2025年キャラクター系の論文一言まとめ(ACL, EMNLP)
こんにちは。CyberAgent AI Labの岩田と申します。
普段はReserach Engineerとして、対話システムに関連する研究開発を行っています。
本記事では私のメイン業務に関連する調査として、2025年に発表されたキャラクター対話に関する論文を簡単なまとめとともに紹介したいと思います(アブストと論文ざっくり確認程度です🙇)。
読み間違えている部分や分かりづらい部分等も多々あると思うので、ご指摘・コメント等、是非よろしくお願いします🙇♂️
2024年のキャラクター論文まとめ:https://zenn.dev/siwata_lab/articles/c8af86d59bd34b
ACL
The Essence of Contextual Understanding in Theory of Mind: A Study on Question Answering with Story Characters

既存のTheory of mind (ToM)のベンチマークは短いシナリオを使用しており、実際の人間のような長い文脈を踏まえられていないと指摘。そこで、本研究では実際の小説を用いたToMのベンチマークを構築。本ベンチマークを使用した結果、既存のLLMは人間よりも著しく劣ることが判明し、現状のLLMのLimitationも示した。
OmniCharacter: Towards Immersive Role-Playing Agents with Seamless Speech-Language Personality Interaction
キャラクターらしい音声出力までを試みた論文。離散トークンベースのSpeechLLMに、キャラクターのプロフィール情報やSpeech Query等を入れて返答に関する音声トークン列を出力。出力されたトークンベースにConditional Flow Matchingモデルによるメルスペクトログラムのサンプリング→HiFiGANによる波形生成を行う。
