レシピサイトをクローリングして健康になった気になってみた
はじめに
エンジニアの @infinity0206 です。近年健康診断の数値が悪くなっており、そろそろ運動しないとやばそうです(しません)
本記事は SimpleForm Advent Calendar 2023 の7日目です。今回は社内で法人データのwebクローリングにも活用されている Scrapy についてお話しします!
膨大なクローラの管理
弊社では SimpleCheck という法人情報を調査することのできるSaaSを開発しています。このサービスの一番根幹とも言える部分が法人データの管理になります。
web 上のデータ収集にはクローラを別途開発して運用しており、クローリング対象となるデータソースは現在50近くに及びます。それだけ数が存在するとただでさえメンテナンスは大変になってくる上に、他のアプリケーションと独立した機能であるが故にどうしてもコードの統一感が失われて読みづらくなっていきます。あとアプリケーションへの直接的な影響が出づらい点からメンテナンスが劣後になりがち問題。ひぃ...
ということもありまして、ある程度管理しやすい方が良いよねということで、社内ではクローラの可読性向上を目的とし Scrapy というフレームワークの導入を推進しています。
Scrapyとは
説明しようと思いましたが、めんどくさ(ry公式読んでいただいた方が早そうなので割愛しました。
Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pages. It can be used for a wide range of purposes, from data mining to monitoring and automated testing.
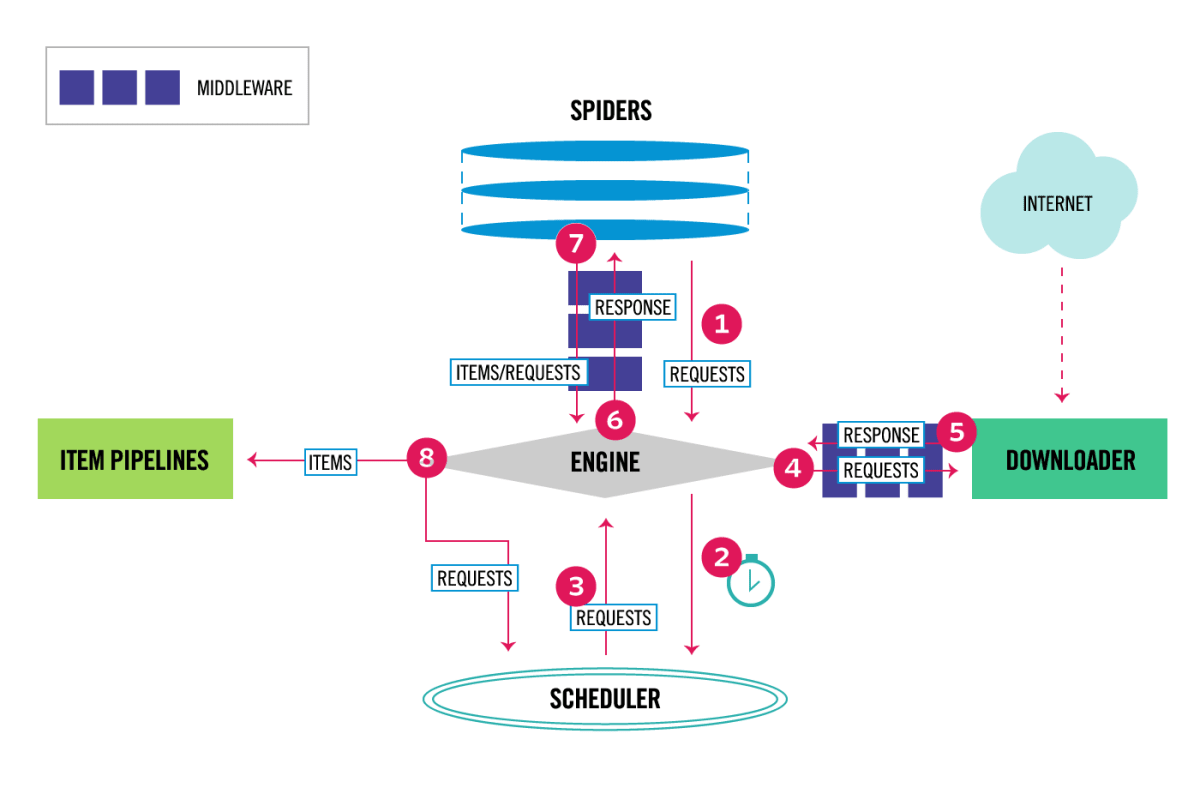
The data flow in Scrapy is controlled by the execution engine, and goes like this:
- The Engine gets the initial Requests to crawl from the Spider.
