Pythonの値の代入とか参照渡しとかコピーとかをメモリーから考えてみる
概要
Pythonで、値の代入(=)から始めて、ミュータブルやイミュータブル、値渡しや参照渡し、deep copyやshalow copyなどを、メモリの観点から考えると非常に理解が深まったので、まとめてみました。
メモリの4領域
まずは、メモリについて説明します。
メモリはメモリ空間の先頭の部分(低位アドレス)から末尾部分(高位アドレス)に向かって、4つの領域が存在します。
(1) テキスト領域: プログラムのバイナリが格納される(読み取り専用)
(2) 静的領域: 静的変数やグローバル変数などが保管される(読み書き可能)
(3)ヒープ領域: 動的に確保されたオブジェクトなどが格納される(読み書き可能)
(4)スタック領域: ローカル変数などが格納される(読み書き可能)
簡単な図で示すとこんな感じになります。

※ヒープ領域は、低位アドレスから高位アドレス側に領域を増やす
※スタック領域は、高位アドレスから低位アドレス側に領域を増やす
変数への値の代入
メモリの概要をつかんだところで、プログラムの基本である変数に値を代入するステートメントを見てみましょう。ここで、変数は全てローカル変数(関数内に記述されている変数)になります。
まずは、基本的なint型で説明します。
x = 1000
変数xに1000という整数を入力しています。これはプログラマなら誰でも知っている基本中の基本です。このステートメントが、メモリの観点から見てどのように動作しているか見てみます。
代入ステートメントでは、以下のように処理が進みます。
- 変数の領域を確保: スタック領域に変数xのための領域を割り当てる。
- 式の評価: CPUが1000を評価し、その結果をオブジェクトとしてヒープ領域に保存する。
- 参照の保存: スタック領域のxにヒープ領域のオブジェクト(1000)への参照を保存する。公式ドキュメントでは"束縛"と表現しています。
つまり、変数にはオブジェクトの参照が入っているということです。
メモリの観点でみると、評価結果のオブジェクトはヒープ領域に保持され、スタック領域の変数の部分にオブジェクトへの参照を保持します。
リストや辞書などの複合的な型の場合でも同じです。
次のようなリストを変数yに束縛する場合を考えます。
y = [1000, True, {"age": 22}]
ヒープ領域に保存されるオブジェクトは、このようになります。
[1000への参照, Trueへの参照, 辞書への参照]
1番目と2番目のリストの要素はint型なので参照先には値が保持されていますが、3番目の要素は、辞書型なので、参照を持つオブジェクトが生成されています。
{"age"への参照: 22への参照}
この参照先のヒープ領域に、"age"と22が保持されています。
図で示すとこんな感じになります。

ミュータブルとイミュータブル
さて、次はミュータブル(mutable)とイミュータブル(immutable)についてみていきましょう。
イミュータブルのデータ型には、
- int
- float
- str
- tuple
などがあげられます。ミュータブルのデータ型は、
- list
- dict
- set
などになります。
ここで勘違いしやすいのは、イミュータブルは変更できないという意味です。これはヒープ領域にあるオブジェクトが変更できなということで、スタック領域にある変数への束縛は変更できます。式で書くとこんな感じです。
t = (0, 1)
t[0] = 100 # できない。タプルなのでヒープ領域のオブジェクトは変更できない。
