ChatGPTとGitHub Copilotの助けを借りたら2週間で技術書が書けた
はじめに
先日、Kindleで技術書を出版しました。それまで、技術書典に参加したことや、技術の泉シリーズから出版したことはありましたが、Kindle Direct Publishingでの出版は初めてでした。
タイトル通り、ChatGPTとGitHub Copilotの助けを借りたら、実際に2週間で技術書が書けました。今回はその経緯を書いていきます。
ちなみに、出版した本はこちらです。Kindle Unlimitedなら無料で読めますので、ぜひ読んでみてください。
なぜ本を書こうと思ったか
私はKindle Unlimitedのヘビーユーザーです。いつものように、ラノベやコミックを探して読んでいたところ、Amazonから次の本をお勧めされました。
この本は、商業出版経験のある「なろう作家」(小説投稿サイト「小説家になろう」に小説を投稿しているユーザー)が、Kindle Direct Publishingで本を出版するまでの経緯を描いたフィクションです。冒頭で「――――この物語は現実です」と書かれていることからもわかるように、筆者の実体験が元になっているようです。設定こそ非現実的ですが(主人公は吸血鬼ですし)、実際に体験しないと書けないような描写が随所に登場し、リアリティを感じました。
私も本を書いたことがあるので、校正に苦しむシーンでは「そうそう、わかるわー」などと共感しながら読んでいました。そして、読み終わる頃には「また本を書いてみようかな」と思うようになっていました。
14日間で技術書を書くまでの経緯
1日目:構想を練る、サンプルコードを作る
構想を練る
まずは、何を書くかを決めます。前の本は全然売れなかったので、今度は売れる本を書きたいなと思いながら、以下のようなことを考えました。
- 間口を広く取る
- 初心者向けにする
- 多くの人が興味を持つようなテーマにする
- 旬のテーマにする
- ChatGPT
- 自分でも興味があるテーマにする
- やっぱりChatGPT
- 音声認識と音声合成も
ということで、ChatGPTのAPIを用いてチャットボットを作る、初心者向けのプログラミング入門書を書くことにしました。さらに、音声認識と音声合成も組み合わせて、音声対話型のチャットボットにすることで、特色を出すことにしました。2023年5月時点で、類似の書籍が出版されていないことも確認しました。
サンプルコードを作る
チャットボットくらいなら、がんばれば自力で書けそうでしたが、せっかくなのでChatGPTと対話しながら作っていくことにしました。
以下はテキストチャットボットを作成したときの、実際の対話の様子です。言語モデルはGPT-4です。すごく長いので、折りたたんでいます。クリックで表示します。
サンプルコードの作成(ChatGPTとの実際の対話の一部)
Person:
- LangChainはご存知ですか?
ChatGPT:
- 申し訳ありませんが、私の知識は2021年9月までのもので、その時点では"LangChain"という名前の特定の技術やサービスについての情報はありません。もし最新の情報を求めている場合は、インターネットで検索することをお勧めします。それにより、最新かつ詳細な情報を提供することが可能になります。
Person:
- ではGoogleでLangChainについて調べて要約してください。
ChatGPT:
- Used WebPilot
LangChainは、大規模言語モデルを使用したアプリケーションの作成を簡素化するためのソフトウェア開発フレームワークです。言語モデルによって駆動されるアプリケーションの開発に特化しており、最も強力で差別化されたアプリケーションは言語モデルだけでなく、LangChainのようなフレームワークによっても駆動されると考えています。
LangChainはチャットボット、生成型の質問応答(GQA)、要約などに使用することができます。また、標準的なインターフェースを提供し、他のツールとの統合、一般的なアプリケーション向けのエンドツーエンドのチェーンを提供します。
LangChainは、LLM(Large Language Models)コンポーネント(モデル、ドキュメントリトリーバー、データなど)を組み立てることを容易にするプラットフォームとして機能します。また、GPT-4によって駆動され、チームのアジェンダからデザインスプリントまで、ケースに特化したワークフローを即座に生成することができます。
LangChainはPythonとJavaScriptで書かれており、Harrison Chaseによって開発され、2022年10月に初リリースされました。MITライセンスの下で提供されています。
Person:
- PythonでGPT-4 APIとLangChainを利用したチャットボットを作成してください。
ChatGPT:
- 私の知識が2021年9月までのものであるため、GPT-4やLangChainの具体的なAPIについては詳しく知らないのですが、一般的なOpenAIのGPT-3 APIとPythonフレームワークを使用したチャットボットの作成方法を示すことはできます。これはGPT-4やLangChainが同様のAPIを提供している場合に参考になるかもしれません。
以下に、OpenAIのGPT-3 APIを使用したチャットボットの簡単な例を示します:
import openai
openai.api_key = 'your-api-key'
def ask_gpt3(question):
response = openai.Completion.create(
engine="text-davinci-003",
prompt=question,
max_tokens=150
)
return response.choices[0].text.strip()
while True:
question = input("You: ")
answer = ask_gpt3(question)
print("Bot: " + answer)
このコードは、ユーザーからの質問を受け取り、それをGPT-3 APIに送信し、生成されたテキストを出力します。ただし、これは非常に基本的な例であり、実際のチャットボットではユーザーとの対話のコンテキストを維持するために追加のロジックが必要になることを覚えておいてください。
LangChainの具体的な使用方法については、公式ドキュメンテーションやチュートリアルを参照することをお勧めします。これらのリソースは、LangChainを使用してアプリケーションを開発する際の最良の実践方法を提供します。
Person:
- 以下にOpenAIのAPIリファレンスのURLを示します。
https://platform.openai.com/docs/api-reference/
この内容を踏まえて上記のチャットボットを書き換えてください。
ChatGPT:
- Used WebPilot
このドキュメントに基づいて、上記のチャットボットの書き換えを行います。
# OpenAIのGPT-3を使用するためのライブラリをインポートします。
import openai
# OpenAIのAPIキーを設定します。
openai.api_key = 'your-api-key'
# チャットモデルを使用して会話を開始します。
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
]
)
# レスポンスから最新のメッセージを取得します。
latest_message = response['choices'][0]['message']['content']
print(latest_message)
このコードは、OpenAIのGPT-3.5-turboモデルを使用してチャットボットを作成します。まず、OpenAIのAPIキーを設定します。次に、ChatCompletion.createメソッドを使用して会話を開始します。このメソッドは、モデル名とメッセージのリストを引数に取ります。メッセージのリストは、各メッセージが持つ役割("system"または"user")と内容を表す辞書からなります。
この例では、システムメッセージでアシスタントの役割を設定し、ユーザーメッセージで質問を投げかけます。その後、レスポンスから最新のメッセージを取得し、それを出力します。
Person:
- 以下にLangChainのMemory機能のドキュメントURLを示します。
https://python.langchain.com/en/latest/modules/memory/getting_started.html
これを踏まえて上記チャットボットを記憶を持つように改良してください。
ChatGPT:
- Used WebPilot
LangChainのMemory機能についてのドキュメントを参考に、上記のチャットボットを記憶を持つように改良します。
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
# OpenAIのAPIキーを設定します。
openai.api_key = 'your-api-key'
# LangChainのLarge Language Model (LLM)を設定します。
llm = OpenAI(temperature=0)
# メモリを設定します。
memory = ConversationBufferMemory()
# チャットボットを作成します。
conversation = ConversationChain(llm=llm, verbose=True, memory=memory)
# ユーザーからのメッセージを受け取り、それに対する応答を生成します。
while True:
user_message = input("You: ")
response = conversation.predict(input=user_message)
print("Bot: " + response)
このコードは、LangChainのConversationChainとConversationBufferMemoryを使用して、ユーザーとの対話の履歴を保持するチャットボットを作成します。ユーザーからの各メッセージは、ConversationChainのpredictメソッドに渡され、これによりAIの応答が生成されます。この応答は、前の対話のコンテキストを考慮に入れています。
このコードは、ユーザーが何かを入力するたびに無限ループを実行します。ユーザーが終了するまで、ユーザーからのメッセージを受け取り、それに対する応答を生成し続けます。
Person:
- 上記スクリプトではopenaiが定義されていませんね。
ChatGPT:
- すみません、その通りです。OpenAIのAPIキーを設定する部分が不足していました。以下に修正したコードを示します。
from openai import OpenAI
from langchain.llms import OpenAI as LangChainOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
# OpenAIのAPIキーを設定します。
OpenAI.api_key = 'your-api-key'
# LangChainのLarge Language Model (LLM)を設定します。
llm = LangChainOpenAI(temperature=0)
# メモリを設定します。
memory = ConversationBufferMemory()
# チャットボットを作成します。
conversation = ConversationChain(llm=llm, verbose=True, memory=memory)
# ユーザーからのメッセージを受け取り、それに対する応答を生成します。
while True:
user_message = input("You: ")
response = conversation.predict(input=user_message)
print("Bot: " + response)
このコードでは、まずOpenAIのAPIキーを設定します。次に、LangChainのLarge Language Model (LLM)を設定し、メモリを設定します。そして、これらの設定を使用してチャットボットを作成します。最後に、ユーザーからのメッセージを受け取り、それに対する応答を生成します。この応答は、前の対話のコンテキストを考慮に入れています。
Person:
- LangChainのドキュメントを読んだら、OpenAIのAPIキーは環境変数で設定しておけば良さそうです。
参考:
https://python.langchain.com/en/latest/getting_started/getting_started.html
スクリプトからAPIキーの設定を除外してください。
ChatGPT:
- ご指摘ありがとうございます。OpenAIのAPIキーは環境変数で設定することが推奨されています。そのため、スクリプトからAPIキーの設定を除外します。
以下に修正したコードを示します。
from langchain.llms import OpenAI as LangChainOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
# LangChainのLarge Language Model (LLM)を設定します。
llm = LangChainOpenAI(temperature=0)
# メモリを設定します。
memory = ConversationBufferMemory()
# チャットボットを作成します。
conversation = ConversationChain(llm=llm, verbose=True, memory=memory)
# ユーザーからのメッセージを受け取り、それに対する応答を生成します。
while True:
user_message = input("You: ")
response = conversation.predict(input=user_message)
print("Bot: " + response)
このコードでは、OpenAIのAPIキーは環境変数から取得されます。その他の部分は前のバージョンと同じです。
Person:
- OpenAIをLangChainOpenAIと言い換える必要はなさそうですね。
ChatGPT:
- その通りです、すみません。OpenAIのインポートを
from langchain.llms import OpenAIと修正します。以下に修正したコードを示します。
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
# LangChainのLarge Language Model (LLM)を設定します。
llm = OpenAI(temperature=0)
# メモリを設定します。
memory = ConversationBufferMemory()
# チャットボットを作成します。
conversation = ConversationChain(llm=llm, verbose=True, memory=memory)
# ユーザーからのメッセージを受け取り、それに対する応答を生成します。
while True:
user_message = input("You: ")
response = conversation.predict(input=user_message)
print("Bot: " + response)
このコードでは、LangChainのOpenAIクラスを使用してLarge Language Model (LLM)を設定します。その他の部分は前のバージョンと同じです。
Person:
- 以下のWarningが出ました。修正できますか?
