Figma 風の並び順管理アルゴリズムを提供する Gem による並び替え機能の提案
突然ですが、アプリケーションの仕様として「データを任意の順番に並び替えたい」という要望があった場合、皆さんならどのように設計しますか?下記の記事でも紹介されているように、複数のアプローチが考えられます。
私が参画したプロジェクトでは、もともとデータの並び替えに対して acts_as_list というGemを使用し、インクリメンタルな整数で並び順を管理していました。そして、並び替えが行われるたびに、クライアント側から並び替え後の全データがサーバーに送られ、その後サーバー側で並び順の再計算が行われていたのです。
この方法は、対象データが10件未満程度であれば、許容できる範囲の処理時間でした。しかし、データ数が増えるにつれて処理速度が指数関数的に遅くなり、最大でN個のデータの並び順を再計算する必要がある点に疑問を感じました。この再計算によるパフォーマンスの問題こそが、より効率的な並び順管理の方法を探し、Gemの開発に取り組むきっかけとなりました。
Fractional Indexing
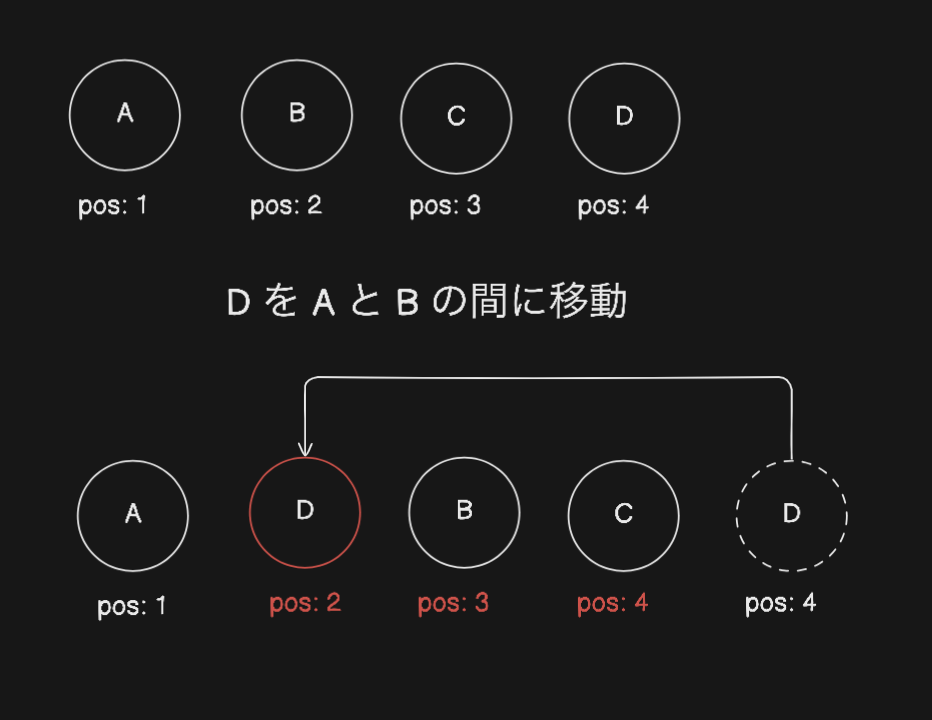
理想として考えたのは、並び替えを行うデータのみ(N=1)を再計算するというアプローチでした。この要件を満たす方法を探していたところ、出会ったのが「Fractional Indexing」という手法です。この手法では、並び順を整数だけでなく、小数を使って表現します。

この手法では、任意の要素間にデータを移動する際、その要素間の平均値を新しい並び順として使用することで、並び替え時の再計算が、そのデータに対してのみ行われます。
これはまさしく私が求めていたアプローチでしたが、いくつかの大きな制約がありました。
従来のFractional Indexingの問題点
それは、並び替えを繰り返すにつれて桁数が増え、早い段階で[1]丸め誤差によって同じ並び順を持つデータが複数存在してしまうという問題です。
さらに、並び順が重複した場合、リバランシング(全データへの並び順の再割り当て)という比較的重い処理が必要になる点も課題となりました。
Figmaが紹介しているFractional Indexingについて
Figmaのブログ記事を読んだ上で、私なりの解釈を元に以下の2点のメリットにより、従来のFractional Indexingの問題点を解決できると考えました。
- 並び順を文字列として表現することで、桁数の制限が緩和されるだけでなく、丸め誤差による並び順の衝突を気にする必要がなくなる。
- 文字列で並び順を表現するため、10進数ではなく95進数で並び順を管理できる。これにより、一般的にはリバランスが不要となる。
これらの点を踏まえて、私はこのアプローチをベースにした並び順管理の新しい仕組みを提供するGemを作成しました。このGemを使うことで、より効率的に並び替えを実現できると考えました。
Gem fractional_indexer の紹介
このGemは、READMEにも記載があるように、Implementing Fractional Indexingをベースに、いくつかのアレンジを加えたものです。Figmaのブログで紹介されていたアプローチを実現するためのアルゴリズムを提供します。
生成される値について
