Sentence-BERTを用いた高速な類似文書検索




概要
BERTを使って高精度な類似文書検索を実現出来ると仕事に役立つのではと思い個人的に色々と実験していたのですが、結局仕事でこれを使う機会は無さそうなので供養のために実装と実験結果を記事にしたいと思います。
この記事では、Sentence-BERT (以下、SBERTと呼ぶ) という手法について主に取り上げます。
このSBERTという手法に注目したのは単純に以下のような理由からです。
- 文書間の類似度を高精度に求めることが出来ると、高精度な類似文書検索が実現できる。
- BERTを使って文書類似度を求めると、非常に高精度だが非常に遅い。
- SBERTを用いると、高精度かつ高速に文書類似度を求めることが出来る。
本記事内では、主に以下のような話をします。
- BERTを用いた類似度計算の方法について (普通のBERTとSBERTとの比較)
- PyTorchとTransformersを用いた各手法の実装
- 実験による精度と速度の比較 (日本語データセットを使用)
実験により得られた結果と結論を先に簡単にまとめると。
- ベースラインの古典的な手法に比べ、BERTやSBERTは圧倒的に精度が高い。
- BERTを用いた場合とSBERTを用いた場合では、BERTを用いた方が高精度だがその差は僅かである。
- BERTを用いた類似文書検索は速度的に現実味に欠けるが、SBERTを使えば実現可能である。
想定読者 (過去の自分)
- 機械学習や深層学習のことはある程度知っている。
- 自然言語処理は専門外だが、趣味や仕事で触れることもあり多少は知識がある。
- BERTについてはほとんど知らないが、深層学習系のモデルの一種ということは知っている。
前提: 作ろうと思っていたアプリケーションの例
大量の文書があって、自然言語でクエリを入力するとそのクエリに類似した文書を返してくれるアプリケーションを作ろうと考えていました。
何らかの情報が文書の形で集積してはいるものの、情報を集積しているだけでそれを活用して作業改善などに役立てることはほとんど出来ていないという状況は珍しくありません。
具体的な話はしませんが自分の身の回りにもそのような状況があり、類似文書検索のような仕組みがフィットする可能性があるのではと考えていました。
BERTを用いた類似度計算の方法
まずは普通にBERTを用いた場合の類似度の計算方法について説明します。
これはとても簡単で、BERTは2つの文章を入力として受け取りそれに対して何らかの出力を返すということが出来ます。
したがって、2つの文章を入力として受け取りそれに対する類似度を出力するようにfine-tuningすればBERTを用いて類似度計算が出来ます。
以下の図はBERTの元論文に載っているものです。下側に書いてあるピンク色の四角が入力文書、上側に書いてある緑色の四角がBERTの出力です。
入力文書はトークンに分割されて渡されており、1つ1つのピンク色の四角がそのトークンに対応しています。
図から分かる通り、BERT内部で諸々の計算が行われた結果このトークンの1つ1つに対して出力を返す構造になっています。
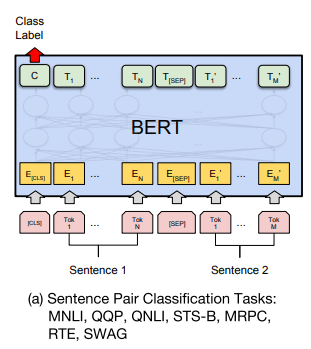
このBERTに対して2つの文章を入力する場合どうすれば良いかというと、(驚くべきことに)2つの文書を単に並べて入力すれば良いようです。
ただ、それだけだと文章の切れ目が分からなくなってしまうので、図からも分かる通り[SEP]というトークンを間に挟んで区切ることになっています。
なお、文章の初めには[CLS]というトークンを入れることになっているのですが、今回のような文章全体に対する回帰や分類のようなタスクの場合はこの[CLS]に対する出力を使うことが多いようです。[1]
詳細についてもうちょっと良く知りたいという方はBERTの元論文を読んでみてください。
こんな簡単に類似度が計算できるんだったらもうこれで良いのではという気持ちになりますが、上で述べたような文書検索にこれを使う場合1つ大きな問題があります。
類似文書の検索にこれを使おうとする場合、クエリ文書と検索対象になるデータセット内の各文書との類似度を1つ1つ計算していく必要があります。
例えば、100万件の文書が含まれているデータセットの中から自分の手持ちの文書によく似ているものを見つけたい場面について考えてみましょう。
単純に考えればBERTの推論を100万回実行して最も類似度が低い文書を選ぶ必要がありますが、BERTの推論はかなり重いのでこの手法を用いるのは現実的ではありません。
SBERTを用いた類似度計算の方法
SBERTでは上述の手法のように文章を2つ入力して類似度を計算させるのではなく、BERTを使って各々の文章からベクトルを抽出し、それらのベクトル間の類似度を用いて文章の類似度を計算します。
以下の図はSBERTの元論文から持ってきた図です。Sentence AとSentence Bという2つの文章があった時に、それぞれからBERTを使ってベクトルuとvを抽出します。
あとは、これらのベクトル間の類似度をコサイン類似度などを用いて計算すれば文章間の類似度を求められます。
ベクトル間の類似度には基本的には何を使っても良いですが、今回は元論文と同様にコサイン類似度を使用します。
なお、図中のpoolingというのはBERTの最終層で各トークンに対して抽出された出力を1つのベクトルにまとめる処理のことです。[2]

文書ベクトルの抽出にはBERTを使うが、類似度の計算にはBERTを使わないというのが重要な点です。
これにより、大量の文書に対して事前に文書ベクトルを抽出しておくことが出来ます。
検索クエリが入力された場合はそのクエリの文書ベクトルだけを抽出し、事前に抽出しておいた文書ベクトルセットからクエリとの類似度が高いものを探してくるというプロセスになります。
1回の検索に対して行うべきBERTの推論が1回だけになるので、単にBERTを使った時よりも類似文書検索を大きく高速化することが出来ます。
実験1: STSによる精度の比較
上で説明した2つの手法 (BERTとSBERT) に、ベースラインとして古典的な手法を1つ加えて、それぞれの手法の性能を比較します。
手法の比較はSTS (Semantic Textual Similarity) というNLPのタスクを用いて行います。
これは、文書のペアに対して正解となる類似度が人間の手によって付与されたデータを用いるタスクです。
「人間によって付与された類似度」と「手法によって計算された類似度」の相関係数を計算することでその手法の性能を評価します。[3]
STSのデータセットは色々とあるようですが、日本語の文書への適用を想定するなら当然日本語のデータで実験する方が良いので、今回はJGLUEという日本語のデータセットを使用することにしました。
このJGLUEの中に、JSTSというSTSのデータセットが含まれているので本稿ではこれを使います。
JSTSは文章のペアとその類似度が各行に含まれた表形式のデータになっています。
類似度の値は0から5までで、0は全く異なる意味のペア、5は完全に同じ意味のペアという意味になります。
例えば、JSTSの中で以下の文章ペアの類似度は4.4と評価されています。
- 街中の道路を大きなバスが走っています。
- 道路を大きなバスが走っています。
実行環境
実験に用いたマシンのスペックと、使用した主要なパッケージのバージョンは以下の通りです。
- OS: Windows11
- CPU: Core i7-12700
- GPU: RTX 3060
- Python: 3.10.8
- PyTorch: 1.12.1+cu116
- Transformers: 4.23.1
各手法の実装
実験により比較する3手法の実装を以下に示します。各手法とも独立したPythonスクリプトとして実装しているので、どれか1つの手法に興味があるという場合はそれだけを読んでも理解できるようになっています。
1. BERTを用いたSTS
BERTを用いたSTSの実装には、PyTorchとTransformesを用いました。
なお、以下のスクリプトはCUDAが使える環境で実行されましたが、CUDAが使えない場合はUSE_CUDAという変数をFalseにすることでCPU版のpytorchでも実行することが出来ます。
BATCH_SIZEやNUM_EPOCHSなどのパラメータは適当に調整して使ってください。
BERTを用いたSTSの実装
from datetime import datetime
from pathlib import Path
import numpy as np
import pandas as pd
from scipy import stats
import torch
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from transformers import AutoTokenizer, AutoModelForSequenceClassification
MODEL_NAME = 'cl-tohoku/bert-base-japanese-whole-word-masking'
BATCH_SIZE = 64
MAX_LENGTH = 128
NUM_EPOCHS = 10
USE_CUDA = True
np.random.seed(20221026)
torch.manual_seed(20221027)
ROOTDIR = Path(__file__).resolve().parent
TRAIN_DATA_PATH = ROOTDIR / 'data' / 'jsts-v1.0' / 'train-v1.0.json'
VALID_DATA_PATH = ROOTDIR / 'data' / 'jsts-v1.0' / 'valid-v1.0.json'