- The Engine schedules the Requests in the Scheduler and asks for the next Requests to crawl.
- The Scheduler returns the next Requests to the Engine.
- The Engine sends the Requests to the Downloader, passing through the Downloader Middlewares (see process_request()).
- Once the page finishes downloading the Downloader generates a Response (with that page) and sends it to the Engine, passing through the Downloader Middlewares (see process_response()).
- The Engine receives the Response from the Downloader and sends it to the Spider for processing, passing through the Spider Middleware (see process_spider_input()).
- The Spider processes the Response and returns scraped items and new Requests (to follow) to the Engine, passing through the Spider Middleware (see process_spider_output()).
- The Engine sends processed items to Item Pipelines, then send processed Requests to the Scheduler and asks for possible next Requests to crawl.
- The process repeats (from step 3) until there are no more requests from the Scheduler.
一応まとめると、Scrapy のアーキテクチャとしては、Spiders、Items、Pipelines のように大きく3つ分けられます。web ドライバなどのめんどくさい設定も、BeautifulSoup などの HTML パーサーなども個別に入れる必要はなく、Scrapy に全て機能が載っています。()
-
Items:取得したいデータ構造を定義する
- Spider から取得したデータは、これを経由して Pipeline や Middleware で操作を行うことができる
-
Spiders:web サイトへのクロール方法を定義する
- HTTP クライアントと HTML パーサーがデフォルトで搭載されている
- 並列処理に長けており、高速で効率的なクロールが可能
-
Pipelines:抽出したデータに対する加工
- Items に関する後処理を記述できる
- データの整形、DB への登録処理、ファイル出力処理、データバリデーション等
-
Middlewares:独自ミドルウェア
- Spider の実行前後、web サイトへのリクエスト前後などのイベントで差し込みで処理を入れることがでたりとかも可能
-
その他
- 独自の CLI コマンドを提供しており、デバッグに関する機能なども豊富です。
- 詳しくはこちらを参照ください。
さっそく開発!の前に、、
クローリングはアクセス先の web サイトに負荷を与えてしまう可能性があります。
例えば Amazon だとこのように利用規約が公開されており、データをどこまで利用して良いのか第三者へ公開しても良いのかなど細かく書かれています(「利用許可およびサイトへのアクセス」に記載があります)。クローリングを実施する場合は、必ず対象サイトの利用規約を遵守の上、負荷をかけないよう実施をお願いします。
また、利用規約に書かれていないからといって負荷をかけて良いわけではありません。モラルを守って実施するようにしましょう。
注意を促すため、1つ怖い事例をおいておきます。librahack事件(こわい)
Scrapy 使っていく
今回は僕が健康になれそうなレシピを公開しているレシピサイトをクローリングしてみたいと思います。
次の手順で実装します。
- レシピサイト上の人気キーワードごとに検索し一覧ページを取得する
- 一覧ページからレシピURLを取得する
- レシピ URL に移動し、レシピ情報を取得する
- 結果をファイルに出力する
なおここでは架空のドメインや URL で記述しております。ご了承ください。
Scrapy スパイダーの作成
まずは Scrapy をインストールします。
pip install scrapy
Scrapy プロジェクトを作成します
scrapy startproject crawl_recipe
作成したプロジェクトに移動し、scrapy genspiderコマンドで Spider の雛形を作成します。
実行するとcrawl_recipe/spiders以下にrecipe.pyという Spider が作成されます。
cd crawl_recipe
scrapy genspider recipe (webサイトのドメイン)
Scrapyの設定
Scrapy プロジェクトを作成後、プロジェクト配下にsettings.pyというファイルが作成されます。デフォルトだとrobots.txtの参照設定くらいしかないので、確認しておきましょう。
先述の通り、クローリングは便利は反面webサイト側に負荷をかけてしまう可能性があるので、特にリクエストレートなどのパラメータは注意が必要ですね。
Itemに取得する情報を決める
Scrapy では Item に scrapy.Item でスキーマを定義するというのが標準ではありますが、バリデーションの実装をある程度省くことができるので社内では代わりに Pydantic を使用しています。
社内ではバリデーションで弾かれる場合についてなどかなり細かくハンドリングを実施してますが、今回は割愛しています。
ちなみに Spider から取得したデータを Items に変換する操作を Pipeline という機能でハンドリングすることができるので、もし Pydantic を利用せずにバリデーションを実施したい場合は Pipeline に独自バリデーションを実装する必要がありそうです。
取得する情報は下記にしてみました。
from pydantic import BaseModel, Field
from pydantic.networks import AnyHttpUrl
class Property(BaseModel):
recipe_name: str = Field(title="レシピ名")
