はじめに
こんにちは、株式会社スマートショッピング エンジニアのhi6okuniです。
フロントエンドエンジニアとして主にReactを用いた開発に従事してきましたが、この半年間は幸運にも自社のバックエンドをGoで開発する機会に恵まれました。Goらしいコードを書く技術も日々学習中ですが、最近ではデータ構造そのものにも興味が湧いてきました。そこで今回、GoのMapの内部構造がどのように作られているのかを深堀りしてみることにしました。主な焦点はruntime/map.goのmapassign関数の解析になります。

ざっくり理解
始めにruntime/map.goファイルのMapのコメントを読んでみましょう。データ構造/仕組みが記載されています。
A map is just a hash table. The data is arranged into an array of buckets. Each bucket contains up to 8 key/elem pairs. The low-order bits of the hash are used to select a bucket. Each bucket contains a few high-order bits of each hash to distinguish the entries within a single bucket. If more than 8 keys hash to a bucket, we chain on extra buckets.
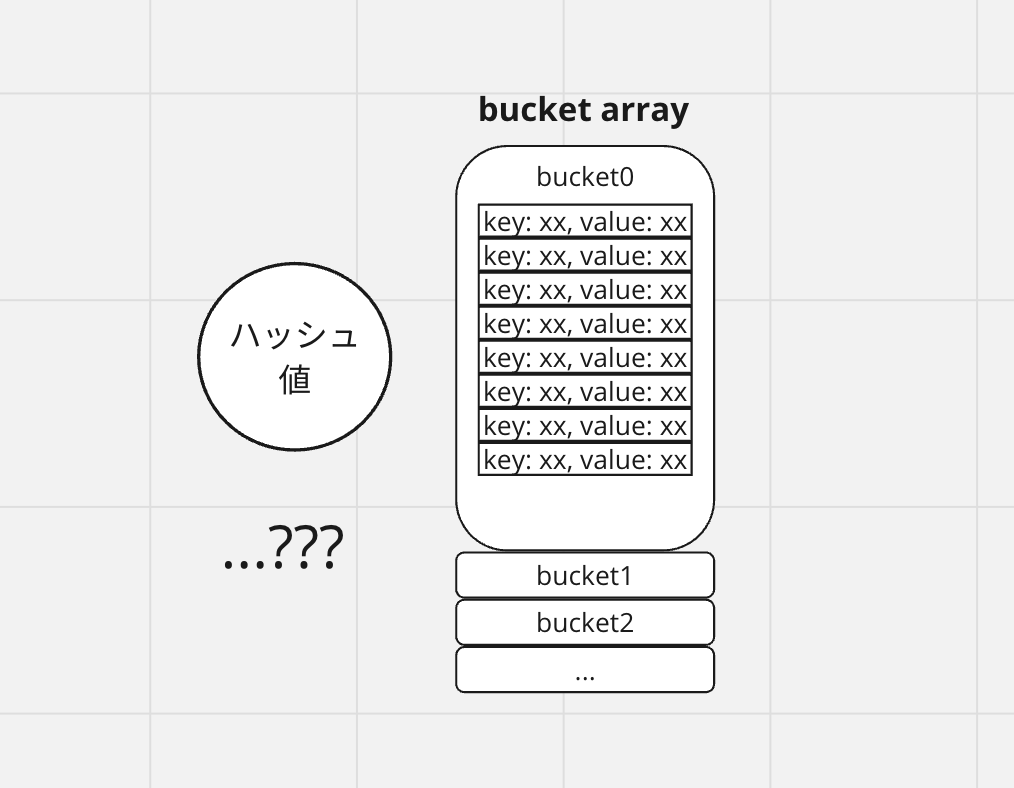
- Mapのデータ構造はハッシュテーブルである
- データはバケットの配列に格納される
- 1つのバケットには最大で8つのkey/valueのペア(以降、本記事内ではkey/valueのペアのことを「スロット」と表記します)が含まれる
- ハッシュ値の下位ビットは、どのバケットを選択するかを決定するために使用される
- ハッシュ値の上位ビットは、同じバケット内の各スロットを区別するために使用される
- もし8つ以上のキーが同じバケットに格納された場合、追加のバケットをチェーン(連鎖)させる
基本的にはkeyをハッシュ化して格納するバケットを選択するハッシュテーブルが採用されているようです。過不足なくデータ構造の説明がされてはいますが、こちらの説明だけで完璧にMapの構造を理解するのは難しいのではないでしょうか。
これからランタイム時の関数の挙動を詳細に追って仕組みを確認していきましょう。
GoのMap宣言の背後で起こること:hmapの解析
まず、make関数を使ってMapを宣言してみましょう。
m := make(map[string]int) // mの型は map[string]int と表示される
宣言されたmは実際にはMapの何を指しているんでしょうか?