def load_data() -> tuple[pd.DataFrame, pd.DataFrame, pd.DataFrame]:
df_train = pd.read_json(TRAIN_DATA_PATH, lines=True).set_index('sentence_pair_id')
df_test = pd.read_json(VALID_DATA_PATH, lines=True).set_index('sentence_pair_id')
random_idx = np.random.permutation(len(df_train))
n_train = int(len(df_train) * 0.8)
df_train, df_valid = df_train.iloc[random_idx[:n_train]], df_train.iloc[random_idx[n_train:]]
return df_train, df_valid, df_test
def encode_input(df: pd.DataFrame, tokenizer: AutoTokenizer) -> list[dict[str, torch.Tensor]]:
sentence1 = df.sentence1.tolist()
sentence2 = df.sentence2.tolist()
encoded_input = tokenizer(
sentence1, sentence2,
max_length=MAX_LENGTH,
padding='max_length',
truncation=True,
return_tensors='pt',
)
dataset_for_loader = []
for i in range(len(df)):
d = {k: v[i] for k, v in encoded_input.items()}
d['labels'] = torch.tensor(df.label.iloc[i], dtype=torch.float32)
dataset_for_loader.append(d)
return dataset_for_loader
def get_data_loaders(df_train, df_valid, df_test, tokenizer):
train_encoded_input = encode_input(df_train, tokenizer)
valid_encoded_input = encode_input(df_valid, tokenizer)
test_encoded_input = encode_input(df_test, tokenizer)
train_dataloader = DataLoader(train_encoded_input, batch_size=BATCH_SIZE, shuffle=True)
valid_dataloader = DataLoader(valid_encoded_input, batch_size=BATCH_SIZE)
test_dataloader = DataLoader(test_encoded_input, batch_size=BATCH_SIZE)
return train_dataloader, valid_dataloader, test_dataloader
def train_step(model, batch, optimizer):
model.train()
if USE_CUDA:
batch = {k: v.cuda() for k, v in batch.items()}
output = model(**batch)
optimizer.zero_grad()
loss = output.loss
loss.backward()
optimizer.step()
SUMMARY_WRITER.add_scalar('train/loss', loss.item(), GLOBAL_STEP)
return loss
def evaluate_model(model, dataloader):
model.eval()
y_test, y_pred = [], []
with torch.no_grad():
total_loss = 0
for batch in dataloader:
if USE_CUDA:
batch = {k: v.cuda() for k, v in batch.items()}
output = model(**batch)
# loss
loss = output.loss
total_loss += loss.item()
# correlations
y_test.append(batch['labels'].tolist())
y_pred.append(output.logits.flatten().tolist())
y_test = sum(y_test, [])
y_pred = sum(y_pred, [])
loss = total_loss / len(dataloader)
pearsonr = stats.pearsonr(y_test, y_pred)[0]
spearmanr = stats.spearmanr(y_test, y_pred).correlation
return loss, pearsonr, spearmanr
def validate_and_savemodel(model, dataloader, max_valid_spearmanr):
loss, pearsonr, spearmanr = evaluate_model(model, dataloader)
SUMMARY_WRITER.add_scalars(
'valid',
{'loss': loss, 'pearsonr': pearsonr, 'spearmanr': spearmanr},
GLOBAL_STEP,
)
if spearmanr > max_valid_spearmanr:
print(f'Saved model with spearmanr: {spearmanr:.4f} <- {max_valid_spearmanr:.4f}')
model.save_pretrained('best_bert_model')
return loss, pearsonr, spearmanr
if __name__ == '__main__':
# 開始
start_time = datetime.now()
SUMMARY_WRITER = SummaryWriter(log_dir='bert_experiment')
# データとモデルのロード
df_train, df_valid, df_test = load_data()
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForSequenceClassification.from_pretrained(MODEL_NAME, num_labels=1, problem_type='regression')
if USE_CUDA:
model = model.cuda()
# モデルの学習
max_valid_spearmanr = float('-inf')
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5)
train_dataloader, valid_dataloader, test_dataloader = get_data_loaders(df_train, df_valid, df_test, tokenizer)
for epoch in range(NUM_EPOCHS):
for i, batch in enumerate(train_dataloader):
GLOBAL_STEP = epoch * len(train_dataloader) + i
_ = train_step(model, batch, optimizer)
# validation step
if i % 10 == 0:
loss, pearsonr, spearmanr = validate_and_savemodel(model, valid_dataloader, max_valid_spearmanr)
print(f'[epoch: {epoch}, iter: {i}] loss: {loss:.4f}, pearsonr: {pearsonr:.4f}, spearmanr: {spearmanr:.4f}')
max_valid_spearmanr = max(max_valid_spearmanr, spearmanr)
# モデルのテスト
_, _, _ = validate_and_savemodel(model, valid_dataloader, max_valid_spearmanr)
model = AutoModelForSequenceClassification.from_pretrained('best_bert_model')
if USE_CUDA:
model = model.cuda()
loss, pearsonr, spearmanr = evaluate_model(model, test_dataloader)
print(f'[Best model] loss: {loss:.4f}, pearsonr: {pearsonr:.4f}, spearmanr: {spearmanr:.4f}')
# [Best model] loss: 0.4071, pearsonr: 0.9013, spearmanr: 0.8571
# 終了
SUMMARY_WRITER.close()
end_time = datetime.now()
