論文まとめ: FlashAttention
はじめに
transformer の AutoModelForXX などで、FlashAttention がよく使われる。この FlashAttention がどのような仕組みなのか気になったため調べて、自分の理解のためにまとめた。
論文メタ情報
タイトル
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
URL
著者

論文詳細
概要
- Attention機構は、速度が遅く、多くのメモリを消費する。具体的には、シーケンスの長さの2乗必要である。
- 従来の手法は、GPU メモリのレベル間の読み取りと書き込みを考慮できていないと主張する。
- 私たちは、GPU の HBM と、SRAM 間のメモリ読み取り/書き込み回数を削減する FlashAttention を提案する。
- FlashAttention は、BERT-large(シーケンス長512)では15%、GPT-2(シーケンス長1K)では3倍、ロングレンジアリーナ(シーケンス長1K-4K)では 2.4 倍の高速化を実現した。
- FlashAttention は元の Attention と厳密に一致する。一方、元の Attention に対して、近似を行うBlock-Sparse FlashAttention も提案する。
- Block-Sparse FlashAttention は、Transformer のより長いコンテキストを可能にし、GPT-2 で 0.7 パープレキシティの改善、ロングドキュメント分類で 6.4 ポイントの向上した。また、Path-X(シーケンス長 16K、精度 61.4%)とPath-256(シーケンス長 64K、精度 63.1%)において、パフォーマンスが改善した。
背景
Transformer の中核となる Self-Attention は、時間と必要メモリがシーケンス長の 2 乗であるため、より長いコンテキストを利用することが困難である。
対策として、計算量とメモリ使用量を削減することを目的に、多くの Attention を近似する手法が存在する。例えば、スパース近似、低ランク近似、それらの組み合わせなどである。これらの手法は、シーケンス長に対して計算量を線形またはほぼ線形に削減するが、その多くは Attention に対して wall-clock の高速化を示さず、広く採用されていない。
主な原因の一つは、これらのアルゴリズムが FLOP 削減に焦点を当てており、メモリアクセス(IO)のオーバーヘッドを無視している点である。つまり、現在の Attention 機構は、計算速度よりも、メモリアクセスがボトルネックになっている。
従来の手法
Flash Attention の説明をするために、まずは GPU の仕組みについて説明する。GPU には、SRAM と HBM が存在する。SRAM は HBM よりも読み書きが高速だが容量は少なく、HBM は SRAM よりも読み書きが遅いが容量は大きい。
次に、従来の Self-Attention の仕組みについて説明する。論文中には以下のように紹介されている。

HMB 上に Query, Key, Value が存在する時に、4 つのステップが必要である。
- HBM上から
\mathbf{Q} \mathbf{K} \mathbf{S} = \mathbf{QK^T} \mathbf{S} - HBM上から
\mathbf{S} \mathbf{P}=softmax(\mathbf{S)} \mathbf{S} - HBM上から
\mathbf{P} \mathbf{V} \mathbf{O} = \mathbf{PV} \mathbf{O} -
\mathbf{O}
この方法には、2 つの課題がある。1 つ目は、中間生成物である
提案手法
以下に提案手法の概要図を示す。

FlashAttention では、従来手法の 2 つの課題を Tiling, Recomputation という手法を用いて解決している。
まず、Tiling では、Query, Key, Value をブロック単位に分割し SRAM にコピーする手法である。Tiling により、遅い HBM 上ではなく、高速な SRAM 上で計算を行うことができる。Figure 1 の真ん中がそのイメージを示している。
次に、Recomputation は、巨大な中間結果を保存するのをやめ、必要になったときにもう一度計算し直す手法である。具体的には、
実験結果

Table1 より、NVIDIA MLPerf(BERTモデルの学習ベンチマーク結果)よりも、Flash Attention の方が早い。

Table2 より、Huggingface や MegatronLM より、Flash Attention の方が学習時間が短い。

Table3 より、vanilla Transformer(通常の Transformer)よりも、FlashAttention を用いた Transformer の方が 2.4 倍、学習速度が速くなった。FlashAttention が、通常の Attention に対して計算が厳密に一致するが、Attention を近似させるアルゴリズムである Block-sparse FlashAttention では、2.8 倍、学習速度が速くなった。
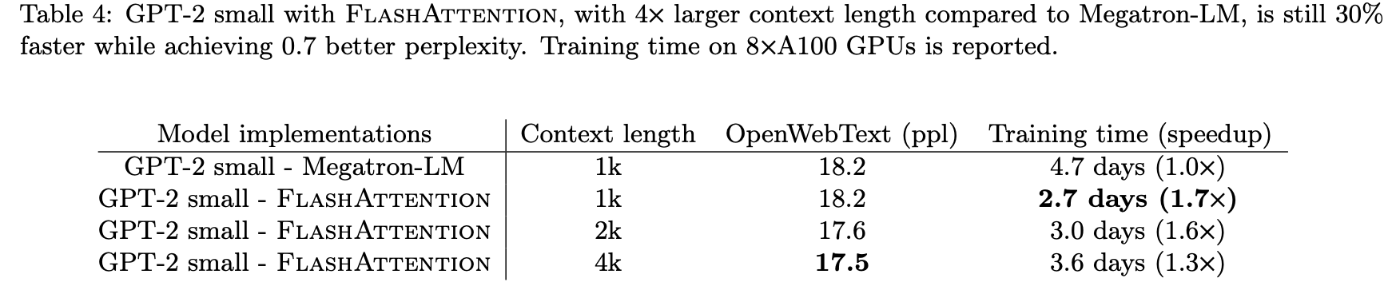
Table4 より、GPT-2 small について、Megatron-LM で 4.7 日かかる学習が FlashAttention では 2.7 日で終わったことが分かる。これは、1.7 倍の高速化である。

Figure3 の左より、FlashAttention は正確なアテンションのベースラインよりも大幅に高速に実行されることが分かる。Figure3 の右より、Pytorch Attention より FlashAttention はメモリ効率が約 20 倍良い。
おまけ 実装面
論文内では触れられていないが、実装面についても紹介する。基本的に Flash Attention が利用できる場合には、自動的に利用される。
ドキュメントとしては以下を参照。
All implementations are enabled by default. Scaled dot product attention attempts to automatically select the most optimal implementation based on the inputs.
そのため、以下のようなコードでモデルを呼び出すと、(利用できる環境であれば)裏側では Flash Attention 2 が利用されることに注意すること。
import torch
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.2-1B-Instruct",
torch_dtype=torch.float16,
device_map="cuda",
# attn_implementation="flash_attention_2", # 明確に指定したい場合はコメントアウトする
# attn_implementation="eager", # flash_attention_2を利用しない場合はコメントアウトする
)
ここで「利用できる環境」とは、Flash Attentionのライブラリがインストールされていることを指す。また、ハードウェア環境やtorch、CUDAなど他のライブラリとの関係性は以下のrepoの公式ドキュメントに記載されている。
思ったこと
- Attention と GPU の特性の両方を考えると、容量が大きいが計算が遅いHBMより、容量が小さいが計算が早い SRAM を使った方が良いよね、というシンプルな発想を数式で証明し、実装面も含めて提供しきっていることが凄い。
- LLM の仕組みとハードウェアの両方を考慮した効率化ネタは、探せば結構あるのかもしれない。
Discussion