t = (100, 1) # できる。新しくヒープ領域のオブジェクトを作成して、変数に束縛している。
図を見た方が分かりやすいと思います。
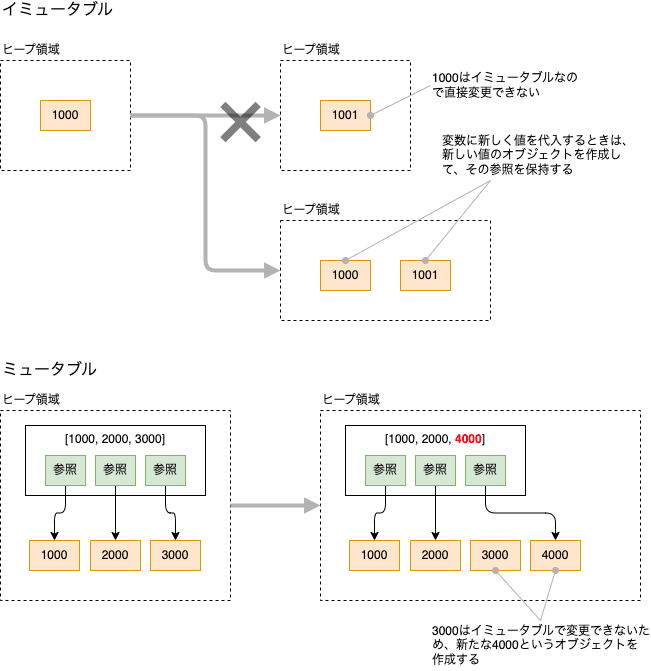
コードを実行しながら確認しましょう。まずは、イミュータブルなint型から。
x = 1000 # ヒープ領域に1000というオブジェクトが確保される。スタック領域のxの割り当て部に1000への参照が入る
print(id(x)) # 1000への参照
y = x # xと同じ参照を変数yに束縛する(xとyはそれぞれ別のスタック領域を持ちます)
print(id(y)) # xと同じ参照になる
x = 1001 # ヒープ領域に1001というオブジェクトが確保される。スタック領域のxの割り当て部に1001への参照が入る
print(id(x)) # 元のxとは異なる参照が入る
print(x) # 1001
print(y) # 1000
次はミュータブルなlist型でやってみます。
x = [1000, 2000] # ヒープ領域に[1000, 2000]というlistオブジェクトが保持される。スタック領域のxの割り当て部にこのlistへの参照が入る
print(id(x)) # オブジェクト[1000, 2000]への参照
print(id(x[0])) # 要素1000への参照
y = x # xと同じ参照を変数yに束縛する(xとyはそれぞれ別のスタック領域を持ちます)
print(id(y)) # xの参照と同じ
print(id(y[0])) # x[0]の参照と同じ
x[0] = 3000 # リストオブジェクトの書き換え
print(id(x)) # 元の参照のまま
print(id(x[0])) # 新しい参照
print(id(y)) # xと同じ参照
print(id(y[0])) # x[0]と同じく変わる
print(x) # [3000, 2000]
print(y) # [3000, 2000]
# 参考 x に直接代入すると別のオブジェクトを参照するので、上記のような動作にはならない
x = [3000, 2000] # ヒープ領域に、別の[3000, 2000]というlistオブジェクトが生成される。このオブジェクトへの参照が変数xに束縛される
print(id(x)) # 新しい参照
print(id(y)) # 元の参照のまま
x[0] = 1000 # リストの要素を書き換える
print(id(x)) # もちろん参照は変わらない
print(x) # [1000, 2000]
print(y) # [3000, 2000]
それでは、イミュータブルな型のtupleの中にミュータブルなlistがある場合と、反対にlistの中にtupleがあるの場合について考えてみましょう。
list_in_tuple = (1000, [2000, 3000])
tuple_in_list = [1000, (2000, 3000)]
list_in_tuple[1][1] = 4000 # 変更できる
tuple_in_list[1][1] = 5000 # 変更できない
list_in_tuple[1] = [2000, 4000] # 変更できない
tuple_in_list[1] = (2000, 5000) # 変更できる
図で表すとこんな感じ
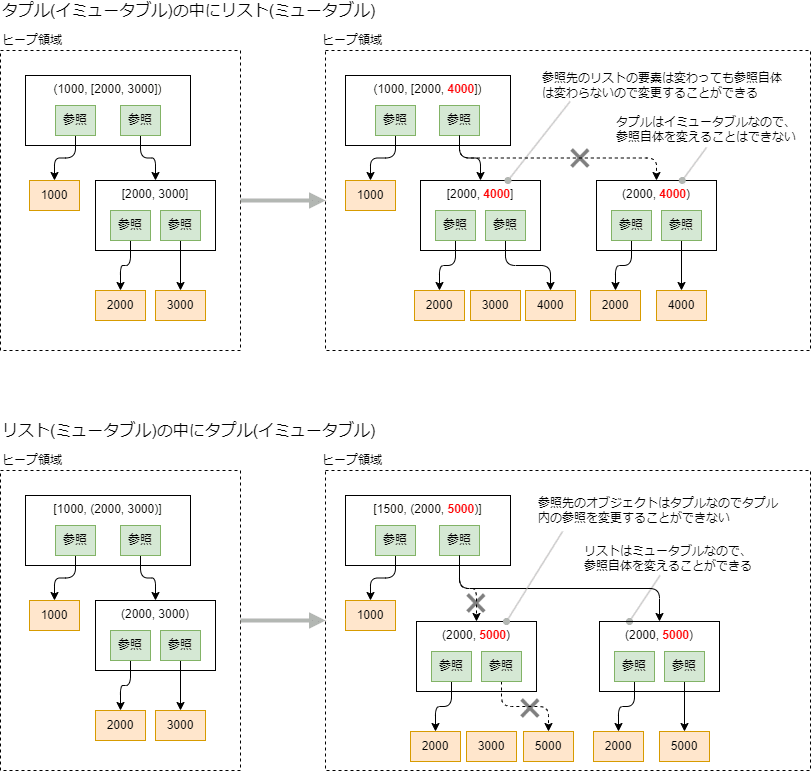
キャッシュ
実は、デフォルトでヒープ領域に保存されているオブジェクトがあります。
- 小さな整数: -5から256までの整数
