こんにちは、株式会社スマートラウンドSREの@shonansurvivorsです。
私は今年5月に1人目のSREとしてこの会社に入社し、既に半年以上が経過しました。
2022年も終わりが近づいて来た中、この場を借りて、スタートアップの1人目SREとして、今年やってきたことを記録として残したいと思います。
なお、本記事で取り扱う内容はSREの理論や原理原則に沿って各種プラクティスを実践したこと、というよりは、セキュリティ、モニタリング、IaC、コスト、パフォーマンス、運用、開発効率などなど、いまこの組織で取り組むことでプロダクトと事業に貢献できるのではないか?と私なりに判断してきたこととなります。
そのため、Site Reliability Engineeringに関して学びのある記事にはなっていないと思いますし、また概ね時系列順に近い形で実施事項を羅列していきますので(述べ方が長たらしいという意味での)冗長に感じられるところも多々あると思います。ご容赦ください。
ちなみに私はコーポレートエンジニアを兼務しており、その立場での改善もいくつか行なってきたのですが、そちらは本記事ではスコープ外としています。
現状把握とインフラ構成図作成
当社のプロダクトであるsmartroundは、AWS上で稼働しています。
まずは現状把握ということで各AWSアカウントにログインして、どのような設計、運用になっているかを確認していきました。確認の観点としては以下のようなものになります。
- AWSアカウントは何個存在し、どのように使い分けされているか
- ルートユーザーの管理状況
- CloudTrailやConfigの設定
- ネットワーク設計
- IAM設計
- S3の設定
- 各種ログの取得状況
確認をする中で改善した方が良さそうな点があれば、順次GitHubのIssueに起票していきました。
なお、機械的、網羅的に確認を実施するにはSecurity HubやTrusted Advisorを使うのが有効です。ただ、この時点ではSecurity Hubがまだ有効化されていなかったのと、AWSのサポートプランがビジネス以上ではなく(現在はビジネスプランにしています)、Trusted Advisorの機能をフルに使えなかったので、いったん知識と過去の経験に頼ってざっくりとスピーディに確認を進めることにしました。
また、現状把握と並行してインフラ構成図を作成し、以後メンテナンスするようにしました。この構成図は後に他のエンジニアへの各種説明や、後述するAWSのソリューションアーキテクトの方のレビューでの提出などにも活用できており、初期に作成しておいて良かったと思っています。
GitHub Issue分類のためのラベル付け
さきほどGitHubにIssueを起票していったと書きましたが、短期間で比較的大量のIssue数となったこともあり、以下のラベルを新設し、Issueを分類するようにしました。
- Operational Excellence(運用上の優秀性)
- 長いのでラベル名としてはopexとしています
- Security(セキュリティ)
- Reliability(信頼性)
- Cost(コスト)
この分類は、AWSのベストプラクティスであるWell-Architectedを参考にしています。
Issueによっては複数のラベルが付くものもあります。なお、AWSに関連しないIssueに関してもこのラベル付けを行なっています。
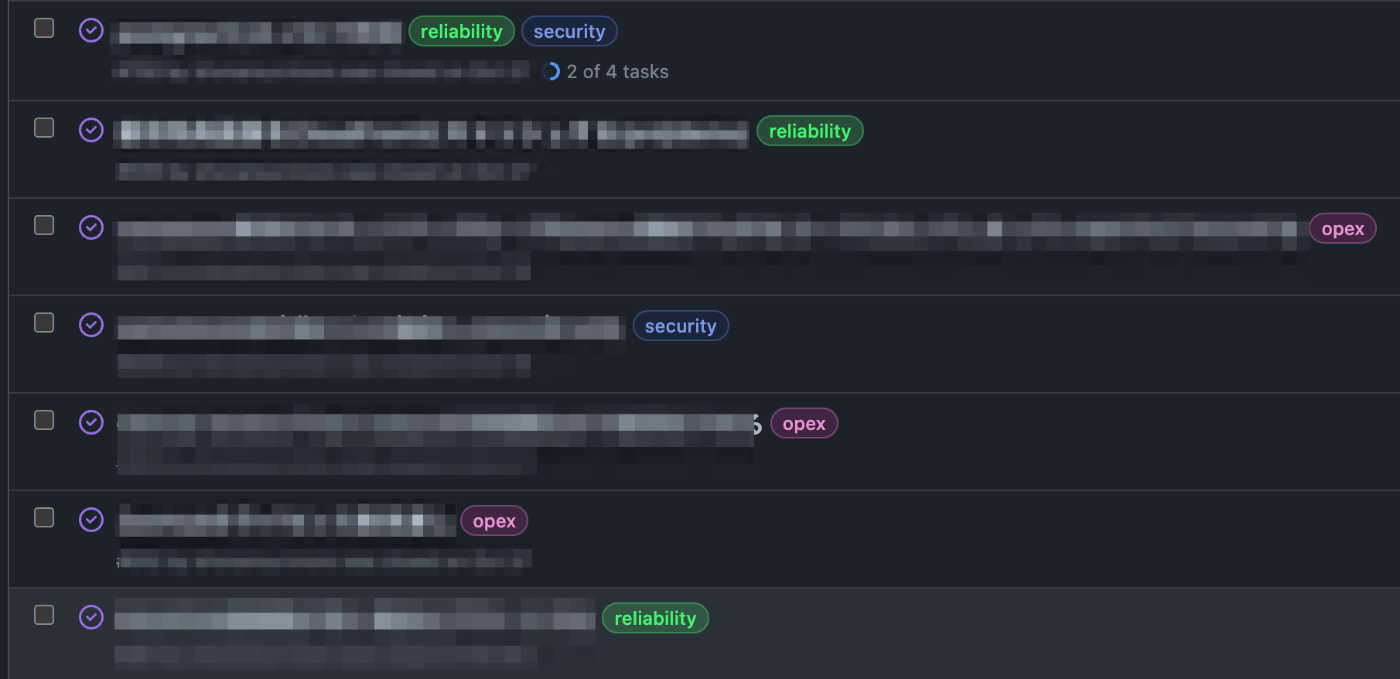
こうした分類によって、最初はセキュリティを優先的に対処し、その後に信頼性に着手・・・といった優先順位付けを短時間に効率的に行えるようになったと思います。
なお、いま思うとWell-Architectedにはあるパフォーマンス効率(Performance Efficiency)がラベルにありませんね。たぶん、そのIssueを解決した後の効果、結果に着目して「信頼性」か「コスト」のラベル付けを行なっていると思います。
IAM Identity Center(AWS SSO)導入とIAMユーザーの廃止
当社のAWSの運用を確認する中で気になったことの1つとして、IAMの使い方がありました。エンジニアがマネジメントコンソールにログインしたり、AWS CLIを使ったりするのにIAMユーザーを使っているという点です。
こうした運用自体は珍しいことではありませんが、IAMユーザーではパスワードやシークレットアクセスキーといった永続的なクレデンシャルを使用するため、流出した際のリスクが大きいものとなります。
加えて、当社はこの時点でAWSアカウントが4つあり(管理、本番、ステージング、サンドボックス)、それぞれのアカウント向けのIAMユーザーを使い分けなければならないという管理の煩雑さもありました。
そこで、IAM Identity Center(AWS SSO)を導入することにしました。当社は社員全員にGoogleアカウントを配布済みのため、これを外部IDとして使用しました。このGoogleアカウントは二要素認証を必須としているため、その恩恵も受けられます。
なお、ヒューマンアイデンティティではなくマシンアイデンティティの話となりますが、一部のEC2でIAMユーザーが使用されており、後にこれもIAMロールに置き換えました。
最終的に当社ではIAMユーザーの利用が無くなり、全て削除しました。
IAM Identity Centerに関するもう少し詳しい内容やTipsは、以下の登壇資料の該当ページやZenn記事も参考にしてください。
S3の設定見直し
S3に関しては、意図せずパブリックになっているものなどはありませんでした。ただ、将来誤ってパブリックにすることが無いよう、ブロックパブリックアクセスを有効化しました。
また、機密性や可用性を高める上で有効な手段である暗号化やバージョニングについては、設定されているのが一部のバケットのみだったので、全てのバケットに設定するようにしました。
AWSの各種ログの取得
WAF、CloudFront、ALB、VPCなどのログ取得状況を確認し、もし取得できていないログがあれば、新たにログを取得するよう設定しました。
Terraformの機密情報管理方法の見直し(パラメータストアの活用)
当社はIaCとしてTerraformを使用しています。
Terraformの利用にあたってはコードに機密情報を記述しないようにするための方法として、direnvが使用されていました。
direnvでは、.envrcに記述した変数と値のペアが環境変数として展開されます。
export TF_VAR_foo_access_key=xxx
さらにTerraformにおいてはプレフィックスがTF_VAR_である環境変数は、プレフィックスを除いた名前の変数として値が展開されます。
variable "foo_access_key" {
type = string
}
この.envrcに機密情報を記述した上でGit管理外とし、Terraformを扱うエンジニア数人の間で共有し合うことで、機密情報をコードに含めないようにしていました。
しかし、この運用では.envrcの内容が更新される都度、他のエンジニアにファイルを配布するという手間が生じます。また、配布漏れにより古い.envrcを使ってしまうことで、正しくインフラを管理できなくなるというリスクもありました。
これを改善するため、機密情報はAWS Systems Managerのパラメータストアに暗号化して保存し、そこを参照するようにしました。
