Datadogとは? by ChatGPT
Datadogは、クラウドベースの監視および分析ツールです。主にインフラストラクチャの監視、アプリケーションパフォーマンスの管理、ログの分析などに使用されます。以下にDatadogの主な機能と特徴をまとめます。
主な機能
-
インフラストラクチャの監視
- サーバ、データベース、コンテナなどのリソースをリアルタイムで監視
- CPU、メモリ、ディスク使用率などのメトリクスを収集・表示
-
アプリケーションパフォーマンスの管理 (APM)
- アプリケーションのパフォーマンスデータを収集・分析
- トレースを使用して遅延やエラーボトルネックを特定
-
ログ管理
- アプリケーションやインフラからのログを収集・集約
- ログデータをリアルタイムで検索、分析可能
-
ダッシュボードとアラート
- カスタマイズ可能なダッシュボードでデータを視覚化
- 閾値に基づいたアラートを設定し、異常を検出した場合に通知
-
クラウドサービスの統合
- AWS、Google Cloud Platform、Azureなどの主要なクラウドサービスと統合
- クラウドサービスのメトリクスを自動的に収集
-
コンテナ監視
- DockerやKubernetesなどのコンテナ環境をサポート
- コンテナごとのメトリクスやログを取得し、パフォーマンスを分析
特徴
- リアルタイム監視: リアルタイムでデータを収集・表示することで、迅速な問題解決が可能
- 拡張性: 小規模から大規模なインフラストラクチャまで対応
- 使いやすさ: ユーザーフレンドリーなインターフェースと豊富なドキュメント
- 統合の豊富さ: 400以上の統合オプションにより、さまざまなツールやサービスとの連携が可能
- セキュリティ: データの暗号化やアクセス制御などのセキュリティ機能を備える
使用例
- システム管理者: サーバやネットワークの状態を監視し、パフォーマンスのボトルネックを特定
- デベロッパー: アプリケーションのパフォーマンスを監視し、コードの最適化ポイントを特定
- データアナリスト: ログデータを分析してビジネスインサイトを得る
Datadogは、可観測性(Observability)を高めるための強力なツールセットを提供し、ITインフラストラクチャやアプリケーションの健全性を維持するのに役立ちます。
弊社では
ECSでシステムを構築しており、Datadog Agent経由で諸々のデータを連携しています。
ですが、Datadogの扱いに慣れているエンジニアがいないので、うまく使いこなせていない状況でした。
たまたま私が深くお犬様(datadog)と戯れる機会を頂けたので、色々触ってみた結果をメモがてらまとめたいと思います。
まず最初に
Datadogは本当に色々な機能があります。
どこになんの機能があるのか探すのも分からなくなるときがあるので、検索窓を使用すると良いです。
Macでは cmd + k 検索窓を開くことができ、キーワードから機能を検索できます。

Metrics Explorer
Datadog Agentを通じて連携された諸々のデータはMetrics Explorerから確認することができます。
このMetricsは後述のMonitorsを設定する際にも使用します。

Monitors
Metricsなどの指標を選択して、その指標が健全な状態を保っているかを監視することができます。
問題なければOK、ある一定の閾値を上回ったり、下回ったりした場合はALERTという表示になります(WARNINGもたしかできるはず...)。
ALERT状態になったタイミングでslackなどに通知を飛ばすこともできます。