make関数を利用してMapを宣言すると、ランタイム時にmakemap関数が呼び出されます。
func makemap(t *maptype, hint int, h *hmap) *hmap
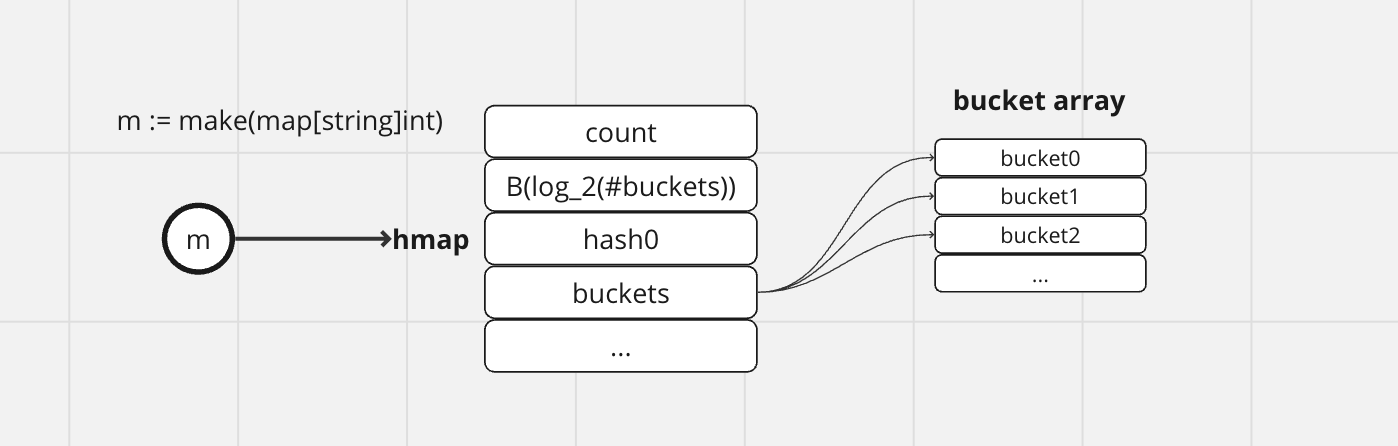
makemap関数の返り値を見ると、見慣れないhmapのポインタが返却されていることが分かります。hmapの中身は以下の通りで、宣言したMapに関わるmetaデータが詰まったstructとなっています。
// A header for a Go map.
type hmap struct {
count int
flags uint8
B uint8 // バケット数の log_2(loadFactor * 2^B までのアイテムを格納できる)
noverflow uint16 // オーバーフローバケットのおおよその数
hash0 uint32 // ハッシュのシード値
buckets unsafe.Pointer // 2^B のバケットの配列
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}
普段のコーディング時にhmapを意識する必要はありませんが、mは自分自身のmetaデータが入ったruntime.hmap構造体のポインタであることが分かりました。
Mapへの書き込み:内部処理のステップバイステップ解析
次にMapにkey/valueをアサインする時に内部でどのような処理が行われているか順を追って見てみましょう。
mのMapに対して、key: "J.K. Rowling"、 value: 1965をアサインすることを想定しましょう。
m["J.K. Rowling"] = 1965
ランタイム時にはvalueを収めるメモリ位置を見つけて返すruntime.mapassign関数が呼び出されます。
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
先に関数の全体像を記載して、ポイントごとに解説を加えていきます。
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
/* 解説する部分だけ抽出しており、一部省略/単純化しています */
// Point1: ハッシュ値の生成
hash := t.Hasher(key, uintptr(h.hash0))
// Point2: 格納するバケットの選択
bucket := hash & bucketMask(h.B)
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
// Point3: tophashの生成
top := tophash(hash)