data "aws_kms_alias" "aws_ssm" {
name = "alias/aws/ssm"
}
resource "aws_ssm_parameter" "secure_string" {
for_each = local.aws_ssm_parameter.secure_string
name = "/${var.project_name}/${var.env}/${each.key}"
type = "SecureString"
value = each.value
key_id = data.aws_kms_alias.aws_ssm.arn
lifecycle {
ignore_changes = [
value, # Terraform外で管理するため
]
}
}
locals {
aws_ssm_parameter = {
secure_string = {
# 暗号化する値はtfファイル上ではダミーの値とし、実際の値はTerraform外で後から設定する。
# その後にterraform applyしてもlifecycle.ignore_changesの対象としているため、ダミーの値で更新されることはない。
"foo/access_key" = "dummy"
"bar/access_key" = "dummy"
# 略
}
}
}
最初にパラメータストアを作成する際は値をdummyとしてterraform applyを行います。
その後にTerraform外で実際のシークレット値を入れるのですが、lifecycleブロックで、ignore_changesにパラメータストアのvalueを指定しているため、以後のterraform plan/applyでも差分が出ることはありません。
なお、パラメータストアをTerraformでResourceとして管理したり、あるいはData Sourceとして参照すると、たとえパラメータストアの値が暗号化されていたとしても、インフラの状態を管理するtfstateファイルには値が平文で書き込まれるので注意が必要です。
当社はtfstateをS3に保管していますが、tfstateにアクセス可能なIAMロールを限定するようにS3バケットポリシーを設定するようにしています。
Terraformでの複数環境管理方法の見直し
Terraformで、direnv(.envrc)を使っていたもう1つの理由として、複数の環境(AWSアカウント)を同一のコードで管理するため、というものがありました。
1つのリモートリポジトリから、1つのPCの異なるディレクトリにリポジトリをそれぞれCloneし、一方のローカルリポジトリをステージング環境用と位置付けてステージング環境向けの.envrcを配置し、もう一方は本番環境用と位置付けて本番環境向けの.envrcを配置します(.envrcはGit管理していないので、各ローカルリポジトリ間で異なる内容のファイルを配置しても問題にはならない)。
そして、ステージング環境用のローカルリポジトリからPRを立てて、ステージング環境に対してplan/applyし、mainブランチにマージした後は、本番環境用のローカルリポジトリにmainブランチをpullして本番環境に対してplan/applyを行う、といった具合です。
よくある「リポジトリ内にステージング環境用のディレクトリと本番環境用のディレクトリを定義する」といった構成ではありません。結構特殊な運用だと思います。
この見直しに関しては、.envrcの代わりにTerraformの変数の値を管理するファイルであるtfvarsをステージング用と本番環境をそれぞれ用意し(stg.tfvars, prd.tfvars)、これを使い分けることで、ローカルリポジトリを複数持つ運用を廃止しました。
現在の当社のTerraformリポジトリの構成は一部抜粋ですが、以下のような感じです。
.
├── stg.tfvars # Git管理しても構わないvariableの値を管理
├── prd.tfvars # 同上
├── variables.tf # variableの定義を管理
├── backend.tf # 通常はここでbackend(tfstateのs3)の設定を定義するが、{env}.tfbackendで管理するので、中身はほぼ空
├── stg.tfbackend # backendの設定を管理
├── prd.tfbackend # 同上
├── terraform.sh # 上記のtfvarsやtfbackendを読み込んでくれる薄いwrapper script。./terraform stg plan のように使う(詳細後述)。
├── xxx.tf # 各種resource定義
├── datadog/ # 独立性の高いリソース群は、別ディレクトリとすることでtfstateを別管理している(構成はルートディレクトリと同じ感じで、terraform.shについてはsymbolic linkを配置)
├── metabase/ # 同上
├── ...
└── schemaspy/ # 同上
また、{env}.tfbackendの中身は、stg.tfbackendであれば以下のような感じです。
bucket = "{stg環境用のtfstateを保管するS3バケット名}"
key = "tfstate"
encrypt = true
profile = "smartround-stg"
region = "ap-northeast-1"
dynamodb_table = "smartround-stg-terraform-state-lock"
こうした構成を取る場合、terraform plan/applyの実行にあたっては、以下のようにbackend-configとvar-fileを正しく指定してあげなければなりません。
terraform init -backend-config=stg.tfbackend
terraform plan -var-file=stg.tfvars
terraform apply -var-file=stg.tfvars
毎回これをミスなく指定するのは大変なので、軽量のwrapper scriptを用意し、環境名の後にterraformコマンドを指定できるようにしています。
./terraform.sh stg plan
./terraform.sh stg apply
scriptの中身は割愛しますが、使い方は以下のような感じです。
$ ./terraform.sh --help
Usage: [TF_SKIP_INIT=boolean ] ./terraform.sh [-help] <env> <command> [args]
env : environment [stg/prd/...]
command : terraform command [plan/apply/state/...]
args : subcommand [e.g. state "mv"] and terraform command options (see : terraform <command> -help)
TF_SKIP_INIT : skip "terraform init"
前述したファイル構成の気に入っているところは、以下のような「異なる環境を同一のtfで管理することを目的としたmodule」を作成しなくても済むので、その分のmodule設計やコード量を減らせるという点です。
.