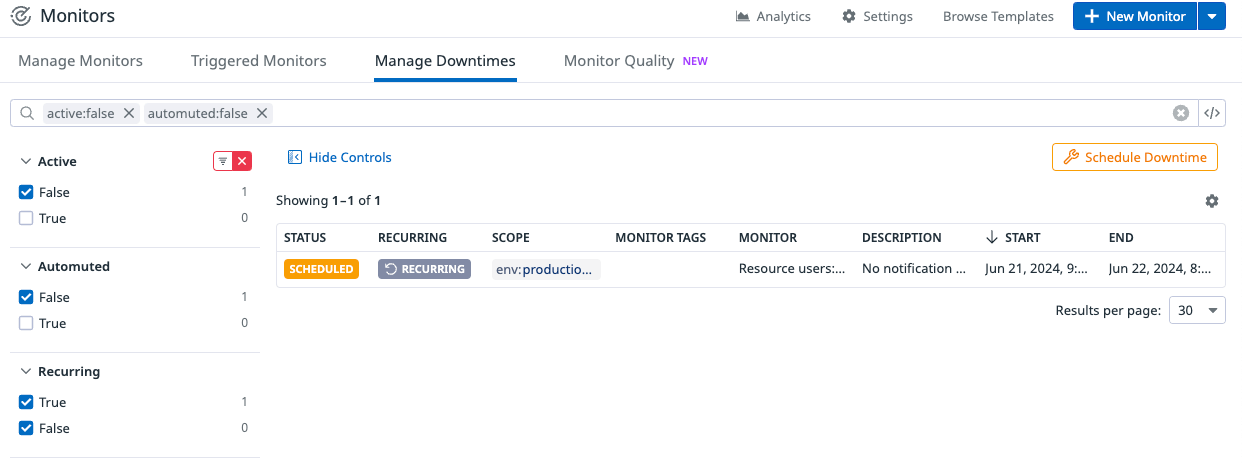
Manage Downtimes
メンテナンス中はアラートを飛ばしたくない!ということもあります。
その時に使えるのがManage Downtimesです。
メンテナンスの時間をあらかじめ設定し、Monitorsによる通知を一時的に止めることができます。
SLO
設定したMonitorsをもとにSLOを可視化することもできます。
MonitorsからSLOを設定できます。
例えば サービスの可用性99.99% を担保できているかといったことを一目で確認することができます。
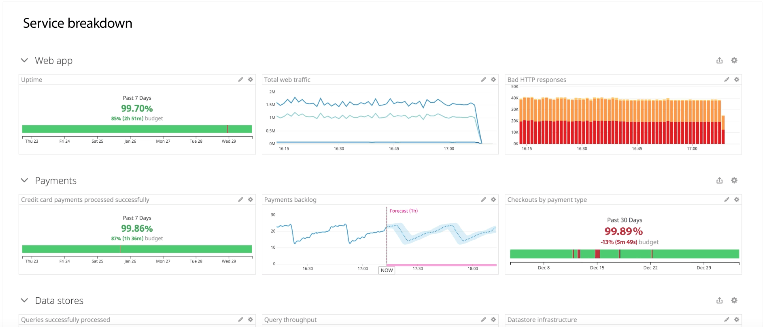
ただし、SLIとして用いるMonitorsが正しい指標となっていなければ、SLOを達成できているとは言えないので注意が必要です。
SLOとかSLIってなんや...
少し道を外れて、これまたChatGPTの力を借りて説明します。
- SLA (Service Level Agreement - サービスレベル契約)
- サービス提供者と顧客との間で合意されたサービス品質に関する契約。
- SLI (Service Level Indicator - サービスレベル指標)
- サービスのパフォーマンスを測定するための具体的な指標
- SLO (Service Level Objective - サービスレベル目標)
- SLIを基に設定される具体的なサービス品質の目標
例えば
A会社がB会社のサービスを使用しているという場合、A会社とB会社がSLAを締結することがあります。
SLAの具体的な内容として「サービスの可用性99.99%」という項目があったとします。B会社はこれを守る義務があります。
SLAは法的拘束力があり、これが満たされない場合、罰則やペナルティが課されることもあります。
そのためB会社ではSLIを用い、SLOを達成できるようにシステムを運用する必要があります。
SLOは内部的なものと対外的なものに分け、対外的なSLOより内部的なSLOを高く設定するのが良いとされています。
対外的なSLOは顧客と合意した具体的なサービスレベルの目標なので、SLAの具体的な内容です。
内部的なSLOはサービス提供者内部での目標で、システムの信頼性を保つために対外的なSLOよりも高い基準を設定することが一般的です。これにより、障害が発生した際にサービスレベルを維持するためのバッファを確保します。
とまあ障害など何かあったときに、SLAを担保できているかどうかを確認する必要が出てくるわけですが、このようにdatadogを活用していれば、さくっと確認できるようになりそうですね。
Integrations
datadogと連携したいサービスを確認することができます。
ここでslack通知に関しての設定をできます。

注意!
datadogを使う上で注意したいことがあります。
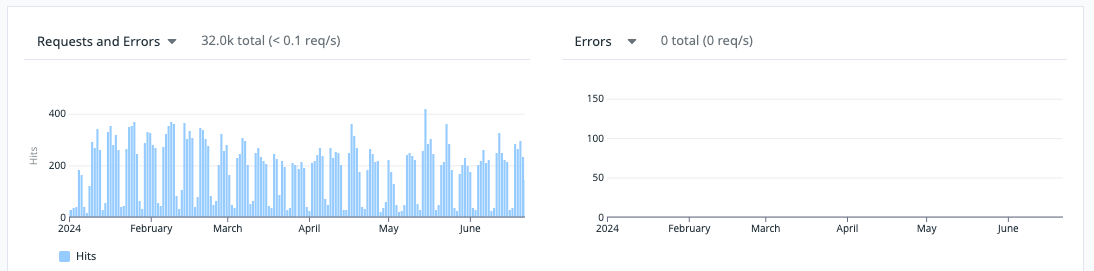
この画像はある処理のサーバーへのリクエストの結果をメトリクスとして表示しているグラフになります。
半年遡って、Errorsが0件です、なんと優秀なサービスなんでしょう...!!!
んなわけあるか!ということで、なんでErrorsが0件になっているか確認してみたところ、このようなカラクリとなっていました。
- ある処理のリクエスト→正常終了→302リダイレクト→リダイレクト先のページへ
- ある処理のリクエスト→異常終了→302リダイレクト→エラーのページへ
これではリクエストが正常終了したのか、異常終了したのか、HTTPステータスコードで区別できないため、datadogでもエラーという判断ができません。
最近はフロントがリッチなので、APIを使うことが多く、このような問題は起きなさそうですが、気をつけたいところです。
まとめ
datadogは機能が多すぎて、使いこなすのが難しいですが、非常に優秀なツールです。
我々エンジニアの精神衛生も良い状態に保てるように、もっとお犬様を崇めていきたいと思います。

Discussion