👤
Kaggle PII Data Detection 振り返り
以下のコンペについて、まとめました。
何をするコンペか
生徒が書いたエッセイから、個人情報(personally identifiable information, pii)をBIO形式で見つけるタスクである。
- 例:
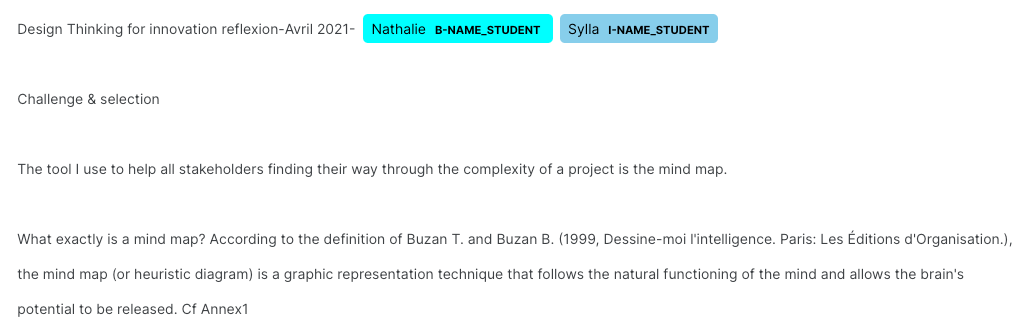
BIOタグの種類とその数は以下である。

評価方法は?
- 指標はf5scoreである。
- 式とグラフ

- Precisionは0.2ぐらいあれば、f5scoreは0.9になりうる
- recallにはほぼ比例する
- 式とグラフ
- 評価はSpaCy English tokenizerのトークン単位で行われる
特徴は?
- 極端に少ないラベルが存在するため、外部データセットの利用が公式から推奨されていた。
- ラベルは、文書の最初と最後に登場しやすい。
- positionとラベル登場頻度のグラフ
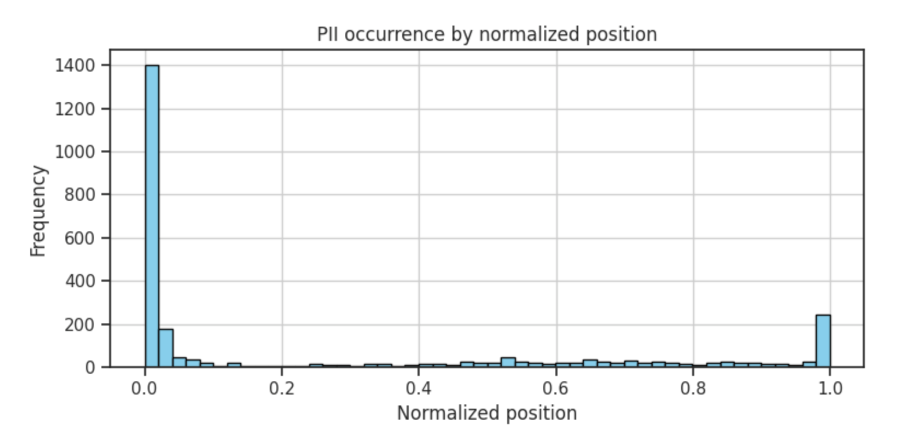
- 引用元: https://www.kaggle.com/competitions/pii-detection-removal-from-educational-data/discussion/473011
- positionとラベル登場頻度のグラフ
- 個人情報の一つである、 NAME(生徒の名前)について、piiと、名前だが生徒名ではない(例えば、著者名、有名人)をモデルが区別するのが困難であった。
- これはpii

- これ(Srinivasan K.,Vivek S.)はpiiではない

- これはpii
publicな手法は?
- Presidio(Microsoftの匿名化SDK)
- DeBERTaによるTokenClassification
- llmとfakerを用いた生成によるデータ拡張
- Oの確率が0.X以下なら、次に確率の高いラベルを出力する。
- f5scoreはrecallを重視する指標であるため、有効だった。
- 正規表現を用いて、電話番号やURLを判定する。
「llmとfakerを用いたデータ拡張」の詳細
多様な方法が試されていた。その中でも、上位ソリューション(後述)にて多く利用されていた、NICHOLAS BROAD(nbroad)さんのデータセット作成方法についてまとめる。
- Mixtral-8x7B-Instruct-v0.1に、faker(ダミーデータ生成ライブラリ)を元にしたダミー個人情報を含むpromptを与えて、データを生成させる。
- prompt
Write an essay that details your experience of applying a specific tool or approach to address a complex challenge. This essay should not only narrate the process but also critically analyze the effectiveness of the chosen tool or approach, reflecting on its strengths and potential limitations.
- promptには、persona(その人がどのような人物か)の情報を与える。(この情報も生成した。)
- personaの例

- personaの例
あなたのチームのソリューションは?

