特定サービスを深く熟知していて、APIも自在に使いこなし、お客さんの必要としているソリューションをつくるのを手伝ってくれるソリューションエンジニアって素敵ですよね。いままでそんな素敵なソリューションエンジニアは、雇用するのも養成するのも大変で、超大手のクラウドベンダーぐらいしか十分に用意するのは難しかったです。
この記事では、OpenAI.functions+IPython+SlashGPTを活用することで、自社サービス専用のソリューションエンジニア(ボット)を手早く起ち上げる方法を解説します。
言い換えると、自然言語での要求に応じて独自APIを呼び出すコードを実装、実行してくれるCode Interpreterをローカルで動かし、確認する方法を解説します。
Code Interpreterとは
2023年7月にOpenAIがChatGPTプラス加入者むけてにCode Interpreterのベータサービスを開始しました。ChatGPTに作って欲しいプログラムを自然言語でリクエストをすると、プログラムを作ってくれるだけでなく実行もしてくれます。
Code Interpreterとは、一言で言えば、ユーザーのリクエストに応じて、必要なプログラムを書き、実行し、結果を届けてくれる人工知能です。
一般の人にはあまり縁のない話ですが、私たちエンジニアは、「特定の目的を達成するために一度だけ走らせるプログラムを書く」ことがあります。「iPhoneアプリ」や「ウェブサービス」のように、大勢の人たちに使ってもらうことを前提にしたプログラムとは違い、自分だけが、(多くの場合)1回だけ走らせるプログラムです。
先週も、そんなプログラムを一つ書きました。とあるところから入手したJSONという形式のファイルを読もうとしたのですが、スペースや改行が全くなかったため、そのままでは読むことが不可能でした。そこで、Pythonで数行のプログラムを書いて、そのファイルを読みやすい形に変形しました。
エンジニアの中でも、この手の「使い捨てのプログラム」を頻繁に書くことで知られているのは、「データ・サイエンティスト」と呼ばれるデータ解析を専門にする人たちです。彼らの多くは、Pythonプログラマーで、Jupyter Notebook と呼ばれるインタラクティブな環境で、データを読み込み、それを解析するのに必要なプログラムを書き、実行し、分かりやすい表やグラフを作る、という作業をしています(Microsoft Excelでも、ある程度のことは出来ますが、本格的なデータ解析をする場合には、Jupyter Notebookがデファクト・スタンダードです)。
この「必要に応じてプログラムを書いて実行する環境」は、これまでソフトウェア・エンジニアにだけ与えられた特権でしたが、そのメリットを誰でも受けられるようにしたのが、Code Interpreterなのです。リクエストに応じて、Jupyter Notebookを使いこなして、データ解析をしてくれる、自分専用の「データ・サイエンティスト」のような役割を果たしてくれる、とも言えます。
OpenAI.functionsで単純に自社APIを呼び出すのとの差は?
こちらの記事ではGPTと自社サービスのAPI呼び出しをつなぐ方法を解説しました。APIを呼び出すだけであれば結果はおなじですが、今回はさらにPythonのコードを追加することができるので結果の解析、加工、グラフ化ということも実行できるようになります。そして、Jupyterにてどのように実行されたのかコードも確認することができます。まるで優秀なソリューションエンジニアがひとりひとりのためにコードを書いてくれた結果を読むことと同じ体験ができます。
注意すべき点としてOpenAI.functionsとして実行するときは呼び出しパラメータさえあれば、あとは返ってきたjsonをそのままGPTに投げればGPTがフレキシブルに解釈してくれました。今回はpythonプログラムで受け取って後処理、解析を行うのでresponseの構造もしっかり定義として伝える必要があります。構造を伝えておけばGPTからresponseをParseするPythonコードが出力されます。(GPT本当にすごいですね。)
準備
- SlashGPT repo のclone
- OpenAI API KEY
- open ai でアカウントを作成後下記でAPI-Keyを発行します
- https://platform.openai.com/account/api-keys
- 無料枠は5$までです https://openai.com/pricing
- Python実行環境
- miniconda 等で準備しておく
- Jupyter(IPython)実行環境
- こちらの記事を参考に準備しておく
- https://zenn.dev/singularity/articles/718cba24bf1275
概要フロー
- GPTに対して、自然言語で要求するときに、呼び出したいサービスのAPI仕様を追記します
- functionsの機能を利用し、Pythonのコードをresponseとして返してくれるよう要求します
- pythonのコードが返ってきたらSlashGPTがIPythonのAPIを利用し実行をおこないます
- グラフや画像等はこの時点でユーザーに表示されます
- Pythonの実行結果とものとリクエストを 再度OpenAI GPTになげます
- 最終的な回答をテキストで表示します
- 結果はJupyterNotebookとして参照できます
このあと、一つずつ解説していきます
自社APIに対応したSlashGPT manifestの準備
SlashGPTとは?