├── envs
│ ├── stg
│ │ ├── backend.tf
│ │ ├── main.tf # ../../modules/foo を呼び出し
│ │ ├── providers.tf
│ │ └── versions.tf
│ └── prd
│ ├── backend.tf
│ ├── main.tf # ../../modules/foo を呼び出し
│ ├── providers.tf
│ └── versions.tf
└── modules
└── foo
├── main.tf
├── outputs.tf
└── variables.tf
(当社でmoduleを一切使わないということではありません。Terraform Registryの便利そうなmoduleは使いますし、部品としての独自moduleも必要であれば作ることもあります。)
もしかしたら、CIサービスによってはディレクトリで環境を分けることをしない当社のファイル構成は相性が悪いことがあるかもしれません。ただ、現在Terraformのplan/apply自動化のためにAtlantisを試験導入中ですが、Atlantisはtfvarsの使い分けをサポートしており、問題無く運用できそうな見込みです。
TerraformとAWS Providerのバージョンアップ
使用しているバージョンがTerraformは0.12系、AWS Providerは2系と古かったため、Terraformは1.x系に、AWS Providerは3系にバージョンを上げました。
その際、Terraformのバージョン管理はtfenvを使用するようにしました。
AWS Providerについては当時4系もリリースされていましたが、S3のコードの書き方について破壊的変更が多かったため、いったん3系までに留め、後に4系に上げています。
なお、現在はRenovateを導入し、自動でバージョンアップのPRが作成されるようになっています。
GitHub Organizationのセキュリティ強化
当社はプロダクトのIssueを全てGitHubで一元管理しており、非エンジニアであるCEO(今は違いますが昔はプロダクトマネージャーも兼務していたそうです)や、その他ビジネスサイドのメンバーもGitHubのアカウントを持っています。
このように全社的にGitHubを使っていることからリスクも高いと考え、その利用が適切なものとなるよう、GitHub Organizationの設定を確認し、必要に応じて見直しました。設定の見直しにあたっては、Flatt Securityさんのブログや、tmknomさんのZennの記事(本)を参考にさせていただきました。
不要コスト削減
AWSのコストを確認すると、比較的コストが高いものとして以下の2サービスがあり、調査することにしました。
- CloudWatch
- S3
CloudWatch
CloudWatchのコストに関しては内訳を確認すると、ステージング環境のPutLogEventsが多い傾向にありました。本番環境ではなくステージング環境であることを不自然に思いつつ、CloudWatchのロググループ画面を見ると、あるLambdaのログ保存量が突出して多くなっていました。さらにログそのものを見ると、Debugレベルのログが大量に出力されています。
他のエンジニアに確認したところ、ある機能追加での検証の際にログレベルをDebugにし、誤ってそのままにしてしまっていたようです。
ログレベルを修正することで、以降CloudWatchのコストは適正なものとなりました。
S3
S3については、Storage Lensという無料で使用できる機能があり、バケット別のサイズ上位や推移などを可視化できるため、こちらをコストの原因調査で活用しました。
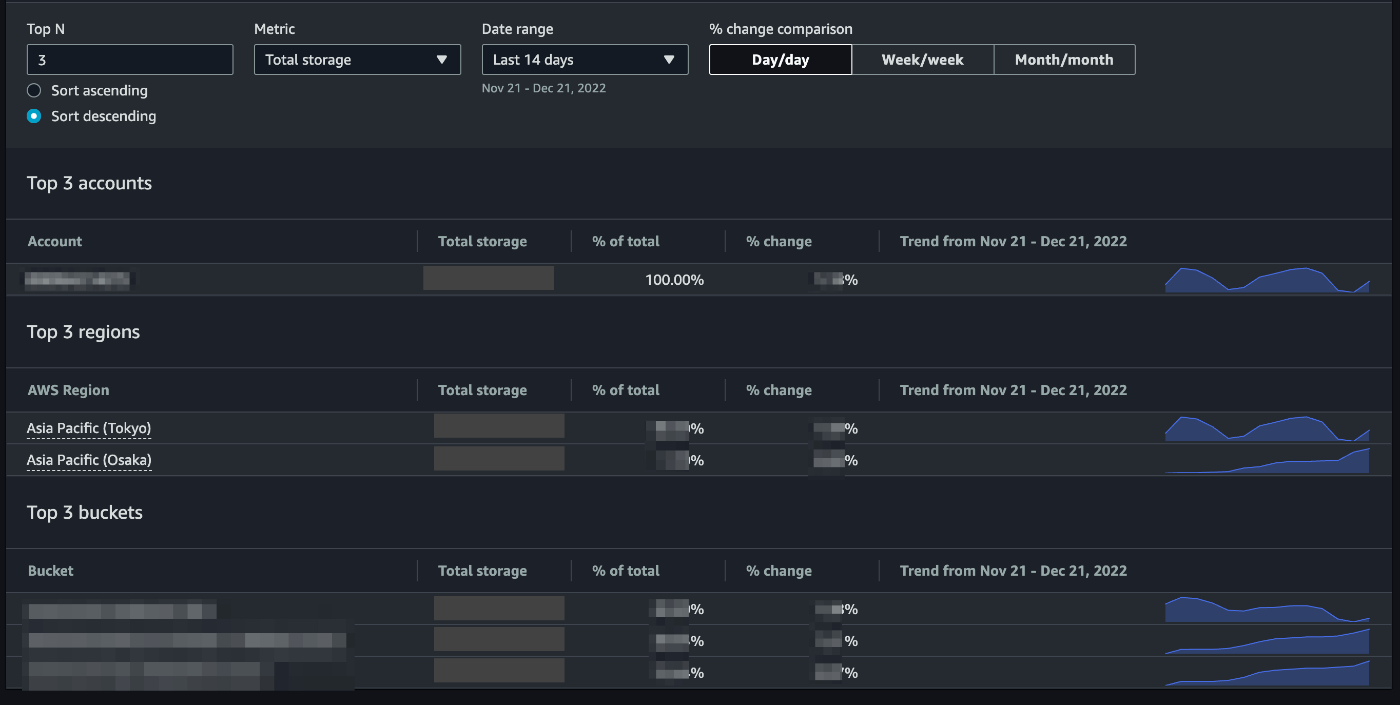
確認したところ、CodeBuildで使用されているS3のサイズが大きいことがわかりました。
当社はCDパイプラインにCodePipelineを使用しており、その中のビルドステージではCodeBuildによるアプリケーションのビルドを行なっています。このビルドによる生成物(アーティファクト)はS3に保存され、このS3をインプットとしてデプロイステージでのデプロイが行われるのですが、S3に保存されたアーティファクトは以後も削除されることはなく、永久に保存され続ける状態にありました。その結果、過去からの蓄積でS3のサイズが非常に大きくなっていました。
そのため、このS3にはライフサイクルポリシーを設定し、作成から一定期間の経過したアーティファクト(S3オブジェクト)が自動で削除されるようにしました。結果、S3についてもコストを大きく削減することができました。
なお、他のS3についてもライフサイクルポリシーを設定することが望ましいのですが、今回のCodeBuild用S3ほどのコスト削減効果が期待できなかったので、いったんは実施を見送りました。
商談用環境の構築
当社サービスであるsmartroundは、プラットフォーム型のSaaSであり、