url: AnyHttpUrl = Field(title="URL")
energy: int = Field(title="エネルギー(kcal)")
salt: float = Field(title="塩分(g)")
protein: float = Field(title="タンパク質(g)")
vegetable_intake: float = Field(title="野菜摂取量(g)")
Spider を実装する
なんやらかんやら実装したものがこちらになります。フレームワークなしだと結構ごちゃごちゃしそうな操作が割とスッキリ書けていますね。
基本的にはクロールの起点となる URL を start_urls に定義し、そのページの HTML に対する処理を parse() に記述する形になります。ただし、ここでは何回かページ遷移をしないと目的のページに辿り着けないため、parse() 内でさらに別の URL にリクエストするというようなことをしています。(parse() -> __parse_recipe_urls() -> __parse_recipe_items() のように複数回リクエストを送っています)
この scrapy.Request メソッドでコールバックに設定したメソッドに適切に response を渡せるので便利ですね。ちなみに parse() 内でコールバックに parse メソッドを指定すると、再帰的なクローリングもできるようです。
import scrapy
from scrapy.responsetypes import Response
from crawl_recipe.items import Property
class RecipeSpider(scrapy.Spider):
name = "recipe"
allowed_domains = ["xxx.dokokanorecipesite.jp"]
start_urls = ["https://xxx.dokokanorecipesite.jp/"]
def parse(self, response: Response):
keywords = self.__parse_keywords(response)
for kw in keywords:
url = f"https://xxx.dokokanorecipesite.jp/?search={kw}"
yield scrapy.Request(
url, callback=self.__parse_recipe_urls
)
def __parse_keywords(self, response: Response) -> list[str]:
return [
element.css("::text").get()
for element in response.css("#content > div > div > div.wordList02.type01 > ul> li")
]
def __parse_recipe_urls(self, response: Response):
for recipe_url in [ li.css("div.img > a::attr(href)").get() for li in response.css("#popularityList > ul > li")]:
yield scrapy.Request(
recipe_url, callback=self.__parse_recipe_items
)
def __parse_recipe_items(self, response: Response):
properties = response.css("#recipeCard > div.recipeCardSpOrderWrap > div.wrap820.recipeCardSpOrder5 > div > div > div > div > div > ul")
_recipe_name = response.css("#recipeCard > div.recipeArea > div.recipeTitleAreaType02 > div > div > h1 > span::text").get().strip()
_energy = properties.css("li:nth-child(1) > div > span:nth-child(2)::text").get().split(" ")[0]
_salt = properties.css("li:nth-child(2) > div > span:nth-child(2)::text").get().split(" ")[0]
_protein = properties.css("li:nth-child(3) > div > span:nth-child(2)::text").get().split(" ")[0]
_vegetable_intake = properties.css("li:nth-child(4) > div > span:nth-child(2)::text").get().split(" ")[0]
yield Property(
recipe_name=_recipe_name,
url=response.url,
energy=_energy,
salt=_salt,
protein=_protein,
vegetable_intake=_vegetable_intake,
)
Spiderの実行
Scrapyにはデフォルトで実行用のコマンドがついてます。次のコマンドでspiderを実行できます。ズラズラとログがでます。
% scrapy crawl recipe -o output.csv
2023-12-06 02:58:16 [scrapy.utils.log] INFO: Scrapy 2.11.0 started (bot: recipe)
2023-12-06 02:58:16 [scrapy.utils.log] INFO: Versions: lxml 4.9.3.0, libxml2 2.9.13, cssselect 1.2.0, parsel 1.8.1, w3lib 2.1.2, Twisted 22.10.0, Python 3.9.16 (main, Mar 18 2023, 04:06:10) - [Clang 14.0.0 (clang-1400.0.29.202)], pyOpenSSL 23.3.0 (OpenSSL 3.1.4 24 Oct 2023), cryptography 41.0.7, Platform macOS-14.1.1-arm64-arm-64bit
2023-12-06 02:58:16 [scrapy.addons] INFO: Enabled addons:
2023-12-06 02:58:16 [asyncio] DEBUG: Using selector: KqueueSelector
