スマートラウンドでエンジニアをやっている福本です!
2/4(火)に開催された、以下の『AIエージェントについてまとめてみた』のイベントに参加してきたので、その個人的な勉強メモを公開します📓
公式のアーカイブが残されているので、こちらに貼っておきます👇️
また、当日のXのタイムラインはこちらです🐦
イベント内容
発表資料が以下で公開されていますので、該当箇所を適宜抜粋しながらメモを記載します👇️
こちらと合わせて見て頂けると理解が深まると思います。
YOJOで稼働するAIエージェント

PharmaXさんのYOJOプロダクトでは、薬剤師の業務を代替するAIエージェントを開発・運用している。具体的な実装では、以下のような業務を自動化している👇️
チャットでの患者対応の80%程度をAIエージェントが処理
- 基本的な質問応答は全てAIが対応
- 複雑な判断が必要な場合のみ薬剤師に確認
- 添付文書に基づく回答で安全性を担保
漢方薬の選択や提案も自動化
- 患者の症状や体質に基づく最適な漢方薬の選定
- 飲み合わせの判断
- 継続使用時の効果確認と提案
継続的な健康相談や服薬確認も自動実行
- 定期的な体調確認メッセージの送信
- 服薬状況の確認
- 症状の変化に応じた提案
これらの業務は、実装されたワークフローに従って実行される。各ステップでの処理内容や分岐条件が明確に定義されており、以下のような流れで処理が行われている👇️
- メッセージ受信時のルールベース分類
- 対応カテゴリーの判定
- 薬剤師確認の要否判定
- メッセージ生成
- 評価・チェック
- 送信
AIエージェントとは

- 情報の認識とアクションを継続的にループさせながら動作するシステム
- 人間があまり手を加えなくても自動的に作業を実行できる
- 時折人間に確認を取ることはあるが、基本的には自律的に動作する
- ユーザー目線では「ほぼ放っておいても結果を出してくれる」という特徴を持つ
現状の解釈の違い
- ユーザー目線:自動で動作して結果が出れば「自律的」と捉える
- 開発者目線:裏側でルールやワークフローが定義されているため、真の意味での自律性はないと考える
「完全自律型」の定義
- 必要な情報収集を自身で判断できる
- アクションの決定を自律的に行える
- プログラムの自己改変も可能
- 新しい動作パターンを自身で獲得できる
Agentic WorkflowとAIエージェントの定義

Agentic Workflow
- LLMの組み合わせをデザインし、目的とする処理系を作り上げる仕組み
- 人による対応や承認を途中で挟むことができる
- ワークフローを組むこのようなパターンをエージェントと呼ぶべきかという議論が存在する
AIエージェントの3つの型
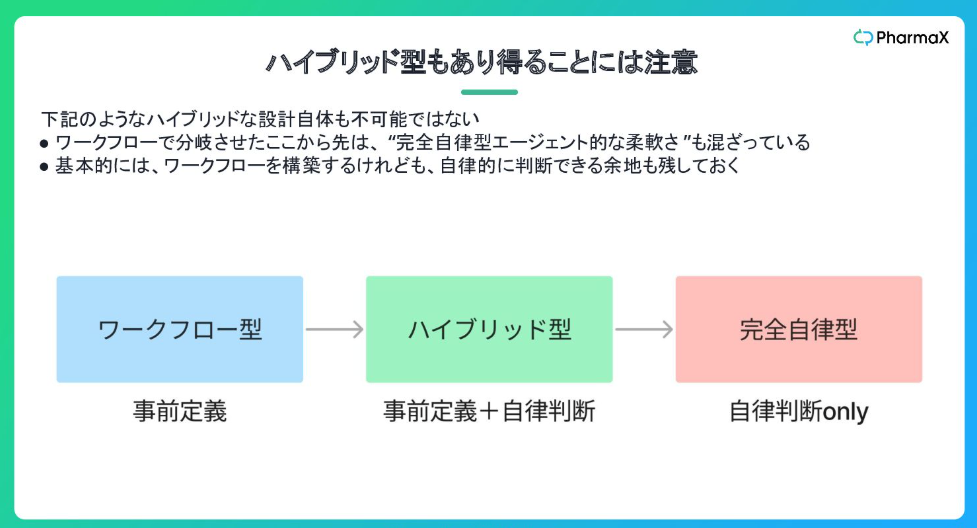
1. ワークフロー型
- 事前に定義された流れに従って動作する
- タスクのルールや選択肢を明示的に定義している
- 必要に応じて人の承認を挟むことができる
2. ハイブリッド型
- 事前定義と自律判断を組み合わせて使用する
- 基本的なワークフローを構築しつつ、自律的な判断の余地を残している
- 分岐後の判断をAIに委ねるなど、柔軟な対応が可能
3. 完全自律型
- 情報収集からアクションの決定まで全てを自律的に判断する
- 必要に応じてプログラムを自己改変できる
- 新しい動作パターンを自身で獲得していく
ユーザー目線と開発者目線での違い
ユーザー目線
- タスクを指示した後、結果が自動的に出てくれば「自律的」と認識する
- 実装方式に関係なく、自動で動作するものを全てAIエージェントとして受け入れる
開発者目線
- 完全自律型のみを真のAIエージェントと考える傾向がある
- 行動手順を人間が制御していない状態こそがエージェントだと捉える
現実的な解としてのワークフロー型
- 動作の安定性が高い
- 人間がタスクを引き継ぎやすい
- エラーが発生した際の原因特定が容易
- 現在の技術レベルでは、複雑な業務の自動化にはワークフロー定義が現実的
- ユーザーへの価値提供が達成できれば、実装方式は二次的な問題として考えられる
これらの考え方を踏まえると、2025年に向けては、ワークフロー型やハイブリッド型が主流になっていくんじゃないか。
ルール設定・ワークフロー構築という現実解

