『GoogleCloudではじめる実践データエンジニアリング入門』を読んだ
BigQueryを使ったデータエンジニアリングの概観を学びたくて読んだ。
データエンジニアリングとは、「データ基盤を構築する、管理する技術領域全般」(はじめにより)
公式のサンプルリポジトリは以下。
1. データ基盤の概要 の メモ
データウェアハウスは、分析をおもな目的としたデータベース。
データマートは、データウェアハウス上に構築されたデータを目的別に事前集計しておくことで、特定用途に対するクエリのレスポンスを向上させることが目的。
2010年以降、データ基盤に3つの変化が起こる。
- 業務システムのシステム化の加速: あらゆる業務がシステム化対象となった。
- デジタルマーケティングの発展: パーソナライズ化したコンテンテンツの提供のために、CRM、DMP,CDPといった顧客情報を管理するプラットフォームが利用される。既存の業務システムのSoR(System of Record)に加えて顧客接点システムのSoE(System of Engagement)もデータソースとして扱われるようになる。
- 非構造化データの急増: 商品マスタの画像、カスタマーセンターへの問い合わせなど、顧客システムのデジタル化により非構造化データを扱う必要
この結果、データウェアハウスを用途別に分割したり、情報系システムと密結合させたりするなど、従来のデータベースと類似した用途で使われ始める。そのため、データは一箇所に統合されずに分断して保存され、データ活用が阻害されるデータのサイロ化が発生した。
2. データウェアハウスの概念とBigQueryの利用方法 の メモ
無料で使えるBigQueryサンドボックスを利用する
クエリの最適化
最適化の際に、公式ドキュメントにあるクエリパフォーマンスの最適化をすべて網羅するのは労力に対する効果の観点からおすすめしない。
クエリを内部で最適化するオプティマイザの改善も取り込まれており、場合によっては効果が見込めない。
BigQueryのSQLのアンチパターンを検出して最適化クエリをレコメンドしてくれるツールもある。
BigQueryの内部アーキテクチャ
ストレージとコンピュートの分離
コンピュート、ストレージ、メモリの動的に割当るマルチテナント方式。Googleが事前にコンピュートリソースを確保し動的に割り当てるので、大きなクラスタのプロビジョニング不要。
コンピュート、ストレージ、メモリが分離されているため、それぞれ完全に独立してスケーリングできる。
一般的なDWHでは、ノードと呼ばれるコンピュートとストレージを合わせたリソースを横に並べ、それらをマスタが管理することで並列処理を行う。MPP(Massive Parallel Processing)と呼ぶ。
BigQueryのアーキテクチャ
- クエリエンジン: Dremel
- ハードウェアアクセラレーションネットワーク: Jupiter
- 分散ストレージ: Colossus
- 列指向ファイルフォーマット: Capacitor
分散インメモリシャッフル
分散処理においては、シャッフルと呼ばれるワーカー間におけるデータを移動する処理が発生する。
BigQueryではシャッフル処理をワーカーではなく、巨大な分散インメモリシャッフル基盤で行う。
- シャッフル機構を設けることでメッシュ状通信のオーバーヘッドを削減
- インメモリの途中状態を保管することで高速に読み出し可能
- 独自通信プロトコル、ハードウェアアクセラレーションを活用した高速な読み書き
- スケールアウトにより拡張可能
3. データウェアハウスの構築 の メモ
フェアスケジューリング
スロットとは、ワーカー上のコンピューティングユニット。
フェアスケジューリングは、スロットを予約内の実行中のクエリとともにプロジェクト間で均等に共有し、さらに特定のプロジェクトの複数ジョブでも均等に共有するように自動的に調整する。
クエリA実行中にクエリBが割り込んだとき、典型的なデータベースでは待機状態が発生するが、BigQueryではフェアスケジューリングによりクエリプランを動的に変更する。
分散インメモリシャッフル内で各ステージの途中経過を保存しているため、クエリを再割り当てできる。
サイジング
BigQueryはコンピュート、ストレージ、メモリの分離とスケールアウトにより、基本的にスロット数に従い、線形にクエリパフォーマンスが推移。
ストレージのサイジングは、Colossusのレイヤで担保されているたため、ディスクIOやディスク利用率のサイジングは不要。
データマート作成の最適化
オンプレミスからクラウドへの変化によりデータの受け渡しをオブジェクトストレージを共通で利用できるようになり、クラウドからBigQueryへの変化によりBigQueryというDWHを共通で利用できるようになった。