// Point4: tophashを利用して書き込むべきメモリ位置を特定
var inserti *uint8
var insertk unsafe.Pointer
var elem unsafe.Pointer
for {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if !t.Key.Equal(key, k) {
continue
}
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
return elem
}
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// Point5: 新しいバケットの追加とチェーン
if inserti == nil {
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.KeySize))
}
if t.IndirectKey() {
kmem := newobject(t.Key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.IndirectElem() {
vmem := newobject(t.Elem)
*(*unsafe.Pointer)(elem) = vmem
}
typedmemmove(t.Key, insertk, key)
*inserti = top
h.count++
return elem
}
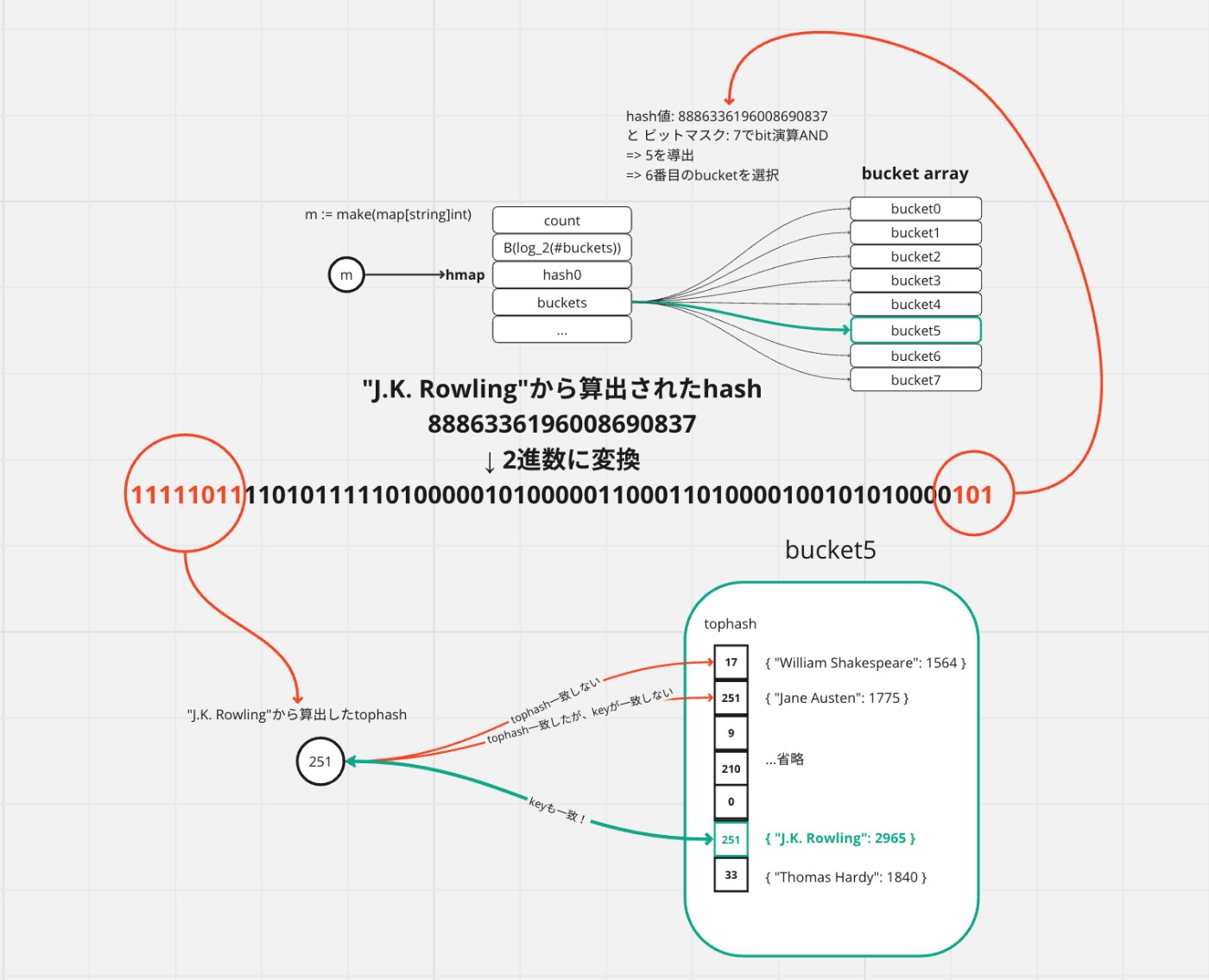
Point1: ハッシュ値の生成
// 初期化時に生成されたhash seedを含んでkeyをハッシュ化
// ex. "J.K. Rowling"というkeyから8886336196008690837を生成
hash := t.Hasher(key, uintptr(h.hash0))
hmapが保持しているhash seed hash0を含めて、keyからハッシュ値を生成します。GoのMapはハッシュテーブルであるため、生成されたハッシュ値がバケット配列のどのバケットを選択するか決定する要素となります。 また、このハッシュ値はhash0は生成されたMap毎にユニークな値であるので、同じkeyでも生成されるハッシュ値は異なります。
マップの内部実装で使われるハッシュアルゴリズムは、Goランタイム内で独自に管理されていますが、maphash packageとしてGoのMapが使用するハッシュアルゴリズムに基づいたハッシュ関数は外部に提供されています。
Point2: 格納するバケットの選択
// bucketMask returns 1<<b - 1, optimized for code generation.