print(f'実行時間: {(end_time - start_time).seconds} 秒')
# 実行時間: 2926 秒
JGLUEの論文中ではtrain/dev/testという3つのセットが実験に使われているようなのですが、
本記事を書いている現在ではtrainとvalidという2つのセットしか公開されていないようなので、trainセットを2つに分割してtrainセットとvalidセットを作ってそれを学習に用いることにしています。
validセットは本来はvalidationに用いるものだと思いますが、このままだとtestセットが用意できないのでとりあえずこれをtestセットとして使っています。
validationの際にはvalidセットを用いてモデルが予測した類似度と正解の類似度とのSpearman相関係数を計算しています。
計算したSpearman相関係数が最大値となった場合はモデルを保存して、testセットで評価を行う際には相関係数が最大となったモデルを使うようにしています。
2. SBERTを用いたSTS
SBERTもBERTと同じくPyTorchとTransformersを用いて実装しています。
BERTの実装と比べてそれほど大きな違いはありませんが、以下のような違いがあります。
- コサイン類似度で回帰を行うため、[0, 5]の値をとる類似度を[0, 1]にスケーリングしている。
- BERTの時は
tokenizerで2つの文を同時にトークナイズしていたが、SBERTでは別々にトークナイズしてモデルに入力する。 -
forwardでは、BERTを使って2つの文をそれぞれ文書ベクトルに変換し、それらのコサイン類似度を返す。
SBERTを用いたSTSの実装
from datetime import datetime
from pathlib import Path
import numpy as np
import pandas as pd
from scipy import stats
import torch
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from transformers import AutoTokenizer, AutoModel
MODEL_NAME = 'cl-tohoku/bert-base-japanese-whole-word-masking'
BATCH_SIZE = 64
MAX_LENGTH = 64
NUM_EPOCHS = 10
USE_CUDA = True
np.random.seed(20221024)
torch.manual_seed(20221025)
ROOTDIR = Path(__file__).resolve().parent
TRAIN_DATA_PATH = ROOTDIR / 'data' / 'jsts-v1.0' / 'train-v1.0.json'
VALID_DATA_PATH = ROOTDIR / 'data' / 'jsts-v1.0' / 'valid-v1.0.json'
def load_data() -> tuple[pd.DataFrame, pd.DataFrame, pd.DataFrame]:
df_train = pd.read_json(TRAIN_DATA_PATH, lines=True).set_index('sentence_pair_id')
df_test = pd.read_json(VALID_DATA_PATH, lines=True).set_index('sentence_pair_id')
# コサイン類似度で回帰するために、[0, 5] の値を [0, 1] にスケーリングする
df_train['label'] = df_train['label'] / 5.0
df_test['label'] = df_test['label'] / 5.0
random_idx = np.random.permutation(len(df_train))
n_train = int(len(df_train) * 0.8)
df_train, df_valid = df_train.iloc[random_idx[:n_train]], df_train.iloc[random_idx[n_train:]]
return df_train, df_valid, df_test
def encode_single_sentences(sentences: pd.Series, tokenizer: AutoTokenizer) -> list[dict[str, torch.Tensor]]:
encoded_input = tokenizer(
sentences.tolist(),
max_length=MAX_LENGTH,
padding='max_length',
truncation=True,
return_tensors='pt',
)
return encoded_input
def encode_input(df: pd.DataFrame, tokenizer: AutoTokenizer) -> list[dict[str, torch.Tensor]]:
encoded_input1 = encode_single_sentences(df['sentence1'], tokenizer)
encoded_input2 = encode_single_sentences(df['sentence2'], tokenizer)
dataset_for_loader = []
for i in range(len(df)):
d1 = {f'{k}_1': v[i] for k, v in encoded_input1.items()}
d2 = {f'{k}_2': v[i] for k, v in encoded_input2.items()}
d = d1 | d2
d['labels'] = torch.tensor(df.label.iloc[i], dtype=torch.float32)
dataset_for_loader.append(d)
return dataset_for_loader
def get_data_loaders(df_train, df_valid, df_test, tokenizer):
train_encoded_input = encode_input(df_train, tokenizer)
valid_encoded_input = encode_input(df_valid, tokenizer)
test_encoded_input = encode_input(df_test, tokenizer)
train_dataloader = DataLoader(train_encoded_input, batch_size=BATCH_SIZE, shuffle=True)
valid_dataloader = DataLoader(valid_encoded_input, batch_size=BATCH_SIZE)
test_dataloader = DataLoader(test_encoded_input, batch_size=BATCH_SIZE)
return train_dataloader, valid_dataloader, test_dataloader
class SentenceBert(torch.nn.Module):
def __init__(self):
super().__init__()
self.bert = AutoModel.from_pretrained(MODEL_NAME)
def forward(self, batch: dict[str, torch.Tensor]):
# vector1
batch1 = {k[:-2]: v for k, v in batch.items() if k.endswith('_1')}
output1 = self.bert(**batch1)
vector1 = self._mean_pooling(output1, batch1['attention_mask'])
# vector2
batch2 = {k[:-2]: v for k, v in batch.items() if k.endswith('_2')}
output2 = self.bert(**batch2)
vector2 = self._mean_pooling(output2, batch2['attention_mask'])
cosine_similarity = torch.nn.functional.cosine_similarity(vector1, vector2)
return cosine_similarity
def _mean_pooling(self, bert_output, attention_mask):
token_embeddings = bert_output.last_hidden_state
attention_mask = attention_mask.unsqueeze(-1)
return torch.sum(token_embeddings * attention_mask, 1) / torch.clamp(attention_mask.sum(axis=1), min=1)
def train_step(model, batch, optimizer):
model.train()
if USE_CUDA:
batch = {k: v.cuda() for k, v in batch.items()}
cosine_similarity = model(batch)
loss = torch.nn.functional.mse_loss(cosine_similarity, batch['labels'])