A) オンプレミスにおける典型的なデータの受け渡し
DWH、ストレージをそぞれで性能や責任分界点を担保するために分離。
データをコピーしていくためパイプラインが長くなり、コストもかかる。
B) クラウドにおける典型的なデータの受け渡し
クラウド事業者がサイズ、I/O含めスケールさせるオブジェクトストレージの登場。
ストレージを共通化できたがDWHはそのまま
C) BigQueryを用いたデータ共有
DWHのコンピュート、ストレージともに事業者によりスケールされ、
仮想的に1つのストレージをDWHで共有しているため共有できた。
MLBのBigQueryの導入事例。
データウェアハウスをBigQueryに移行する
BigQueryに移行する理由。
BIツールはアピールポイントではなく、今求められているのは予測分析。
4. レイクハウスの構築 の メモ
データウェアハウス
分析対象が業務アプリの構造化データに加えて、JSONなどの半構造化データや、アクセス解析の活用によるスパース(まばら)なデータに対する分析対象となる。
スパースなデータ
これにより変化した分析ニーズ
①半構造化データやスパースなデータを取り扱うファイルフォーマットの柔軟性
②半構造化データ及び非構造化データのペタバイト級のサイズのデータ(Webアクセスログなど)を扱う必要性が発生
データレイク
データレイクの技術スタックは分散ストレージを基礎として発展。
分散ストレージ(基盤):
- Hadoop Distributed File System (HDFS)
クエリエンジン(処理):
- 分散ストレージに対して処理を実行できるクエリエンジンが開発
- MapReduce
- Apache Hive
- Presto
- Apache Spark
スキーマ管理(メタデータ):
- データレイクを利用するユーザーが増えデータの複雑性やデータの検索性が課題なり、テーブルメタデータを管理するようになる。
- Apache Hive Metastore
アクセス制御(セキュリティ):
- テーブル中のデータを用いて列ベースでアクセス制御を行う
- Apache Ranger
これらの技術スタックが独立したソフトウェアとして開発され、相互に依存するため、複雑となる。
レイクハウス
構造化・非構造化データの統合: 構造化・非構造化に関わらずデータを保管し、アプリケーションに対して統合的なアクセスレイヤーを提供する。
Google CloudのDataplexでゾーンの構成を選択でき、生データとキュレートされたデータの2つのゾーンを扱える
Google Cloudのレイクハウスアーキテクチャ
ストレージ層:
- 構造化データ、半構造化データ、非構造化データなどあらゆる種類のデータを一元的に管理する
- BigLake
データ処理エンジン層:
- ストレージ層に格納されたデータを処理するためのエンジン
- BigQuery
データガバナンス層:
- データの品質、セキュリティ、アクセス制御などを管理する
- Dataplex
5. ETL/ELT処理 の メモ
BigQueryデータパイプラインの移行
ETL

ELT
BigQueryをDWHとして使用する際には、ETLではなくELTをできるかぎり採用する。
- スケーラブルなBigQuery上で、大規模なデータの変換処理を実施できる。
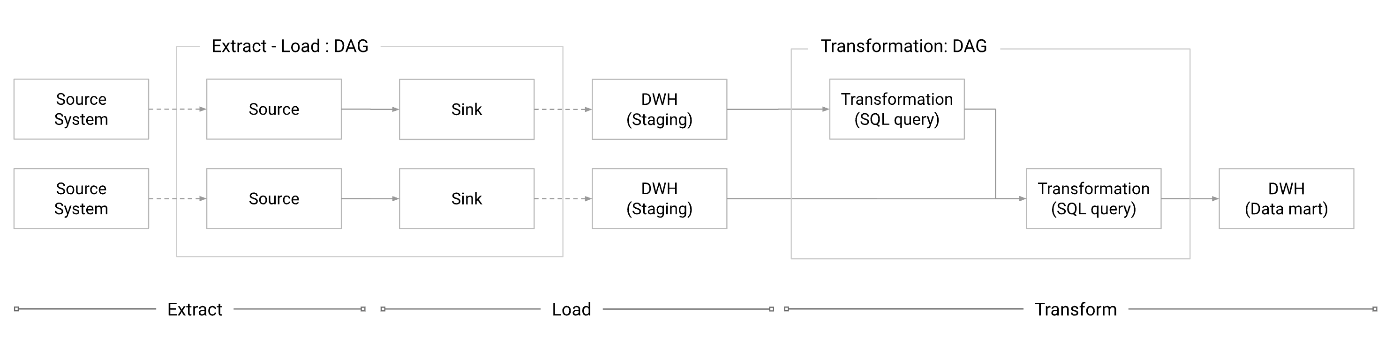
ETLとELTの使い分け
BigQueryを用いたELT
- 適応するユースケース
- SQLやstoread procedurecesで完結できるようなデータ処理である
- ストリーミングデータ処理
- ストリーミング読み込み、ストリーミングでの書き出し対応
Dataflowを用いたETL
- 適応するユースケース
- SQLで表現できないバッチ処理である。
- ストリーミング処理である
- クラスタ起動のオーバーヘッドが許容できる規模のデータ(数百GB-)である
- ストリーミングデータ処理
- ストリーミング取り込みとストリーミング中の分析が可能
Dataformを用いたELT
- 適応するユースケース:
- SQLで完結できるようなデータ処理であり、マネージドに実行をしたい
- ストリーミングデータ処理
- 不可
BigQueryを用いたELTの課題とDataform
BigQueryを用いたELTの課題
- SQLの前後関係を考慮したスケジュール実行
- SQLのバージョン管理
- 中間テーブルの依存関係の管理
- データ品質のテスト
これらの課題を管理するため、DataformはBigQuery上でデータ変換ワークフローを開発、テスト、スケジュールの設定を行うマネージドサービス。
DataflowとApacheBeam
DataflowはGoogleCloudのフルマネージドなデータ処理サービス