func bucketMask(b uint8) uintptr {
return bucketShift(b) - 1
}
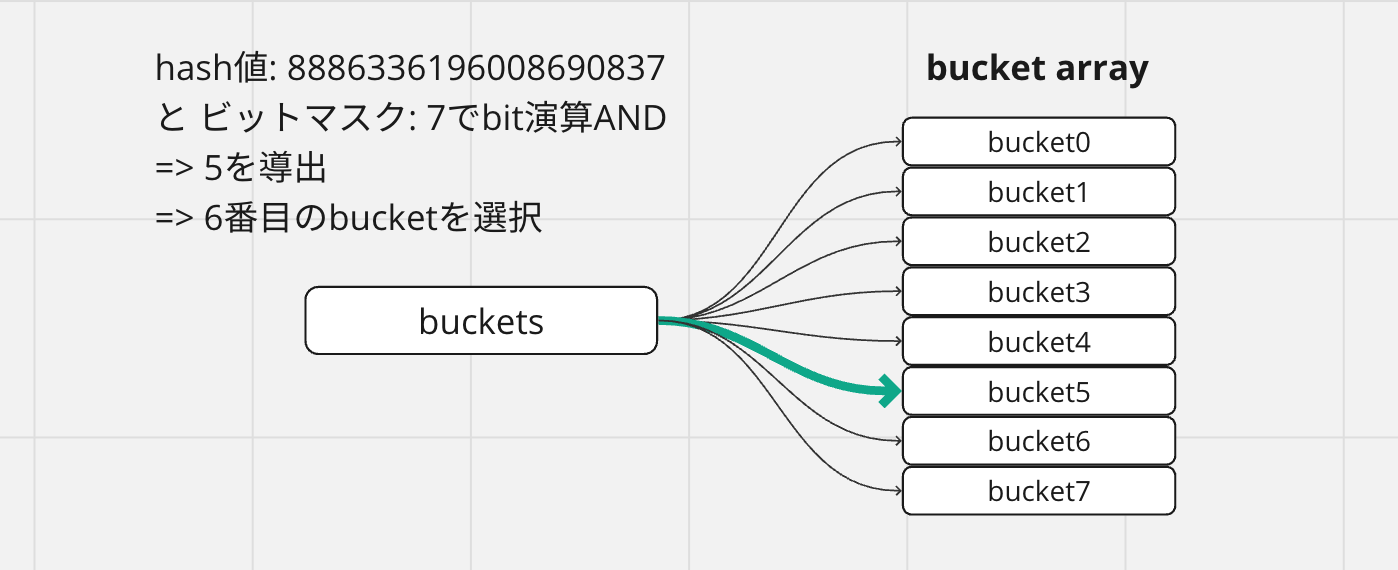
// bit演算 ANDで格納するべきバケットを見つける
// >>> 8886336196008690837 & 7
// >>> 1111101111010111110100000101000001100011010000100101010000101 & 111
// >>> 5 (6番目のバケット)
bucket := hash & bucketMask(h.B)
// バケットを格納するためのメモリの先頭アドレスから、オフセットを加えて、指定のバケットに対応するメモリアドレスを入手。
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
次に生成したハッシュ値とビットマスクを利用して、格納するバケットを決定します。
バケット数が8の場合、hmapのBは3(2^3)なので、生成されるビットマスクは111です。この111とハッシュ値でANDビット演算することで、ハッシュ値の下位3ビットを抽出し(2進数で000 ~ 111, 10進数で0~7)選択されるバケット番号とします。今回の例では5が導出され、6番目のバケットが選択されたこととなり、そのバケットのメモリ位置はオフセットを加えて見つけています。
Point3: tophashの生成
// 1つのバケットに格納されているkey/valueのペア数(この記事内ではスロット数と呼ぶ)
const bucketCnt = abi.MapBucketCount // 8で固定されていると考えて良い
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
}
// ハッシュの先頭8ビットを利用する
// >>> 8886336196008690837
// >>> 1111101111010111110100000101000001100011010000100101010000101
// >>> first byte: 11111011
// >>> top hash: int(11111011) = 251
top := tophash(hash)
対象のバケットが決まったので、あとはバケットの中の該当スロットを見つける作業となりますが、この部分でも一工夫があります。不一致keyを高速に排除するために直接サイズの大きなkeyを比較するのではなく、ハッシュ値のビット先頭8桁から生成されるtophashという値を比較に利用します。 今回の例では251が導き出されました。
ちなみに0~4は特殊なtophash値として予約されているので、keyから算出されるtophashは常に5以上になるように調整されます。
// Possible tophash values. We reserve a few possibilities for special marks.
