TikTokスクレイプ基盤をGCP上で構築してハマったこと

TikTokへスクレイプするバッチをGCP上で構築しました。
GCP構築のシステム設計話と、その構築時に、ハマったことを共有します。
きっかけ
2020年、最もダウンロードされたアプリがFacebookを抜いてTikTokが一位になったそうです。
私もTikTokを利用しています。
ネットサーフィンをしている時に、tiktok-scraperというライブラリをcloudflareのサイトで発見しました。これを使って、TikTokの情報収集できるんじゃないかなと思い始めましたのがきっかけです。
tiktok-scraper
Scrape and download useful information from TikTok.
No login or password are required.
This is not an official API support and etc. This is just a scraper that is using TikTok Web API to scrape media and related meta information.
上記のとおり、TikTokのWebAPIを通してスクレイプします。
ライブラリでは、特定のTikTok動画をダウンロードすることができますが、次の切り口で、TikTok動画を一括ダウンロードすることもできます。
- ユーザー
- ハッシュタグ
- トレンド
- 音楽

動画をダウンロード

様々な切り口で、動画をダウンロード
加えて、メタ情報(フォロワー数やいいね数など)も手に入ります。
中には、ユーザー画像や動画カバー画像などのTikTok CDNへのリンクもあります。(https://p16-sign-va.tiktokcdn.com)
リンクには、有効期限を示す文字が含まれており、一定の時間が経過すると Access Denied となります。
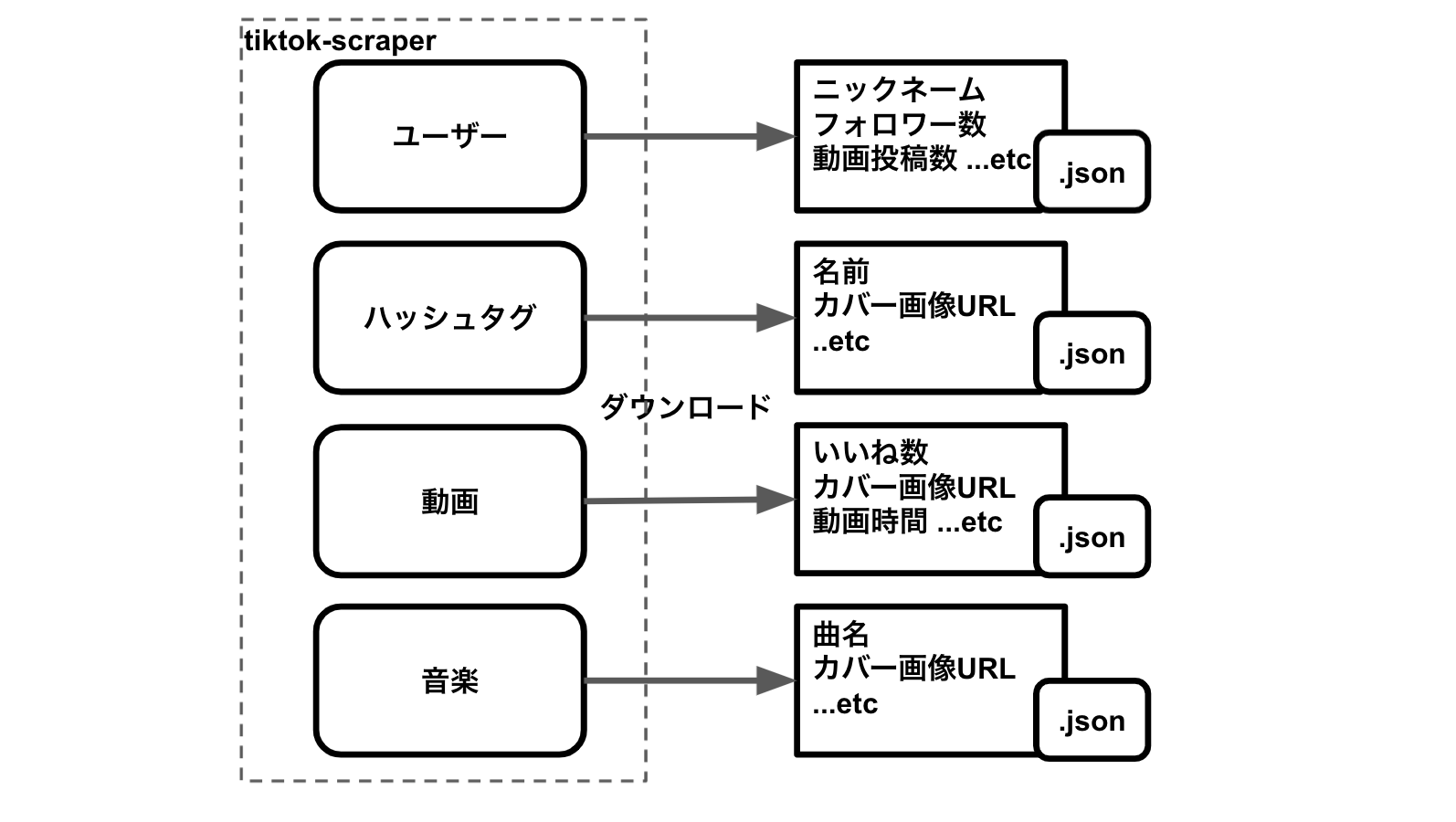
様々な切り口で、メタ情報をダウンロード
手に入れられない情報は、ログインが必要なものです。
例えば、私がフォローしているユーザーとかです。
その情報が欲しかったので、どうにかして手に入れました。(詳細は省きます)
そのユーザー情報を使って、先程のユーザーという切り口でTikTokの動画やメタ情報を収集するバッチを作ろうと考えました。
システム設計
バッチを動かす環境ですが、プライベートでよく使っているGCP上で構築しようと思いました。
バッチで収集したデータを閲覧するWebアプリケーションも作ろうと考え、NetlifyとReactで動かすことにしました。

Webアプリケーション UI
目的
私がフォローしているユーザーのTikTok動画やメタ情報を集めること。
I/O
- インプット
- ユーザー情報
- アウトプット
- TikTok動画
- メタ情報
GCPリソース選定
- TikTok動画
- Cloud Storage へ保存
- メタ情報
- Cloud SQL へ保存
- コンピューティングリソース
- Cloud Run
設計図
実際に構築したGCPのシステム設計図が、次の画像のとおりです。
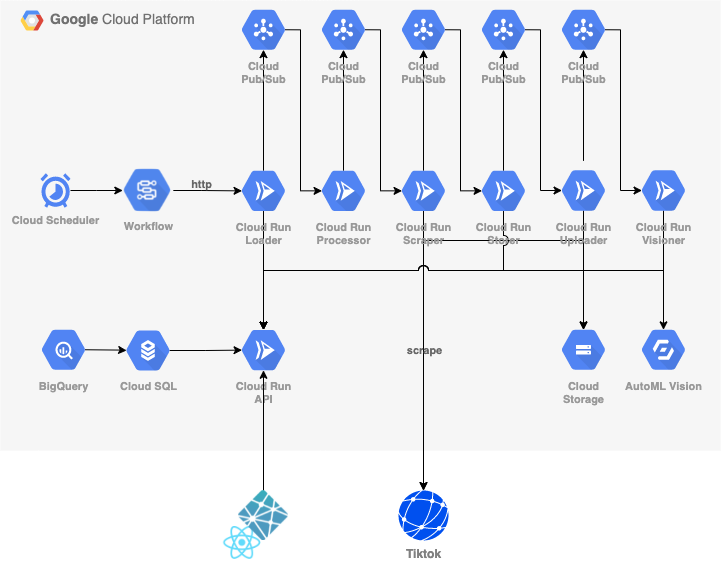
GCPリソースの用途は、次のとおりです。
| GCPリソース | 用途 |
|---|---|
| Cloud Scheduler | バッチ起動のスケジュールを管理 |
| Cloud Worlflows | バッチのワークフローを制御 |
| Cloud Run | 役割に応じて処理 |