/Users/tro/devel/voice-chat-bot/venv/lib/python3.10/site-packages/langchain/llms/openai.py:696: UserWarning: You are trying to use a chat model. This way of initializing it is no longer supported. Instead, please use:from langchain.chat_models import ChatOpenAI
ChatGPT:
- その警告メッセージによれば、チャットモデルを使用するための初期化方法が変更されたようです。
langchain.llms.OpenAIの代わりにlangchain.chat_models.ChatOpenAIを使用するように指示されています。
以下に修正したコードを示します。
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
# LangChainのLarge Language Model (LLM)を設定します。
llm = ChatOpenAI(temperature=0)
# メモリを設定します。
memory = ConversationBufferMemory()
# チャットボットを作成します。
conversation = ConversationChain(llm=llm, verbose=True, memory=memory)
# ユーザーからのメッセージを受け取り、それに対する応答を生成します。
while True:
user_message = input("You: ")
response = conversation.predict(input=user_message)
print("Bot: " + response)
このコードでは、LangChainのChatOpenAIクラスを使用してLarge Language Model (LLM)を設定します。その他の部分は前のバージョンと同じです。
Person:
- 上記を参考にして、以下のスクリプトを作成しました。
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate
)
# テンプレートの準備
template = """あなたは猫のキャラクターとして振る舞うチャットボットです。
制約:
- 簡潔な短い文章で話します
- 語尾は「…にゃ」、「…にゃあ」などです
- 質問に対する答えを知らない場合は「知らないにゃあ」と答えます"""
# chatプロンプトの準備
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template(template),
MessagesPlaceholder(variable_name="history"),
HumanMessagePromptTemplate.from_template("{input}")
])
# LangChainのLarge Language Model (LLM)を設定します。
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
# メモリの設定
memory = ConversationBufferMemory(return_messages=True)
# チャットボットの作成
conversation = ConversationChain(llm=llm, verbose=True, prompt=prompt, memory=memory)
# ユーザーからのメッセージを受け取り、それに対する応答を生成する
while True:
user_message = input("You: ")
response = conversation.predict(input=user_message)
print("Bot: " + response)
このスクリプトの内容を説明してください。
ChatGPT:
- このスクリプトは、LangChainを使用して特定のキャラクターとして振る舞うチャットボットを作成します。この場合、チャットボットは猫のキャラクターとして振る舞います。
以下に、各部分の詳細な説明を示します。
- インポート : 必要なモジュールとクラスをインポートします。これには、LangChainのチャットモデル、会話チェーン、メモリ、およびプロンプトテンプレートが含まれます。
- テンプレートの準備 : チャットボットの振る舞いを定義するテンプレートを作成します。このテンプレートでは、チャットボットは猫のキャラクターとして振る舞い、簡潔な短い文章で話し、語尾は「…にゃ」、「…にゃあ」などになります。また、質問に対する答えを知らない場合は「知らないにゃあ」と答えます。
- プロンプトの準備 : チャットのプロンプトを作成します。これは、システムメッセージ(上記のテンプレート)、過去のメッセージの履歴、およびユーザーからの入力から構成されます。
-
Large Language Model (LLM)の設定 : LangChainの
ChatOpenAIクラスを使用してLLMを設定します。ここでは、モデルの温度を0に設定し、モデル名を"gpt-3.5-turbo"に設定します。 -
メモリの設定 :
ConversationBufferMemoryを使用してメモリを設定します。ここでは、メッセージを返すように設定します。 - チャットボットの作成 : 上記の設定を使用してチャットボットを作成します。これには、LLM、プロンプト、およびメモリが含まれます。
- メッセージの生成 : 無限ループを使用して、ユーザーからのメッセージを受け取り、それに対する応答を生成します。この応答は、前の対話のコンテキストを考慮に入れています。
このスクリプトを実行すると、ユーザーは猫のキャラクターとして振る舞うチャットボットと対話することができます。
Person:
- このスクリプトのコードレビューを行ってください。
ChatGPT:
- このスクリプトは、LangChainを使用して特定のキャラクターとして振る舞うチャットボットを作成するためのもので、全体的には非常によく書かれています。以下に、いくつかの観点からのレビューを提供します。
- コードの構造 : スクリプトは整然としており、各部分が明確に区切られています。これにより、コードの各部分が何を行っているのかを理解しやすくなっています。
- コメント : コードには適切なコメントが含まれており、それぞれの部分が何を行っているのかを説明しています。これは非常に良い実践で、コードの可読性と保守性を向上させます。
- エラーハンドリング : 現在のスクリプトでは、エラーハンドリングが明示的には行われていません。ユーザー入力やAPI応答など、予期しない状況を処理するためのエラーハンドリングを追加することを検討すると良いでしょう。
- ユーザー体験 : 現在のスクリプトでは、ユーザーが何を入力すべきかについてのプロンプトが提供されていますが、ユーザーが終了する方法についての情報は提供されていません。ユーザーがいつでも対話を終了できるように、終了コマンド(例えば、「quit」や「exit」など)を追加すると良いでしょう。
- コードの再利用 : このスクリプトは特定の目的(猫のキャラクターとして振る舞うチャットボットの作成)に対して書かれていますが、可能な限り汎用的にコードを書くことで、他の目的にも再利用しやすくなります。例えば、テンプレートやモデルの名前など、特定のパラメータを外部から設定できるようにすると、このスクリプトを他の種類のチャットボットにも使用できるようになります。
以上の点を考慮に入れて、このスクリプトは非常によく書かれており、特定の目的を達成するための強力なツールとなっています。
Person:
- このスクリプトをLangChainを使わずに書き換えてください。
ChatGPT:
- LangChainを使わずに、OpenAIのAPIを直接使用して同様のチャットボットを作成することは可能ですが、LangChainが提供するような高度な機能(例えば、会話のメモリ)を再現するのは難しいです。
