今度こそ火鍋型分類機械学習モデルhotpotパッケージを実装した
概要

SojinProject, CC-BY-SA-4.0
2日遅れのエイプリルフール
要約
分類モデルとして見たロジスティック回帰の分類境界線は、『誤った図解から学ぶロジスティック回帰の性質』で指摘したように曲線ではない. 当然シグモイド曲線でもない. そこで, ロジスティック回帰に代わって, 『誤った図解から学ぶロジスティック回帰の性質』で紹介したようなS字状の分類境界線を描く分類モデルを考案し, 実装した. 現時点では R のパッケージである hotpot として配布している. パッケージ名は分類境界が火鍋に似ているためである. 現時点では改良の余地は大いにある.
[https://github.com/Gedevan-Aleksizde/hotpot]

ロジスティック回帰の図としては間違っている模式図
先行研究
以前書いた『非線形分類アルゴリズム「HotPot」を新開発しました!』はエイプリルフールなので嘘だった. S字曲線になるようなデータでしかS字状の分類境界が発生しない. 決定木で過剰適合しているだけだからである. つまり, どのようなデータに対しても火鍋のようなS字状の曲線になる分類モデルはまだ作られていないため, 今回が初の試みとなる.
次に, 火鍋型の分類境界として, 適切な曲線がなんであるかを知る必要がある. 火鍋の曲線の特定が必要である. 火鍋の形状には色々あり, 明確に決まっているようには見えない. 太極図になぞらえた形状であることは間違えないので, 太極図の曲線についても調べたが, 特定の曲線を使うことが決まっているわけでもないようだ. よって, 今回は曲線を特定せずに, いくつかの扱いやすいS字曲線を使用した.
モデル
まずは現在のモデルに至るまでに考えたことを書く. 最初はサポートベクターマシン(SVM)を拡張してできないか考えていたが, 超平面を曲面に拡張すると, 二次計画法で解けるという便利な性質が失われる. いわゆる非線形SVMはカーネル変換を使っているだけで, 超平面を変換するものではないので, カーネル変換で超平面の形状を固定するのは難しい.
結局思いつかなかったので, 大幅に制約したモデルとなった.
- 2次元の特徴量空間と2値ラベルのデータにのみ適用できる
- 所与の曲線を分類境界とし, 正答率が最大化するように回転角パラメータを学習する
- スコアを出力する機能はない
(2)の曲線のパラメータを増やすことはそこまで難しくないが, 数時間で作るのは大変なので省略した. 実装したパッケージでは, ユーザー定義の関数を曲線として指定でき, この関数は少なくとも特徴量空間上で連続である[1]ことが求められる. デフォルトでは, 位置とスケールを調整したシグモイド曲線が使われる.
それから, 目的関数は間違いなく凹関数に限定されないのでニュートン法で最適解を求められる保証はない. グリッドサーチのほうがうまくいく可能性すらある.
デモ
hotpot の依存パッケージは stats のみであるが, 以降のデモでは tidyverse, ggplot2, そして ggthemes も使っている. GitHubには, 完全なコードが掲載された, この投稿の原稿であるQMDファイルと, 実行環境の再現用ファイルがある.
require(tidyverse)
require(ggthemes)
require(hotpot)
theme_set(theme_gray(base_family = "Noto Sans CJK JP"))