| PubSub | Cloud Runを繋げる |
| Cloud Storage | 動画を保存 |
| AutoML Vision | 動画のカバー画像をラベル検出 |
| Cloud SQL | 全てのメタ情報を管理 |
各Clour Runの役割は、次のとおりです。
| Cloud Run名 | 役割 |
|---|---|
| Loader | ユーザー情報を読み込む |
| Processor | 一連の処理を行む |
| Scraper | TikTokへスクレイプする |
| Storer | 渡された情報を保存する |
| Uploader | 動画をダウンロードし、Storageへアップロードする |
| Visioner | 画像を(Vision APIを通して)ラベル情報を抽出する |
| API | Cloud SQLとのインターフェース |
ハマったこと
Cloud Workflowsの制限が厳しい
当初、PubSubは使わずに、Cloud Runの連携はCloud Workflowsで行おうと考えていました。
PubSubでワークフローを制御するよりも、Cloud Workflowsのyamlでワークフローを制御した方が分かりやすいと思ったからです。
具体的には、Cloud RunへHTTPリクエストし、HTTPレスポンスに応じて、次のCloud Runを呼び出そうと考えていました。
ただ、Cloud Workflowsには、次のページに書いてあるとおり、いくつかの制限があります。
特に困ったのが、全ての変数のメモリ合計が、64kb だということです。
HTTPレスポンスのBodyを変数保持する構成を取ると、そのサイズを考慮しなければいけません。
いくつかやり方を見直してみたのですが、思うような形に仕上げることができず、断念しました。
結果、PubSubを使ってCloud Runを連携することになりました。
Cloud Workflowsは、バッチのキック、通知などをすることとなりました。
Firestoreのページカーソルに±2ページ以降への移動が難しい
GCPでデータストレージで、無料枠があるFirestoreを当初使っていました。
理由は、単純にGCP無料枠としてFirestoreがあったからです。
当初、Firestoreを使って、バッチとWebアプリを書いていました。
Webアプリには、バッチで収集したTikTokの動画を一覧表示するViewを用意しました。
閲覧するTikTok動画が多くなると、ページネーションが欲しくなりました。
そこで、Firestoreでページネーションの実現方法を調べてみると、次の資料を発見しました。
これを見ると、ページネーションは、現在位置から±1ページの移動は簡単です。
資料にあるサンプルコードのように、startAfterを使えばよいだけです。
var first = db.collection("cities")
.orderBy("population")
.limit(25);
return first.get().then((documentSnapshots) => {
// Get the last visible document
var lastVisible = documentSnapshots.docs[documentSnapshots.docs.length-1];
console.log("last", lastVisible);
// Construct a new query starting at this document,
// get the next 25 cities.
