当社では複数の SaaS プロダクトを開発・稼働するための環境として、主に AWS を利用しています。AWS 等のシステムにかかるコスト構造を正確に把握することは、プロダクト原価の算定や適正なプライシングを行う上で非常に重要です。
今回、カスタム定義のコストカテゴリ体系を各種 AWS リソースにかかるコストに適用し、継続的にモニタリングするための仕組みを構築してみたので、本記事ではその内容についてご紹介したいと思います。
概要
まず、実装を試みたコストカテゴリ設計の考え方について説明します。
次に AWS Cost Categories で実装する際の課題感に触れた後、今回利用する AWS Cost and Usage Report (CUR) について紹介します。
コストカテゴリ設計
コストカテゴリのレベルとして、以下の 3 つを定義しました。
- Level-1 ... プロダクト原価を構成する費用 (Product) か、それ以外 (Platform) か
- Level-2 ... Level-1 が Product の場合はいずれのプロダクトに該当するか、Platform の場合は主な用途は何か (Security, Analitycs ... etc.)
- Level-3... 固定費 (Fixed Costs) か、変動費 (Variable Costs) か
AWS にかかる全てのコストが、それぞれのレベルで分類されることになります。例えば、プロダクト A で利用される RDS データベースのコストであれば、[ Product, ProductA, Fixed ]、データ分析基盤の Redshift Serverless でのクエリ実行にかかるコストであれば [ Platform, Analytics, Variable ] といった具合です。

また、複数のプロダクト・用途から利用されるような AWS リソースもあるため、その場合は利用実態などを考慮し、適切な割合にて各カテゴリにコスト配賦したいという要件を定めました。
AWS Cost Categories の課題感
AWS をコストを分類するための機能として、AWS Cost Categories があります。この機能を利用すると、以下のようなことを実現できます。
- 特定の属性(アカウント・料金タイプ・サービス・使用タイプ・コスト配分タグ 等)の値に基づいて条件を設定し、コストを分類できる。
- 条件を満たすコストを、特定のグループのみに対して配賦することも可能だが、複数グループに対して等分に配賦することもできる。
- Cost Categories で作成したコストカテゴリでの分類結果を、別のコストカテゴリ作成時にも利用・継承できる。
コスト構造を把握する仕組みを実装する際、当初この Cost Categories を利用しようと考えていました。しかし、上記 2 つ目に記載した点について「等分にしか配賦できない」というのが要件を満たす上で問題になりうると考えました。
例えば、以下のようなコスト配賦を実現しようと思った際、配賦割合 (X-Z, M-N) を自由に設定できないことになります。
- ある ECS サービスの稼働コストとして、X% を Product A, Y% を Product B, その他 Z% を Platform (Analytics) に配賦する。
- ある RDS データベースの稼働コストに対して、M% を Product A, その他 N% を Platform (Analytics) に配賦する。
AWS Cost and Usage Report (CUR) について
そこで、AWS Cost and Usage Report (CUR) の利用を検討することにしました。CUR は、AWS コストと使用状況に関する詳細なレポートを提供します。これにより、AWS Cost Explorer で参照・分析できる情報を、Athena や Glue といった他サービスから分析(集計・変換)することが可能になります。
AWS コストをサービス毎・リソース名毎などで集計したデータを Glue で処理できれば、独自に用意した CSV データソースなどを用いて柔軟なコスト配賦を実現できると考えました。
アーキテクチャ
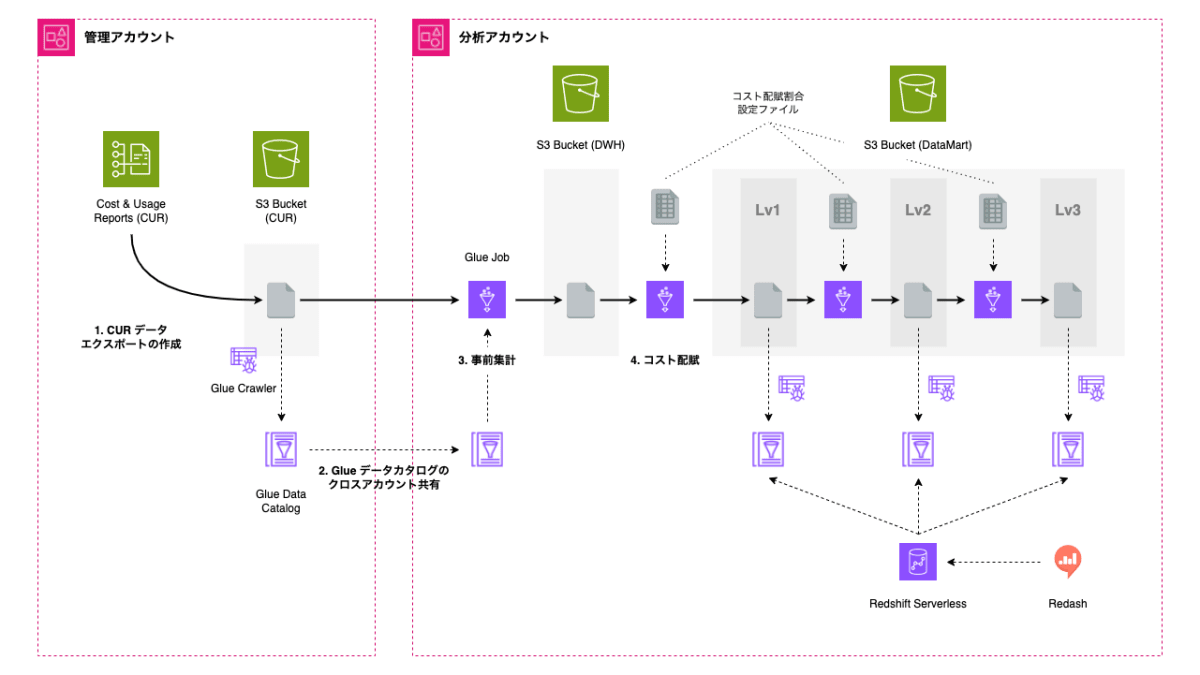
実装したアーキテクチャは以下のようなものです。
AWS Organizations を用いたマルチアカウント構成となっている場合、組織全体の請求情報は管理アカウント(Payer アカウント)に集約されるため、CUR データエクスポート設定を管理アカウントにて作成します。
Glue クローラーによって作成されたデータカタログを、AWS RAM というサービスを利用して分析アカウントに共有し、複数の Glue ジョブで必要な集計処理を実行します。データカタログ化された集計結果に対して、Redshift Serverless を分析エンジンとして Redash 上でクエリし、ダッシュボード化します。
作成したダッシュボード
具体的なプロダクト名や金額などは伏せますが、以下のようなダッシュボードを作成しました。
コストカテゴリレベル毎の各カテゴリが占める割合や、月別のコストカテゴリ割合の推移などを表示しています。また、未分類コストの上位リソースも表示しておくことで、未分類コストの割合を一定以内に維持するのに役立ちます。