- 複数の外部データによるアンサンブルを行った。
- 外部データごとに得意なラベルが異なっていたため、アンサンブルで良いとこどりがしたかった。
- tokenizerのtruncationをfalseにした。
- データの最後にラベルは集まるため、文章の最後のラベルを漏らさず出力するため。
- spacyトークン単位の提出ファイルについて、B→Iの関係性が正しくなる保たれるよう後処理を行った。
- データの匿名化に由来したパターンで後処理を行った。
- 提供データはおそらく、元々個人情報が載っていたテキストを、fakerを使って匿名化したデータであると推測されていた。
- 匿名化の際に発生するパターンが見つけ、ラベル付けに利用した
- 例 nameは必ずキャメルケースである。\nは必ず住所である。
- ONNX化を行い、推論速度を30%改善することで、アンサンブルするモデルを10→12に増やした。
詳細
- 効かなかったこと
- B-[PII], B-[PII], I-[PII]での学習を、B-[PII], I-[PII], I-[PII]など、 TokenClassificationとして正しいラベル順にして学習する
- 生徒名でない名前を加えた独自の生成データセットで学習を行う
- PIIタイプごとに閾値をチューニングを行う
- LightGBMで第二ステージ推論する
- deberta modelsのpredictionsを特徴量として利用した
- DeBERTa TokenzierのToken区切りをSpacyのToken区切りに変換し、学習、推論した
- 誤字・脱字の修正を行う
pii Top Solutionまとめ
| rank | model backbone | Training Method | model数 | max_length | stride | CV Strategy | additional data | ensemble method | PostProcess | その他 | URL |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | deberta(おそらくv3-large) | - PIIが存在しないデータは削除しなかった - o_weight = 0.05 - lstm layerを追加した - Knowledge Distillation(学習済みの教師モデルが出力するlogitを正解として学習した。) - 予測クラスは13 labels(本来は15、多分trainに存在しないI-[PII]を削除したのだと思う。) |
10 | 1600~2048 | なし | ? | - nbroad - mpware |
weighted voting ensemble - 重みつけsoftmaxの出力値の和を計算し、voteing_thr以下は出力しない - 値はCVに対しOptunaで計算した - 各モデルごとに、softに最適な閾値を決定するため |
- ラベルごとに閾値を設ける - NAME_STUDENTがキャメルケースかどうか 他多数 |
- | link |
| 2 | deberta-v3-large | - is_split_into_wordsを利用した。単語が複数のトークンで表現される場合の平均出力確率を利用した。 - ターゲットからB-とI-接頭辞を除去し、予測するクラスを7つに絞った。 - full train |
6 | 512, 1024 and 2048 | 32 | ? | - nbroad(weightを0.5で利用) | ?(bag of 6 models) | - 長さ1とキャメルケースではないNAME_STUDENTをOにした。 | - | link |
| 3 | deberta-v3-large | - mpwareでpretrainingを行う - competition + nbroadでFine tuning |
1 | ? | なし | PIIの有無 | - mpware - nbroad |
- | - Oによる閾値 - (多分)I-NAME始まりを B-NAMEに修正する |
- | link |
| 4 | deberta-v3-large | - Focal Loss - BiLSTM and GRU head - 空白文字を全て[SPACE]としてTokenizerに追加 - optunaを用いて、異なるモデルに対する最適な重みと閾値を取得した。 |
10 | Training - 1280 Inference - 4000 |
1024 | Stratified based on PII | - nbroad - 自分で生成(やり方はhttps://www.kaggle.com/competitions/pii-detection-removal-from-educational-data/discussion/472221) - train.jsonのPIIでないデータの人名を言い換えて、データセットとして追加する。言い換えにはhttps://huggingface.co/kalpeshk2011/dipper-paraphraser-xxl(言い換え用の生成モデル)を利用する。 |
? | - 数字を含むSTUDENT_NAMEを削除 - instructor namesを削除 |
unicodedataによる正規化 | link |
| 5 | deberta-v3-large | - full train - Oのweightを小さくする - lstm layerの追加 - B- I-は使わず、NAME_STUDENTなどをラベルに利用 - freeze layer |
12 | Training/Inference - 128/128 - 512/512 - 1536/4096 |
384 | ? | - nbroad - mpware - pjmath |
vote | - 空白の削除 - B, Iを正しくする - 正規表現 - 冠詞の有無( The の後に名前以外がくる、など) |
AMP(推論時間削減) | link |
- 共通しているのは
- deberta-v3-large
- nbroad、mpwareのデータを利用
- max_lengthを設定している(truncation=Falseではない)
Discussion