Glue DynamicFrame 生成時のカラム SELECT でパフォーマンス改善した話
こんにちは。インフラチームの山岸 (@yamagishihrd) です。
本記事は SimpleForm Advent Calendar 2023 の5日目です。
今回は Glue ジョブ開発に関する Tips についてご紹介したいと思います。
記事概要
当社のデータ基盤では ETL 処理に AWS Glue を使用しており、社内のデータ分析業務等のため RDS 上のデータを S3 上の DWH に日次で連携しています。
連携対象のテーブルの中に他テーブルよりも明らかに処理時間の長いものがあり、どうやらバイナリ型カラムの存在が影響していそうでした。また、調べたところデータ出力先への書き込みではなく、データソースからの読み込みがボトルネックになっているようでした。
そこでデータ読み込みの時点でカラムを SELECT する方法を試し、バイナリ型カラムを DynamicFrame 生成前に除外してみたところ、劇的にパフォーマンスが改善されました。以降で詳細について解説します。
当社のデータ基盤について
本題に入る前に、当社のデータ基盤のアーキテクチャについて少し紹介したいと思います。
データ基盤はデータソースに負荷をかけず、また様々なデータを統合的に分析することを可能にします。当社ではデータ基盤の各レイヤー(データレイク/DWH/データマート)をそれぞれ S3 上に構築しており、Glue クローラーでデータカタログ化しています。Redshift Spectrum の機能を利用して、データ実体を S3 に置いたまま外部スキーマとして登録し、Redshift のコンピューティングリソースを活用して分析しています。分析インターフェースとして Redash を ECS 上に構築しています。

各種データソースからのデータ取得やレイヤー間データ転送のための ETL を Glue ジョブで実装しています。DWH には、データレイクに蓄積された各種アプリケーションログやメトリクスデータの他、RDS からも連携対象として指定しているテーブル群のデータを S3 出力しています。
課題
各テーブルの処理時間を計測していて、他テーブルと比較して突出して処理時間の長いテーブル (A) を発見しました。レコード数は 1,300 万件ほどでグラフ的には 200~300 秒ほどで完了して良さそうでしたが、実際には約 5,000 秒(= 1.5時間以上)を要していました。[1]