実装
以下のような流れで進めます。
1. CUR データエクスポート設定の作成
まず、組織の管理アカウントにて CUR データを S3 に出力するためのデータエクスポート設定を作成します。マネジメントコンソールから作成する場合は、[請求とコスト管理 (Billing and Cost Management)] - [データエクスポート] から作成します。
エクスポートタイプとしていくつか選択肢がありましたが、Terraform の AWS Provider (5.42.0) で作成できるタイプが「レガシー CUR エクスポート」のみであり、特に困ることもなかったため本記事ではこちらのレポートタイプの利用を想定します。

出力先の S3 バケットには、CUR データエクスポートのために必要なバケットポリシーを設定しておく必要があります。詳細は 公式ドキュメント をご確認ください。
データエクスポートが作成されると、出力先 S3 バケットには以下のような構成になります。
s3://empample-cur-bucket/
├── aws-programmatic-access-test-object/
└── legacy/
└── all/
├── 20240501-20240601/
│ ├── all-Manifest.json
│ └── all-create-table.sql
├── all/
│ └── year=2024/
│ └── month=5/
│ ├── all-00001.snappy.parquet
│ ├── ...
│ └── all-00005.snappy.parquet
├── cost_and_usage_data_status/
│ └── cost_and_usage_data_status.parquet
└── crawler-cfn.yml
以下の S3 パスのデータを Glue クローラーでデータカタログ化しておきます。
s3://empample-cur-bucket/legacy/all/all/
2. Glue データカタログのクロスアカウント共有
管理アカウントで作成した CUR の Glue データカタログを分析アカウントで利用できるよう、AWS RAM を利用してクロスアカウント共有します。具体的な手順については以下のエントリに書いているので、よろしければ併せてご覧ください。
3. 事前集計
分析アカウントにて、CUR データの Glue テーブルを参照可能になりました。ただし、CUR の元データは様々な切り口でドリルダウン分析できるよう、超多次元細粒度の状態で保存されています。(コスト配分タグの数等にも依存しますが、以下の例では 237 ものカラムが存在しています)