var next = db.collection("cities")
.orderBy("population")
.startAfter(lastVisible)
.limit(25);
});
しかし、現在位置から±2ページ目以降への遷移がしたい場合は、どうすれば良いでしょうか。
上記のサンプルコードで言えば、firstをコピペしてsecond変数を生成するのでしょうか。
それよりも、offsetメソッドがほしいところです。
しかし、次の資料を発見し、諦めることになります。
オフセットは使用しないでください。その代わりにカーソルを使用します。オフセットを使用すると、スキップされたドキュメントがアプリケーションに返されなくなりますが、内部ではスキップされたドキュメントも引き続き取得されています。スキップされたドキュメントはクエリのレイテンシに影響し、このようなドキュメントの取得に必要な読み取りオペレーションは課金対象になります。
という訳で、クエリカーソルを推奨されています。
解決策としては、順序を示すフィールドがあれば、解決するかもしれません。
例えば、orderというフィールドを用意し、1,2,3とインクリメントしたデータがあれば、クリアできるかもしれません。
startAfterの引数はdocumentオブジェクトだけではなく、orderBy句で指定したフィールドの変数を含めることができます。
var next = db.collection("cities")
.orderBy("order")
.startAfter(50)
.limit(25);
これだと、1ページ25個のデータを表示するならば、3ページ目(51~75)を取得できます。(startAfterは開始点を含めません)
そもそも、ドキュメントベースの設計よりも、RDBの設計に慣れていた私は、
Firestoreよりも、Cloud SQLの方が扱いやすいと思いました。
そこで、データストレージをFirestoreからCloud SQLへ切り替えることとしました。
改修自体、Cloud Runの役割が明確に分離されていたので、一部の処理を書き換えるだけで、簡単にできました。
Eventacのリソース選択が物足りない
Cloud RunとPubSubの連携には、Eventacを使用します。
昨年 10 月、60 を超える Google Cloud ソースから Cloud Run にイベントを送信できる新しいイベント機能、Eventarc を発表いたしました。Eventarc は、さまざまなソースから監査ログを読み取り、それらを CloudEvents 形式のイベントとして Cloud Run サービスに送信します。また、カスタム アプリケーションの Pub/Sub トピックからイベントを読み取ることもできます。
このEventarcのソースとして、Cloud StorageのObject.createをトリガーとして設計を考えていました。
しかし、そのイベントをフィルタリングする選択肢は、2つしかありません。
できるのは、執筆時点(2021年8月)で、次の2つです。
- All resource
- Specific resource
All resourceは、Cloud Storageの全てのバケットにおけるObject.createイベントがトリガーとなります。
Specific resourceは、特定のObeject名がObject.createされた場合のみ、トリガーとなります。
欲しいなと思ったのは、Specific resouceの正規表現によるフィルタリング、任意のバケットやフォルダの配下で限定など
のフィルタリングです。例えば、gs://bucket/folder/*.json のような形式です。現状は、gs://bucket/folder/A.jsonとするしかありません。
今回は、PubSubのイベントのみでトリガーするようにしました。
PubSubをトリガーとするCloudRunでHTTPレスポンス500を返却すると、PubSubが再試行される
Cloud Runで、5XX系のエラーとなった場合、PubSubの再試行されます。
何度もPubSubが実行されると、Cloud Runのコンピューティングリソースが消費され続けます。
そうすると、課金が発生するので、対策が必要です。
Cloud Workflowsの処理は、あまりカスタマイズできない
Cloud Workflowsは、あくまでワークフローの管理です。
変数処理などは、基本的に使わず、ワークフローのタスクを連結するだけにした方が良いです。
次の資料には、Cloud Workflowsで使える標準機能です。
ワークフローのタスクを並列処理する機能は、まだ実験段階なので、本番環境は使えないようです。
終わりに
システム設計変更が度々変更がありつつも、目的とするTikTok動画やメタ情報を収集することは達成できました。
変更があったとしても、役割をできる限り小さく保つことで、変更に柔軟に対応することができます。
また、実際に動かすことで、気付けるポイントもあるので、フィードバックサイクルを短くすることも大切です。
まだまだ改善する余地はあります。ユーザー情報という切り口で情報収集していましたが、トレンドやハッシュタグなどからも
取得できるようにしたいです。また、ユーザーのRSSを作ることで、金銭的な節約もしてみたいと思っています。
Discussion