非定型 AI-OCR 作ってみた 〜 AI 時代の開発戦略を添えて
シンプルフォーム CTO の小間 (@hkomachi) です。
本記事は SimpleForm Advent Calendar 2023 の2日目です。
大 AI 時代の技術開発戦略
最近の AI 技術革命により、ChatGPT に代表される LLM(Large Language Model: 大規模言語モデル)が普及し、いわゆる AI の民主化が進んでいます。これにより、機械学習についての低レイヤーな知見がなくても世界最高レベルの AI を活用した機能の開発や PoC を迅速に推進できるようになりました。先日の OpenAI DevDay と Microsoft Ignite での発表も衝撃的であり、AI による可能性が日々急速に広がっています。
このようなジェットコースターに乗っているかのような急速な時代変化の中で、私達が取ろうとしている技術開発戦略は大きく3つあります。
戦略 Ⅰ : 民主化された技術をスピーディに組み合わせ、これまで到達できなかった高レイヤーな開発に挑む
戦略 Ⅱ : なかなか民主化されないような領域で低レイヤーな技術開発を行う
戦略 Ⅲ : 独自データが集まる/容易に作れるようなサイクルを作る
それぞれ説明したいのですが、この記事では特に戦略 Ⅰ について説明します。
以前は、機械学習に関する低レイヤーの技術(基礎技術や原理)を持っていなければ、高度な機械学習アプリケーションを作ることができなかったため、そういった基礎技術を一つひとつ積み上げてきた企業が独自性の高いサービスを提供できていました。しかし、LLM の登場により高性能な汎用モデルが一般公開され、多くの企業が積み上げてきた独自技術の優位性は急速に低下しました。
「独自の文字認識技術に強みがある」「独自の音声認識エンジンに強みがある」「独自の文章要約アルゴリズムに強みがある」… こういった主張は LLM 登場以前は成立していましたが、これからは誰もが安価で使える技術になっていきます。これらの分野の基礎研究に投資してきた企業にとっては大きなショックだと思います。
一方で、私たちのような「先頭集団にいなかったランナー」にとっては、一気に先頭に躍り出れる可能性がある大チャンスです。現代のビジネス環境では、迅速に市場に製品を投入し、イノベーションを起こし続けることが必要です。そのためには、LLMのような民主化された技術をスピーディに活用することが重要です。
ただし、誤解無いように添えておきたいのは、低レイヤーの技術開発を完全に否定しているわけではありません。基本的には低レイヤーの技術をしっかり理解しマスターすることは、高度な技術開発や革新的な製品の基盤となります。この点については別の記事に譲ろうと思います。
戦略 Ⅰ の実践 〜 非定型帳票を読める AI-OCRの開発
OCR についての前提知識
OCR(Optical Character Recognition: 光学文字認識) とは、文字を含む画像をコンピュータが扱えるテキスト形式に変換する技術です。例えば、請求書や領収書はスキャンされると画像ファイルになり、このままではテキストエディタでは開けませんが、この画像に OCR を適用してテキストドキュメントに変換すると、その内容はテキストエディタで開けるようになります。
OCR はかなり昔から存在する技術で、日本では1960年代頃にハガキの郵便番号を読み取る用途で実用化されていたようです。昨今、ペーパーレス化が進んでいるとはいえ、現在でも多くの業務フローで依然として紙が使用されています。そのため、OCRは効率的なデータ処理や分析といったデジタル化の進展において今もなお重要な技術なのです。
そして、今、OCRは長い歴史の中で転換期を迎えています。古典的な OCR は、文字通り、光学的に文字を認識する能力しか持ち合わせていませんでした。言い換えれば、これは ”文字の形” にのみ注目したアプローチです。だから形が似ている文字は認識ミスが起きていました。一方、現代的な OCR は言語処理の技術と組み合わさって「前後の文字列から文脈や意味を捉える」といった言語的な認識能力を持つようになってきました。
これにより今では以下のようなことができるようになってきました。
① 光学的な認識ミスを、言語的なアプローチで修正できる
② 単語を認識するだけでなく、その単語の性質(金額を表している、日付を表している等)も認識できる
このような機能を有する OCR を「AI-OCR」と呼ぶこともあるようです。
請求書 AI-OCR とシンプルフォーム
請求書は各社によってレイアウトが異なっており、請求金額や請求元、請求先が書かれている場所がレイアウトごとに異なる可能性があります。このような帳票を非定型帳票と言い、非定型帳票から目的の項目を抜き出し構造化するには、これまでかなり高い専門性を要しました。

今回は請求書 AI-OCR を、一般提供されている API を組み合わせるだけでサクッと作ってみます。
その前に、当社がAI-OCRと相性が良いということについて簡単に論じておきます。当社のメインプロダクトである「SimpleCheck」というサービスは、法人名をインプットするだけで、その法人に関する情報がインターネットから瞬時に収集され、当社が独自に蓄積・検知したリスク情報と共に30秒でレポーティングするというものです。主に、金融機関様を中心にリスクチェックの用途で導入いただいています。詳しくはこちらをご覧ください。