boundary_logis <- function(x) hotpot::boundary_sigmoid(x, b = .2)
動作確認用のデータを2種類用意する. 1つは完全にランダムであり, もう1つはシグモイド曲線で分離できるが, 曲線が60度回転しているため, 通常のシグモイド曲線,
のスケールや位置を調整しただけではうまく当てはまらない.
bind_rows(d_random %>% mutate(data = "random"), d_60 %>% mutate(data = "60 degrees")) %>%
mutate(data = factor(data, labels = c("random", "60 degrees"))) %>%
ggplot(aes(x = x.1, y = x.2, color = y, group = data)) + geom_point() +
facet_wrap(~data) +
scale_color_manual(values = c(`FALSE` = "gray100", `TRUE` = "red3")) +
coord_fixed(xlim = c(-1.5, 1.5), ylim = c(-1.5, 1.5))
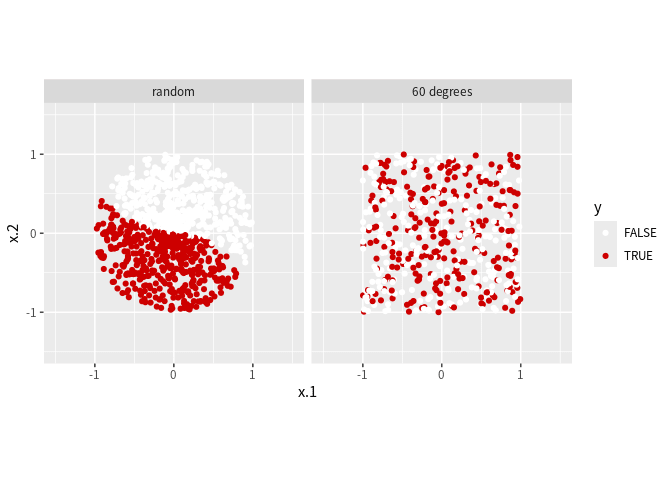
生成されたデータの散布図
だが, hotpot は回転に対応しているため, 適切に分類できるであろう.
ここで hotpot の構文を簡単に解説する. 構文は既存のRの多くの関数と同じように設計している. 例えば, 2列の行列 X を特徴量行列 y を対応する分類ラベルとする. すると, 以下のようにして学習と予測値の出力ができる.
require(hotpot)
fit <- hopot(X, y)
predict(fit)
さらに, 別の特徴量 X_new に対してラベルの予測を出力するなら, predict(fit, X_new) と書くだけである. 境界曲線は, デフォルトではロジスティックシグモイド関数が使われる. 全単射の実関数であれば boundary_function 引数に指定して, 境界線の関数を変更できる.
これが乱数生成したデータに対する当てはまりである. 点ごとに正答しているかどうかは点の形状で表している.
fit <- list(random = d_random, deg60 = d_60) %>%
map(
~hotpot(X = as.matrix(.x[, 1:2]), y = .x$y, boundary_function = boundary_logis)
)
d_result <- map2_dfr(
list(mutate(d_random, data = "random"), mutate(d_60, data = "deg60")),
fit,
~mutate(.x, p = predict(.y))
)
d_result %>%
ggplot(aes(x = x.1, y = x.2, color = y, shape = y == p, group = data)) +
geom_point() +
scale_shape_manual(
values = c(`FALSE` = 4, `TRUE` = 20)) +
facet_wrap(~data) +
scale_color_manual(values = c(`FALSE` = "gray100", `TRUE` = "red3")) +
coord_fixed(xlim = c(-1.5, 1.5), ylim = c(-1.5, 1.5))