Beware of Your Po! Measuring and Mitigating AI Safety Risks in Role-Play Fine-Tuning of LLMs
Role-Playingに特化したFine-tuningは危険な発話を生成するリスクも上げてしまうと指摘。本研究ではRole-Playing性能と安全性の2つのバランスを意識したFine-Tuning方法を構築。LLaMA-3-8B-Instruct、Gemma-2-9B-it、Qwen2.5-7B-InstructのFFT及びLoRAで有効性を示した。
BEYOND DIALOGUE: A Profile-Dialogue Alignment Framework Towards General Role-Playing Language Model
Role-Playing対話においてLLMの入力に用いるプロファイル情報は全文は必要でないケースが存在したり、LLMがFine-grainedな理解を欠如していると指摘。本研究では各発話と理由となるプロファイルを理由付きで回答させるタスクを実施。加えて、対話中に理由として出ない必要でないプロファイル情報の削除や、必要なプロファイル情報の追加も実施。
RolePlot: A Systematic Framework for Evaluating and Enhancing the Plot-Progression Capabilities of Role-Playing Agents
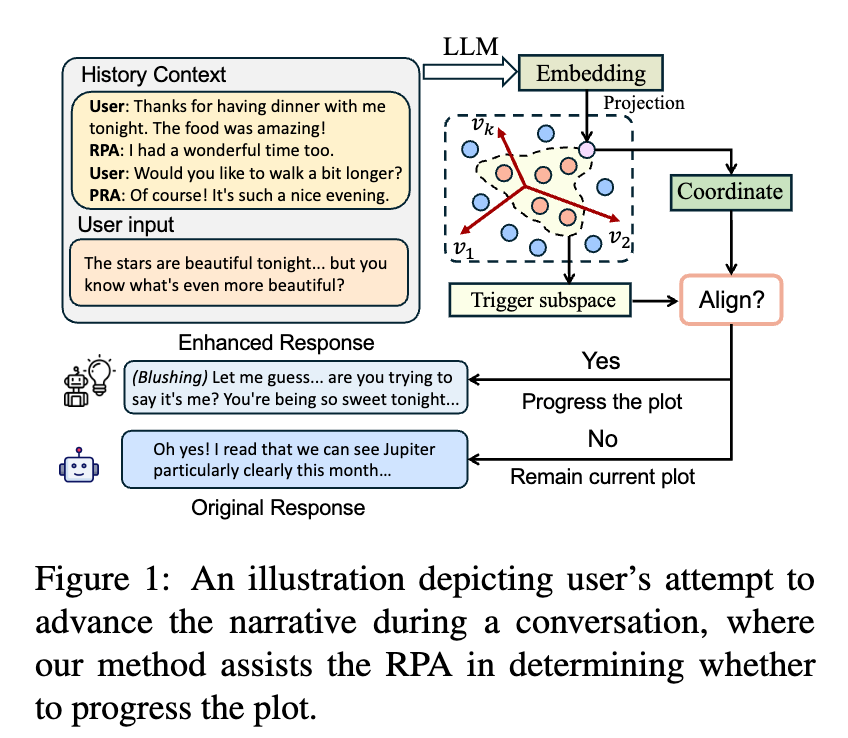
物語を進行させる転換点となる入力を検知するタスクを提案。物語の転換点に関する先行研究に従い、5人のアノテータがアノテーションした転換点データセットを構築。さらに、文埋め込みベースで転換点となる入力を検知する手法を構築。
Crab: A Novel Configurable Role-Playing LLM with Assessing Benchmark
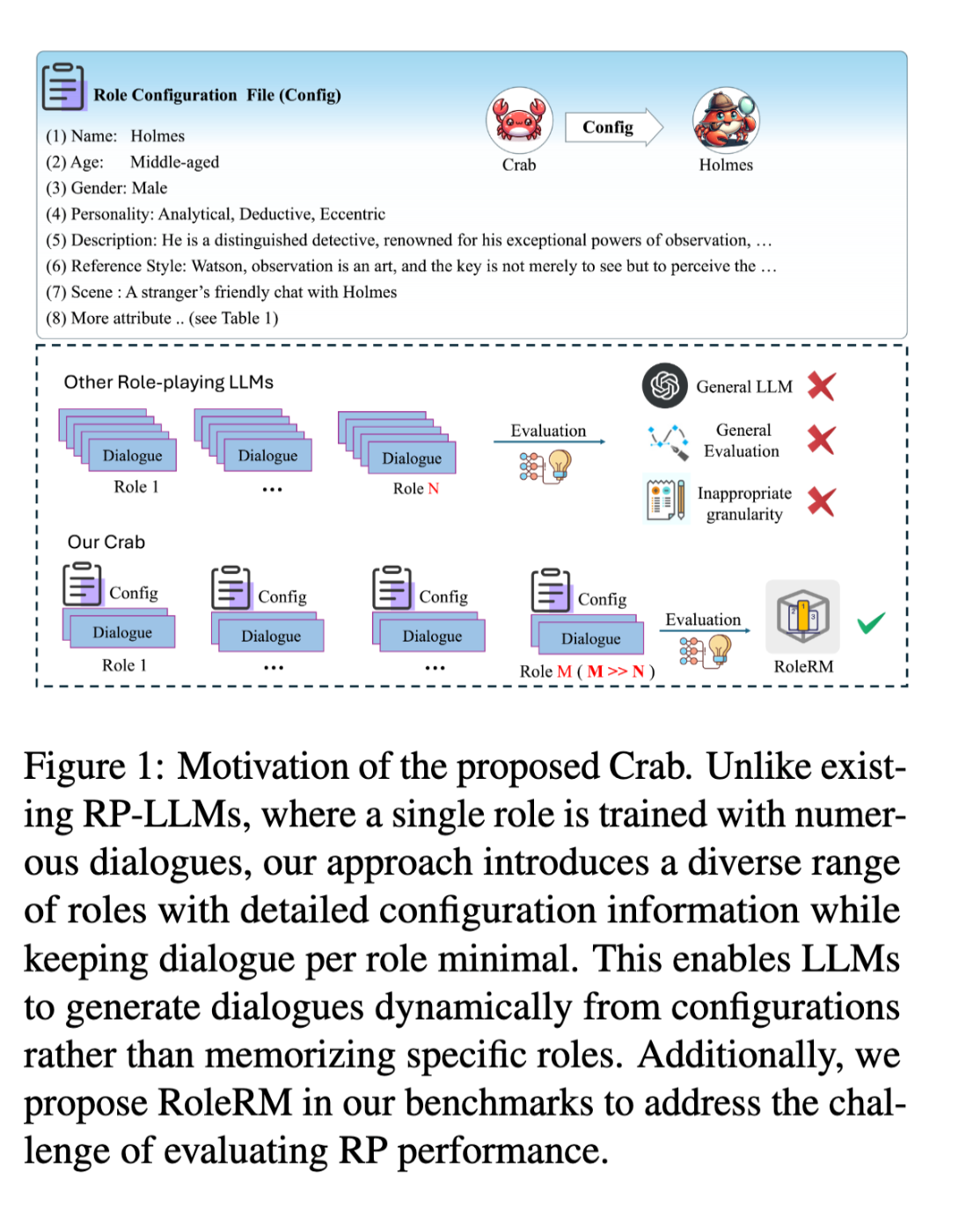