当然データ量もかなり大きくなってしまい、そのままでは毎回不要な集計処理が必要になって扱いづらいため、分析に用いる可能性のあるカラムを残して事前に集計しておきます。
例えば、Glue ジョブスクリプトにて DataFrame 読み込み時に以下のような集計を施し、対象年月の他に AWS サービス名とコスト配分タグ(Nameタグ)のみを残して次元圧縮してみます。これにより、ある月の CUR データサイズを約 430 MB → 約 42 KB まで削減できました。
RESOURCE_ID_COLUMNS = [
"line_item_usage_account_id",
"product_servicecode",
"resource_tags_user_name",
]
COST_COLUMN = "line_item_blended_cost"
def load_cur_org_df(target_year: str, target_month: str) -> DataFrame:
df = glueContext.create_dynamic_frame.from_catalog(
database=SRC_GLUE_DATABASE,
table_name="legacy_all",
push_down_predicate=f"year = '{target_year}' and month = '{target_month}'",
).toDF()
# Select, drop, and cast columns
cur_columns = [*RESOURCE_ID_COLUMNS, COST_COLUMN,]
df = df.select(*cur_columns)
df = df.withColumn(COST_COLUMN, F.col(COST_COLUMN).cast(DoubleType()))
# Aggregation
df = df.groupBy(RESOURCE_ID_COLUMNS).sum(COST_COLUMN)
df = df.withColumnRenamed(f"sum({COST_COLUMN})", "cost")
return df
4. コスト配賦
事前集計済みの CUR データと、コスト配賦割合設定ファイルのデータを用いて、Glue ジョブでコスト配賦の処理を実行します。コスト配賦割合データは、CUR データと結合 (Join) しやすいよう横持ち変換 (Unpivot, Melt) しておきます。
各リソースのカテゴリ毎の配賦割合が決定したら、元の合計額と掛け合わせて配賦後コストを計算します。また、コスト配賦割合データで定義されないリソースのコストについては未分類コスト (unclassified) として識別できるようにしておきます。
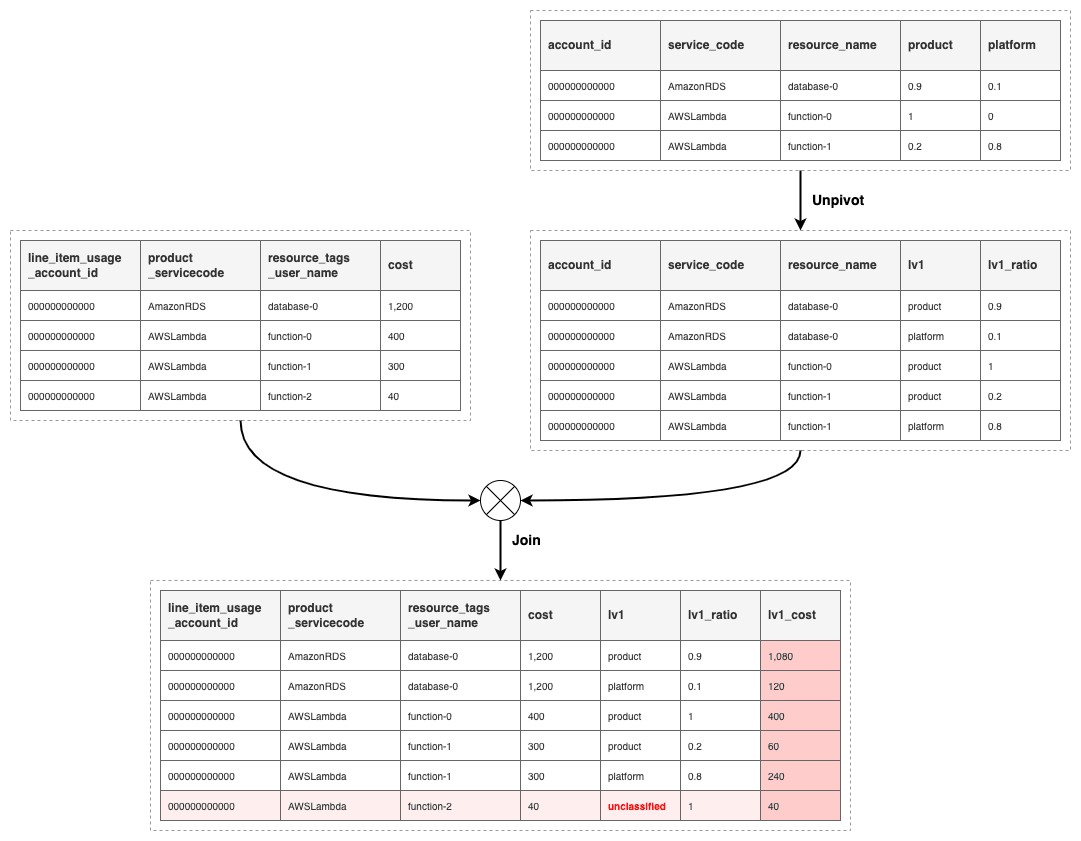
コストカテゴリ Lv1 のコスト配賦処理のイメージ
上の図はコストカテゴリ Lv1 における処理のイメージですが、Lv2, Lv3 についても考え方は同様です。(ただし Join する際の結合キーは1つずつ増えます)
一連の処理を AWS Step Functions ステートマシンとしてワークフロー化しておくと、BI ダッシュボードの自動更新なども実現できます。
実装についての説明は以上です。
さいごに
AWS コスト構造の継続的なモニタリングというテーマで書いてみました。
初期段階から AWS アカウントをマルチアカウントで構築し、プロダクト毎・用途毎に完全にアカウントを分離できていれば、もっと簡易な方法で目的を達成できるかもしれませんが、現実的にはなかなかそうもいかないのではないかと思います。本記事が、読者様における FinOps 実践の参考になれば幸いです。
最後まで読んで頂き、ありがとうございました。

Discussion