- 短い文字列: からの文字列や短い文字列など
- Bool値: True / False
- その他: Noneや空のタプルなど
したがって、
x = 1 # 1はデフォルトでヒープ領域に保持されている
y = 1 # 上の1と同じデフォルトの1を使用する
print(id(x) == id(y)) # True
x = 1000 # 右辺の評価結果は新たにヒープ領域に保持される
y = 1000 # 上の1000とは別の1000がヒープ領域に保持される
print(id(x) == id(y)) # False
となります。
参照渡しと値渡し(2025.12.03修正)
プログラム言語には、関数へのパラメータの渡し方に、値渡しと参照渡しがあります。
値渡し:値のコピーを渡す方式。関数内で変更しても呼び出し元に影響しません。
※多くの言語では、この値渡しをおこなっています。
参照渡し:変数そのもの(別名)を渡す方式。関数内の変更がそのまま呼び出し元に反映されます。
※この純粋な参照渡しを持つ代表的な言語は C++ です。
PythonはC++のような参照渡しは持たず、すべて値渡しです。ただしPythonの変数には、ほぼ全て「ヒープ領域のオブジェクトへの参照」が入っており、その参照値を関数に渡します。つまり、丁寧に言えば “参照の値渡し” を行っていることになります。
id関数の罠(2025.12.03修正)
Pythonの引数が、値渡しなのか参照渡しなのか混乱する場面もあるようですが、その要因の一つに、id関数の挙動があると思います。
id 関数が返すアドレスは、引数の変数そのものが保持されている**(Python処理系の実装上はほぼスタック相当の)領域のアドレスではなく、その変数が参照しているオブジェクトが保持されているヒープ領域**のアドレスです。
そのため、呼び出し元の変数aと関数側の引数xで id(a) と id(x) が同じ値を示していても、スタック側(=各スコープのローカル変数としての領域)には a と x が別々に存在しています。
つまり、a と x は別の変数ですが、同じヒープ上のオブジェクトを参照しているため、id の値が一致して見えるというだけです。
id 関数の結果が同じだと「同じ変数が渡されている」と誤解しやすいですが、
実際には “別々のスタック上の変数が、同じヒープ上のオブジェクトを指している” という点が注意ポイントになります。
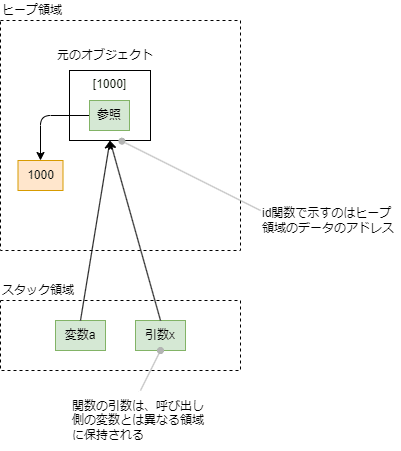
確認
コードで確認してみましょう。まずは、イミュータブルなint型ではこうなります。
def print_sum(x: int, y: int) -> None:
print(id(x)) # main関数の変数と同じ参照が入る main関数の変数aと引数xは別の領域に保持されている
x = 7 # 引数のaを変更する
print(id(x)) # 新しくオブジェクトを作成したので、新しい参照が入る
print(x) # 値が7に変更されている
s = x + y
print(s) # 12
def main():
a = 5 # 呼び出し元の変数a
print(id(a)) # main関数の変数aの参照
b = 10
print_sum(a, b)
print(a) # 5 のまま
print(id(a)) # 元の参照のまま
main()
ミュータブルなlist型でも同じ挙動を示します。
def print_sum(x: list[int]) -> None:
print(id(x)) # main関数の変数と同じ参照が入る main関数の変数aと引数xは別の領域に保持されている