optimizer.zero_grad()
loss.backward()
optimizer.step()
SUMMARY_WRITER.add_scalar('train/loss', loss.item(), GLOBAL_STEP)
return loss
def evaluate_model(model, dataloader):
model.eval()
y_test, y_pred = [], []
with torch.no_grad():
total_loss = 0
for batch in dataloader:
if USE_CUDA:
batch = {k: v.cuda() for k, v in batch.items()}
cosine_similarity = model(batch)
# loss
loss = torch.nn.functional.mse_loss(cosine_similarity, batch['labels'])
total_loss += loss.item()
# correlations
y_test.append(batch['labels'].tolist())
y_pred.append(cosine_similarity.tolist())
y_test = sum(y_test, [])
y_pred = sum(y_pred, [])
loss = total_loss / len(dataloader)
pearsonr = stats.pearsonr(y_test, y_pred)[0]
spearmanr = stats.spearmanr(y_test, y_pred).correlation
return loss, pearsonr, spearmanr
def validate_and_savemodel(model, dataloader, max_valid_spearmanr):
loss, pearsonr, spearmanr = evaluate_model(model, dataloader)
SUMMARY_WRITER.add_scalars(
'valid',
{'loss': loss, 'pearsonr': pearsonr, 'spearmanr': spearmanr},
GLOBAL_STEP,
)
if spearmanr > max_valid_spearmanr:
print(f'Saved model with spearmanr: {spearmanr:.4f} <- {max_valid_spearmanr:.4f}')
torch.save(model.state_dict(), 'best_sentence_bert_model.bin')
return loss, pearsonr, spearmanr
if __name__ == '__main__':
# 開始
start_time = datetime.now()
SUMMARY_WRITER = SummaryWriter(log_dir='sentence_bert_experiment')
# データとモデルのロード
df_train, df_valid, df_test = load_data()
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = SentenceBert()
if USE_CUDA:
model = model.cuda()
# モデルの学習
max_valid_spearmanr = float('-inf')
optimizer = torch.optim.Adam(model.parameters(), lr=2e-5)
train_dataloader, valid_dataloader, test_dataloader = get_data_loaders(df_train, df_valid, df_test, tokenizer)
for epoch in range(NUM_EPOCHS):
for i, batch in enumerate(train_dataloader):
GLOBAL_STEP = epoch * len(train_dataloader) + i
_ = train_step(model, batch, optimizer)
# validation step
if i % 10 == 0:
loss, pearsonr, spearmanr = validate_and_savemodel(model, valid_dataloader, max_valid_spearmanr)
print(f'[epoch: {epoch}, iter: {i}] loss: {loss:.4f}, pearsonr: {pearsonr:.4f}, spearmanr: {spearmanr:.4f}')
max_valid_spearmanr = max(max_valid_spearmanr, spearmanr)
# モデルのテスト
_, _, _ = validate_and_savemodel(model, valid_dataloader, max_valid_spearmanr)
model.load_state_dict(torch.load('best_sentence_bert_model.bin'))
loss, pearsonr, spearmanr = evaluate_model(model, test_dataloader)
print(f'[Best model] loss: {loss:.4f}, pearsonr: {pearsonr:.4f}, spearmanr: {spearmanr:.4f}')
# [Best model] loss: 0.0223, pearsonr: 0.8759, spearmanr: 0.8328
# 終了
SUMMARY_WRITER.close()
end_time = datetime.now()
print(f'実行時間: {(end_time - start_time).seconds} 秒')
# 実行時間: 2791 秒
基本的には論文で読んだ内容をそのまま実装しただけという感じです。
唯一どうするか悩んだのは、コサイン類似度で回帰をする場合に正解データの類似度をどうスケーリングするかという部分です。
コサイン類似度は[-1, 1]の値をとるので、正解の類似度も[-1, 1]にスケーリングしそうになりますが、以下のように[0, 1]にスケーリングするのが良いです。[4]
# コサイン類似度で回帰するために、[0, 5] の値を [0, 1] にスケーリングする
df_train['label'] = df_train['label'] / 5.0
df_test['label'] = df_test['label'] / 5.0
コサイン類似度は0の時は直交、-1の時は逆向きのベクトルという意味になるわけですが、
STSの類似度0は逆向きというよりかは直交しているという意味だと思うので、[0, 1]にスケーリングするというのは感覚的にも合っているでしょう。(感覚的な話ですみませんが。)
実際、SBERTの論文の著者の方の実装を見てもSTSの実験では[0, 1]にスケーリングしているようだったので、そういう意味でも間違いないと思われます。
3. 名詞の頻度ベクトルとコサイン類似度を用いたSTS
最後に、BERTやSBERTと比較する目的で、古典的な手法を用いた実験も行いました。
手法の概要は以下の通りです。
- 文章を形態素解析して名詞のみ抽出する。
- 名詞の頻度ベクトルを作成して文書ベクトルとする。
- 文書ベクトル間のコサイン類似度を文書間の類似度とする。
名詞の頻度ベクトルとコサイン類似度を用いたSTSの実装
from datetime import datetime
from pathlib import Path
import re
import unicodedata
from janome.tokenizer import Tokenizer
import numpy as np
import pandas as pd
from scipy import stats
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
ROOTDIR = Path(__file__).resolve().parent
TRAIN_DATA_PATH = ROOTDIR / 'data' / 'jsts-v1.0' / 'train-v1.0.json'
VALID_DATA_PATH = ROOTDIR / 'data' / 'jsts-v1.0' / 'valid-v1.0.json'
TOKENIZER = Tokenizer()
def load_data() -> tuple[pd.DataFrame, pd.DataFrame, pd.DataFrame]:
df_train = pd.read_json(TRAIN_DATA_PATH, lines=True).set_index('sentence_pair_id')
df_test = pd.read_json(VALID_DATA_PATH, lines=True).set_index('sentence_pair_id')
random_idx = np.random.permutation(len(df_train))
n_train = int(len(df_train) * 0.8)
df_train, df_valid = df_train.iloc[random_idx[:n_train]], df_train.iloc[random_idx[n_train:]]
return df_train, df_valid, df_test