// Each bucket (including its overflow buckets, if any) will have either all or none of its
// entries in the evacuated* states (except during the evacuate() method, which only happens
// during map writes and thus no one else can observe the map during that time).
emptyRest = 0 // this cell is empty, and there are no more non-empty cells at higher indexes or overflows.
emptyOne = 1 // this cell is empty
evacuatedX = 2 // key/elem is valid. Entry has been evacuated to first half of larger table.
evacuatedY = 3 // same as above, but evacuated to second half of larger table.
evacuatedEmpty = 4 // cell is empty, bucket is evacuated.
minTopHash = 5 // minimum tophash for a normal filled cell.
Point4: tophashを利用して書き込むべきメモリ位置を特定
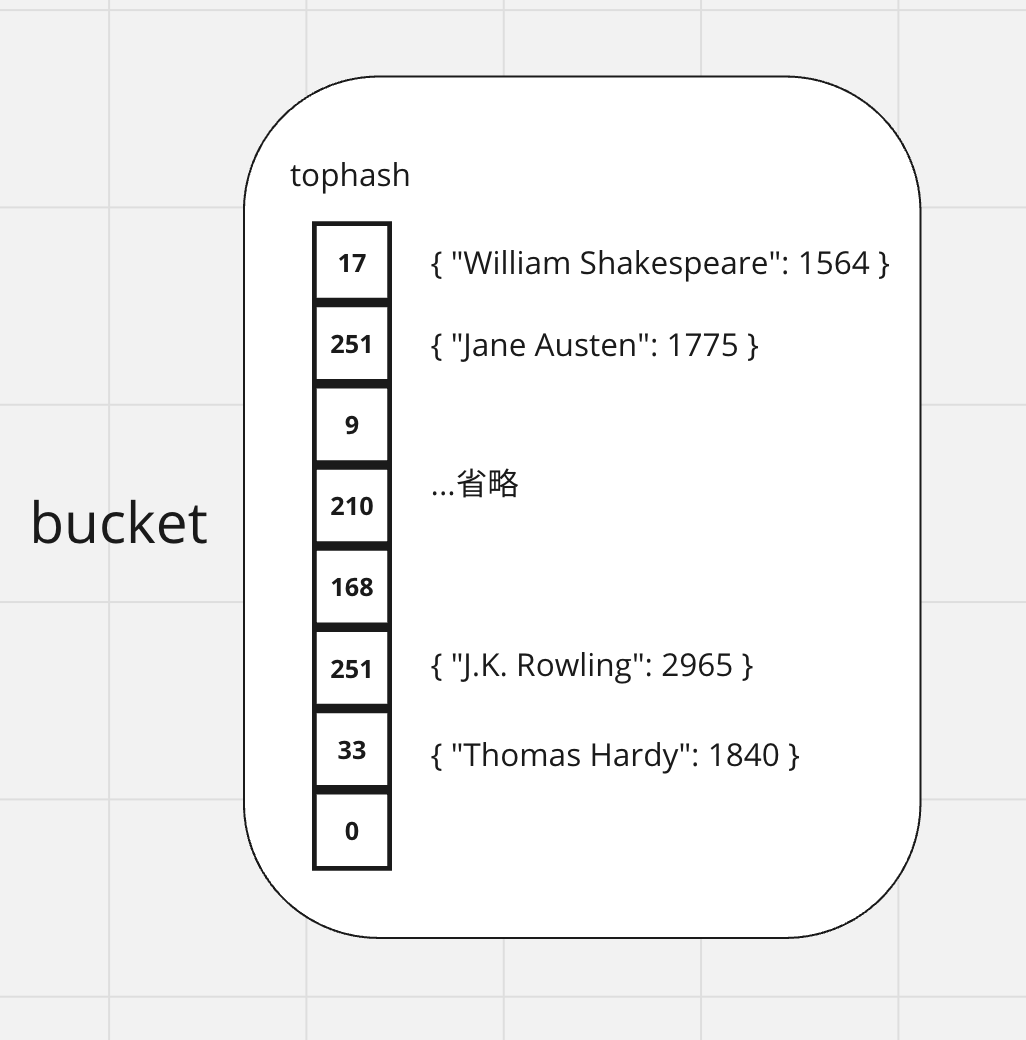