- スタートアップ
- スタートアップに投資する投資家(ベンチャーキャピタルなど)
- スタートアップや投資家を支援するパートナー(会計事務所や法律事務所など)
といった様々な立場のユーザーが利用できます。
いずれの立場でもオンラインでサインアップすることで無料で利用を開始できるのですが、より機能の充実した有料プランでの利用を検討いただいているお客様向けに対しては、営業メンバーが商談を設定し、実際のサービスを使ってデモを行うということが頻繁にあります
(なお、スタートアップに関しては、簡単な条件を満たせば有料の基本プランでも無料、上位のプランでも割り引いた金額で利用できます)。
当時、smartroundが動いている環境としてはローカル以外では本番環境とステージング環境の2つが存在し、商談ではステージング環境を使用していたのですが、これには弊害がありました。
ステージング環境はまだ品質が充分に保証されていない新しい機能が随時リリースされるため、本番環境と比較して不安定です。最悪、商談の途中でバグが発生してしまうということも考えられなくありません。また、営業メンバーがまだ充分に把握していないUI変更などが商談の直前や最中にリリースされると、営業メンバーが想定しているシナリオ通りにデモを進行できなくなるリスクもあります。
そのため、商談中はステージング環境へのリリースを控えたり、(本来であれば本番環境へのリリースの前に行えば良いはずの)大きなUI等の変更の説明をステージング環境へのリリース前に営業メンバーに対して行なったりしていました。
しかし、こうした運用による商談への影響回避はミスもありえますし、たとえ100%遵守できたとしてもこういった運用ルール自体が開発速度を低下させることも大いに懸念されます。
そこで、ステージング環境とは別に商談専用の環境(以降、デモ環境)を構築することの検討に入りました。
複数案を比較検討した結果、ステージング環境とは完全に隔離した、デモ環境専用のAWSアカウントを新設することにしました。他の考えられる案と比較して維持費用はやや大きくなりますが、商談と開発が互いに影響を与えないようにするという目的を果たすには、AWSアカウントごと分離するのが適切と判断しました。私自身も他の改善のためにインフラ変更を今後頻繁に行うことを想定すると、ステージング環境とデモ環境でインフラが完全に分離されていた方が安心感がありました。
なお、ステージング環境と本番環境はスペックを同等としていますが、デモ環境はアクセスが非常に少ないため、それを考慮したスペックとすることで費用を抑えるようにしました。
新環境の構築作業自体は、RDSや一部のS3はデータ移行が必要でしたが、その他のステートレスなリソースはTerraformによって簡単に再現できるので、そう大変なものではありませんでした。一部アプリケーション側の修正も必要であったため、初めてKotlinのコードを触りましたが、簡単な処理分岐追加程度でしたので問題無く修正のPRを上げ、マージすることができました。
デモ環境の運用開始は営業メンバーにもエンジニアにも喜ばれ、今年やった仕事の中でも達成感のあるもののひとつでした。
複数環境を使い分けるためのChrome拡張の作成
本番環境、ステージング環境に加えてデモ環境といった計3環境を用途に応じて使い分けることとなったため、ビジネスサイドのメンバーやエンジニアが、いま自分がアクセスしている環境を取り違えて誤操作などが発生しないようにする必要があると考えました。
そこで、各環境を一目で見分けることのできる社内用のChrome拡張を作成しました。画面左上に環境名を示すリボンのようなオブジェクトが表示されるようになります。なお、デモ環境は社員のPCの画面をお客様に見せることを想定し、このChrome拡張を入れても何も追加表示を行いません。
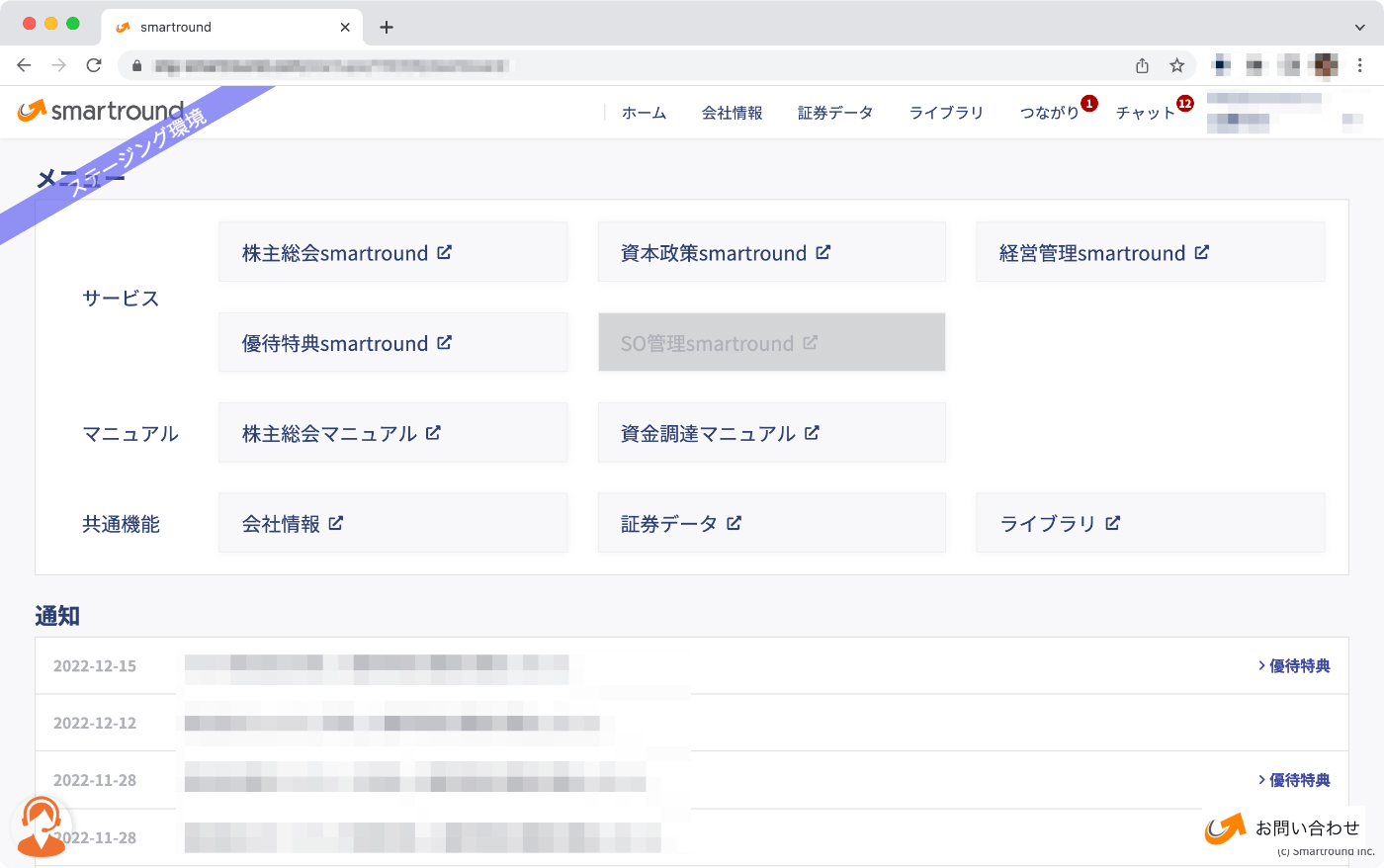
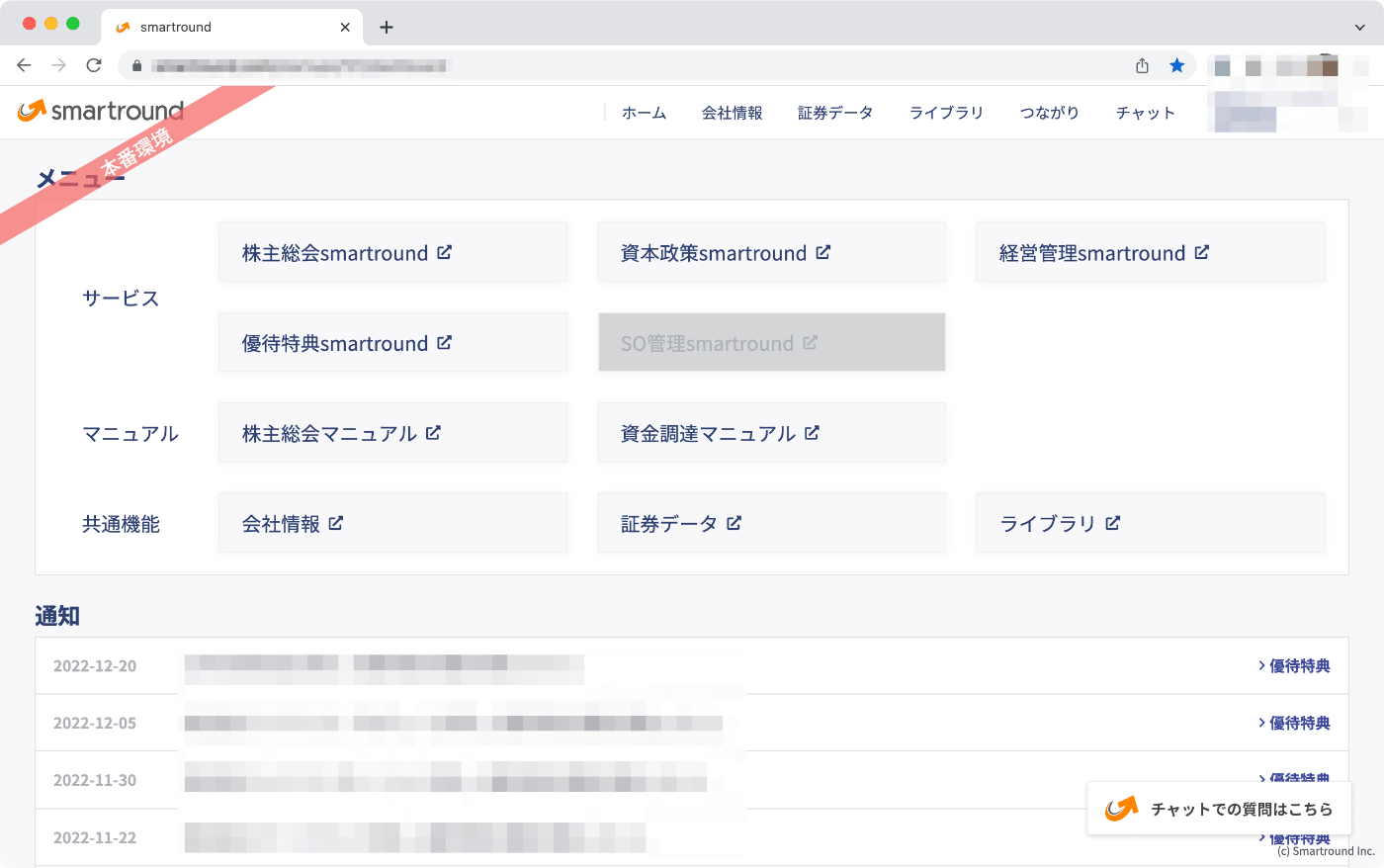
こちらを社員全員のChromeにインストールすることで誤操作リスクを下げるようにしました。
なお、Chrome拡張を作成するのは今回が初めてでしたが、chrome-extension-v3-starterをベースに修正を行うことで簡単に作成することができました。
CDパイプラインの見直し
当社はCDパイプラインとしてCodePipelineを採用していましたが、歴史的経緯から1環境あたりに処理内容の異なる3本のCodePipelineが存在し、それらをエンジニアが手順に沿って手動で連携させることでデプロイを行なっていました。
それぞれの処理内容を分析したり、デプロイ作業を行なっているエンジニアにヒアリングしたりした結果、全ての処理内容を1本のパイプラインにまとめられることがわかったため、そのようにCodePipelineを修正し、デプロイに関わるエンジニアの手作業を削減しました。
その他の運用改善として、一部でGitHub Actionsを採用しました。