Gem で作成される並び順を表すための文字列は以下のように3つのパーツから構成されます。
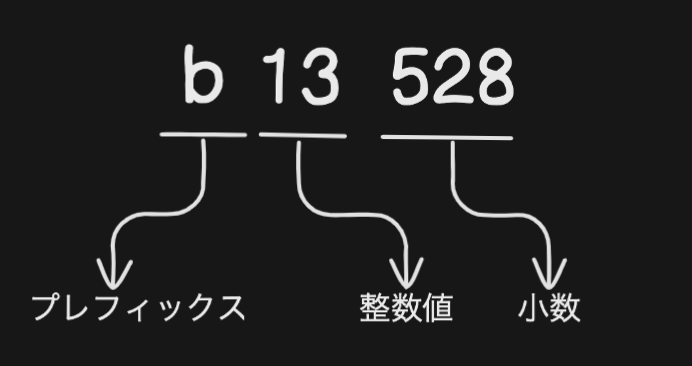
まず、プレフィックスについてです。
このプレフィックスは、小文字のa〜zおよび大文字のA〜Zで表され、以下の役割を持っています。
- 整数部分が何桁であるかを示す。(つまり、何文字目までが整数部分であるかを表します)
- 正の整数と負の整数を識別する
| 表現する値/桁数 | 1 | 2 | 3 | 4 | 5 | ... | 26 |
|---|---|---|---|---|---|---|---|
| 正の整数値 | a | b | c | d | e | ... | z |
| 負の整数値 | Z | Y | W | X | Y | ... | A |
この表は、プレフィックスが表す桁数とその表現の関係を示しています。たとえば、プレフィックスがaの場合、それは整数部分が1桁の正の数を表し、bであれば2桁の正の数を表します。同様に、負の数を表す場合、Zは1桁の負の数、Yは2桁の負の数を示します。この仕組みにより、文字列の長さに依存せずに、並び順が正しく数学的に整列されるようになります。
次に、整数値ですが、これはプレフィックスが示す桁数の文字列です。
最後に、小数部分はプレフィックスと整数値を除いた残りの文字列を指します。
小数部分には1つルールがあり、それは最後の文字が進数の最小値であってはならないというものです。これは、数学的に1.20が1.2と同じ意味になるため、表記を統一するためのルールです。
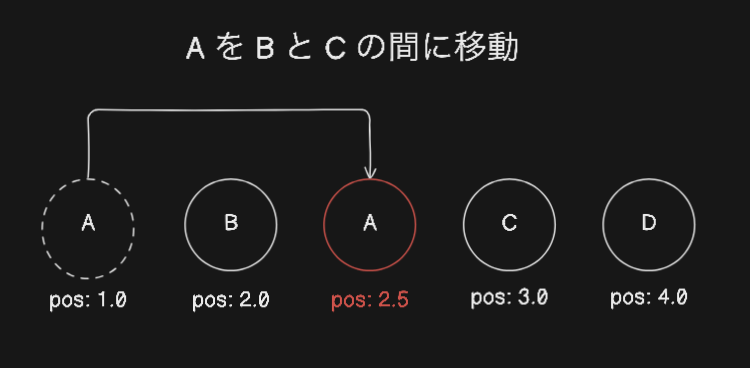
並び替え時の挙動について
Fractional Indexingについて説明した際に、「任意の要素間にデータを移動する際、その要素間の平均値を新しい並び順として使用する」と述べました。このアプローチは、基本的にはデータを並び替えるたびに桁数(つまり、文字数)が指数的に増加していく傾向があります。
しかし、このGemでは、できるだけ桁数が増加しないように設計されています。これにより、桁数が増加しないことのメリットとして、データベース上で並び順を永続化する際にインデックスの容量を抑えることができ、特にVARCHAR型などの任意のフィールドで扱いやすくなると考えています。
以下の図は、並び替えを行った際に割り当てられる並び順のイメージを示しています。

Active Recordとの統合: Gem narabikaeの紹介
上記で紹介したfractional_indexerとActive Recordを統合することで、acts_as_listのような使用感で、簡単に並び順の自動生成や並び替え機能を提供できるのでは?という考えから作成したのが、Gem narabikaeです。
このGemは、簡単な構文で以下の機能を提供します。
✅ レコード作成時に並び順の自動生成と永続化
✅ 並び替えを行うためのいくつかのメソッドの提供
✅ スコープ機能のサポート
✅ 生成した並び順の値が重複した場合のリトライ機能
このGemは、並び順管理や並び替え機能をより効率的に実現するためのシンプルで強力なツールです。ぜひ実際にプロジェクトで試していただき、並び替え操作のパフォーマンスや使い勝手の向上を体感してみてください。ご意見やフィードバックもお待ちしております!
参考
Discussion