x = [20, 1, 2, 3, 4] # 新しくlistオブジェクトがヒープ領域に作成される
print(x) # [20, 1, 2, 3, 4]
print(id(x)) # 新しくオブジェクトを作成したので、新しい参照が入る
s = sum(x)
print(s) # 30
def main():
a = [0, 1, 2, 3, 4] # 呼び出し元の変数a
print(id(a)) # main関数の変数aの参照
print_sum(a)
print(a) # [0, 1, 2, 3, 4] 値は変わらない
print(id(a)) # 元の参照のまま
main()
Pythonの関数の引数の渡し方が参照渡しに見えるのは以下の挙動を示すからだと思います。
※id(x) == id(a) となるのも迷うポイント
def print_sum(x: list[int]) -> None:
print(id(x)) # main関数の変数と同じ参照が入る main関数の変数aと引数xは別の領域に保持されている
x[0] = 20 # 元のオブジェクトの1番目の要素の参照が変わる
print(x) # [20, 1, 2, 3, 4]
print(id(x)) # 元のaの参照と同じ
s = sum(x)
print(s) # 30
def main():
a = [0, 1, 2, 3, 4] # 呼び出し元の変数a
print(id(a)) # main関数の変数aの参照
print_sum(a)
print(a) # [20, 1, 2, 3, 4] 値が変わる
print(id(a)) # 元の参照のまま
main()
関数内の引数xとmain関数の変数aは、同じオブジェクトを参照しており、それは処理中に変わりません。この参照先のオブジェクトが変更になったため、関数実行後に変数aの値も変更されているということになります。
deep copy(深いコピー)とshallow copy(浅いコピー)
さて、最後にdeep copyとshallow copyについて説明します。
python公式のドキュメントを見るとそれぞれの定義は、以下のようになります。
浅い (shallow) コピーと深い (deep) コピーの違いが関係するのは、複合オブジェクト (リストやクラスインスタンスのような他のオブジェクトを含むオブジェクト) だけです:
- 浅いコピー (shallow copy) は新たな複合オブジェクトを作成し、その後 (可能な限り) 元のオブジェクト中に見つかったオブジェクトに対する 参照 を挿入します。
- 深いコピー (deep copy) は新たな複合オブジェクトを作成し、その後元のオブジェクト中に見つかったオブジェクトの コピー を挿入します。
ここでは、ミュータブルなオブジェクトとイミュータブルなオブジェクトがそれぞれのコピーでどのような挙動をとるのか調べてみました。
イミュータブルオブジェクトのshallow copy
イミュータブルオブジェクトのshallow copyは、元のオブジェクトの参照を取ります。つまり、=で代入した時と同じ結果になります。
import copy
x = (1000, (2000, 3000))
y = copy.copy(x)
z = x
print(id(y) == id(z)) # True
print(id(y[0]) == id(z[0])) # True
print(id(y[1]) == id(z[1])) # True
print(id(y[1][0]) == id(z[1][0])) # True