なぜ完全自律型ではなく、ワークフロー型が現実的と考えるのか👇️
1. 安定性が高い
- 決まった業務の自動化には、事前定義された流れの方が確実に動作する
- 毎回判断基準を考え直す必要がなく、処理速度も安定する
- 想定外の動作を防ぎやすい
2. 人間による引継ぎが容易
- 途中で処理が止まった場合でも、次のステップが明確
- エラーの原因特定がしやすい
- 人間のワークフローと親和性が高い
3. セキュリティ管理ができる
- アクセス権限や操作範囲を明確に制御できる
- 機密情報の取り扱いルールを明確に定義できる
- 監査やログ追跡が容易
また、現時点での技術レベルを考慮すると、複雑な業務を安定的にこなすためには、ある程度のワークフロー定義が不可欠。
他の"AIエージェント"について調査

ClineをForkしたRoo-Codeの実演と、内部実装で使われているプロンプトを見てみて👇️
- 見た目は自律的に動作しているように見えるが、実際には詳細なルールやプロンプトが定義されている
- 各ツールの使用方法や制限事項が明確に規定されている
- メッセージの処理方法や応答生成のルールが細かく設定されている
- カスタムルールを追加することで、より細かい制御が可能
例えばRoo-Codeの内部に実装されたプロンプトを見ると👇️
- ツールの定義(
read-file,search-file,list-files等)が明確- 各ツールの使用ルールが詳細に規定
- 1メッセージにつき1つのツールしか使用できないなどの制限
- タスク実行の方法論も規定されている
read-fileの例👇️
これらのエージェントも、完全な自律性というよりは、綿密に設計されたワークフローに従って動作していることがわかる。
他にもリクルタ AIなどの具体的な製品の話も話題に上がってました。ちなみに、リクルタAIの開発トークが以下のnoteで公開されてまして、こちらも大変参考になりました 📝
AIエージェントの注目トレンド