スロット数(=8個)分for文を回して、算出したtophashとバケット内のtophashを比較し、ようやくvalueを書き込むべきメモリ位置の特定に至ります。
- tophashが一致した場合、key本体を比較して、key本体も一致する場合はすでに存在しているkeyだと分かるのでアップデートされるべきvalueのメモリ位置を返却します。
- 最後までkeyが一致しない場合は新規のkeyであると分かるので、新しいvalueを収めるべきメモリ位置を返却します。
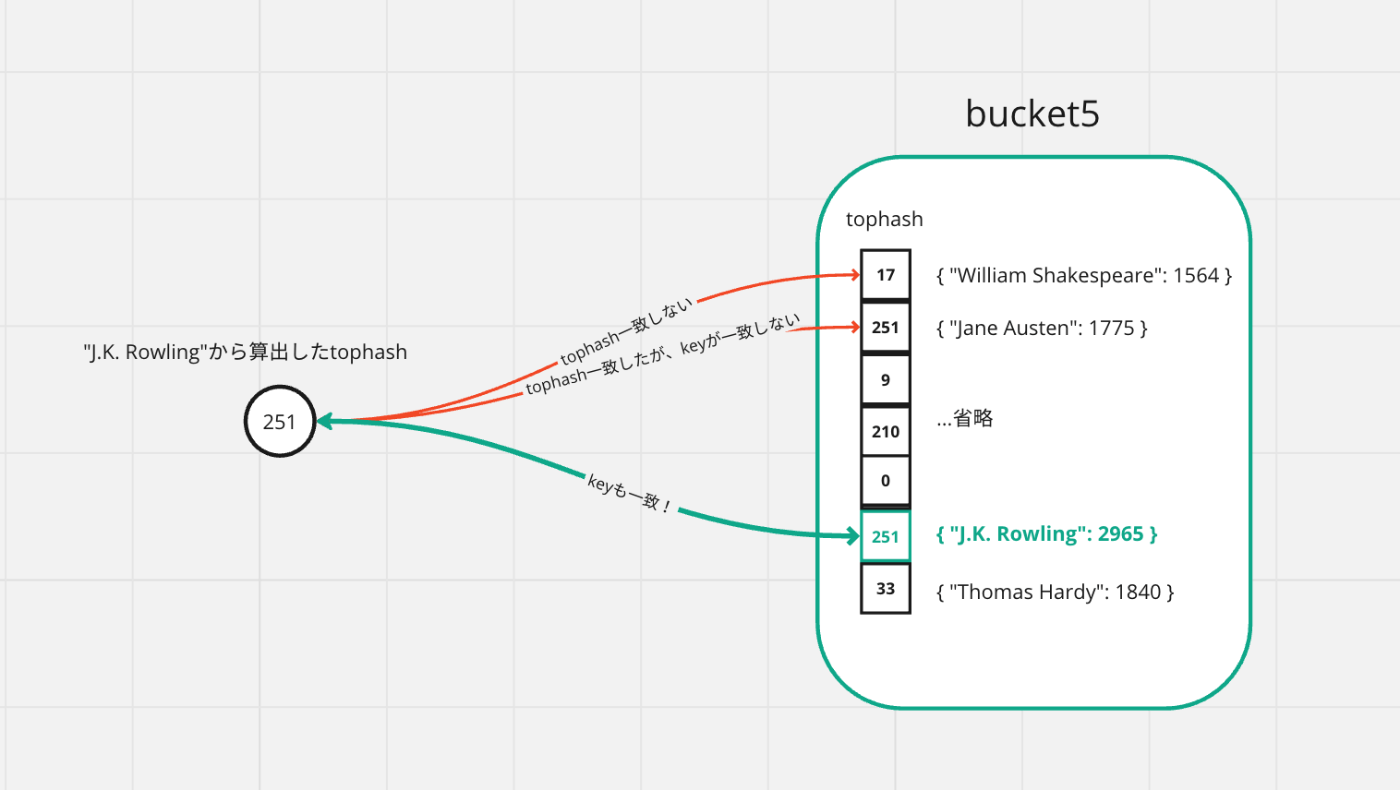
画像の例では、5番目のバケットの中を探索し、6番目のスロットにすでに"J.K. Rowling"のkeyが存在していたので、このスロットのvalueが収められているメモリ位置を返却することになります。
for i := uintptr(0); i < bucketCnt; i++ {
// tophashが一致しなければ次のtophashへ
if b.tophash[i] != top {
continue
}
// tophashが既存のtophashと一致した場合
// keyを取得
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
// tophashが一致しただけでkeyは異なっている場合は次のtophashへ
if !t.Key.Equal(key, k) {
continue
}
// kとkeyが一致したので、更新対象のvalueを収めるメモリ位置を取得して返却
elem = add(undafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
return elem
}
// Point5: 新しいバケットの追加とチェーン 部分を省略