当社のお客様の中には、請求書を起点として法人をチェックしたいというニーズを持っている方もいます。大量の請求書には法人名や登録番号(インボイス番号)が記載されており、これらを自動的に認識して「SimpleCheck」に連携させるには AI-OCR による効率的な項目抽出が必要になってきます。
アーキテクチャ
まずスキャンされた請求書画像を、Google Vision API を用いてテキスト化します。このテキストはこのままだと単なる文字の羅列ですので、これに対し GPT-4 を用いた構造化を試みます。
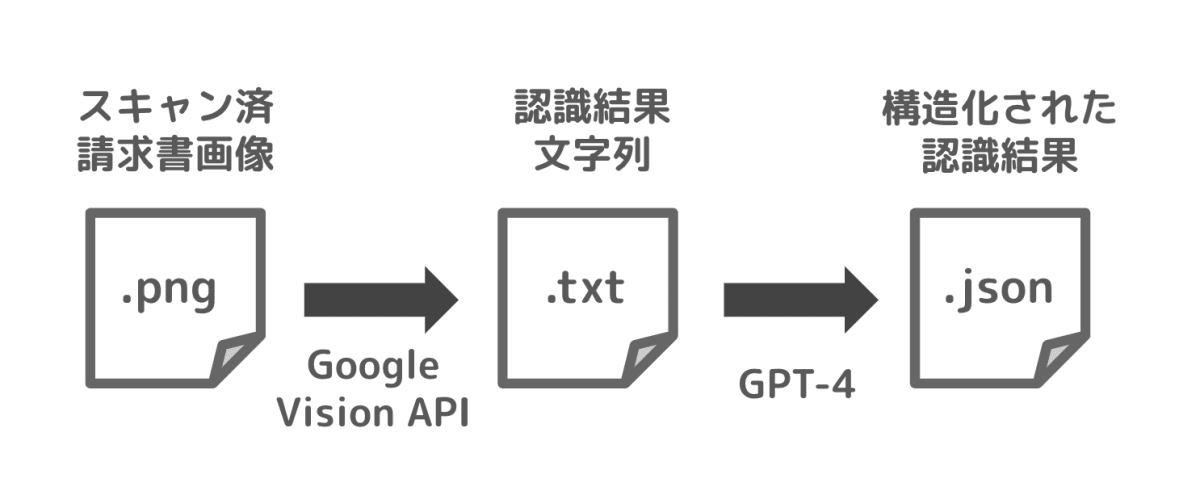
実装
apt install poppler-utils
pip install pdf2image openai google-cloud-vision
from pathlib import Path
from typing import Any
import io
import openai
import json
import numpy as np
from pdf2image import convert_from_path
from google.cloud import vision
class GoogleVisionTextExtractor:
def __init__(self):
self.client = vision.ImageAnnotatorClient()
def extract(self, file_path: Path) -> str:
img_pil = convert_from_path(file_path)[0]
img_bytes = io.BytesIO()
img_pil.save(img_bytes, format='PNG')
img_bytes = img_bytes.getvalue()
image = vision.Image(content=img_bytes)
response = self.client.document_text_detection(image=image)
return response.full_text_annotation.text
class GPTEntitiesExtractor:
def __init__(self, model: str = "gpt-4-1106-preview"):
self.model = model
self.system_role = """Correct errors in the given OCR result text, then extract the following entities and values as key-value pairs according to the constraints, then print them as JSON.
# Entities and constraints
請求先法人名 means the name of the legal entity responsible for paying in this invoice. It generally tends to appear at the beginning of the text. You can use hiragana, katakana, alphabet and kanji in its name, but you cannot use symbols. It often contains the string '会社', '法人' or '御中'.
合計請求金額 means the total amount in this invoice. This is typically the largest amount of any string of money that appears on an invoice. However, if there is a "▲" in front of the amount, that amount means a negative number and will never be adopted as this entity.
品目 means a description that expresses the specific contents of the claim in this invoice. This can have multiple elements, so print them in list form like [foo, bar].
請求元法人名 means the name of legal entity requesting payment in this invoice. It generally tends to appear later in the text. You can use hiragana, katakana, alphabet and kanji in its name, but you cannot use symbols. It often contains the string '会社' or '法人'.
請求元登録番号 means a 14-digit code that uniquely identifies the claimant. This code always starts with 'T' followed by 13 numbers. It is sometimes referred to as '登録番号' or '事業者番号' or 'インボイス番号' in the invoice.