調査・検討
当初はレコード 1 件あたりのデータサイズが大きいのかもと思いましたが、レコード数 6,500 万件ほどのテーブル (B) と比較して出力されたデータサイズは 1/5 ほどだったので、1 レコードあたりのデータサイズは関係なさそうでした。
しかしテーブルスキーマを見てみると、分析には利用されない MEDIANBLOB 型(Glue データカタログの binary 型)カラムが存在しており、これが処理時間に影響しているのではないかと思われました。[2] 試しに ETL の中でカラムを drop してみたものの処理時間にあまり変化がなかったため、図の下のように DynamicFrame を生成する時点で事前に SELECT する方法について検討しました。
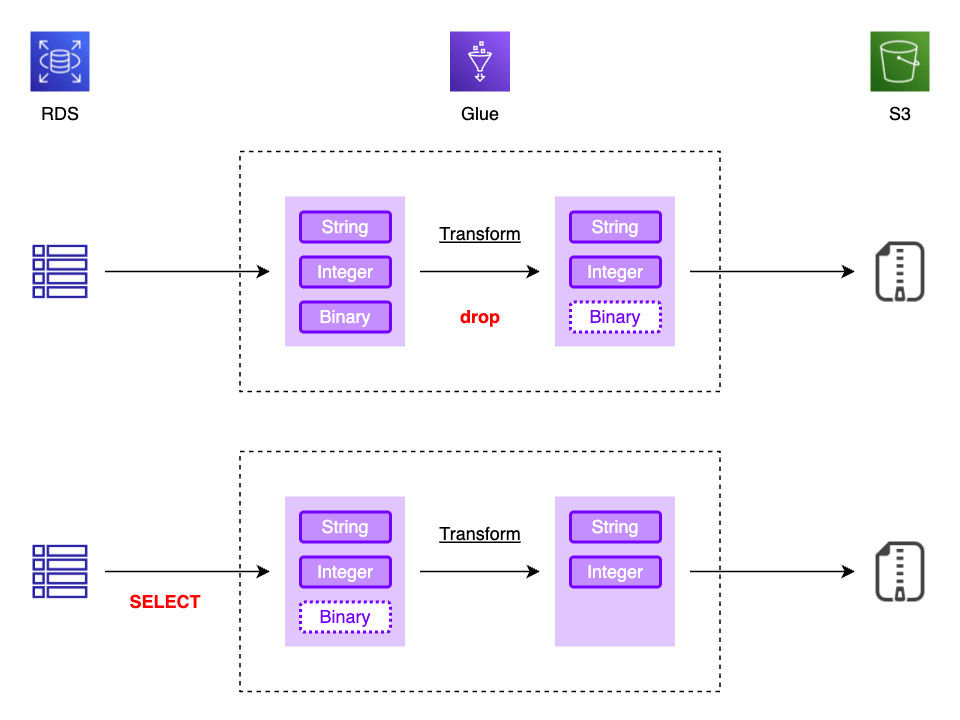
コード修正
もともとの DynamicFrame 生成のコードは以下のようになっていました。
dyf = glueContext.create_dynamic_frame.from_catalog(
database=DATABASE_NAME,
table_name=f"{schema}_{table_name}",
)
これを sampleQuery オプション [4] を使用して、当該のテーブルについて以下のように修正します。
# SELECTED_COLUMNS: BLOB 型を除いた読み込み対象のカラムリスト
query = f"SELECT {','.join(SELECTED_COLUMNS)} FROM {schema}.{table_name}"
dyf = glue_context.create_dynamic_frame.from_catalog(
database=SRC_GLUE_DATABASE,
table_name=f"{schema}_{table_name}",
+ additional_options={
+ "sampleQuery": query,
+ }
)
不要なバイナリ型カラムを事前の SELECT で除外したことで、1.5 時間以上かかっていた処理を 4 分弱まで短縮することができました。

sampleQuery オプションについて
増分 ETL
sampleQuery オプションの存在は今回の件で初めて知りましたが、不要カラムを SELECT で除外しておく以外に、増分 ETL でも有効活用できそうに思いました。
データソースが更新のない INSERT-only のテーブルである場合、データ出力先を例えば created_date=%Y-%m-%d のようにパーティション化します。Spark DataFrame 操作で日付による filter を行うのではなく、事前に sampleQuery の WHERE 句で日付抽出をしておくと Glue におけるデータ処理量・DPU 時間をかなり削減できそうです。
enablePartitioningForSampleQuery
sampleQuery はデフォルトで単一 executor で実行されるので、大きなデータセットを並列で読み取りたい場合は enablePartitioningForSampleQuery オプションを有効にします。この場合、渡すクエリは WHERE または AND で終わる必要があります。[4:1]
"sampleQuery": (オプション) サンプリング用のカスタム SQL クエリステートメント。デフォルトでは、サンプルクエリは単一のエグゼキュターによって実行されます。大きなデータセットを読み取る場合は、JDBC パーティション化を有効にして、テーブルを並列にクエリする必要がある場合があります。...
"enablePartitioningForSampleQuery": (オプション) デフォルトでは、このオプションは false となっています。sampleQuery をパーティション化された JDBC テーブルで使用する場合は必要になります。...
明日は当社 CTO 小間さんによる音声認識に関する投稿の予定です。お楽しみに!
-
グラフは横・縦軸ともに対数スケールです。 ↩︎
-
バイナリ型カラムを含む DynamicFrame 生成が遅くなるというような情報は見つけられなかったため、本当にこれが支配的な要因であるかどうかは分かっておりません。 ↩︎
-
https://d1.awsstatic.com/webinars/jp/pdf/services/202108_Blackbelt_glue_etl_performance1.pdf | p.25 - p.27 ↩︎
-
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/aws-glue-programming-etl-connect.html ↩︎ ↩︎
-
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/aws-glue-api-crawler-pyspark-extensions-dynamic-frame-reader.html#aws-glue-api-crawler-pyspark-extensions-dynamic-frame-reader-from_options ↩︎
Discussion