SlashGPTは中島聡が開発したChatGPTなどのLLMエージェントを手軽に開発するためのツールです。SlashGPTを使えば、manifest(jsonファイル)を記述するだけでChatGPTを使ったLLMエージェントやチャットアプリを手軽に、簡単につくることができます。
簡潔なAPI仕様準備
OpenAIがPythonプログラムを作成するときに参照できるように、APIの呼び出し方、Responseの構造が定義されたテキストを準備します。RestであればOpenAPI(Swagger)のjson,GraphQLであればスキーマを利用するのが良いと思います。
注意点としては要求の都度GPTに送付されるので、長すぎるとGPT呼び出しが失敗してしまいます。素のSwaggerだと冗長な定義もあるので下記の例のように呼び出したいのに必要な部分だけに絞るという工夫が必要です。
cat some_api_openapi.json | jq -r '.paths | [ to_entries[] | {(.key) : { ("desc"):.value.get.description, ("parameters") : .value.get.parameters , ("responces") : .value.get.responses."200" } }]' > resources/functions/simple_openapi.json
下記のデモでは Githubの標準GraphQLスキーマからBasicな部分を抜き出したスキーマを利用しています。
manifest file 準備
今回の記事では下記のmanifestを使用します。
ポイントは下記の点です
-
"functions": "./resources/functions/code.json"- Python codeをGPTが返すための設定です
-
"notebook": true,- IPytonを利用してnotebookを作成、実行します
-
"resource": "./resources/functions/github_basic.graphql",- 追加でつたえたいAPI仕様です
- 自分のサービスごとにカスタマイズしてください
- prompt
"prompt": [ "You are an expert in GraphQL and a data scientist who writes Python code to analyze data.", ... "Use GraphQL query by http request to 'https://api.github.com/graphql' when you need to get github data, and use os.getenv(SLASH_GPT_ENV_GITHUB_TOKEN) as Github Token", "Here is the schema of GraphQL query:", "{resource}" ]- ユーザーの要求文章とともにGPTに送信されます
- 上記で定義した
resourceの内容が展開され一緒に送付されます
API Secretの渡し方
外部のAPIを呼び出すには何かしらsecretを渡す必要がでてきます。
GPTにsecretを送ることは避けたいです。SlashGPTのIPythonでは、ローカルの.envに定義された環境変数を読み込む機能があるので、promptでuse os.getenv(SLASH_GPT_ENV_GITHUB_TOKEN) as Github Tokenのように明確に指定をすると、出力されるPythonCodeに下記のように反映してくれます。
# GitHub GraphQL APIのエンドポイント
url = 'https://api.github.com/graphql'
# GitHub Token
token = os.getenv('SLASH_GPT_ENV_GITHUB_TOKEN')
# GraphQLクエリ
...
# GraphQLリクエストのヘッダー
headers = {
'Authorization': f'Bearer {token}'
}
# GraphQLリクエストの実行
response = requests.post(url, json={'query': query}, headers=headers)
SlashGPTによるpythonの実行、notebookの自動作成の仕組み
OpenAI Functionsで、Pythonコードを返してもらう
manifest fileに"functions": "./resources/functions/code.json"の定義を追加しましたが、中身は以下のようになっています。
このfunctions指定は、OpenAI.ChatCompletion呼び出し時にGPTに渡ります。
promptとして、"When you write Python code, call 'run_python_code' function."と指示しているので、GPTの作成したpythonのコード部分が応答のなかの'function_call'として受け取ることができます。
content={
"role": "assistant",
"content": null,