以下の特徴がある。
- ApacheBeamの実行環境。ストリーミングとバッチ処理の双方を1つのサービスに統合して提供
ApacheBeamはデータ処理に特化した統一プログラミングモデル。
特定のプログラミング言語ではなく、Java、Python、Goなど複数言語でBeamパイプラインを記述するためのSDKを提供。
以下の特徴がある。
- バッチとストリーミングを、同じ書き方で記述できる
- Runnerと呼ばれる実行環境で実行される(Apache Sparck、Apache Hadoop MapReduce、Apache Flink、Dataflowなど)
BigQuery data preparation
BigQuery data prepartionはデータの前処理を行うためのソリューション
6. ワークフロー管理とデータ統合 の メモ
Cloud Composer、Cloud Data Fusion、Dataformの比較
Cloud Composer
- ApacheAirflowがベースのワークフローオーケストレーション https://airflow.apache.org/
- サービスのユースケース: ワークフロー制御
- ETL/ELT処理全体のワークフロー管理を目的。
- Operatorを利用してCloud Data Fusion、Dataformも管理可能。Cloud Data Fusionで作成したETL/ELTジョブをオーケストレーションできる。
Cloud Data Fusion
- CDAPがベースのGUIを使ったETL/ELTサービス https://github.com/cdapio/cdap
- サービスのユースケース: データ統合
- GUIによるデータ統合と各種コネクタによる開発
Dataform
- SQLベースのデータ変換サービス
- サービスのユースケース: ELTのパイプライン
- BigQuery内でのデータ変換に特化
- SaaSのAPIからデータ連携をするなどSQLだけで完結しない場合は単体での運用が難しいため、Cloud Data Fusionと併用する。
7. データ分析基盤におけるセキュリティとコスト管理の設計 の メモ
階層化セキュリティ
- 認証: その人であることを確認
- 認可: 「だれが」「なにを」「いつ」の制御
- テーブル: 暗号化関数による暗号化、認可済みUDF
- ストレージ: デフォルトでストレージの暗号化、Cloud KMSを用いたユーザによる暗号鍵管理
暗号化関数に加え、暗号シュレッティングを行うことででデータの削除をより楽に行うことができる。
復号化キーを削除すれば、該当ユーザーの情報は復号負荷となり、削除したものとみなすことができる。
Apple製品でも利用されている。
8. BigQueryへのデータ集約 の メモ
BigQuery Data Transfer Service(BigQuery DTS)とCloudFunctionsを利用したデータパイプライン
- BigQuery DTSは、対応するデータソースから設定されるスケジュールでBigQueryへデータを転送するマネージドサービス
- BigQueryDTSとPub/Subを利用する方法
- BigQueryDTSはデータパイプライン上でのExtractとLoadを行う
- Pub/Subに通知された結果を受け取ったうえで、後続の処理を実行する
Dataformを利用したパイプライン
- Dataformを利用してSQLをオーケストレーションする方法
- すべてSQLでパイプラインを構築できるのであれば運用負荷は低い
CloudSchedulerやCloudComposerを利用したDataflowのジョブ管理
- Dataflowを利用する方法
- ApacheBeamによるプログラミング処理自体が1つのデータパイプラインを表現
- Dataflowにはジョブ管理のようなデータパイプランの構築に必要な機能がないため、スケジューリングや監視といった仕組みはCloudScheduler、Cloud Composerと組み合わせる
- ジョブがシンプルな場合はCloudScheduler、依存関係の管理が必要な場合はCloudComposerを利用する
9. ビジネスインテリジェンス の メモ
Googleが提供している3つのBIツール
- コネクテッドシート
- スプレッドシートベースのデータ分析ツール
- GoogleSpreadSheetの拡張機能で大量のデータを扱うことができる。Excelでは100万行程度など扱えるデータボリュームに限度がある。
- 一般的なBIツールのダッシュボード機能にあるような共通フィルタやレポート送信機能はないため、小規模組織の単位で運用。