Name, Gender, Age, Personality, and Background Description(必須) + Expressions, Reference Style, and Role Knowledge(任意)からなるRole-Playing Datasetを構築。また、各対話に対し人手で4段階スコアでアノテーションを実施(Language Fluency, Language Relevance, Role Language, Role Knowledge, Emotional Expression, Interactive Engagementの6つのそれぞれに対して4段階で実施)
A Character-Centric Creative Story Generation via Imagination
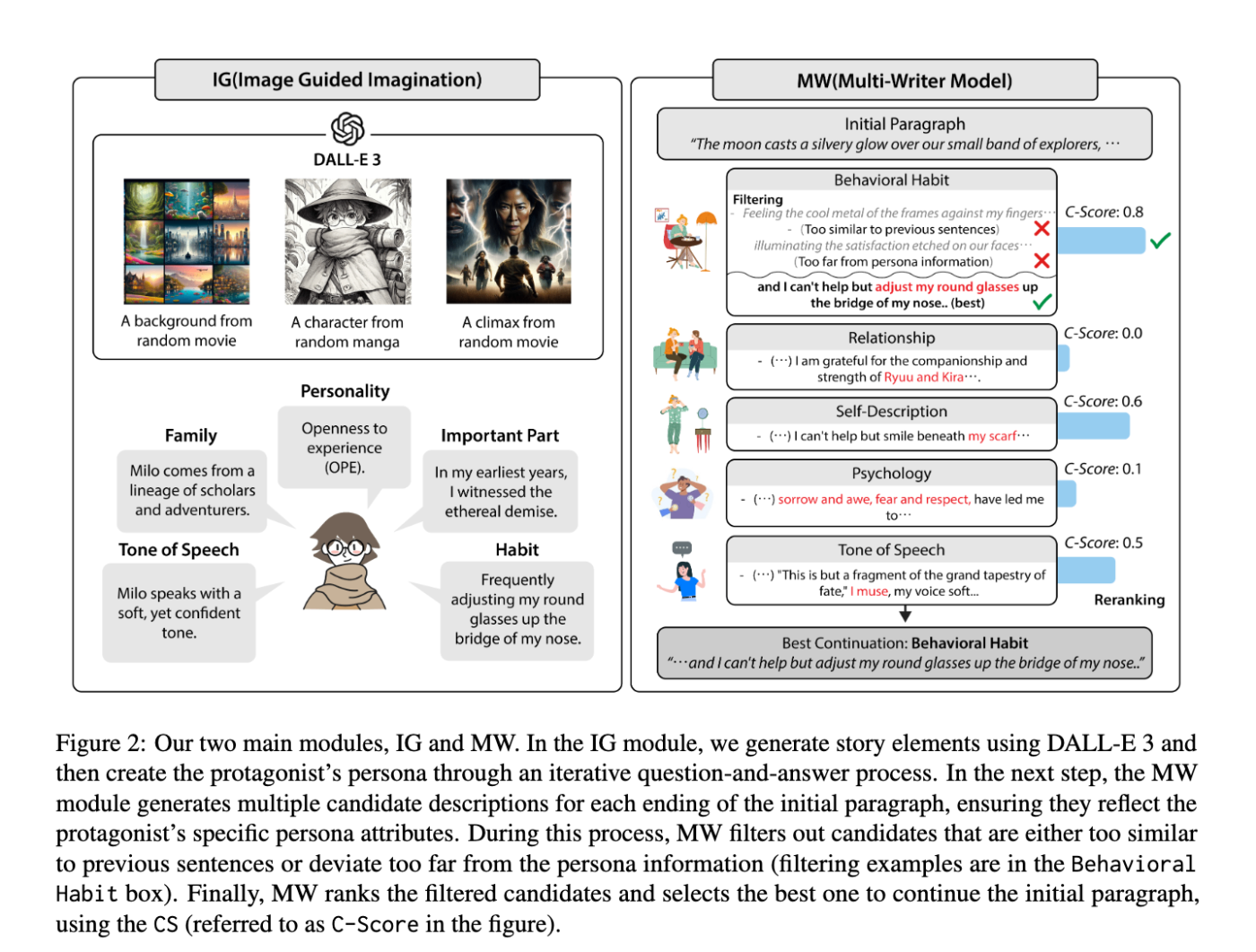
クリエイティブな物語生成に着目した論文。まず画像生成モデルにランダムに画像を生成させる。その画像からGPTにキャラクターやプロットを生成させる。
Spotting Out-of-Character Behavior: Atomic-Level Evaluation of Persona Fidelity in Open-Ended Generation

長文を生成した時等、文内でペルソナの記述が変化することがある。既存研究では捉えられていないこれらの部分を、本研究では文をAtomic-unit(先行研究例)に分けて、それごとに見ることで対処。Atomic間で一貫しているか等を計測した。
SHARP: Unlocking Interactive Hallucination via Stance Transfer in Role-Playing LLMs

Interactive Hallucinationという例えば、友好的なキャラクターの質問にはなんでも肯定するが、嫌いなキャラクターの質問にはなんでも否定する等のインタラクションの作用により発生するハルシネーションを定義。このハルシネーションを評価する特殊な指標として、仲が良い人が間違ったことを行ったときの挙動を観察するSycophancy Rate (SR)と仲が悪い人が正しいことを言った時の挙動を観察するAdversary Rate (AR)を作成した。