以下に、OpenAIのAPIを直接使用してチャットボットを作成する基本的な例を示します。ただし、この例では、猫のキャラクターとしての振る舞いや会話のメモリなど、上記のスクリプトの一部の機能は再現されていません。
import openai
# OpenAIのAPIキーを設定します。
openai.api_key = 'your-api-key'
# ユーザーからのメッセージを受け取り、それに対する応答を生成します。
while True:
user_message = input("You: ")
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": user_message
}
]
)
print("Bot: " + response['choices'][0]['message']['content'])
このコードは、ユーザーからのメッセージを受け取り、それをOpenAIのAPIに送信し、生成されたテキストを出力します。ただし、これは非常に基本的な例であり、実際のチャットボットではユーザーとの対話のコンテキストを維持するために追加のロジックが必要になることを覚えておいてください。
Person:
- ありがとうございます。systemのcontentはtemplateと同じ内容(あなたは猫のキャラクターとして…)にしてください。
それからBotの回答内容を"role":"assistant"としてmessage配列に順次追加してください。これで会話のメモリを簡易的に再現できるはずです。
ChatGPT:
- ご指摘ありがとうございます。システムメッセージの内容を指定のテンプレートに変更し、ボットの回答をメッセージ配列に追加するようにコードを修正します。
import openai
# OpenAIのAPIキーを設定します。
openai.api_key = 'your-api-key'
# テンプレートの準備
template = """あなたは猫のキャラクターとして振る舞うチャットボットです。
制約:
- 簡潔な短い文章で話します
- 語尾は「…にゃ」、「…にゃあ」などです
- 質問に対する答えを知らない場合は「知らないにゃあ」と答えます"""
# メッセージの初期化
messages = [
{
"role": "system",
"content": template
}
]
# ユーザーからのメッセージを受け取り、それに対する応答を生成します。
while True:
user_message = input("You: ")
messages.append({
"role": "user",
"content": user_message
})
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
bot_message = response['choices'][0]['message']['content']
print("Bot: " + bot_message)
messages.append({
"role": "assistant",
"content": bot_message
})
このコードでは、ユーザーからの各メッセージとボットからの各応答がmessages配列に追加されます。これにより、各新しいメッセージが前の対話のコンテキストを考慮に入れて生成されます。
ちょうどChatGPTでプラグインが使えるようになり始めた時期だったので、WebPilotを活用してChatGPTにAPIリファレンスを読み込んでもらいました。この調子で音声認識と音声合成のサンプルコードも作りました。文字にすると長く感じますが、実際には全部で1時間ほどで作成できました。
動くようになったので、家族に見せて自慢しました。しばらくは興味を持って遊んでいましたが、残念ながらすぐに飽きてしまいました。まあ、所詮はサンプルコードですし。
2日目:執筆環境を準備する
翌日は執筆環境を準備しました。前回の環境が残っていたので、設定はそのまま、Re:VIEWのバージョンだけ新しくしました。作業手順は以下の記事に詳しくまとめています。
私の執筆方針をまとめると以下のようになります。
- VSCodeで書く
- Markdownで書く
- 組版にはRe:VIEWを利用する