def _preprocessor(text: str) -> str:
text = unicodedata.normalize('NFKC', text)
text = re.sub(r'\s', '', text)
return text
def tokenize(text: str) -> list[str]:
token_list = [
token.base_form
for token in TOKENIZER.tokenize(text)
if token.part_of_speech.split(',')[0] == '名詞'
]
return token_list
class BaselineModel:
def __init__(self):
self.cv = CountVectorizer(
preprocessor=_preprocessor,
tokenizer=tokenize,
token_pattern=None, # Note: tokenizer を設定すると UserWarning が出るので token_pattern=None としておく
)
def fit(self, texts):
self.cv.fit(texts)
def transform(self, texts):
return self.cv.transform(texts)
def get_similarity(self, sentence1: str, sentence2: str) -> float:
vector1 = self.transform([sentence1])
vector2 = self.transform([sentence2])
similarity = cosine_similarity(vector1, vector2)
return similarity[0][0]
if __name__ == '__main__':
# 開始
start_time = datetime.now()
# データの読み込み
df_train, df_valid, df_test = load_data()
df_train = pd.concat([df_train, df_valid]) # validation しないので validation セットも学習に使う
# vectorizerの学習
cv = BaselineModel()
cv.fit(pd.concat([df_train['sentence1'], df_train['sentence2']]))
# 類似度の計算と評価
df_result = df_test.copy()
df_result['similarity'] = df_result.apply(
lambda row: cv.get_similarity(row['sentence1'], row['sentence2']),
axis=1,
)
spearmanr = stats.spearmanr(df_result['label'], df_result['similarity'])
pearsonr = stats.pearsonr(df_result['label'], df_result['similarity'])
print(f'Pearson/Spearman: {pearsonr[0]:.4f}/{spearmanr.correlation:.4f}') # Pearson/Spearman: 0.6696/0.6529
# 終了
end_time = datetime.now()
print(f'実行時間: {(end_time - start_time).seconds} 秒') # 実行時間: 18 秒
名詞のみ抽出しているのは、頻度ベクトルの作成法を何パターンか試した中で名詞だけ使うのが最も精度が高かったからです。
単純な手法ですが、後々デモでも示すようになかなか良い感じに類似文書を検索してくれます。
実験結果
上で説明した各スクリプトを実行したところ、以下の結果が得られました。
JGLUEの論文に合わせてPearson相関係数も一応載せていますが、今回の場合はSpearman相関係数の方が指標として適切だと思うので以下ではSpearman相関係数のみに注目します。[5]
| 手法 | Pearson相関係数 | Spearman相関係数 |
|---|---|---|
| BERT | 0.9013 | 0.8571 |
| SBERT | 0.8759 | 0.8328 |
| ベースライン | 0.6696 | 0.6529 |
ベースライン手法のSpearman相関係数が0.6529なのに対し、BERTとSBERTはそれぞれ0.8571, 0.8328という結果になりました。
さすがにBERTの方が精度は高いのですが、個人的な印象としてはSBERTもかなり健闘したなと感じています。
そして、この結果はSBERTの元論文とも同様の結果 [6] なので、とりあえず実装としては上手くいっていると思って良さそうです。
参考として、JGLUEの論文におけるJSTSの実験結果も以下に抜粋します。
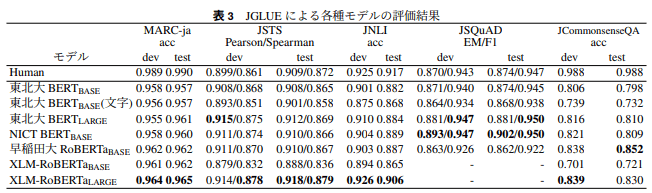
この表から、今回の実験結果に関係のあるJSTSの結果のみを抜粋すると以下のようになります。
| 手法 | Pearson相関係数 | Spearman相関係数 |
|---|---|---|
| Human | 0.909 | 0.872 |
| 東北大BERT(BASE) | 0.908 | 0.865 |
Humanは論文中ではヒューマンスコアと呼ばれていますが、これはおそらく人間がBERTと同じタスクを行った場合の結果です。[7]
そして東北大BERT(BASE)は、今回の実験でも使用したBERTのモデルです。
実験条件に色々と違いはありますが、本実験(0.857)と元論文(0.865)で大体同じくらいの値が得られており、こちらも概ね元論文の結果を再現出来ていそうです。
実際に検索に使うとどうなるか
BERTやSBERTの精度が高いことが数値的には確認できましたが、そうなると実際に検索に使った場合にどうなるか気になるところです。
ここでは、以下の3つの文をクエリとしてJSTSのテストデータに対して検索を行い、各手法の上位10件の結果を見てみることにします。
- 湖の側の草むらで、3頭の馬が草を食べています。
- 海の近くの牧場で、牛たちが何かを食べています。
- 湖の側の草むらで、3頭の馬が草を食べていません。
実験に使ったコードはこちらです。
検索に使ったコード
from pathlib import Path
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
import torch
from torch.utils.data import DataLoader
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from baseline_experiment import BaselineModel
from sentence_bert_experiment import SentenceBert, encode_single_sentences
USE_CUDA = True
BATCH_SIZE = 64
MAX_LENGTH = 128
MODEL_NAME = 'cl-tohoku/bert-base-japanese-whole-word-masking'
ROOTDIR = Path(__file__).resolve().parent
TRAIN_DATA_PATH = ROOTDIR / 'data' / 'jsts-v1.0' / 'train-v1.0.json'
VALID_DATA_PATH = ROOTDIR / 'data' / 'jsts-v1.0' / 'valid-v1.0.json'
def load_test_texts():
df_test = pd.read_json(VALID_DATA_PATH, lines=True).set_index('sentence_pair_id')
test_texts = pd.concat([df_test['sentence1'], df_test['sentence2']])
test_texts = test_texts.drop_duplicates()
return test_texts
class BaselineSearcher:
def __init__(self, texts):
self.texts = texts
self.baseline_model = BaselineSearcher.load_baseline_model()
self.baseline_vectors = self.baseline_model.cv.transform(texts)
def search(self, query, data_size=None):
if data_size is None:
data_size = len(self.texts)
query_vector = self.baseline_model.cv.transform([query])
similarities = cosine_similarity(query_vector, self.baseline_vectors[:data_size])
df_result = pd.DataFrame({'text': self.texts.iloc[:data_size], 'similarity': similarities[0]})
return df_result.sort_values('similarity', ascending=False)
@staticmethod