"""
self.example_text = """T151-0064
東京都 渋谷区
上原三丁目29番1号
シンプルフォーム株式会社
西 祐気 様
下記の通りご請求申し上げます。
合計金額 1,650,000円
|サンプルサービス ABC ご利用費用
振込期日
振込先
詳細
2022年07月31日
*****銀行 *******支店
1234567
カ) サンプルノカイシャ
請求書
備考欄
支払期日が金融機関休業日の場合には
前日までのご入金をお願い致します。
恐れ入りますが、 振込み手数料は貴社負担でお願い申し上げます。
株式会社サンプルノカイシャ(庁
[**********s
T105-0012
東京都 港区南青山1-2-3
********* 123 10F
電話: 03-1234-1234
田中 花子
事業者番号:丁6012345678123
日付
請求書番号
数量
小計
消費税
合計金額
単価
1,500,000
2022年06月30日
金額
18934
1,500,000
1,500,000円
150,000円
1,650,000円
"""
self.example_entities = """{
"請求先法人名": "シンプルフォーム株式会社",
"合計請求金額": "1,650,000円",
"品目": ["サンプルサービス ABC ご利用費用"],
"請求元法人名": "株式会社サンプルノカイシャ",
"請求元登録番号": "T6012345678123"
}"""
def extract(self, ocr_generated_text: str) -> dict:
response = openai.chat.completions.create(
model=self.model,
response_format={"type":"json_object"},
temperature=0,
messages=[
{"role":"system","content":self.system_role},
{"role":"user","content":self.example_text},
{"role":"assistant","content":self.example_entities},
{"role":"user","content":ocr_generated_text}
]
)
return json.loads(response.choices[0].message.content)
解説
ここでは、 GPTEntitiesExtractor にフォーカスして解説します。
このクラスの中身を略記すると、以下のようになっています。
class GPTEntitiesExtractor:
def __init__(self, model: str = "gpt-4-1106-preview"):
self.model = model
self.system_role = "(略)"
self.example_text = "(略)"
self.example_entities = "(略)"
def extract(self, ocr_generated_text: str) -> dict:
response = openai.chat.completions.create(
...
messages=[
{"role":"system","content":self.system_role},
{"role":"user","content":self.example_text},
{"role":"assistant","content":self.example_entities},
{"role":"user","content":ocr_generated_text}
]
)
return ...
ここでは、LLM の精度を引き上げるテクニックの1つである Few-shot Learning を使用しています。