2023-12-06 02:58:16 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.asyncioreactor.AsyncioSelectorReactor
2023-12-06 02:58:16 [scrapy.utils.log] DEBUG: Using asyncio event loop: asyncio.unix_events._UnixSelectorEventLoop
2023-12-06 02:58:16 [scrapy.extensions.telnet] INFO: Telnet Password: 01352dc5e03e7796
2023-12-06 02:58:16 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage',
'scrapy.extensions.feedexport.FeedExporter',
'scrapy.extensions.logstats.LogStats']
2023-12-06 02:58:16 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'recipe',
'DOWNLOAD_DELAY': 0.2,
'FEED_EXPORT_ENCODING': 'utf-8',
'NEWSPIDER_MODULE': 'recipe.spiders',
'REQUEST_FINGERPRINTER_IMPLEMENTATION': '2.7',
'ROBOTSTXT_OBEY': True,
'SPIDER_MODULES': ['recipe.spiders'],
'TWISTED_REACTOR': 'twisted.internet.asyncioreactor.AsyncioSelectorReactor'}
2023-12-06 02:58:16 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2023-12-06 02:58:16 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2023-12-06 02:58:16 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2023-12-06 02:58:16 [scrapy.core.engine] INFO: Spider opened
2023-12-06 02:58:16 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2023-12-06 02:58:16 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2023-12-06 02:58:16 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://xxx.dokokanorecipesite.jp/robots.txt> (referer: None)
2023-12-06 02:58:16 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://xxx.dokokanorecipesite.jp> (referer: None)
2023-12-06 02:58:17 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://xxx.dokokanorecipesite.jp/?search=%E3%81%BF%E3%81%9E%E3%82%8C%E9%8D%8B> (referer: https://xxx.dokokanorecipesite.jp)
2023-12-06 02:58:18 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://xxx.dokokanorecipesite.jp/123456> (referer: https://xxx.dokokanorecipesite.jp/?search=%E3%81%BF%E3%81%9E%E3%82%8C%E9%8D%8B)
2023-12-06 02:58:18 [scrapy.core.scraper] DEBUG: Scraped from <200 https://xxx.dokokanorecipesite.jp>
recipe_name='*****' url=AnyHttpUrl('https://xxx.dokokanorecipesite.jp/123456/', ) energy=123 salt=0.1 protein=23.4 vegetable_intake=345.0
また Scrapy では、自前で出力するスクリプトを実装しなくても Items の項目をファイルに出力するオプションが搭載されています。-oオプションで設定できます。ちなみに CSV ファイルを選択すると CSV にも出力することができます。
scrapy crawl recipe -o output.json
出力結果はこんな感じで出力することができます( JSON を出力形式に選択した場合)。
[
{"recipe_name": "◯◯◯スープ", "url": "https://.../", "energy": 100, "salt": 2.1, "protein": 3.0, "vegetable_intake": 4.0},
{"recipe_name": "×××の鍋", "url": "https://.../", "energy": 308, "salt": 7.0, "protein": 50.3, "vegetable_intake": 320.0},
{"recipe_name": "△△△のケーキ", "url": "https://.../", "energy": 327, "salt": 0.2, "protein": 3.2, "vegetable_intake": 0.0},
...
]
まとめ
超簡易的な内容にはなりましたが、Scrapy を使って簡易的なクローリングを試してみました。(本当はもう少し込み入った仕組みを紹介したかったのですが、それはまた別の機会で、、)
スクレイピングとかする際はフレームワーク入れずにゴリっと書いちゃう方が多いかと思いますが、機会があればぜひ Scrapy を使ってみてください!
ちなみに完全な興味本位ですが、収集したレシピデータを分析したところ、エネルギーあたりの野菜含有量で計算すると白菜漬けが一位でした。つまりジャパニーズトラディショナルスタイルな一汁一菜が最強ということがわかりました(適当)。これで来年の健康診断はバッチリです(?)。
SimpleForm のアドベントカレンダー、まだまだ面白い記事が上がる予定なのでお楽しみに!!!
Discussion