Tell Me What You Don’t Know: Enhancing Refusal Capabilities of Role-Playing Agents via Representation Space Analysis and Editing
Role-Playing Agent内に無い知識の問い合わせに対する回答のベンチマークを作成。
また、モデルの表現空間内に質問に対してそのまま回答する領域と拒否する領域があることを見出し、モデルの重みを変更せずに、質問に対して拒否させるような方法を考案した。
MECoT: Markov Emotional Chain-of-Thought for Personality-Consistent Role-Playing
既存のRole-Playingシステムは不自然な感情の変化や、キャラクター固有の感情を保持できない課題がある。その課題に対処するために、Kahnemanのdual-process theoryに従ったCoT方法を提案。
迅速な直感的反応(システム1)と意図的な合理的制御(システム2)が関与し、個人の性格特性や文脈的要因によって調整される。
[Reasoning Does Not Necessarily Improve Role-Playing Ability](https://aclanthology.org/2025.findings-acl.537.pdf)
ReasoningやCoTがRole-Playing性能を低下させたり、適さない可能性があることを示唆。GPT-4 Turbo等のモデルに対して調査。
The Rise of Darkness: Safety-Utility Trade-Offs in Role-Playing Dialogue Agents
Role-Playing LLMが危険な発話を生成しやすい問題に対して、特に悪役のキャラクターをロールプレイする時に発生しやすい問題だと指摘。本研究では、安全度をコントロールしつつ生成する手法とハイリスクな応答を生成する際にも安全度を保持したエッジケースをあらかじめ訓練サンプルとして作成して対処する方法を提案。
Towards a Design Guideline for RPA Evaluation: A Survey of Large Language Model-Based Role-Playing Agents
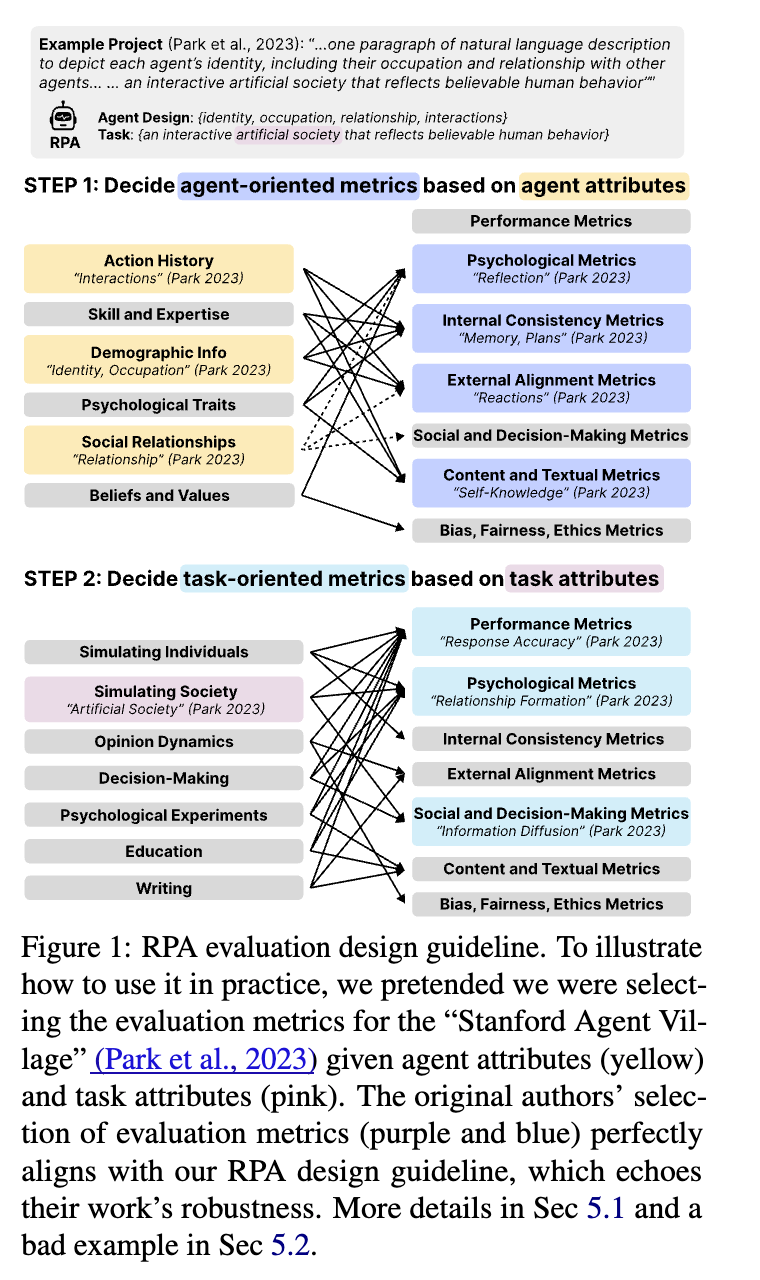
Role-Playing対話システムの評価に向けた周辺論文サーベイ
RoleMRC: A Fine-Grained Composite Benchmark for Role-Playing and Instruction-Following
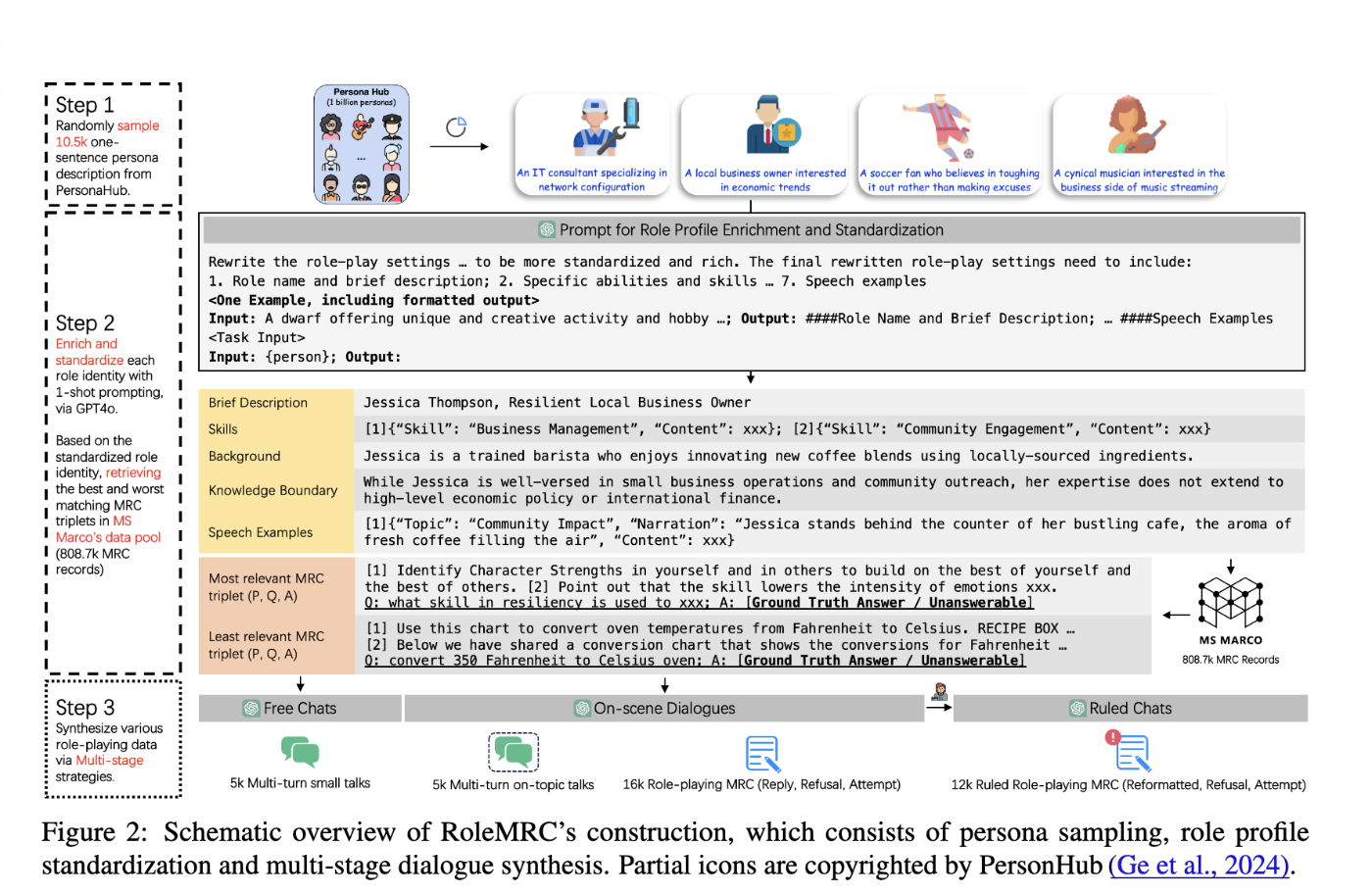
Role-Playingにおける新規データセットの構築。ユーザとの対話シミュレーションのFree Chat, 与えられたパッセージに関連したナラティブか応答を行うOn-Scene Dialogues, On-Scene Dialogueに更に厳しい制約条件を加えたRuled Chatsの3つを基準に収集
EMNLP
Anchoring-Guidance Fine-Tuning (AnGFT): Elevating Professional Response Quality in Role-Playing Conversational Agents

Role-Playing用にLLMをFine-tuningすると、たとえ法律等の専門家のRoleでも法律に関する専門知識が抜けてしまう等の専門知識の欠如が発生する。
本研究では2段階の訓練ステップで対処。1段階目ではAnchorとなるシステムプロンプト(例:あなたは法律の専門家です)と幅広い専門知識に関するシステムプロンプトを同時に用いることでAnchorプロンプトと専門知識を結びつける。2段階目でRole-Playingを行うように訓練する。