LLM には「ユーザがこう質問してきたらこう答えましょう」といった形でインプットとアウトプットのいくつかの例を与えてから実際の質問をすると、出力精度が高まるという性質があります。このように事例を与えて精度を引き上げるテクニックを Few-shot Learning と言います。
-
system_roleは LLM に指示を与えるプロンプトです。指示の要旨は以下の通りです:- OCRの誤りを修正してください。
- 次の項目をJSON形式で出力してください。
- 請求先法人名:これは◯◯という特徴を持つ
- 合計請求金額:これは◯◯という特徴を持つ
- 品目:これは◯◯という特徴を持つ
- …
- (必要な項目の分だけ特徴の説明をしてください)
-
example_textとexample_entitiesはそれぞれ、Few-shot Learning に用いるインプットとアウトプットです。-
example_textは、適当な請求書画像に対する Google Vision API の結果のテキストです。このテキストには OCR ミスが含まれていても構いません(実際、事業者番号のTを丁と誤認識しています)。 -
example_entitiesは、最終的に得たい正解の JSON です。
-
使い方
このモデルを実際に使用する際には、請求書 pdf のパスを指定します。もちろん、先ほど Few-shot Learning で与えた請求書とは異なるレイアウトの請求書を与えても大丈夫です。
os.environ["OPENAI_API_KEY"] = "******"
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "******"
text_extractor = GoogleVisionTextExtractor()
entities_extractor = GPTEntitiesExtractor()
file_path = "./invoice/株式会社清和ビジネス.pdf"
text = text_extractor.extract(file_path)
entities = entities_extractor.extract(text)
print(entities)
入力と出力結果
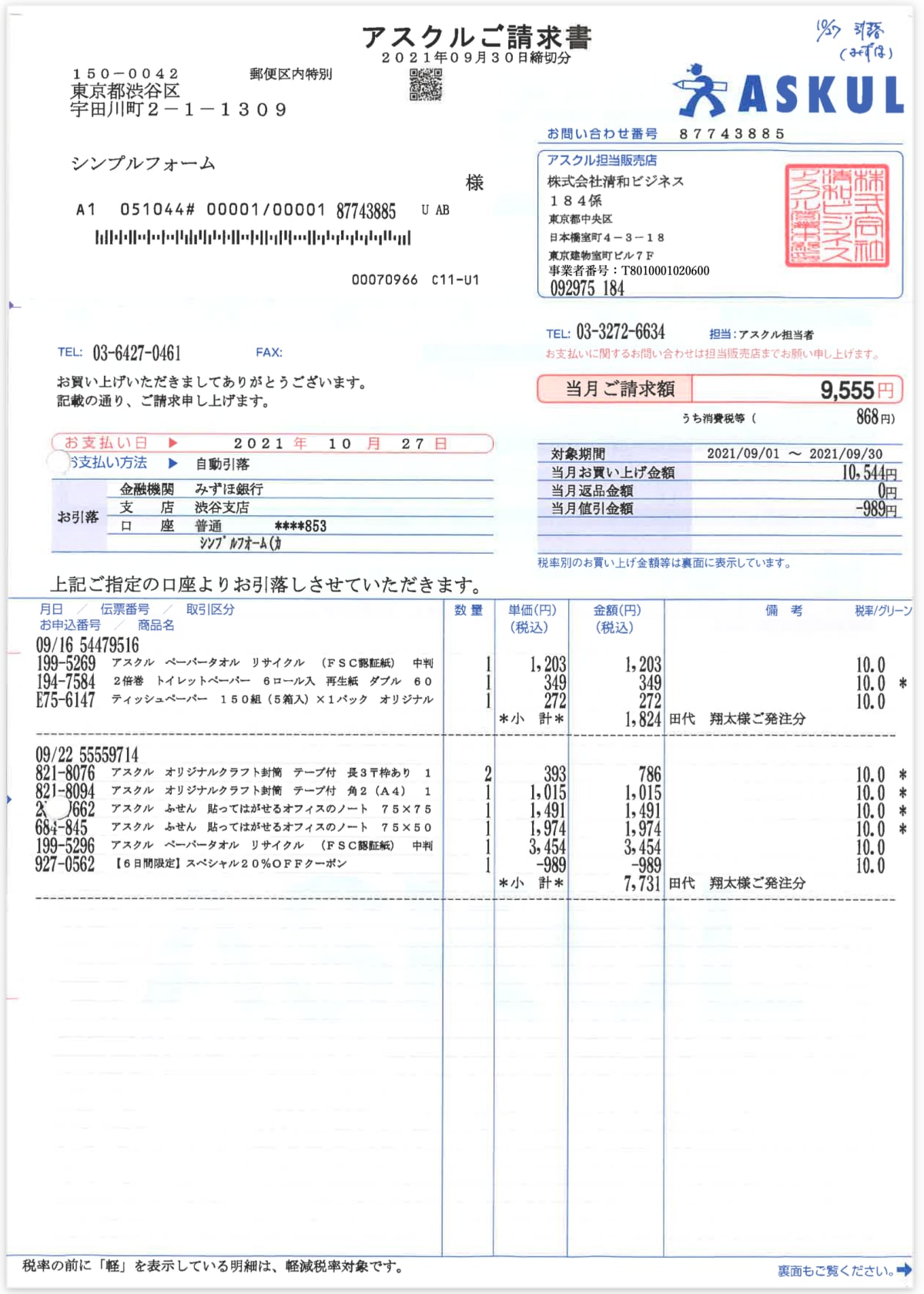
{
"請求先法人名": "シンプルフォーム",
"合計請求金額": "9,555円",
"品目": [
"アスクルペーパータオル リサイクル (FSC認証紙) 中判",
"2倍巻 トイレットペーパー 6ロール入 再生紙 ダブル",
"ティッシュペーパー 150組(5箱入)×1パック オリジナル",
"アスクル オリジナルクラフト封筒 テープ付 長3〒枠あり",
"アスクル オリジナルクラフト封筒 テープ付 角2(A4)",
"アスクルふせん 貼ってはがせるオフィスのノート 75×75",
"アスクル ふせん 貼ってはがせるオフィスのノート 75×50",
"アスクルペーパータオルリサイクル (FSC認証紙) 中判",
"【6日間限定】 スペシャル20%OFFクーポン"
],
"請求元法人名": "株式会社清和ビジネス",
"請求元登録番号": "T8010001020600"
}
おわりに
本番環境で使うには、もっと出力を安定させたり、上述のように誤認識に対応できるようにするためのアプリケーション上の工夫が必要だったりとまだまだ改善の余地はありますが、かなり少ないコード量でかなり汎用的・高性能な AI-OCR を実装することができました。
とはいえ、この AI-OCR 機能すらも数カ月後には OpenAI が API で公開してきそうな勢いですね。
この記事で見ていただいたように、シンプルフォームでは新しい技術開発にスピーディに挑戦し続けています。私達はいつでも積極採用中ですので、少しでも興味を持っていただいた方は、ぜひカジュアルにお話しさせてください!
Discussion