CodePipelineではソースとしてGitHubのリポジトリおよびブランチを設定可能であり、ステージング環境のCodePipelineではデフォルトブランチを設定しているのですが、当社の運用ではそれ以外のブランチに切り替えたい場面がありました。
ここで素直にCodePipelineの対象ブランチを切り替えようとすると、マネジメントコンソールにログインして対象のCodePipelineを選択してから、5回以上のクリックが必要となります。
また、この操作による切り替えは、CodeBuildの「上書きビルド」のような一時的な変更ではなく永続的なものであるため、元に戻しておかなかった場合にTerraformで差分として検知されることになります。
こうした点が煩わしかったため、ステージング環境ではGitHub Actionsをデプロイの起点とするようにしました。
なぜ、GitHub Actionsを採用したかというと、CodePiplineのソースとなるブランチを変更する操作よりも、GitHub ActionsのWorkflow Dispatchでブランチを選択する操作の方が、UI的に開発者体験が良かったためです。
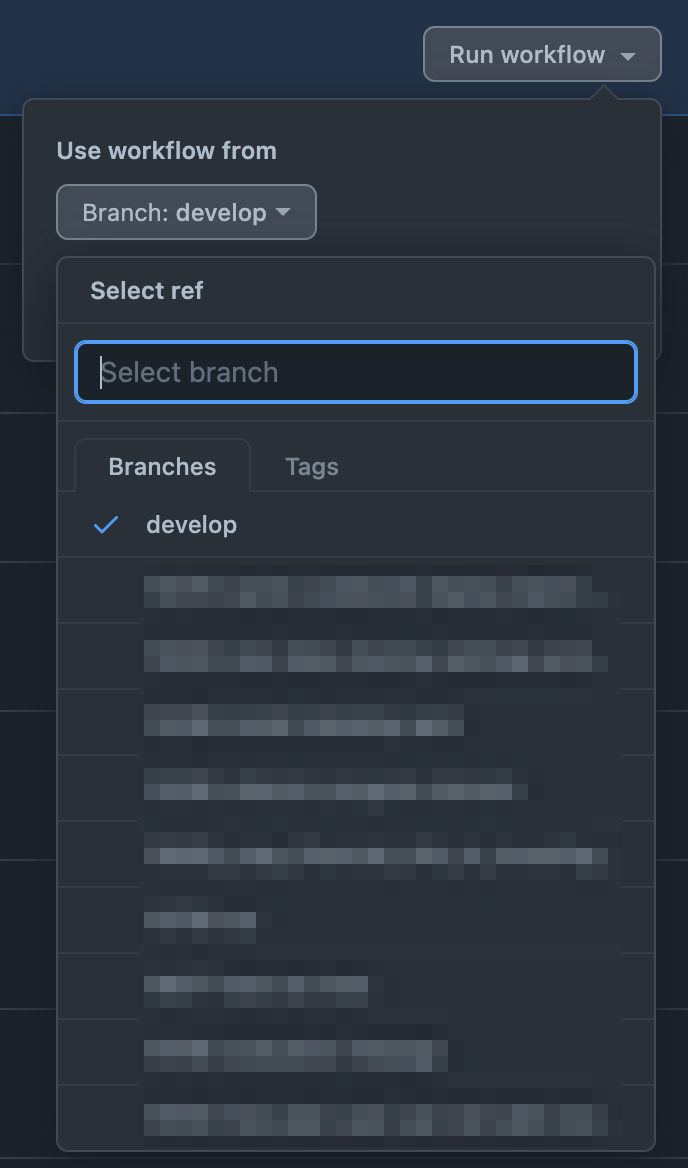
具体的な変更内容としては、GitHub Actionsでは任意のブランチのコードをZip形式でステージング環境のS3にアップロードするまでを行い、ステージング環境のCodePiplineではソースとしてGitHubそのものに接続するのではなく、このS3を使うようにしました。
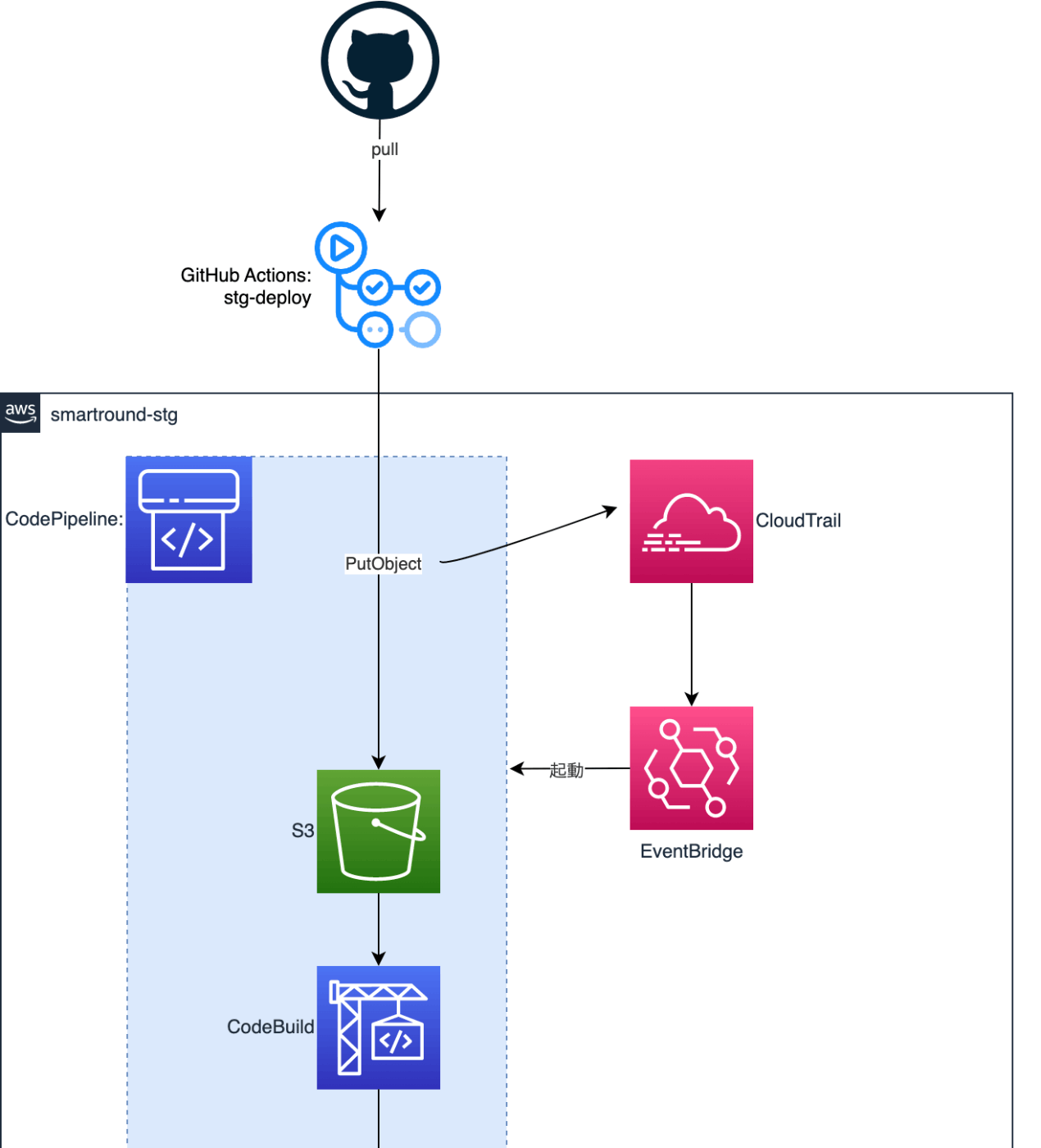
この改善により、任意のブランチをステージング環境にデプロイするのが楽になり、またTerraformで余計な差分が検知されることも無くなりました。
Synthetic Monitoringの導入(UptimeRobot)
当社ではもともと様々な監視が行われていましたが、Synthetic Monitoringが未導入であったため、この仕組みを構築しました。
Synthetic Monitoringを行う方法は各種ありますが、当時はまだDatadogが未導入であったり、AWSのCloudWatch Syntheticsの機能は実現したいことに対してややリッチであったりしたので、安価でシンプルなUptimeRobotを採用しました。
まず書籍「入門監視」における「healthエンドポイントパターン」となるエンドポイントを他のエンジニアに構築してもらい、その上で私はそこへのリクエストの成否を監視するようにUptimeRobotに設定を行いました。
(「healthエンドポイントパターン」は、クラウドデザインパターンで言うところのDeep Health Checkパターンと多分同じものだと思いますので、解説としてはそちらを見ていただけたらと思います)
ちなみにこの構築を行った後のタイミングで、LAPRASさんがUptimeRobotのTerraform moduleを公開されており、今後ぜひこちらを利用させていただいてIaC化したいと思います。
CloudWatch Logsでのログ表示の改善
CloudWatch Logsに表示される複数行のスタックトレースが、1行ごとにインデックスされる状態にあり、見づらいものとなっていました。

1行ごとに"▷"が存在している
これをスタックトレースが1つにインデックスされるようにしました。

スタックトレース単位で"▷"が存在している
当社はメインのプロダクトをElastic Beanstalkで稼働させているのですが、Elastic Beanstalkの場合、EC2内の/opt/aws/amazon-cloudwatch-agent/etc/beanstalk.jsonというファイルが、CloudWatch Agentの設定ファイルとなっています。
これにmulti_line_start_patternを追加することで、スタックトレースが1つにインデックスされるようにしました。
{
"logs": {
"logs_collected": {
"files": {
"collect_list": [
{
"file_path": "/var/log/eb-engine.log",
"log_group_name": "/aws/elasticbeanstalk/{Elastic Beanstalkの環境名}/var/log/eb-engine.log",
"log_stream_name": "{instance_id}"
},
# 略
{
"file_path": "/var/log/web.stdout.log",
"multi_line_start_pattern": "^*.[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}.[0-9]{3}",
"log_group_name": "/aws/elasticbeanstalk/{Elastic Beanstalkの環境名}/var/log/web.stdout.log",
"log_stream_name": "{instance_id}"