"function_call": {
"name": "run_python_code",
"arguments": "{\n \"code\": [\n \"import pandas as pd\",\n \"import matplotlib.pyplot as plt\",\n \"import requests\",\n \"import os\",\n \"from datetime import datetime\",\n \"\",\n \"# Set up the GraphQL query\",\n \"query = '''\",\n \"query {\",\n \" repository(owner: \\\"snakajima\\\", name: \\\"SlashGPT\\\") {\",\n \" ref(qualifiedName: \\\"main\\\") {\",\n \" target {\",\n \" ... on Commit {\",\n \" history(first: 100) {\",\n \" edges {\",\n \" node {\",\n \" committedDate\",\n \" author {\",\n \" name\",\n \" }\",\n \" }\",\n \" }\",\n \" }\",\n \" }\",\n \" }\",\n \" }\",\n \" }\",\n \"}\",\n \"'''\",\n \"\",\n \"# Send the GraphQL request\",\n \"headers = {\",\n \" 'Authorization': 'Bearer ' + os.getenv('SLASH_GPT_ENV_GITHUB_TOKEN')\",\n \"}\",\n \"response = requests.post('https://api.github.com/graphql', json={'query': query}, headers=headers)\",\n \"data = response.json()\",\n \"\",\n \"# Extract the commit data\",\n \"commits = data['data']['repository']['ref']['target']['history']['edges']\",\n \"\",\n \"# Convert the commit data to a pandas DataFrame\",\n \"commit_data = []\",\n \"for commit in commits:\",\n \" date = datetime.strptime(commit['node']['committedDate'], '%Y-%m-%dT%H:%M:%SZ').date()\",\n \" author = commit['node']['author']['name']\",\n \" commit_data.append({'date': date, 'author': author})\",\n \"df = pd.DataFrame(commit_data)\",\n \"\",\n \"# Group the commits by date and author\",\n \"grouped = df.groupby(['date', 'author']).size().unstack(fill_value=0)\",\n \"\",\n \"# Plot the time series graph\",\n \"grouped.plot(kind='line', marker='o', figsize=(12, 6))\",\n \"plt.xlabel('Date')\",\n \"plt.ylabel('Commit Count')\",\n \"plt.title('Commit Count by Contributor')\",\n \"plt.legend(title='Contributor')\",\n \"plt.show()\",\n \"\"\n ],\n \"query\": \"\"\n}"
}
}
Local Python Runtime(IPython)で実行
上記でfunction_callを受け取ったあとは下記でpython_runtime(IPython)に渡されます。
そして下記が呼び出されます。 Python codeがcellとして追加、実行され、結果が返ります。
動作確認方法
この記事の例で使用している例はSlashGPTに取り込んでもらっているので、RepositoryをCloneすればすぐに試せます。
- Secret等の準備
- https://docs.github.com/ja/authentication/keeping-your-account-and-data-secure/managing-your-personal-access-tokens を参考にGithub Tokenを取得
- .envファイルに
SLASH_GPT_ENV_GITHUB_TOKEN=と追記しておく - 他に
OPENAI_API_KEY=も準備セクションを参考に準備