// 既存のkeyが一致しなかった場合は、新規でkey/valueをinsert
// 新規でvalueを収めたメモリ位置を取得して返却
// hmapのカウントもプラス1
if t.IndirectKey() {
kmem := newobject(t.Key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.IndirectElem() {
vmem := newobject(t.Elem)
*(*unsafe.Pointer)(elem) = vmem
}
typedmemmove(t.Key, insertk, key)
*inserti = top
h.count++
return elem
Point5: 新しいバケットの追加とチェーン
if inserti == nil {
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.KeySize))
}
選択されたバケットの8スロットが全て埋まっている場合は、9個目のスロットを作るのではなく、もう1つバケットを新設します。8スロットが全て埋まっているバケット内にオーバーフローとして新設されたバケットのメモリアドレスを保持します。オーバーフローの繋がり方はいわゆるLinked Listのチェーン構造となっているため、オーバーフローの連鎖は計算量をO(n)に近づけ、パフォーマンス悪化の原因となります。
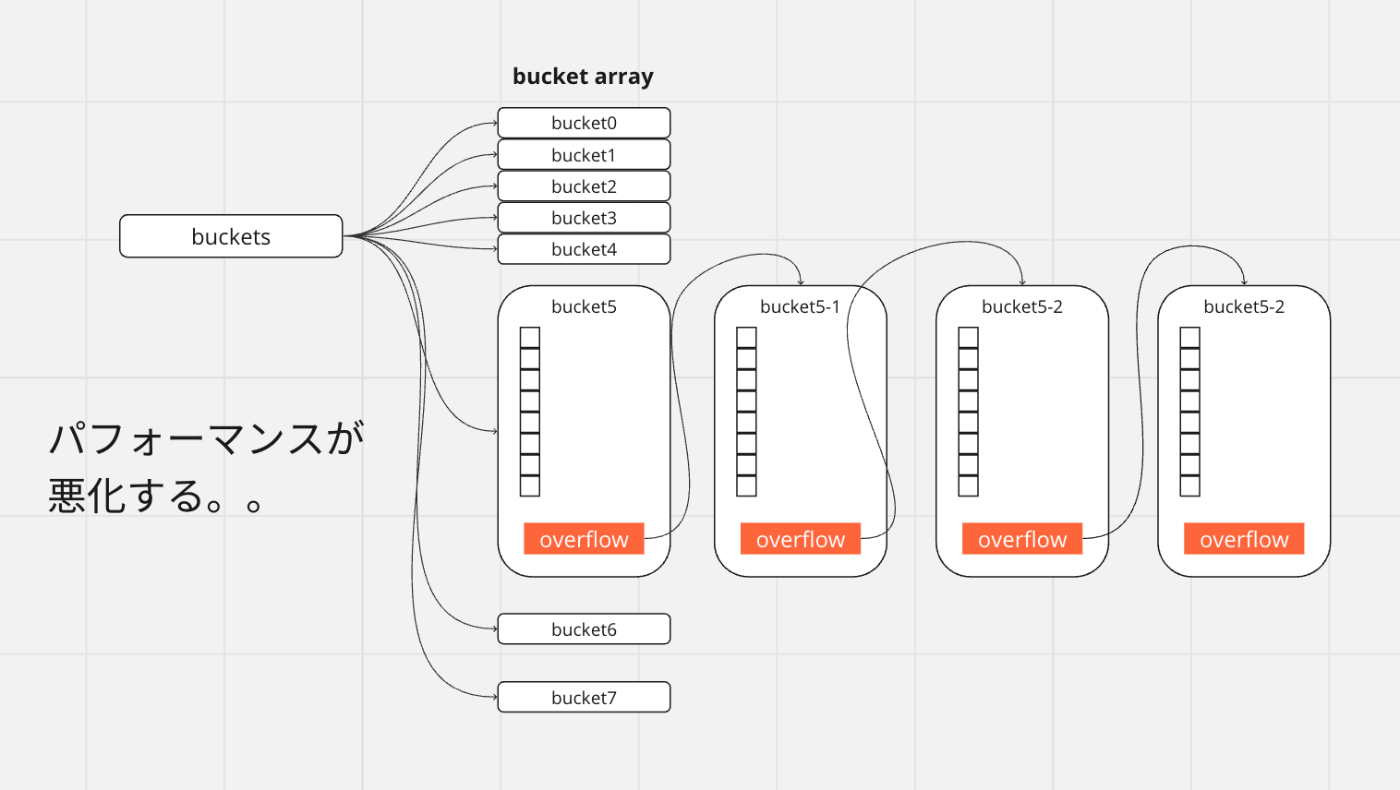
おさらい
前述の解説を通じて、Go言語のMapの内部動作についての理解を深めました。ここで改めてruntime/map.goのMapのコメントを読んでみましょう。アサインの過程をさらったことでより意味を捉えやすくなったのではないでしょうか?