親要素が同じなので、子要素なども当然ながら同じ参照になります。
図で書くとこんな感じです。
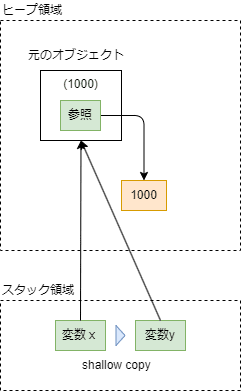
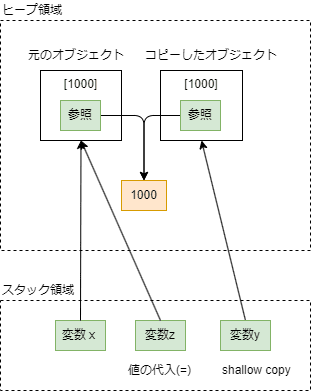
ミュータブルなオブジェクトのshallow copy
ミュータブルなオブジェクトのshllow copyは、元のオブジェクトをそのままコピーして新しいオブジェクトを作成します。子要素の参照は元の要素と同じ参照になります。
import copy
x = [1000, [2000, 3000]]
y = copy.copy(x)
z = x
print(id(y) == id(z)) # False
print(id(y[0]) == id(z[0])) # True
print(id(y[1]) == id(z[1])) # True
print(id(y[1][0]) == id(z[1][0])) # True
図で書くとこんな感じです。
deep copy(ミュータブルもイミュータブルも同じ)
公式ドキュメントでいうところの複合オブジェクトの場合、ミュータブルでもイミュータブルでも同じ挙動を示します。どちらもオブジェクトの要素によって場合分けされます。
オブジェクトの要素(子孫要素含む)が全てイミュータブルの場合
元のオブジェクトを参照します。
オブジェクトの要素(子孫要素含む)にミュータブルが含まれる場合
オブジェクトを複製して、新しいオブジェクトを作成します。
そして、これらを再帰的に全ての子孫要素に適用します。この再帰的に適用していく部分が分かりにくいです。例を挙げて説明します。tupleとlistが複数ネストしたオブジェクトを考えます。
まずは、分かりやすく全ての要素がtupleの場合を考えてみると、当然ながら全て元のオブジェクトの参照になります。
# tupel -> tuple -> tuple -> tuple の場合
import copy
obj = (1000, (2000, (3000, (4000))))
c_obj = copy.deepcopy(obj)
print(id(obj) == id(c_obj)) # (1000, (2000, (3000, (4000)))) -> True
print(id(obj[1]) == id(c_obj[1])) # (2000, (3000, (4000))) -> True
print(id(obj[1][1]) == id(c_obj[1][1])) # (3000, (4000)) -> True
print(id(obj[1][1][1]) == id(c_obj[1][1][1])) # (4000) -> True
print(id(obj[1][1][1][0]) == id(c_obj[1][1][1][0])) # 4000 -> True
これに最後の要素がイミュータブルになった場合(この場合はリスト)、これより親の要素は全てコピーになります。
import copy
obj = (1000, (2000, (3000, [4000])))
c_obj = copy.deepcopy(obj)
print(id(obj) == id(c_obj)) # (1000, (2000, (3000, [4000]))) -> False
print(id(obj[1]) == id(c_obj[1])) # (2000, (3000, [4000])) -> False
print(id(obj[1][1]) == id(c_obj[1][1])) # (3000, [4000]) -> False
