","updated_at":"2023-10-20T07:34:00Z","text":"text_2","id":14491908904345}},{"id":"unique_id_3","distance":0.8198807239532471,"metadata":{"title":"title_3","url":"https://example_url.com/3","text":"text_3","updated_at":"2023-04-11T04:51:56Z","id":14688433210521}}]}</function_result>
Assistant: はい。その情報は見つかりませんでした。わかりません。
</example2>
</rule>
Human: OK. Let's continue the conversation.
このシステムプロンプトを先頭に、質問と関連するドキュメントを Human: で始まるように文字列結合して Claude に渡すプロンプトを作ります。
今回はプロンプトの元になるデータは OpenAI 用の構造を流用しているので、Claude 用に変換を行いました。
function buildClaudePrompt(messages: Message[]): string {
const prompt = messages.reduce((previous, current) => {
if (current.role === Role.System) {
return `${Anthropic.HUMAN_PROMPT} check your rule.
${Anthropic.AI_PROMPT} <rule>${documentReadPromptRule}</rule>
${Anthropic.HUMAN_PROMPT} OK. Let's continue the conversation.`;
}
if (current.role === Role.Function) {
return `${previous} ${Anthropic.HUMAN_PROMPT} <function_result>${current.content}</function_result>`;
}
if (current.role === Role.User) {
const userid = current.name ? `user=${current.name}: ` : "";
return `${previous} ${Anthropic.HUMAN_PROMPT} <>userid=${userid} ${current.name} ${current.content}</user>`;
}
if (current.role === Role.Assistant) {
if (current.function_call) {
return `${previous} ${Anthropic.AI_PROMPT} <function_call>
<function_name>${current.function_call.name}</function_name>
<function_arguments>${current.function_call.arguments}</function_arguments>
</function_call>`;
}
}
return `${previous} ${Anthropic.AI_PROMPT} ${current.content}`;
}, "");
return `${prompt} ${Anthropic.AI_PROMPT}`;
}
こうすることで、以下のように OpenAI 用のメッセージのリストを流用して Claude にリクエストを送ることができます。
async function invokeModelClaude(messages: Message[]): Promise<string> {
const prompt = buildClaudePrompt(messages);
const params: InvokeModelCommandInput = {
modelId: "anthropic.claude-v2",
contentType: "application/json",
accept: "*/*",
body: JSON.stringify({
prompt,
anthropic_version: "bedrock-2023-05-31",
temperature: 0.7,
max_tokens_to_sample: 2000,
}),
};
const response = await bedrockClient.send(new InvokeModelCommand(params));
const result = JSON.parse(new TextDecoder().decode(response.body));
return result.completion.trim();
}
これでドキュメントに沿った回答を取得することができました。
確認
実装した bot を実際に動かしてみると、ヘルプページの内容を見て回答を生成してくれます。
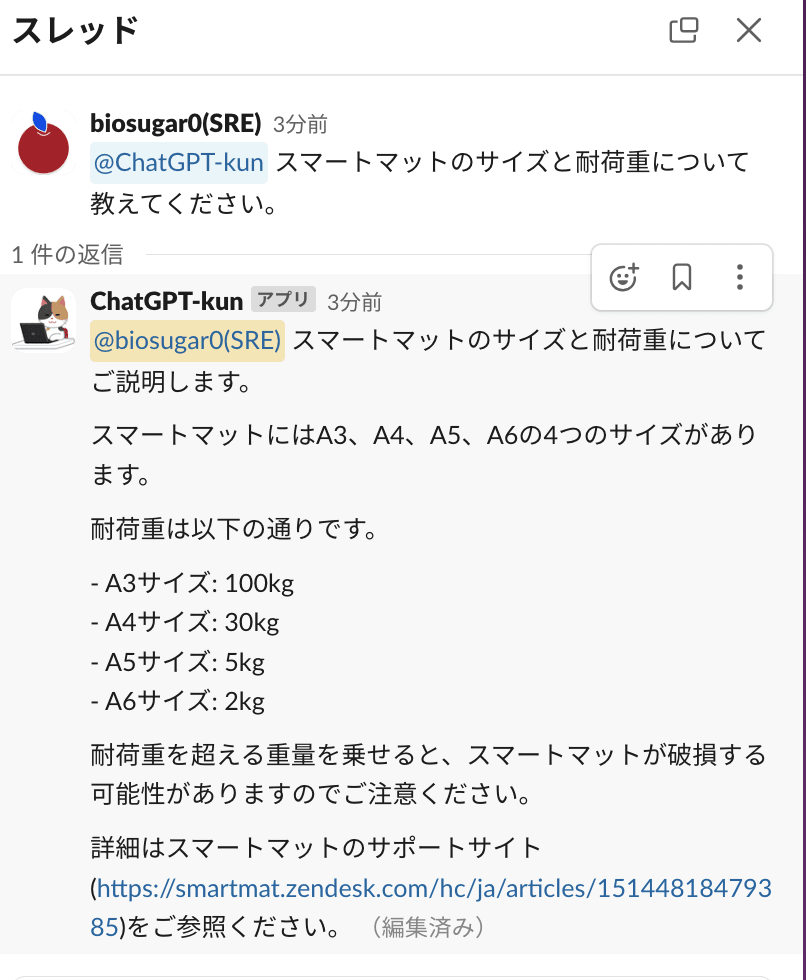
リンクのヘルプページも確認してみましょう。

正しい回答になっていますね!
Amazon Bedrock Prototyping Camp はサポートを受けながら Bedrock を使って実装に取り組むことができるいいイベントでした。
他の参加者はまた別の実装に取り組んでいたと思うので、参加者の他の事例もブログになるといいなと思っています。皆さんが何に Bedrock を使うのか気になります。

IoT重量計スマートマットを活用した在庫管理・発注自動化DXソリューション「SmartMat Cloud」を運営しています。一緒に働く仲間を募集しています。 s-mat.co.jp/recruit
Discussion