Agent-as-Judge for Factual Summarization of Long Narratives

長文(> 100K tokens)の要約において、正確性等には未だに改善の余地があると指摘。そこで、まずは登場人物間に関するKnowledge Graphを構築する。要約文をatomic factsに分解し、その各atomic factとKnowledge Graphの部分グラフを比較し、整合しているかを判定する。これらの判定から得られたフィードバックを元に要約を精緻化する。
Video2Roleplay: A Multimodal Dataset and Framework for Video-Guided
動画上の人物のRole-Playingに向けて、動画像も使用したフレームワークを構築。動画をそのまま入れてキャラクターの動的な部分のプロフィールを反映することを目指す。
R-CHAR: A Metacognition-Driven Framework for Role-Playing in Large Language Models


Role-Playingシステムにおいて、認知プロセスまでは模倣できないと指摘。そこで、Metacognitive-Drivenなフレームワークを提案。データ作成ではBasic(知識等の表層的な一貫性に着目), Advanced(感情的なニュアンス等のキャラクターの深い部分に着目), Difficult(道徳的に曖昧だったり社会的に複雑な事項)の3つに分けてシナリオ作成。また、各シナリオに対してそれぞれの作成意図に合わせて評価指標をLLMで3つ自動作成する。推論プロセスを作成する時には推論軌跡を複数出し、先程の評価指標が最も高い軌跡を採用する。それをベースに次の推論軌跡をLLMが生成することを繰り返す。以上から出来たデータを学習用データとする。
CogDual: Enhancing Dual Cognition of LLMs via Reinforcement Learning with Implicit Rule-Based Rewards