2025年に向けて、次の3つの主要なトレンドがあると思っている👇️
- マルチモーダル対応
- 画像・音声など、これまでデータ化されていなかった情報も処理可能に
- 例:飲食店の電話受付AIが、監視カメラの映像から店内の混雑状況を判断したり
- より人間に近い、総合的な判断が可能に
- ブラウザ/コンピュータ操作(Browser Use, Computer Use)
- API連携なしでの多様なツール操作が可能に
- 既存のWebアプリケーションを直接操作
- 例:採用活動支援AIが複数の求人サイトを横断的に操作
- 各種スカウトメッセージの自動生成と送信
- 処理能力の向上とコンテキストウィンドウの拡大
- より複雑なワークフローの実行が可能に
- より広範な情報を考慮した判断が可能に
- プロンプトの長さ制限が緩和されていく
- より自然な文脈理解と応答生成
AIエージェントの課題と将来
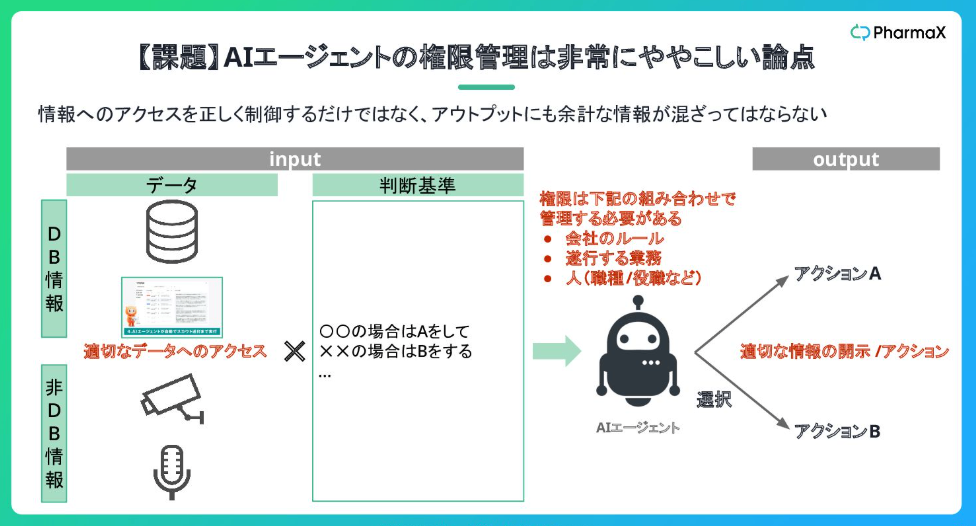
課題
1. 権限管理の複雑さ
- ユーザーごとのアクセス制御が必要
- 役職や職種による情報アクセスレベルの制御
- 機密情報の適切な取り扱い
- 権限の動的な変更への対応
2. メモリ管理とフィードバックループ
- 長期的な文脈の保持が困難
- 学習結果の効果的な反映方法
- シミュレーションベースの学習環境の構築
- フィードバックループの高速化
3. 物理的な制約
- デスクワーク以外の業務の自動化は依然として困難
- ロボティクスとの連携が必要
- センサー技術との統合
- 実世界でのアクション実行の制限
2025年に向けての展望
- 完全自律型ではなく、ワークフロー型が主流となる気がする
- 既存システムとの統合がより容易になる
- 特定業務に特化したエージェントが増加
- SaaSビジネスモデルの変化
- UIの重要性が相対的に低下
- データベースそのものの価値が増大
- API連携よりもブラウザ操作が主流に
将来的にはAIエージェント同士の連携や、AIエージェントを訓練するためのAIエージェントの出現も予想される。ただし、これらの実現には、セキュリティやプライバシーの課題、技術的な制約の克服が必要となる。
これらの変化がソフトウェア開発の方法論自体も変えるかもしれない。従来のAPIや人間のユーザーファーストの設計から、AIがより柔軟な操作を可能にする設計への移行が求められる可能性がある。
Q&A
イベントであったQ&Aも可能な限り書いておきます👇️
(登壇者の上野さんの見解であることにご留意ください⚠️)
GeminiやGPTのDeep Researchはワークフロー型ですか?
裏側で動作パターンが定義されていると考えられる。完全にオープンではないが、ある程度のルール設定型の仕組みが実装されていると予想される。
完全自立型は目的も自立的に設定するんでしょうか?
理論上は、目的設定から実行手順まで全て自律的に判断する。ただし、そこまでの自律性は現実的ではなく、必要性も疑問がある。
ワークフローを設計する際のコツなどあれば教えていただきたいです。例えば、LangGraphのように一を設計する際に、そもそもUIで分かるものか、一つのワークフローの中で分岐させるのか、など作りが難しいなと思ってしまいます。
適切な粒度での分割が重要。エンジニアがクラスや関数を設計する際と同様に、各タスクが明確に命名できる単位になるよう設計することがポイントとなる。
CursorやClineでコードを支援する時に、上手く動作させるために活用しているTipsはありますか?例えば、Rules for AIや`.cursorrules` をカスタマイズするなど。
カスタムルールを丁寧に定義することが重要。自社のルールや望む動作を明確に記述することで、より制御しやすい動作を実現できる。
Roo-Codeなどを実際の業務利用すると仮定したときですが、ゼロから簡単なアプリの開発には使えそうな印象を受けましたが、既存の比較的大きめのアプリに対して、現在の有用度はどのように感じていますか?
新規アプリケーションの早期立ち上げには適しているが、大規模な既存コードベースへの適用は難しい。ドメイン知識が必要な部分は、AIツールの種類によらず課題となる。