def load_baseline_model():
df_train = pd.read_json(TRAIN_DATA_PATH, lines=True).set_index('sentence_pair_id')
train_texts = pd.concat([df_train['sentence1'], df_train['sentence2']])
baseline_model = BaselineModel()
baseline_model.fit(train_texts)
return baseline_model
class SentenceBertSearcher:
def __init__(self, texts):
self.texts = texts
self.tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
self.sentence_bert = SentenceBert()
self.sentence_bert.load_state_dict(torch.load('best_sentence_bert_model.bin'))
if USE_CUDA:
self.sentence_bert = self.sentence_bert.cuda()
self.sentence_bert.eval()
self.sentence_bert_vectors = self.make_sentence_vectors(texts)
def search(self, query, data_size=None):
if data_size is None:
data_size = len(self.texts)
query_vector = self.make_sentence_vectors(pd.Series([query]))
similarities = cosine_similarity(query_vector, self.sentence_bert_vectors[:data_size])
df_result = pd.DataFrame({'text': self.texts.iloc[:data_size], 'similarity': similarities[0]})
return df_result.sort_values('similarity', ascending=False)
def make_sentence_vectors(self, texts):
encoded = encode_single_sentences(texts, self.tokenizer)
dataset_for_loader = [
{k: v[i] for k, v in encoded.items()}
for i in range(len(texts))
]
sentence_vectors = []
for batch in DataLoader(dataset_for_loader, batch_size=BATCH_SIZE):
if USE_CUDA:
batch = {k: v.cuda() for k, v in batch.items()}
with torch.no_grad():
bert_output = self.sentence_bert.bert(**batch)
sentence_vector = self.sentence_bert._mean_pooling(bert_output, batch['attention_mask'])
sentence_vectors.append(sentence_vector.cpu().detach().numpy())
sentence_vectors = np.vstack(sentence_vectors)
return sentence_vectors
class BertSearcher:
def __init__(self, texts):
self.texts = texts
self.tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
self.bert = AutoModelForSequenceClassification.from_pretrained('best_bert_model')
if USE_CUDA:
self.bert = self.bert.cuda()
self.bert.eval()
def search(self, query, data_size=None):
if data_size is None:
data_size = len(self.texts)
dataloader = self.load_test_dataloader(query, self.texts.iloc[:data_size])
logits = []
for batch in dataloader:
if USE_CUDA:
batch = {k: v.cuda() for k, v in batch.items()}
with torch.no_grad():
bert_output = self.bert(**batch)
logits.append(bert_output.logits.squeeze().cpu().numpy())
df_result = pd.DataFrame({'text': self.texts.iloc[:data_size], 'similarity': np.hstack(logits)})
return df_result.sort_values('similarity', ascending=False)
def load_test_dataloader(self, query, texts):
n_texts = len(texts)
encoded_input = self.tokenizer(
[query] * n_texts, texts.tolist(),
max_length=MAX_LENGTH,
padding='max_length',
truncation=True,
return_tensors='pt',
)
dataset_for_loader = []
for i in range(n_texts):
d = {k: v[i] for k, v in encoded_input.items()}
dataset_for_loader.append(d)
return DataLoader(dataset_for_loader, batch_size=BATCH_SIZE)
def result_to_markdown_table(df_result):
result = '\n'.join(f'|{r.text}|{round(r.similarity, 3)}|' for _, r in df_result.iterrows())
return f'|text|similarity|\n|---|---|\n{result}'
def search_and_show_results(query, top_k=10):
baseline_result = baseline_seacher.search(query).head(top_k)
sentence_bert_result = sentence_bert_seacher.search(query).head(top_k)
bert_result = bert_seacher.search(query).head(top_k)
print(f'## クエリ: {query}')
print('### baseline')
print(result_to_markdown_table(baseline_result))
print()
print('### SBERT')
print(result_to_markdown_table(sentence_bert_result))
print()
print('### BERT')
print(result_to_markdown_table(bert_result))
print()
if __name__ == '__main__':
# テストデータを読み込んで検索データとして使う
test_texts = load_test_texts()
# 各手法のSearcherを作成
baseline_seacher = BaselineSearcher(test_texts)
sentence_bert_seacher = SentenceBertSearcher(test_texts)
bert_seacher = BertSearcher(test_texts)
# 検索実行
search_and_show_results('湖の側の草むらで、3頭の馬が草を食べています。')
search_and_show_results('海の近くの牧場で、牛たちが何かを食べています。') # 似たような文章だが単語が違う
search_and_show_results('湖の側の草むらで、3頭の馬が草を食べていません。') # 否定形
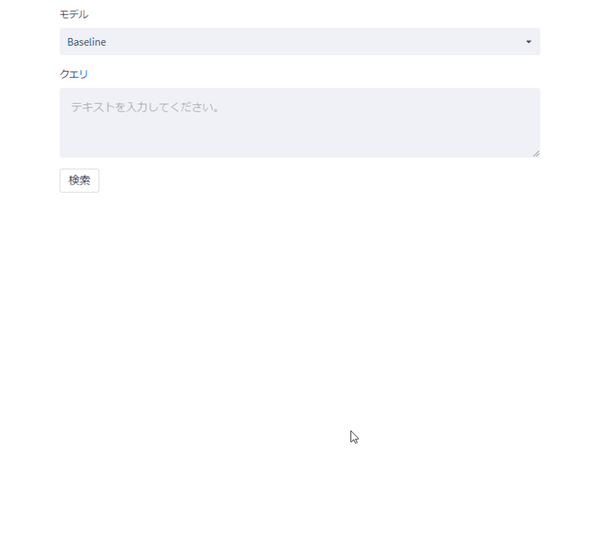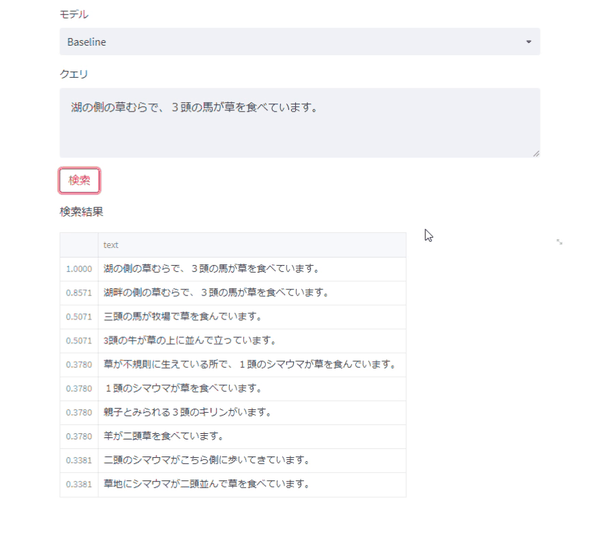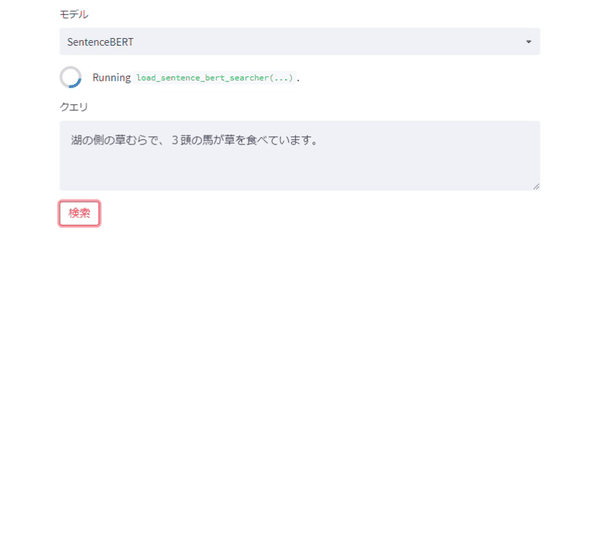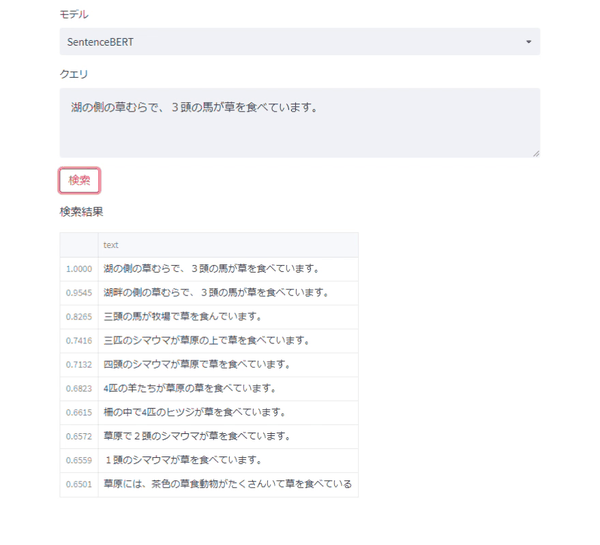
クエリ1: 湖の側の草むらで、3頭の馬が草を食べています。
まずは、普通の文章を入力してみます。
このクエリはテストデータに含まれている文章をそのまま持ってきたものです。
当然のごとく、どの手法でも最も類似度が高い文章はこのクエリと同じ文章です。
どの手法でも何となくそれらしい動物の文章が上位に来ているのが分かります。