既存のRole-Playingシステムは認知メカニズムを軽視しがちだと指摘。本研究では認知プロセスを考慮したCoT or 学習方法を提案。認知時は状況の認識(環境の認識・他者に関する認識)と自己認識を応答前に挟むという仮定を元にしている。
Probing Narrative Morals: A New Character-Focused MFT Framework for Use with Large Language Models
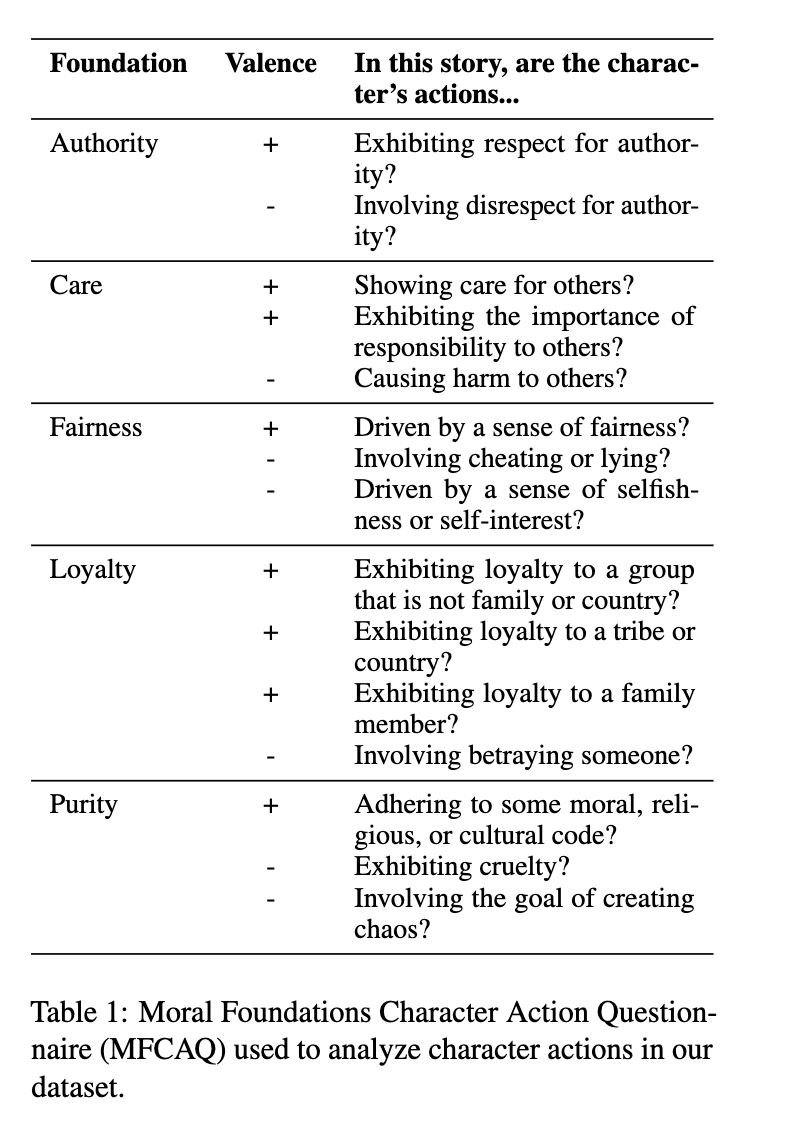
計算機で計測できるようにするため、キャラクターのMoral Foundationを計測する質問項目を作成。Authority/Care/Fairness/Loyalty/Purity+キャラクターがヒーローorヴィランかの6項目に関して5段階で回答できる質問を行う。
Guess What I am Thinking: A Benchmark for Inner Thought Reasoning of Role-Playing Language Agents
キャラクターの行動決定等の理解や、より柔軟な制御に向けて応答前の内的思考を入れたデータセットを構築。
Revealing and Mitigating the Challenge of Detecting Character Knowledge Errors in LLM Role-Playing
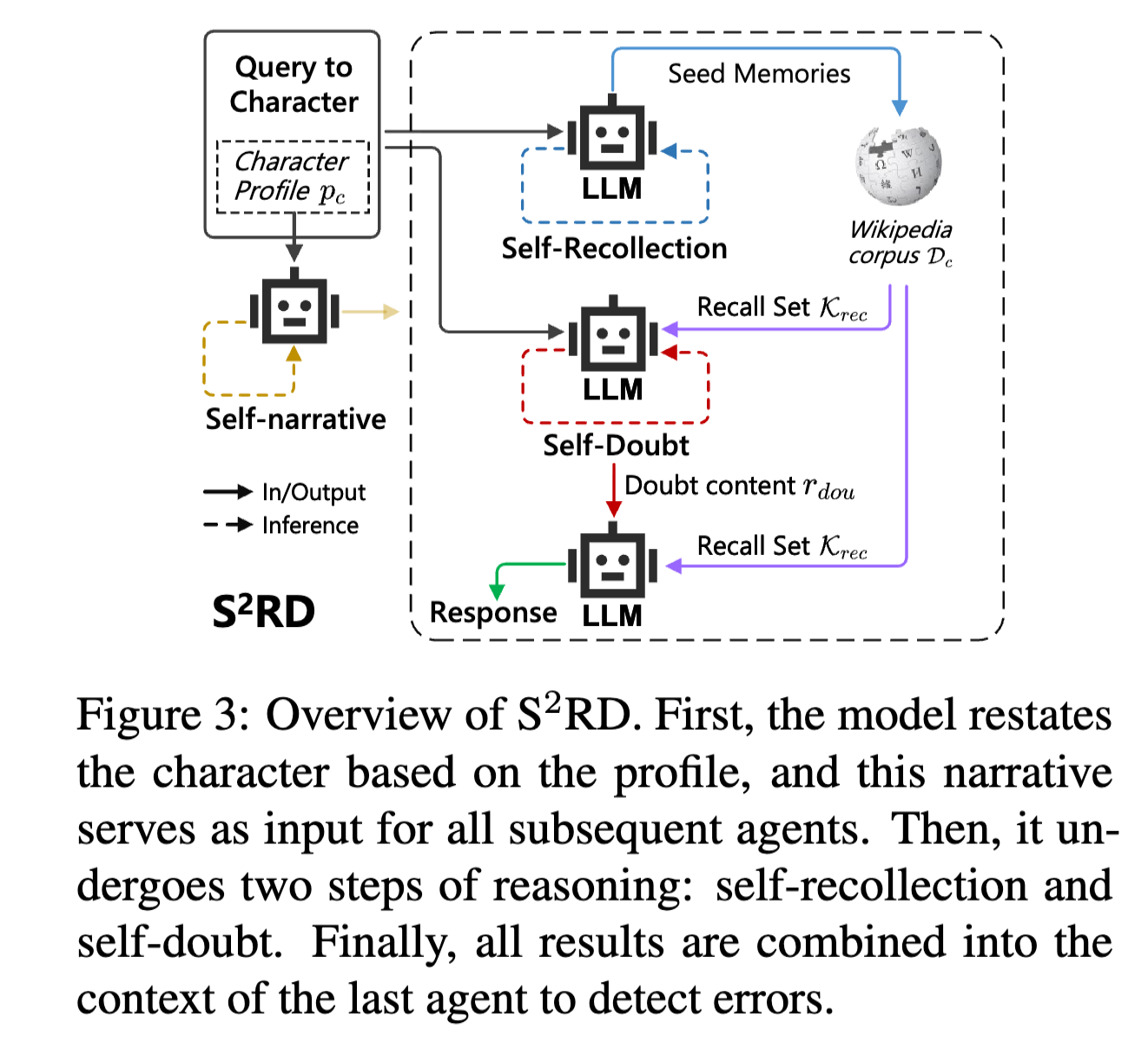
キャラクターの知識のハルシネーションに関して、Agent-baseの手法で対処を試みた。
特定のクエリに対して、それに関連する記憶手がかりを思い出し、外部知識から検索するSelf-Recollection, クエリが本当に正しいかを疑わせるSelf-Doubtのエージェントからなる。
OPEN-THEATRE: An Open-Source Toolkit for LLM-based Interactive Drama