}
]
}
}
}
}
当社はElastic BeanstalkのEC2のAMIとして、AWSの提供するマネージドなAMIを素で使っています。そのため、新規にEC2が起動するたびに前述のbeanstalk.jsonはデフォルトの状態になってしまいます。
Elastic Beanstalkにはhooksという仕組みがあり、EC2起動後のアプリケーションがデプロイされるタイミング前後で、任意のスクリプトを実行できます。これを利用して、predeployのタイミングでbeanstalk.jsonにmulti_line_start_patternが追加されるようにしています。
#!/usr/bin/env bash
set -euo pipefail
# multi_line_start_patternについて
# multi_line_start_patternの値となっている正規表現はタイムスタンプを表している(例: 2022-07-02 17:29.30.500)。
# スタックトレースには上記形式のタイムスタンプが無いので、それ以前のタイムスタンプのあるログと一緒にCloudWatch Logsにインデックスされる(つまり、CloudWatch Logs上で複数行に分かれない)。
# 参考: https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/CloudWatch-Agent-Configuration-File-Details.html#CloudWatch-Agent-Configuration-File-Logssection
#
# 正規表現について
# 今回の正規表現では \ によるエスケープを使用しなくて済む内容にしている。
# 正規表現で \ を使おうとすると、sedのエスケープとjsonのエスケープの両方を考慮した複雑な処理になるため。
sed -i '\/"file_path": "\/var\/log\/web.stdout.log",/a "multi_line_start_pattern": "^*.[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}.[0-9]{3}",' /opt/aws/amazon-cloudwatch-agent/etc/beanstalk.json
ただ、このpredeployのhookが動くタイミングでは、既にCloudWatch Agentの起動処理が完了しており、このままでは修正後のbeanstalk.jsonの設定が反映されません。そのため、beanstalk.jsonの変更後にCloudWatch Agentの再起動を行うようにしています。
#!/usr/bin/env bash
set -euo pipefail
# ElasticBeanstalkのデプロイ処理では、
# prebuild hook -> beanstalk.jsonの再作成-> CloudWatch Agentの再起動 -> predeploy hook ... といった順に処理が進むので、
# predeploy hook内では、
# - beanstalk.jsonのカスタマイズ
# - CloudWatch Agentの再起動(2回目)
# を実施している。
amazon-cloudwatch-agent-ctl -a fetch-config -c file:/opt/aws/amazon-cloudwatch-agent/etc/beanstalk.json -s
MetabaseのElastic BeanstalkをECS Fargateへ移行
当社は、データ分析にMetabaseを使用しています。
MetabaseをAWS上で動かす方法として、公式ドキュメントではElastic Beanstalkを使う方法が紹介されており、実際にElastic Beanstalkで稼働させていました。
ただ、いくつか課題があり、
- IaC化が見送られていた
- Metabaseのバージョンが構築当初のまま
- Metabaseの設定用DBとして利用しているRDSのストレージが暗号化されていない
という状況でした。
また、Elastic Beanstalkでは初期構築時にRDSを同時作成して管理下に置くか、あるいはRDSは独自に構築してElastic Beanstalk(のEC2)と接続させるかを選択できるのですが、前者を選択しており、RDSの暗号化のためにElasticBeanstalkの管理外にする必要がありました。
以上を踏まえ、ゼロから新規構築した方が課題を解消させやすく、また今後もメンテナンスしやすいと考え、ECS Fargateを使った構成をTerraformで構築しました。RDSに関しては、旧RDSのスナップショットを元に暗号化した上でリストアし、新DBインスタンスを作成しました。
IaC化され、バージョンアップもECSタスク定義に指定する公式イメージを差し替えるだけになり、以前よりも管理がしやすくなったと思っています。