baseline
| text | similarity |
|---|---|
| 湖の側の草むらで、3頭の馬が草を食べています。 | 1.0 |
| 湖畔の側の草むらで、3頭の馬が草を食べています。 | 0.857 |
| 三頭の馬が牧場で草を食んでいます。 | 0.507 |
| 3頭の牛が草の上に並んで立っています。 | 0.507 |
| 草が不規則に生えている所で、1頭のシマウマが草を食んでいます。 | 0.378 |
| 1頭のシマウマが草を食べています。 | 0.378 |
| 親子とみられる3頭のキリンがいます。 | 0.378 |
| 羊が二頭草を食べています。 | 0.378 |
| 二頭のシマウマがこちら側に歩いてきています。 | 0.338 |
| 草地にシマウマが二頭並んで草を食べています。 | 0.338 |
SBERT
| text | similarity |
|---|---|
| 湖の側の草むらで、3頭の馬が草を食べています。 | 1.0 |
| 湖畔の側の草むらで、3頭の馬が草を食べています。 | 0.955 |
| 三頭の馬が牧場で草を食んでいます。 | 0.827 |
| 三匹のシマウマが草原の上で草を食べています。 | 0.742 |
| 四頭のシマウマが草原で草を食べています。 | 0.713 |
| 4匹の羊たちが草原の草を食べています。 | 0.682 |
| 柵の中で4匹のヒツジが草を食べています。 | 0.661 |
| 草原で2頭のシマウマが草を食べています。 | 0.657 |
| 1頭のシマウマが草を食べています。 | 0.656 |
| 草原には、茶色の草食動物がたくさんいて草を食べている | 0.65 |
BERT
| text | similarity |
|---|---|
| 湖の側の草むらで、3頭の馬が草を食べています。 | 4.474 |
| 湖畔の側の草むらで、3頭の馬が草を食べています。 | 4.429 |
| 三頭の馬が牧場で草を食んでいます。 | 3.986 |
| 柵の中にたくさんの馬がおり、草を食べたりしています。 | 3.527 |
| 三匹のシマウマが草原の上で草を食べています。 | 3.143 |
| 四頭のシマウマが草原で草を食べています。 | 3.128 |
| どこかの山間の草原にて放し飼いにされた馬たちが餌を食べています。 | 3.103 |
| 柵の中で4匹のヒツジが草を食べています。 | 3.079 |
| 囲いのある牧草地で、放牧中の家畜が草を食べています。 | 3.074 |
| 草原で2頭のシマウマが草を食べています。 | 2.942 |
クエリ2: 海の近くの牧場で、牛たちが何かを食べています。
次に、クエリ1と似たような意味ではあるものの、使われている単語が全く異なるクエリを試してみました。
すると、baseline手法では単純に出現する単語が類似した文章を上位に持ってくるため、感覚的にはあまり似ていないような文章も上位に来てしまいました。
一方で、SBERTやBERTでは動物が何かを食べている系の文章が上位に来ていて、確かにこちらの方が類似した文章を上手くとれているような気がします。
baseline
| text | similarity |
|---|---|
| 草原に牛たちと人々が佇んでいます。 | 0.408 |
| 牧場で野放しで飼育されている馬たちがいます。 | 0.408 |
| 海辺の近くに何か物が置かれています。 | 0.408 |
| カウボーイが牛の群れの近くにいます。 | 0.408 |
| 柵で囲われた牧場に牛が数頭います。 | 0.365 |
| 海でマリンスポーツをおこなっている人たちがいます。 | 0.365 |
| 曇り空の中、海の近くで女性が傘をさして立っています。 | 0.333 |
| 子供たちが遊んでいます。 | 0.289 |
| 水辺に牛がいて、人々も牛に触ったり、水の中で遊んでいます。 | 0.289 |
| キッチンで何もせずに話している | 0.289 |
SBERT
| text | similarity |
|---|---|
| 囲いの中で黒い牛達が餌を食べています。 | 0.624 |
| 湖の側の草むらで、3頭の馬が草を食べています。 | 0.554 |
| 牧草地で羊が牧草を、食べているところです。 | 0.542 |
| フリスピーを食べてる人がいます。 | 0.515 |
| 湖畔の側の草むらで、3頭の馬が草を食べています。 | 0.507 |
| 三頭の馬が牧場で草を食んでいます。 | 0.495 |
| 4匹の羊たちが草原の草を食べています。 | 0.492 |
| 日かげでキリンがえさを食べています。 | 0.484 |
| 浜辺に人間が居る中、牛も遊んでいます。 | 0.483 |
| どこかの山間の草原にて放し飼いにされた馬たちが餌を食べています。 | 0.481 |
BERT
| text | similarity |
|---|---|
| 囲いの中で黒い牛達が餌を食べています。 | 3.187 |
| 囲いのある牧草地で、放牧中の家畜が草を食べています。 | 3.165 |
| 曇り空の山肌で、牛が2匹草を食んでいます。 | 2.738 |
| 牧草地で羊が牧草を、食べているところです。 | 2.521 |
| 三頭の馬が牧場で草を食んでいます。 | 2.473 |
| 草原に牛たちと人々が佇んでいます。 | 2.424 |
| 草原にたくさんの家畜が放牧されています。 | 2.4 |
| どこかの山間の草原にて放し飼いにされた馬たちが餌を食べています。 | 2.389 |
| 柵の中に沢山の牛が集まっています。 | 2.381 |
| 土の上でたくさんの牛が壁際に集まっています。 | 2.29 |
クエリ3: 湖の側の草むらで、3頭の馬が草を食べていません。
最後に、クエリ1とほぼ同じ内容ではあるものの、文末が否定形になっているクエリを試してみます。
baseline手法については完全にお手上げという感じで、クエリ1と全く同じ検索結果になってしまいます。[8]
一方で、SBERTとBERTではクエリ1と同じ文章が依然として上位には出てくるものの、否定形になったことにより類似度が激減したということが分かります。[9]
baseline
| text | similarity |
|---|---|
| 湖の側の草むらで、3頭の馬が草を食べています。 | 1.0 |
| 湖畔の側の草むらで、3頭の馬が草を食べています。 | 0.857 |
| 三頭の馬が牧場で草を食んでいます。 | 0.507 |
| 3頭の牛が草の上に並んで立っています。 | 0.507 |
| 草が不規則に生えている所で、1頭のシマウマが草を食んでいます。 | 0.378 |
| 1頭のシマウマが草を食べています。 | 0.378 |
| 親子とみられる3頭のキリンがいます。 | 0.378 |
| 羊が二頭草を食べています。 | 0.378 |
| 二頭のシマウマがこちら側に歩いてきています。 | 0.338 |
| 草地にシマウマが二頭並んで草を食べています。 | 0.338 |
SBERT
| text | similarity |
|---|---|
| 歩道に停めてあるオートバイにはスピードメーターが見当たりません。 | 0.724 |
| ゲームをしていません | 0.668 |
| 紙袋と傘を持った女性と2人の男性がいません。 | 0.656 |
| 建物の横に点灯していない信号機があります。 | 0.573 |
| キッチンで何もせずに話している | 0.536 |
| 整備されていない道路を自動車が走っている | 0.531 |
| 電気の点いていない信号機が立っています。 | 0.496 |
| 湖の側の草むらで、3頭の馬が草を食べています。 | 0.386 |
| 湖畔の側の草むらで、3頭の馬が草を食べています。 | 0.369 |
| サーフボードを持っている人と、持っていない人がいます。 | 0.367 |
BERT
| text | similarity |
|---|---|
| 三頭の馬が牧場で草を食んでいます。 | 3.371 |
| 柵の中にたくさんの馬がおり、草を食べたりしています。 | 3.217 |
| 湖畔の側の草むらで、3頭の馬が草を食べています。 | 2.939 |
| 湖の側の草むらで、3頭の馬が草を食べています。 | 2.885 |
| 柵の中で4匹のヒツジが草を食べています。 | 2.807 |
| 囲いのある牧草地で、放牧中の家畜が草を食べています。 | 2.637 |
| どこかの山間の草原にて放し飼いにされた馬たちが餌を食べています。 | 2.531 |
| 四頭のシマウマが草原で草を食べています。 | 2.511 |
| 三匹のシマウマが草原の上で草を食べています。 | 2.477 |
| 3頭の牛が草の上に並んで立っています。 | 2.446 |
実験2: 類似文書検索の速度の比較
実験1により、SBERTがBERTには劣るものの、かなり高い精度で文書類似度を計算できることが分かりました。
実験2では、SBERTのBERTに対する差別化ポイントであるところの検索速度の比較を行ってみたいと思います。
実験には以下のスクリプトを用いました。
from collections import defaultdict
import time
import pandas as pd
from search_demo import BaselineSearcher, BertSearcher, SentenceBertSearcher, load_test_texts
if __name__ == '__main__':
# テストデータを読み込んで検索データとして使う
test_texts = load_test_texts()
# 各手法のSearcherを作成
baseline_seacher = BaselineSearcher(test_texts)