プレイヤーがキャラクター間の対話に介入するインタラクティブドラマを作成するためのOSSの開発
RMTBench: Benchmarking LLMs Through Multi-Turn User-Centric Role-Playing
これまではキャラクターの一貫性等、Character-Centricな要素に着目されていたと指摘し、User-centricなRole-Playing Benchmarkを構築。ユーザがキャラクターの情報や背景に対して好奇心を抱く程度を示すCharacter Understanding, ユーザがAIだと知っている上での質問(例:Which company developed you?)をした上でもキャラクター一貫性を保つCharacter Maintenance, ユーザ主導の対話に対してキャラクターらしい対応ができるかを測るImplicit User Intentions Response, ユーザ情報を覚えているかのUser Preference Awareness and Reasoning, センシティブな発言に対する対応を測るSensitive User Begavior Handlingの5つを仮定したシナリオに対して評価を行う。
Crafting Customisable Characters with LLMs: A Persona-Driven Role-Playing Agent Framework
カスタマイズ可能な会話エージェントを作成するフレームワークを構築。
Character is Destiny: Can Persona-assigned Language Models Make Personal Choices?

LLMは重要な意思決定において、人間を模倣できるかを調査。キャラクターが特定の重大な決断が必要な状況に置かれた時、どのような決断をするかを4択問題から選択するデータセットを構築。重大な決断が必要な場面はLLMで自動的に抽出。
Discussion