- 起動
% python ./SlashGPT.py - manifestを選択
You(GPT): /gitm_code - あとは実際の質問プロンプトを入力するだけです。以下のように外部サービスのAPIの応答を利用しないと答えられない質問にも答えてくれます!
例1:
You(gitm_code):Github graphql で snakajima/SlashGPT repo の mainブランチでcontributor ごとのcommit数を日毎に集計し、時系列グラフで表示して
-
APIで実行した結果を、JupyterNotebookで実行した結果のグラフがポップアップされます。
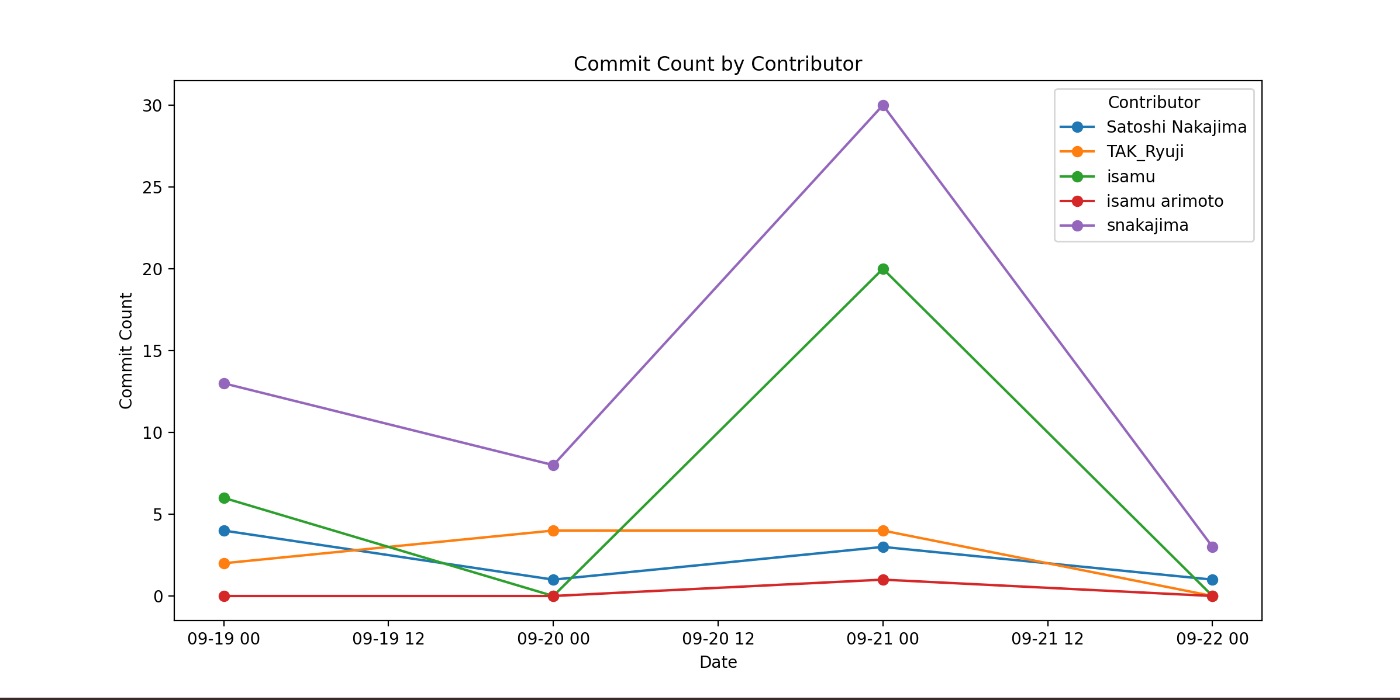
-
ポップアップしたグラフを閉じると下記のパスに対応するNotebookが連番格納されています
output/notebooks/notebookXX.ipynb
-
下記の記事を参考に、自分で編集、追加実行することもできます(デバッグのときによく使います)
https://zenn.dev/singularity/articles/718cba24bf1275
注意:どんな回答にも正確に答えてくれるわけではないです。たとえば上記の質問を直近1ヶ月のとかえると正しく解釈してくれません。このあたりは与えるAPI仕様を関係ある部分はフルセットで入力することと、promptを工夫するといったことが考えられます。
また答えの内容が正しくないこともありますので、最初は自分たちが正解を知っている質問でためしてみてください。SlashGPT上で/verboseと入力すると詳細のログも出力されるので製品レベルにするには、APIの応答、GPTへのリクエスト、応答等 地道に追っていくことも必要になると思います。
Python runtimeでよく発生するエラーと、デバッグ方法
context length error
以下のようなエラーが出た場合は、GPTに送信しているTokenが長すぎます。
Exception: Restarting the chat :This model's maximum context length is 16385 tokens. However, your messages resulted in 16431 tokens (16375 in the messages, 56 in the functions). Please reduce the length of the messages or functions.
API仕様やManifestでのPrompt定義、Programに出力させるテキスト等を調整して短くしましょう。
また、SlashGPTではAgentを切り替えたときセッションごとに過去の会話も含めた形でGPTに送信しています。何回か会話続けてからerrorが発生した場合は/newと実行することで過去の会話を忘れてくれ発生しなくなる場合もあります。
API実行権限ないので応答の型が異なる
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
File <ipython-input-1-4003c3c8f6c1>:28
25 data = response.json()
27 # Extract your login name from the response
---> 28 login_name = data['data']['viewer']['login']
30 # Return your login name
31 login_name
KeyError: 'data'
デバッグ方法としては、実際にdataに何がはいっているかを確かめるためjupyter_notebookのセルを分割して、直前のdataを出力してみます。
原因としては下記のように GPTが出力したコードに正しく.envの変数が反映されていないということがあります。
# Set your GitHub personal access token
token = 'YOUR_PERSONAL_ACCESS_TOKEN'
修正方法はpromptの指示を上記API Secretの渡し方を参考に見直します。
responseの解釈失敗
上記と同じような KeyErrorが発生した時に原因が、responseの構造を正しくparseできていないということもあります。そのようなときも細かくnotebookのcellをsplitして実行して、原因を確定させます。修正方法としてはAPIの仕様定義で出力がただしく定義できているかということをチェックします。
まとめ
OpenAIのfunctions+IPython+SlashGPTを利用することで、自分のAPI仕様を追加し、manifestを追加するだけで優秀なソリューションエンジニアを雇うのと同等なことが実現できます!
商用レベルにもっていくまでにはresource定義、prompt定義のデバッグが重要です!

人工知能を活用したアプリケーションやサービスを活用し、内発的動機付けで行動するエンジニア、起業家、社会起業家をサポートするコミュニティーです。 singularitysociety.org Supported by 週刊 Life is beautiful
Discussion