hotpotによる予測分類
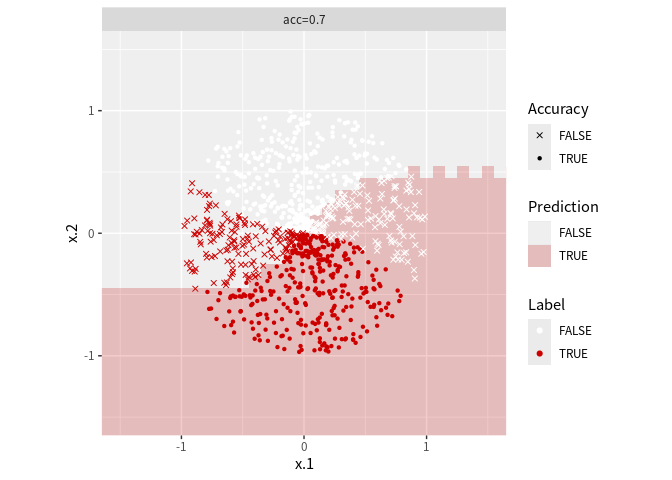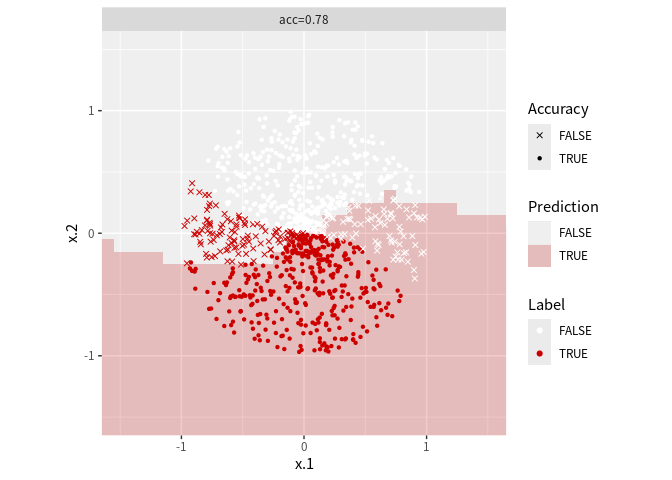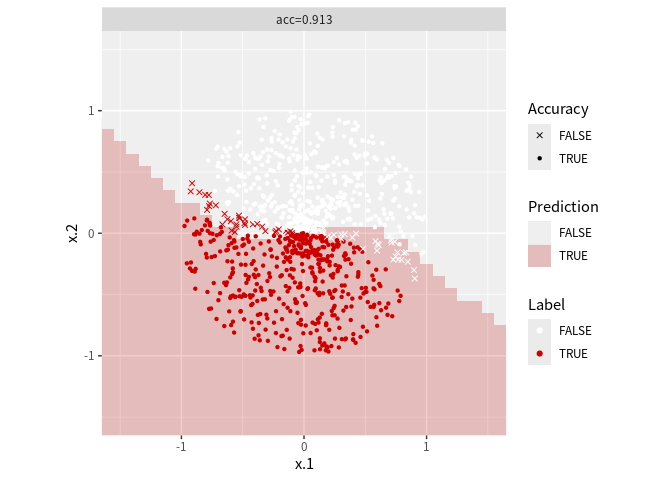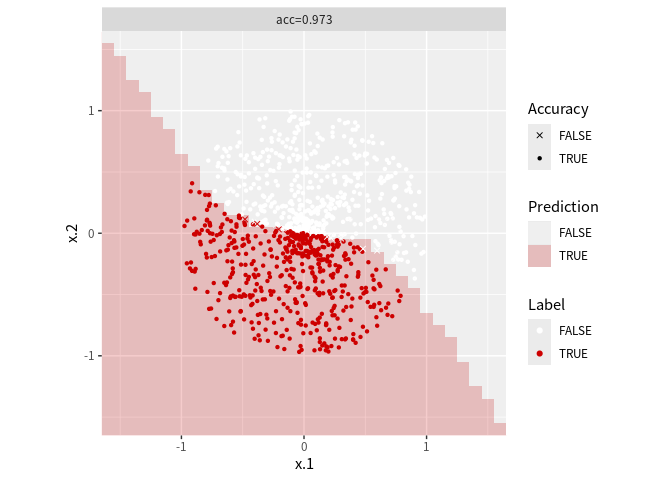
境界を表すと以下のようになる. 代数的に表示するのがめんどくさいのでグリッドで近似している. 60度回転させたケースでもうまく当てはまっていると分かる.
d_grid %>%
ggplot(aes(x = x.1, y = x.2, fill = p)) +
geom_tile(alpha = .2) +
geom_point(aes(x = x.1, y = x.2, shape = accuracy, color = y),
data = d_result %>% mutate(accuracy = y == p), inherit.aes = F) +
coord_fixed(xlim = c(-1.5, 1.5), ylim = c(-1.5, 1.5)) +
facet_wrap(~data) +
scale_color_manual(values = c(`FALSE` = "gray100", `TRUE` = "red3")) +
scale_fill_manual(values = c(`FALSE` = "gray100", `TRUE` = "red3")) +
labs(color = "Label", fill = "Prediction", shape = "Accuracy") +
scale_shape_manual(values = c(`FALSE` = 4, `TRUE` = 20)) +
coord_fixed(xlim = c(-1.5, 1.5), ylim = c(-1.5, 1.5))