- スプレッドシートベースのデータ分析ツール
- Looker Studio / Lookder Studio Pro
- データの可視化とレポート作成に特化したBIツール
- ダッシュボードでの分析および構築。レポート作成・配信・共有などが可能
- Looker Studio Proでエンタープライズ向けの機能(チームワークスペースなど)を提供
- 小規模からエンタープライズまで運用できる
- データの可視化とレポート作成に特化したBIツール
- Looker
- エンタープライズ向けのBIツール
- セマンティックモデルレイヤーによるデータガバナンスを必要とするエンタープライズ向け
Looker
Lookerはエンタープライズ向けのBIツールで、セマンティックモデルレイヤーによるデータガバナンス機能を提供している。
LookerMLはセマンティックモデルレイヤーをコードで定義する。
セマンティックモデルレイヤー
セマンティックモデルレイヤーは、データウェアハウスなどのデータスキーマから、分析者が直接利用できるディメンション(分析軸)と指標(測定値)を定義する。
たとえば、注文分析において、売上はキャンセルされた注文を除外して集計するといったビジネスロジックを適用する必要があるが、セマンティックモデルレイヤーではこれらの処理を事前に定義しておくことで統一的にデータ分析できる。
指標の定義や計算方法が個人に依存すると分析結果の解釈にばらつきが生じるリスクを軽減する。
- ディメンション(分析軸):
- 分析に利用する軸。ディメンションで指定した持つ値ごとにデータを分けてみることができる。
- 例えば、日時型のデータをディメンションとして選択した場合、月ごとや時間ごとのデータ分析が可能になります。
- 指標(測定値):
- グラフなどで表示される数値です。
- 例えば、注文レコードを持つテーブルにおいて、注文件数や売上金額を指標として設定することで、売上の合計や平均などを算出できる。
10. リアルタイム分析 の メモ
リアルタイム分析は、できるだけ早いアクションが求められるビジネスにおいて重要。
- Eコマースでタイムセールの最中にクーポンや広告の配信最適化を行う
- ライブストリーミング配信中に視聴者の反応を分析し、動的にコンテンツなどプログラミングを変える
サンプルコードでは、ニューヨークのリアルタイム位置情報データを使ったリアルタイム基盤の構築を紹介。
GoogleCloudを利用したリアルタイム分析のアーキテクチャ
リアルタイムデータは、バッチと異なりデータのボリュームが予測できない場合があるため、突発的なデータのバーストに安定して処理できる可用性とスケーラビリティが、データの収集、処理、蓄積、分析それぞれのプロセスにおいて必要。
GoogleCloudでは、おもに以下のサービスが提供されている。
- 収集、メッセージ: Pub/Sub
- ストリーミング処理: Dataflow
- 蓄積・分析: BigQuery
11. 発展的な分析-地理情報分析と機械学習、非構造データ分析 の メモ
Google Cloud上での機械学習
- BigQuery ML: BigQueryが提供する機械学習に関連する機能
- Vertex AI: 機械学習プラットフォーム
- Auto ML: VertextAIの一部として提供される、データ特性に応じて適切なモデルを自動で選択・学習できる機能
BigQueryMLとVertextAIを組み合わせて利用するユースケース。
・画像や音声、動画などの非構造化データをVertexAIが提供する生成AIのAPIで構造化し、その結果をBigQuery上に保存して後続の分析につなげる
BigQueryMLとVertextAIはユースケースに応じて、相互に補完する関係にある。
サンプルコードでは、BigQueryの一般公開データセットに含まれるGoogleアナリティクスのデータを利用して、ECサイトへの訪問者が商品を購入するかどうかを予測するモデルを構築する。機械学習のモデルとしては、BigQueryMLの2項ロジスティク回帰を利用する
機械学習
機械学習の詳細については下記コースを参照。
「Applying Machine Learning to Your Data with GC - 日本語版」
「Machine Learning Crash Course」
ラップアップ
BigQueryはSQLを利用してDWHから機械学習まで利用でき、ETL/ELTを構築するサービス群も豊富に提供されている。
Dataflow、Dataformなど類似のサービス名で混乱したが、DataflowはApacheBeamの実行環境など、OSSとサービスとの関係性も明記されており理解しやすい。
実際の開発手法の少ないため実務でどこから初められばいいのかは学習が必要。
参考資料
Discussion