現状、ワークフローAI Agentの作成は基本LangGraph一択ですか。もし、他のフレームワークがあれば教えて頂きたいです。
現時点でAIエージェントで利用するもっともおすすめのLLMは何ですか?(OpenAI, Gemini, Claudeなど)
OpenAI、Gemini、Claudeのいずれも精度が向上しており、用途に応じて選択できる。現時点では、どのモデルも十分な性能を備えていると思う。
AIエージェントの製品が増えている印象ですが、差別化要素は何なるのでしょうか。Roo Codeの例を見るとプロンプトが重要ですか?
開発力と実装の質が差別化要素となる。業務フローの設計、指示の方法、情報収集の手法など、適切な実装が必要で、これらは簡単には実現できない。
比較的大きめのアプリに関しても、AIエージェントが効率的に開発支援をするために、どのような開発環境や開発プロセスを整えるのが実務的に大切か、と思われますでしょうか?
ドキュメントの整備が大事。フォルダ構成やモジュール単位での文書化を行い、AIが参照可能な形で情報を整理する必要がある。人間の理解のしやすさと同様の配慮が必要。
複数のエージェントへの指示を1つのプロンプトにぶち込んで利用して使いたいですが、o1とかo3はレスポンスタイムがずっと遅くなるし、STEM系に特化した進化をしている気がするので、進化の方向が違いたい方向と違うように感じています
コンテキストサイズの拡大により、将来的には複数のタスクを1つのプロンプトで効率的に処理できる可能性がある。現状では処理時間の課題があるが、一つの大きなプロンプトでの処理が個別処理より効率的になる可能性もある。
各機関単位ごとにベクトルDBをもたせることができると良さそうに感じますが、難しいのでしょうか?
技術的には可能だが、実装と運用が非常に複雑になる。シンプルな設計との両立が課題。
Clineなど横なアプリ・ツールで、各種クラウドLLMのAPI利用料の予算は、技術者一人当たり月いくらぐらいかかっていますか。現時点ではいくらが妥当だと思いますか。
基本料金部分で月7-8万円程度となる。人件費(100-200万円/月)と比較すると非常に割安であり、数万円程度の投資は妥当な気がする。
AIエージェントのセキュリティ的な質問です。エージェントの利用高の段階的な進歩を考えてみると Computer useのエージェントに特定の権限だけ渡していたとしても、プロンプトインジェクションのようなその他のアクセスも含め、不正に権限利用されるといったリスクは仕組み的には内包する感じですか?
自分もセキュリティリスクが内在していると思う。PCへの不正アクセスや意図しない操作の可能性があり、定期的な監視と検証が必須になる。
LangChainの実装のキャッチアップをした印象として、個人開発ではなく、プロダクションで動かすとなるとCI や評価の部分でハードルがある印象ですが、どのような工夫がありましたか?
評価部分に課題はあるが、様々な工夫を重ねることで対応可能。運用面での技術的な課題については、別途詳細な議論が必要となる。
o1以降、Reasoningが出来るLLMとそれ以前とではプロンプトの作り方は変わるのでしょうか?
最新のモデルは精度が向上しており、より効果的な利用が可能になっている理解。
業務に特化していくときにプロンプトを育て方代わりに、モデル自体をFineTuneする方法も考えられると思います。FineTuneの利用は今後進むと思われますか?
特に特定タスクの精度向上に効果的で、プロンプトエンジニアリングだけでは95%の精度が限界でも、ファインチューニングにより98-99%まで向上できる。専門家による適切なアノテーションデータを用いることで、高い精度を実現できる。

株式会社スマートラウンドは『スタートアップの可能性を最大限に発揮できる世界を作る』というミッションを掲げています。スタートアップと投資家の実務を効率化するデータ作成・共有プラットフォーム『smartround』を開発・提供しています。 採用ページはこちら-> jobs.smartround.com/
Discussion