print(id(obj[1][1][1]) == id(c_obj[1][1][1])) # [4000] -> False
print(id(obj[1][1][1][0]) == id(c_obj[1][1][1][0])) # 4000 -> True
自分自身の子孫要素にミュータブルな要素があると複製になるのです。
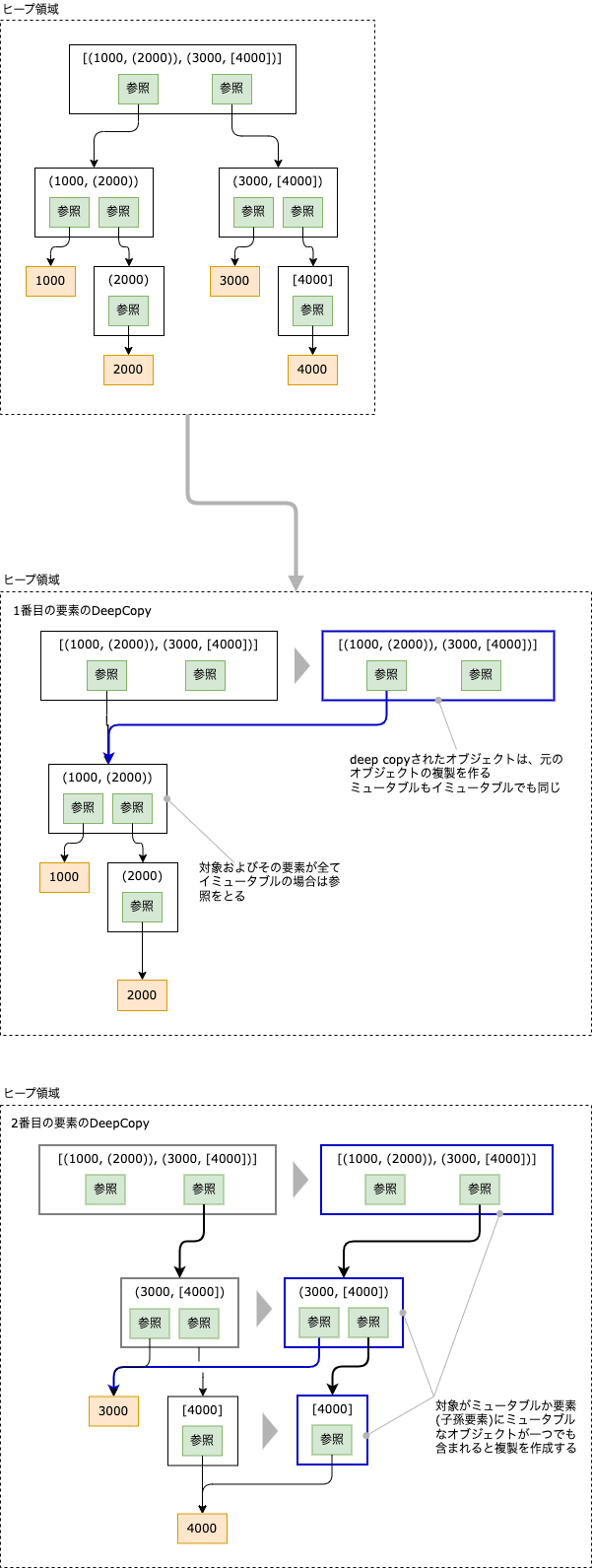
ミュータブルな要素の子孫にイミュータブルな要素があった場合も見てみます。
import copy
obj = [(1000, (2000, (3000))), (4000, (5000, [6000]))]
c_obj = copy.deepcopy(obj)
print(id(obj) == id(c_obj)) # [(1000, (2000, (3000))), (4000, (5000, [6000]))] -> False
print(id(obj[0]) == id(c_obj[0])) # (1000, (2000, (3000))) -> True
print(id(obj[1]) == id(c_obj[1])) # (4000, (5000, [6000])) -> False
print(id(obj[1][1]) == id(c_obj[1][1])) # (5000, [6000]) -> False
print(id(obj[1][1][1]) == id(c_obj[1][1][1])) # [6000] -> False
print(id(obj[1][1][1][0]) == id(c_obj[1][1][1][0])) # 6000 -> True
objは、リストなので、そのdeep copyは、元のオブジェクトの複製になります。
objの1番目の要素は、(1000, (2000, (3000)))で、全てがイミュータブルです。この場合、deep copyでは参照をとります。
objの2番目の要素は、(4000, (5000, [6000]))で、子孫要素にミュータブルが含まれます。この場合、deep copyでは複製を作ります。同様に子要素の(5000, [6000])と孫要素の[6000]についても、複製を作ります。リスト要素の6000はイミュータブルなので参照することになります。
図で書くとこんな感じになります。要素数を少なくしています。
最後に
かなり詳細な部分にまで調べてみました。私自身も認識を間違えていた部分もあり、大変勉強になりました。いろいろ迷ったときは、こういった原点に返って考えてみるのも良いかもしれないですね。
Discussion
参照渡しでいう 参照は変数のことなので 参照値が変更できない以上、参照渡しにはならないのですけれどね。(破壊的操作により 変数の参照値ではなく、状態が変更されることは参照渡しとは関係ない為
Rustの参照型は参照を渡して値共有できますが、C++やC#のような参照渡しによる変数共有はできません。
Rustの言語仕様にも「参照渡し」という表記はありません。
Rustの参照の表現がまちがえていましたので、記事を修正しました。ご指摘ありがとうございました。
質問失礼します。
記事中にある図は、何のソフトを使って作られていますか?
アクセスありがとうございます。
こちらで、使用しているのは、VScodeのExtensionで、Draw.io Integrationというものを試用しています。Draw.ioというブラウザでひらくことできるツールをVScodeで使えるようにしたみたいです。