分類境界の視覚化
なんか動いてる実感がないと納得しない人向けのGIFアニメ画像が以下になる.
収束してるっぽいアニメーション
もう1つ曲線を用意した. 半円を互い違いにつなげただけのものだ.
boundary_circle <- function(x) hotpot::boundary_half_circle(x)
ggplot(tibble(x.1 = c(-2, 2)), aes(x = x.1)) +
stat_function(fun = boundary_half_circle) +
labs(y = "x.2") +
coord_equal(ylim = c(-2, 2))

2つの半円を組み合わせた曲線
このように, hotpot は入力データに関係なく何が何でもS字状の分類境界を作る. なお, 回転の計算の実装が手抜きなので定義域に制約があると角部分の境界が計算できない.

半円を組み合わせた境界線を当てはめた結果
境界線に使用できる関数は, 全単射かつ
boundary_m <- function(x){
- 2 * (abs(x/2)-1/3)^2
}
ggplot(tibble(x1 = c(-2, 2)), aes(x = x1)) +
stat_function(fun = boundary_m) +
coord_equal(ylim = c(-2, 2)) +
labs(y = "x2")

変則的だが条件を満たす境界線の例

変則的な境界関数を当てはめた結果
実用的なのか?
他に使いみちがあるとは思えない. だが, 誰も参入しないブルーオーシャンなのでアルゴリズムや実装の改良案は出し放題である.
参考文献
zen.dev を使ってみた感想
本筋とは関係ないので折りたたんでいる
以降は今回の投稿内容とは直接関係ない話である. どのサービスが一番こういう技術文書を書きやすいか比較するために複数箇所に投稿しているため, レビューも残しておく. こういう話の説明文を書くには, 以下のような機能があると望ましい.
- 見出し, 段落, 強調, ハイパーリンク, 箇条書き, 脚注 (または, 傍注)のような基本的なスタイルを指定できる
- 画像を貼り付けられる
- シンプルな表を貼り付けられる
- LaTeXに準拠した構文で数式を記入できる
- プログラムや疑似コードのシンタックスハイライトがある
- 図・表・数式の相互参照ができる
- Markdownに対応している
- ブラウザを使わず, 以上のような内容の含まれる投稿を直接アップロードできる
(1)の動作は申し分ない.
(2)は, Quartoで生成したレポートだと画像ファイルの配置の位置が違うため, 手動で変更する必要があった. キャプションも独自の構文が用意されているため, Pandocフィルタか何かを作らないと手動で書くことになる.
今回の投稿には表が含まれていないので(3)は省略する.
(4)はKaTeXを使用していることから, 最低限の機能は備えている. KaTeX なので相互参照はうまくいかない.
エンジニア向けのサービスというだけあって(5)も充実していた. Prims.js というライブラリのおかげらしい. ただし, Pandocの仕様ではフェンスと言語名の間にスペースを空けて出力するため, そのままでは修飾子が認識されない.
(6)はできないようだ. ユーザー側で自動生成するプログラムを作れということだろうか. 本を書く機能もあるらしいが, 図表数式の相互参照なしの技術書や専門書を読むのは厳しいので対策が必要だろう.
(7)も当然ながら対応している.
(8)は好きなテキストエディタで書いてアップロードできるので申し分ない. 何十ページも書かこうとしたら壊れて投稿できないということもないだろう.
よって, 上記の要件のうち, (6) を満たしていない. (2, 4) にも一部不便なところがある, という結論になる.
-
入力データを [-1,1]区間にスケールするオプションがあるため, スケール後の空間上で連続であれば動作する. ↩︎
Discussion