- Mapのデータ構造はハッシュテーブルである
- データはバケットの配列に格納される。
- 1つのバケットには最大で8つのkey/valueのペアが含まれる。
- ハッシュ値の下位ビットは、どのバケットを選択するかを決定するために使用される。(Point2に該当)
- ハッシュ値の上位ビットは、同じバケット内の各スロットを区別するために使用される。(Point3に該当)
- もし8つ以上のキーが同じバケットに格納された場合、追加のバケットをチェーン(連鎖)させる。(Point5に該当)
アサインの過程をトレースしましたが、keyへのアクセス過程でも類似のプロセスをたどります。主な違いは、一致するkeyが見つからない場合、アサインでは新規に書き込むのに対し、アクセス時にはその型のゼロ値が返されます。
Mapの拡大タイミングとその判定条件
1つのバケット内のスロットは8個で固定ですが、バケット数自体は良きタイミングで拡大しなければ困ります。バケット数が一定のままでは、データ数の増加に応じてオーバーフローの連鎖を繋げることでしか対応ができずパフォーマンスの悪化を招きます。
以下がMapの拡大判定部分です。
overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)
- まずバケットの中のスロットの埋まり具合をチェックします。
Maximum average load of a bucket that triggers growth is bucketCnt*13/16 (about 80% full)
Goでは1バケットの中のスロットが平均で約80%埋まった状態(6.5個スロットが埋まった状態)になると、バケット数を2倍に拡張するトリガーが発火します。
- 次にオーバーフローのバケット数をチェックします。
// tooManyOverflowBuckets reports whether noverflow buckets is too many for a map with 1<<B buckets.
// Note that most of these overflow buckets must be in sparse use;
// if use was dense, then we'd have already triggered regular map growth.
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
// If the threshold is too low, we do extraneous work.
// If the threshold is too high, maps that grow and shrink can hold on to lots of unused memory.
// "too many" means (approximately) as many overflow buckets as regular buckets.
// See incrnoverflow for more details.
if B > 15 {
B = 15
}
// The compiler doesn't see here that B < 16; mask B to generate shorter shift code.
return noverflow >= uint16(1)<<(B&15)
}
Bが16未満の場合は、2^B個が閾値となります。バケット数が8の時(Bが3)、オーバーフローのバケット数の閾値も8個となります。
最後に
個人的にはPoint2: 格納するバケットの選択のビットマスクの部分でO(1)の、Point5: 新しいバケットの追加とチェーンの部分でO(n)のイメージが具体的につくようになったのが収穫でした。生成されたハッシュ値のバイナリの先頭と末尾が別々に活用されていることも新しく知ることができました。
もし本記事が皆さんのGoのMapに関する内部構造への理解を一歩でも前に進める手助けとなれば幸いです。
参考にしたリソース
- https://go.dev/src/runtime/map.go
- 📝 How the Go runtime implements maps efficiently (without generics) by Dave Cheney
- 📝 If a map isn’t a reference variable, what is it? by Dave Cheney
- 📝 Some insights on Maps in Golang by Aleksandr Kochetkov
- 🎥 Internals of Maps in Golang by Sreekanth

IoT重量計スマートマットを活用した在庫管理・発注自動化DXソリューション「SmartMat Cloud」を運営しています。一緒に働く仲間を募集しています。 s-mat.co.jp/recruit
Discussion