- GitHub Copilotを利用する
3日目〜:執筆を開始する、ひたすら書く、とにかく書く
執筆環境ができたら、あとはひたすら書いていくだけです。ここでGitHub Copilotが大活躍しました。私はかなり遅筆な方ですが、続きの文章をどう書くか迷っていると、Copilot君が文章を提案してくれます。提案された文章は、そのままでは使えない場合が多いのですが、とりあえず提案通りに書いてみます。できた文章を読み返すと、やっぱりいまいちですが、読み返すうちにもっと良い文章が思い浮かびます。消して書き直すと、そこそこ良い文章が出来上がるという寸法です。これを繰り返すことで、かなりの時間短縮になりました。
また、今回は初心者向けの本なので、サンプルコードの説明をかなり丁寧に書きました。さすがにコードの解説はCopilot君の得意分野です。コードを1行ずつ説明するようなフェーズでは、そのままでも使えそうな文章を生成してくれる確率が高まり、とても助かりました。ただし、たまに嘘をつくことがあるので、注意は必要です。
今回の本は8割ほどがサンプルコードの説明なので、機械的に作業できる部分が多く、主観的には楽に書き進められました。
12日目:校正作業1回目、表紙を作る
校正作業1回目
ようやく1冊分の原稿を書き終えました。書いている途中で、サンプルコードの不備を見つけ「ここを修正すると、こことここ、それからあそこも修正する必要がある。このままでも動くし、サンプルとしては十分だから、見なかったことにしようかな」と思いながらも、歯を食いしばって修正しました。B5サイズで72ページの薄い本ですが、GitHub Copilotの力を借りても10日ほどかかりました。もし自力だけで書いていたら、1か月はかかっていたでしょう。
さて、本の制作というのは、原稿を書いたら終わりではありません。むしろ、原稿を書き終えてようやくスタート地点に立てるといっても過言ではありません。原稿を書き終えたら地獄の校正作業が始まります。前回の本では、執筆に費やした時間よりも、校正作業に費やした時間の方が圧倒的に長くかかりました。技術書典に出すまでに1か月、商業化するまでにさらに1か月は校正作業に追われていました。
私は、人の文章の間違いを見つけるのは比較的得意です。誤字脱字を含む文章を見ると、間違っている箇所がぼんやりと光って見えるので、そのあたりを重点的に読むと実際に間違いが見つかることがよくあります。ただし、自分で書いた文章では、この能力がうまく働きません。おそらく、脳内で正しい文章に補正してしまうのでしょう。したがって、自分で書いた文章を校正するのは、とても大変でした。
今回はChatGPT(GPT-4)に校正をお願いすることで、一人でも校正作業がかなり楽になりました。プロンプトは、大体以下のような感じです。
以下に私が書いている本の一部を示します。制約事項にしたがって、校正をお願いします。
制約事項:
- 指摘のある箇所だけを表示してください
- 誤字脱字は必ず指摘してください
校正対象の文章:
{ここに校正対象の文章を貼り付ける}
あとから気づいたので、今回は実践できていませんが、制約事項は毎回書いた方がよいです。1章分の文章を全部貼り付けるとエラーになるので、分割して校正していくのですが、あとの方になるとChatGPTは制約事項を忘れてしまうようです。「最初に設定した制約事項を復唱してください」とお願いしたら、全然違う内容をでっち上げてきたので判明しました。一見すると、きちんと制約事項通りに校正されているように見えるので、なかなか気づきませんでした。ChatGPTに長い文章を連続して校正させると、雰囲気で校正するようになるという気づきを得ました。
1回目の校正作業は、最も修正量が多くなります。文章そのものの構成や、サンプルコードの内容にも指摘が入るので、必要に応じて修正します。説明が不足している箇所は加筆し、冗長な箇所は削除します。
表紙を作る
私が校正作業をしている間、妻にCanvaで表紙を作ってもらいました。出来上がった表紙はこちらです。素人が作ったにしては、なかなかよくないですか。
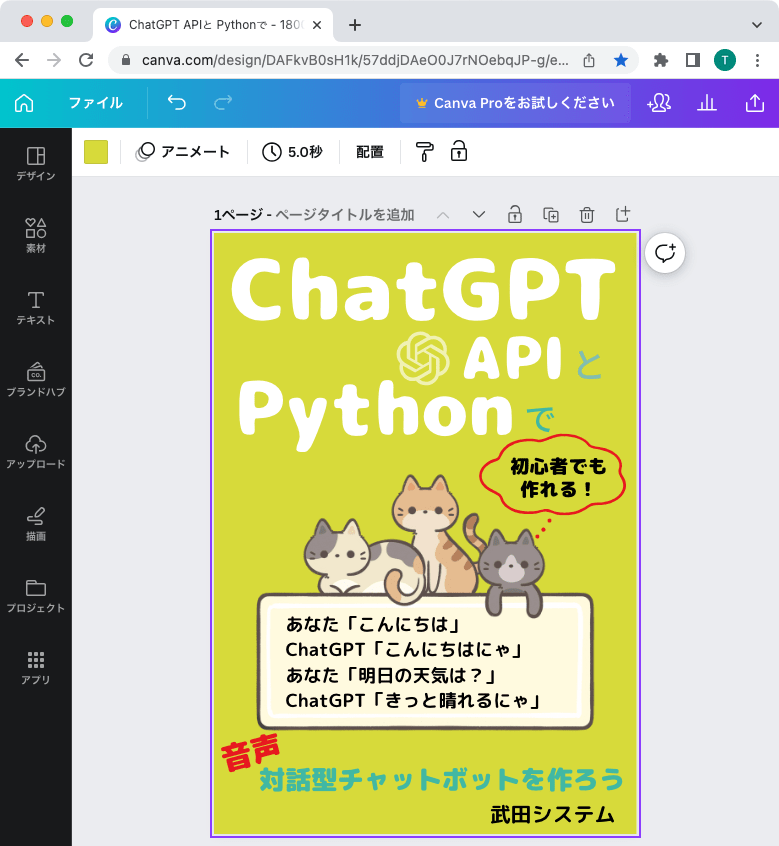
13日目:紙に印刷して校正する(校正作業2回目)、最終校正1回目(校正作業3回目)