CIの処理時間削減
当社はプロダクトのCIにCircle CIを使用しています(なお、TerraformのCIなど、私の入社以降に新規追加する処理はGitHub Actionsで構築させてもらっています)。
このプロダクトのCIの処理時間が以前よりもかかっているという声が上がっていたため、現状把握の上、改善することにしました。具体的には以下のような変更を行いました。
- CI環境へのcheckout(git clone)に時間がかかっていたのでshallow cloneにすることで短縮
- Job構成の見直し(直列である必要の無いstepを別jobへ切り出すなど)
- Job内のテスト実行の並列化
- とある処理の実現のためにCI環境にあるソフトウェアをインストールしていたが代替手段があるのでインストールをやめる
- 出力されるログのうち、不要なものは抑制
- 出力されるレポートのうち、参照されていないものは抑制
結果、全体の処理時間を約半分にすることができました。
AWSマルチアカウント戦略とセキュリティ向上
この時点で、AWSアカウントは5アカウント(管理、本番、デモ、ステージング、サンドボックス)存在しましたが、これらアカウントに対する統制をベストプラクティスに沿って行うため、Control Towerを導入しました。
このControl Tower導入により、さらに2アカウント(監査、ログアーカイブ)が増えています。
こうしたマルチアカウント戦略をどのような考えで行ったかは、AWS Startup Community Conference 2022の登壇資料が詳しいので、ぜひそちらもご覧いただけたらと思います。
AWSソフトウェアパスに加入し、FTRを受けてAWS認定ソフトウェアを取得
私の入社後、当社はAWSパートナーネットワークに加入しました。AWSパートナーネットワークというと、企業のクラウド導入・利用を支援するSIerさんなどが加入しているものというイメージがもしかしたらあるかもしれませんが、実は当社のようなSaaSを提供している企業もソフトウェアパスという枠組みで加入できます。加入するだけでしたらお金はかかりませんし、上位のステージでの待遇を受けるには費用が必要なものの、それによって得られる各種特典なども考慮すると、総合的にはお得です。詳しくはAWSの担当営業や担当アーキテクトの方に聞いてみてください。
加えて、ソフトウェアパスには、FTR(Foundational Technical Review)というものがあり、AWSのパートナーソリューションアーキテクトにより自社のアーキテクチャについて技術レビューを受けることができます。そして、このレビューを通過することでAWS認定ソフトウェアとなることができます。
当社は準備を行なった上でFTRに臨み、レビューを無事通過してAWS認定ソフトウェアになることができました。
レビューに向けてどう準備したかなどの詳細は別途記事化するか、何かのイベントで登壇してお話しできたらと思います。
DBのドキュメントを自動更新して認証付きS3にホスト
当社は、DBのテーブル・カラム一覧やER図などのドキュメントの作成にSchemaSpyを使用しており、その実行のためのスクリプトなどは整備されていたのですが、特に自動化などはされていませんでした。
そこで、DBの定義情報ファイルが更新される都度、GitHub ActionsでSchemaSpyを実行して作成されたドキュメント(静的ファイル)がS3にアップロードされるようにしました。これにより、エンジニアが最新のDBに関するドキュメントを楽に簡単に閲覧できるようにしました。
このS3は、CloudFront x Lambda@Edge x Cognitoにより認証をかけ、社内の特定の人間しかアクセスできないようにしています。Lambda@Edgeでは、Cognito@Edgeを動かしているので、Lambdaのコードはほとんど書かずに済んでいます。
Datadog Log Management導入
ALBのログを可視化してパフォーマンス分析を行うため、Datadog Log Managementを導入しました。
当社プロダクトのsmartroundは、スタートアップによる経営管理やベンチャーキャピタルによる投資管理等を行うサービスという業務特性上、アクセス数は他のWebサービスと比較して多くはありません。Datadog Log Managementの料金は転送されるログのインデックス量に左右されますが、当社サービスのログ量であれば安価にログの可視化ができると考え、まずはLog Managementの機能からDatadogの利用を開始することにしました。実際、非常に低コストで利用できています。
現在は主要なパスごとにパフォーマンスを可視化したダッシュボードを作成し、SREやその他エンジニアは必要に応じてこれを確認しています。
また、Datadogではダッシュボードのスナップショットを、指定したメールアドレス宛に定期的にレポートすることができます。
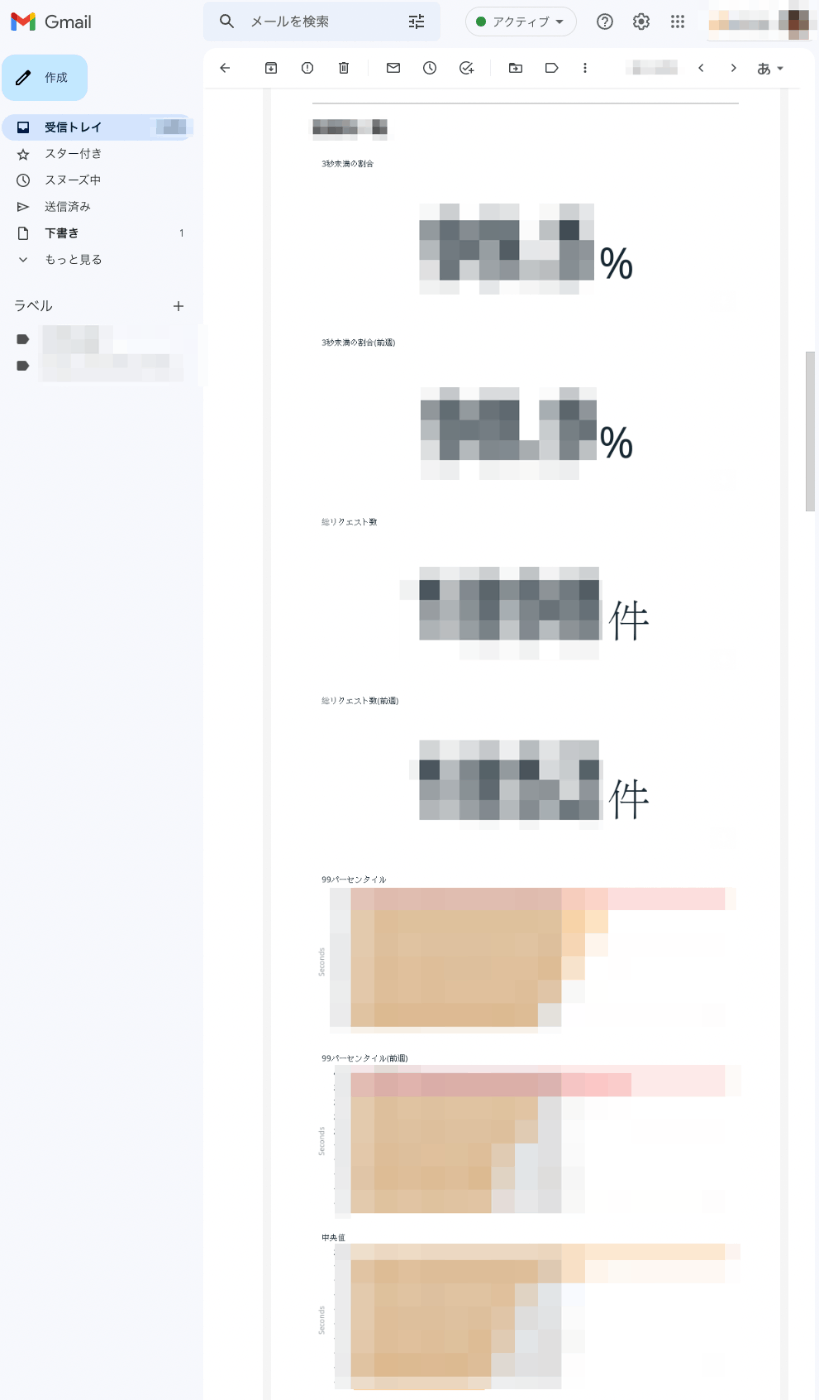