sentence_bert_seacher = SentenceBertSearcher(test_texts)
bert_seacher = BertSearcher(test_texts)
# 検索実行
query = '大体の速度感が分かれば良いのでクエリ文字列はとりあえず何でも良い。'
data_sizes = [100, 1000, len(test_texts)]
results = defaultdict(list)
for data_size in data_sizes:
# baseline
start_time = time.time()
baseline_result = baseline_seacher.search(query, data_size=data_size)
results['baseline'].append(time.time() - start_time)
# sentence_bert
start_time = time.time()
sentence_bert_result = sentence_bert_seacher.search(query, data_size=data_size)
results['sentence_bert'].append(time.time() - start_time)
# bert
start_time = time.time()
bert_result = bert_seacher.search(query, data_size=data_size)
results['bert'].append(time.time() - start_time)
df_result = pd.DataFrame(data=results, index=data_sizes)
print(df_result)
基本的には単純に各手法を実行しているだけですが重要なポイントが1つあります。
SBERTとベースライン手法は文書ベクトルを事前に作っておけるので、クエリ文字列のベクトル化と類似度計算だけをすれば良いですが。
BERTではクエリ文字列と各文書をモデルに入れて類似度計算を行うのを検索対象の文書の数だけ行う必要があります。
上でも述べたようにBERTの処理はかなり重いので、検索時にこの処理を省略出来るSBERTの方が速度面では圧倒的に有利です。
スクリプトを実行した結果は以下の通りです。各行は速度の計測に用いたデータセットのサイズ、各列はそれぞれの手法を表しており、書かれている数字の単位は秒です。
baseline sentence_bert bert
100 0.003000 0.009000 0.426070
1000 0.003001 0.007944 4.327121
2808 0.003000 0.012244 12.080791
ベースラインとSBERTはおそらく速度が早すぎてこのくらいのデータサイズでは上手く計測が出来ていないようですが、BERTについてはデータサイズが増えるに従い線形に速度が落ちていることが分かります。
1000件のデータで4秒程度かかっていることから、100万件のデータだったら4000秒、つまり1時間以上かかってしまうことになります。
ちょっとした文書検索をするだけで1時間以上待つのはユーザー体験としては最悪なので、単純にBERTを使うのが今回の用途には適していないということがよくわかります。
ちなみに、今回の実験では分かりませんでしたが、ベースライン手法やSBERTでも今回のやり方ではデータサイズが増えるに従い線形に速度が落ちてしまうはずです。
ただ、これらの手法の場合は近似近傍探索の手法を使ってデータサイズがかなり大きくなっても高速に動くように出来ます。
なので、そういう意味でもやはり単にBERTを使うよりもこの種の手法を用いるべきだと言えるでしょう。
おまけ: 今後やろうと思っていたこと
本件は諸々の都合でボツになってしまいましたが、ボツにならなかったらやろうと思っていたことが色々とあるのでその一部を紹介します。
NLIのデータセットを用いた事前学習
SBERTの元論文では、単にSTSのデータセットを使って回帰問題として学習するだけではなく、
NLIのデータセットを使って事前学習することでSBERTの精度を上げられるということが示されています。
元論文ではこれによりSpearman相関係数が1~2ptほど上がっているので、精度にこだわるならNLIを使った事前学習も出来ればやっておきたいです。
近似近傍探索の手法を使う
SBERTがいくら早いと言っても、今回のやり方だと計算量はO(n)なのでデータサイズが増えすぎると使えなくなることに変わりはありません。
今回のような単純な全探索ではなく、近似近傍探索の手法を使えば計算量をO(1)にすることも出来るので、もっと大規模なデータにも対応できるはずです。
Triplet Loss を使った学習
今回の実験ではJSTSのような類似度のラベルが付いた文書ペアという非常に便利なデータがありました。
そのおかげで単純な回帰問題によるfine-tuningが可能になったのですが、実際の仕事ではこんな都合の良いデータはないことが多いです。
文書ペアに対して類似度のラベルを人手で大量に付与するという作業をちょっとした小さいプロジェクトで実行するのは現実的に難しいですから、何らかの代替策が欲しいところです。
そのような状況で使えるかもしれない手法が、Triplet Lossを使った学習です。
例えばSBERTの元論文では、Wikipediaの同一セクションに書かれている文同士は別のセクションに書かれている文よりも類似度が高くなるように学習を行っています。
「文章ペアの類似度はこれくらい」というデータを作るのはかなり大変ですが、「同じセクションにある文同士は似ている」のようなデータならスクリプトを書いて自動で作成できる可能性があります。
勿論このようなやり方が機能するかどうかは場合によると思いますが、そもそも学習データが存在しなければ何もできないので有用なケースも多いでしょう。
おまけ2: Streamlitを使った検索システム
完全に蛇足でしかないのですが、この記事の目的は供養なので自分用に試作した検索システムのコードも公開しておきます。
import streamlit as st
from search_demo import BaselineSearcher, BertSearcher, SentenceBertSearcher, load_test_texts
@st.cache
def load_baseline_searcher(test_texts):
return BaselineSearcher(test_texts)
@st.cache
def load_sentence_bert_searcher(test_texts):
return SentenceBertSearcher(test_texts)
@st.cache
def load_bert_searcher(test_texts):
return BertSearcher(test_texts)
if __name__ == '__main__':
# 検索対象のテキストをロード
test_texts = load_test_texts()
# セレクトボックスでモデルを選択
model_type = st.selectbox('モデル', ['Baseline', 'SentenceBERT', 'BERT'])
if model_type == 'Baseline':
searcher = load_baseline_searcher(test_texts)
elif model_type == 'SentenceBERT':
searcher = load_sentence_bert_searcher(test_texts)
else:
searcher = load_bert_searcher(test_texts)
# クエリを入力し検索ボタンを押したら検索結果を表示する
query = st.text_area('クエリ', placeholder='テキストを入力してください。')
if st.button('検索') and query:
df_result = searcher.search(query).set_index('similarity')
st.write('検索結果')
st.write(df_result.head(10))
参考文献
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
- JGLUE: 日本語言語理解ベンチマーク
-
最初見たときかなり恣意的な印象を受けましたが「そういう風に学習したからそういうものとして機能する」と言ってしまえばそれまでですね。 ↩︎
-
本記事では各トークンに対して得られた出力ベクトルを平均することで文書ベクトルとしています。SBERTの元論文でも同じ手法を用いています。 ↩︎
-
つまり、人間にとっての類似度により近い類似度を計算出来る手法ほど高い性能を持つものとみなされます。 ↩︎
-
[-1, 1]にスケーリングして学習しても全然精度が上がりません。 ↩︎
-
今回の用途では類似度が高い文書がそうでない文書より上位に来るということだけ満たされていれば十分で、2つの類似度が比例関係になっている必要性はない。 ↩︎
-
SBERTよりもBERTの方が精度が高いが、他の手法よりはSBERTの方が高いという結果。 ↩︎
-
Humanをここに載せる必要は無かったのですが、BERTと人間が同レベルであることに驚いたので載せてしまいました。 ↩︎
-
名詞しか見ていないので当然ですね。 ↩︎
-
SBERTとBERTで検索結果が大きく異なるのが興味深いですが、これについてはどっちが適切なのか判断が難しいですね。(否定形の文章に似ている文章として何が適切なのか判断に困る。) ↩︎
Discussion