紙に印刷して校正する(校正作業2回目)
「それはそうと、一部分とはいえアレで校正作業は完了ですの?」
「いや、あの後、紙に印刷して紙媒体でじっくり目視確認して修正する」
「紙もデータも書いてある文字は同じなのですからちゃんとWordで修正しておけば間違いは残らないはずではなくて?」
「のーこーるーの!どういうわけか知らんが、紙にして見直さんと絶対絶っっっ対ミスが残るように宇宙の法則で決まっとるんじゃ!」
――――左高例「獣耳吸血鬼少女の売れないなろう作家が自作品を電子書籍にするようです」より
1回目の校正が終わったら、今度は紙に印刷して校正します。不思議と、画面上では気づかなかったミスが、紙の上ではあっさり見つかったりするものです。ここではChatGPTの恩恵は受けられないので、ざっくり目を通して次の校正作業に移りました。
最終校正1回目(校正作業3回目)
次は最終校正です。最終といいつつも、1回目と書いてある通り、この後も校正作業が残っています。ここで行う校正は、基本的には最初の校正作業と同じで、ChatGPTにお願いします。ただし、プロンプトの制約事項に次の内容を追加します。
- ソースコードの内容は校正対象から除外してください
- 文章全体の構成についてのアドバイスは不要です
1回目の校正作業で、ソースコードと文章の構成は固まっているので、指摘されないようにしました。この作業が終わった時点で、文章としてはほぼ完成です。
14日目:最終校正2回目(校正作業4回目)、出版する、最終校正3回目(校正作業5回目)
最終校正2回目(校正作業4回目)
最終校正の2回目は、epubファイルをKindleに転送して、見え方を確認します。私はFireタブレットとiPhoneのKindleアプリ、Mac標準アプリの「ブック」で確認しました。iPhoneのKindleアプリで見ると、箇条書きが改行されず横に繋がってしまうという現象を発見しましたが、おそらくKindleアプリのバグだろうと判断しました。
出版する
ようやく出版です。Kindle Direct Publishing(KDP)にサインインして、epubファイルと表紙をアップロードします。Amazonのレビューが通ったらKindleストアに表示されます。私の場合は、レビューに3日もかかってやきもきしました。
最終校正3回目(校正作業5回目)
出版したあとも校正作業は残っています。今度は自分で自分の本を購入し、Kindleアプリで表示を確認します。iPhoneでも正常に表示されたので、epubファイルが正常に表示されなかったのは、やはりKindleアプリのバグだったようです。これでようやく初版の完成です。
おまけ:ペーパーバック版を作る
ペーパーバック版の表紙を作る
せっかくなので、ペーパーバック版も作ってみました。ペーパーバック版を作るのは簡単で、印刷用のPDFと表紙を用意するだけです。PDFは、Re:VIEWのコマンドを切り替えるだけで簡単に作れます。表紙は、KDPのサイトで型紙をダウンロードできるので、それに合わせて作ります。出来上がった表紙はこちらです。
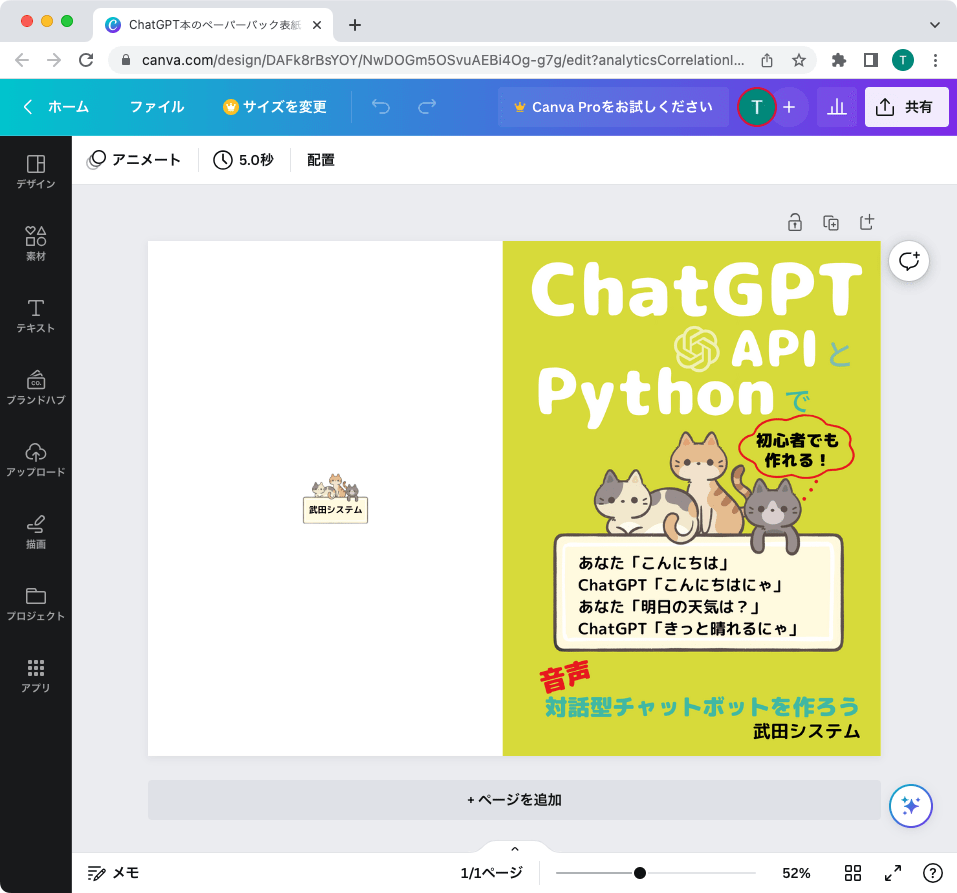
校正刷りを注文する
表紙をアップロードしたら、著者用の校正刷りを注文できるようになります。校正刷りを見て、仕上がりを確認し、必要であれば修正します。校正刷りには、下図のように「再販禁止」という文字が入ります。

私は、校正刷りを見て、表紙を少し修正することにしました。また、表紙仕上げを「光沢なし」から「光沢あり」に変更しました。
ペーパーバックを出版する
表紙を更新して設定を変更したら、いよいよ出版です。またAmazonのレビュー待ちになりますが、今度は同じ内容だったためか、翌日には販売されました。これも自分で購入しました。思ったよりもきれいな仕上がりで大満足です。

まとめ
ChatGPTとGitHub Copilotに手伝ってもらいながら、2週間で技術書を出版した経緯を紹介しました。1作目と比べると、作業の効率が格段に上がりました。今後も、ChatGPTとGitHub Copilotを使って、本を出版していきたいと思います。次は、小説も書いてみたいな。
Discussion