このレポートをエンジニアだけでなく、プロダクトマネージャーやカスタマーサクセスといったプロダクト関係者に週次で送るようにしました(ダッシュボードのアクセス権も付与していますが、メールで情報をプッシュした方が見てもらえると判断)。これにより、プロダクトマネージャーやカスタマーサクセスも、ユーザーがどの程度快適に当社サービスを使えているかがより客観的な数値で把握できるようになり、プロダクトの改善を議論するにあたり、パフォーマンス面に関しても以前より話題に上がるようになりました。
なお、彼らからは「特にデータ量の多い顧客企業について企業別のパフォーマンスを見たい」という要望もあったため、そうしたダッシュボード等を作成し、これもレポートメールを週次で送るようにしています。
Datadog APM導入
パフォーマンス改善のための分析をより深く効率的に行えるようにするため、Datadog APMも導入しました。こちらはパフォーマンスが低いAPIの原因分析を行う際などに役立っています。
Graviton移行
RDSやElastiCacheといったマネージドサービスについて費用削減、というか同一費用でより高い性能を得て将来のコスト増を先送りすることを目的として、Gravitonに移行しました。
Graviton移行にあたっては、@integrated1453さんの以下の登壇資料を参考にさせていただきました。
GitGuardian導入
アクセスキーなどの秘密情報をGitリポジトリに混入させない方法は様々ありますが、当社ではGitGuardianを導入しました。
GitGuardianは、GitHub Appsというかたちでも提供されており、これをGitHubにインストールするだけで、GitHubにコミットをプッシュする都度、秘密情報の混入を検知してくれます。

もちろんGitHubにプッシュした時に検知、であると、たとえ秘密情報をコードから削除したとしてもリモートのGitの履歴にそれは残り、混入を事前に防いでいることにはならないのですが、その秘密情報は無効化して新しいものを再発行して使うといった運用を取ることで、有効な秘密情報がコードに残存しないようにしています。
なお、秘密情報のコミットを完全に事前に防ぎたい場合は、GitGuardianのCLIをローカルにインストールし、GitのPre-CommitでGitGuardianを走らせることで実現可能です。
このGitGuardianの良いところは、秘密情報を検知すると謳っている他のサービスと比較して、非常に多くのサービスの秘密情報を精度高く検知してくれるところです。また、リポジトリを過去のコミットも含めてフルスキャンし、Gitの歴史に残った秘密情報を検出してくれもします。
そして、随時であってもフルスキャン時であっても、検出した秘密情報は管理画面に一覧表示され、担当者のアサインや、以下のようなステータス管理ができます。
- 解決した
- 秘密情報であり、revokeした
- 秘密情報であり、revokeはしなかった
- 無視した
- テスト用の秘密情報だから
- 低リスクな秘密情報だから
- そもそも秘密情報ではないから(偽陽性)
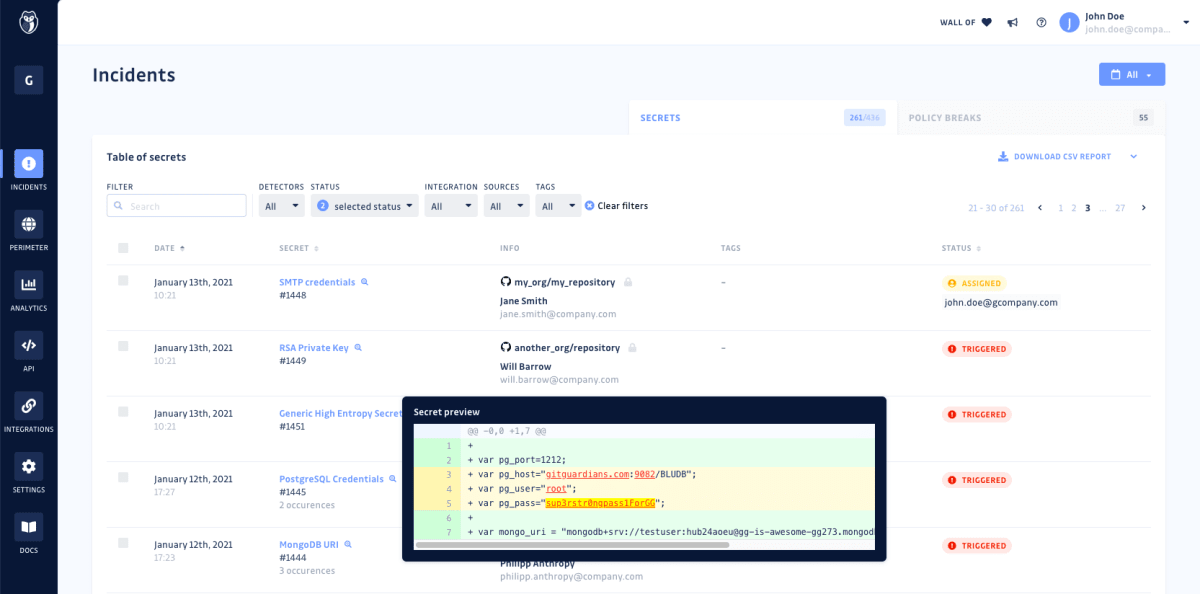
機密情報混入防止は各社様々な対策を取られていると思いますが、その対策はそのままにこのGitGuardianを追加導入してみても良いのではと思います。
振り返りと今後に向けて
以上、スタートアップの1人目SREとして、(ここにあることが全てではありませんが)この2022年にやってきたことの記録でした。長文でしたが、ここまでお付き合い下さり、ありがとうございます。
こうした様々な取り組みができたのも、大きな裁量を持ってやれるよう任せてくれるCTOや、私の苦手領域のことをフォローしてくれる社内のエンジニアのおかげであり、感謝です。
今後は以下のようなものをはじめとして、さらなる改善を図っていきたいと思います。
-
プロダクトをElastic BeanstalkからECS Fargateに移行し、今後新規ジョインする人のElastic Beanstalkの知識キャッチアップを不要とする(2023年4月にECS Fargateへの移行が無事完了しました) - Terraform plan/apply自動化のためのAtlantis本格運用開始
- 現在SRE内に閉じて各種の判断に利用しているSLI/SLOを全社に展開
など。
そして、採用活動にもより一層力を入れていきたいと思っています。
採用情報
ということで、株式会社スマートラウンドではエンジニアを募集中です!正社員はもちろん、副業でのジョインも歓迎です。少しでもご興味あれば、お気軽にカジュアル面談にお申し込みください。

株式会社スマートラウンドは『スタートアップの可能性を最大限に発揮できる世界を作る』というミッションを掲げています。スタートアップと投資家の実務を効率化するデータ作成・共有プラットフォーム『smartround』を開発・提供しています。 採用ページはこちら-> jobs.smartround.com/
Discussion