執筆背景
CtoC EC サイトにおいて、出品者に売れそうな商品をおすすめしたり、購入者にクーポンを配ったりしたい。その効果を予測したり最適化したりしたい。特に直接的なKPIである利益を予測対象にしたい。この問題をオフ方策評価を使って解くことが可能か考えたい。
オフ方策評価で解くメリットは、直接的に最適化したい KPI を最適化出来ることと考える。
問題の定式化
最適化したい KPI 定義
商品が購入されることにより得られる利益とする。
データの観測構造をモデル化
商品の特徴量を x で表す。行動は a∈A で表す(行動は例えば出品者に商品をおすすめするかしないかやクーポンを配るか配らないかなどが考えられる)。商品から得られる利益を r と表す。商品特徴量の観測確率を p(x) と表す。ベースライン方策を πb(a∣x) とし、評価方策を π(a∣x) と表す。報酬の観測確率を p(r∣x,a) と表す。
ベースライン方策で観測されたログデータ D は以下のように表せる。
D={(xi,ai,ri)}i=1n∼p(x)π(a∣x)p(r∣x,a)
真に推定したい指標
真に推定したい指標は評価方策により得られる利益の期待値である。
V(π)=Ep(x)π(a∣x)p(r∣x,a)[r]=Ep(x)π(a∣x)[q(x,a)]
ここで、 q(x,a)=Ep(r∣x,a)[r] は期待報酬関数である。
ログデータで推定したい指標を近似
ログデータ D を利用して推定したい指標を近似した値 V^(π;D) を得ることを考える。
実験
実験に利用したコードは以下参照。
https://github.com/st81/ope-continuous-reward
各種パラメータ設定
特徴量の次元数は 10 とした。行動 a は2種類とした。行動は正規分布からサンプルした 10 次元のベクトルで表すこととした。ログデータのサイズは 8000 とした。評価方策の真の性能を近似するためのデータサイズは 100000 とした。
ベースライン方策は以下で定義した。
πb(a∣x;β)=∑a′∈Aexp(β⋅q(x,a′))exp(β⋅q(x,a))
β はデフォルト値を -3.0 とした。
評価方策は epsilon-greedy 方策とし以下で定義した。
π(a∣x;ϵ)=(1−ϵ)⋅I{a=a′∈Aargmaxq(x,a′)}+∣A∣ϵ
ϵ はデフォルト値を 0.1 とした。
推定量は比較的簡単に計算することができる IPS 推定量を試してみる。IPS 推定量は以下で表される。
V^IPS(π;D)=πb(a∣x)π(a∣x)ri
シミュレーション回数は100回とした。
とりあえず推定量計算(実験 ID2)
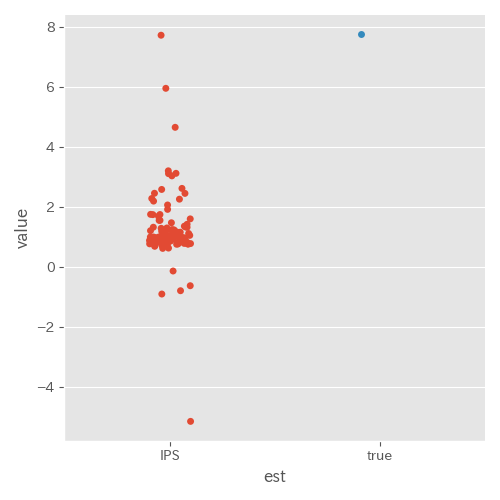
推定精度がかなり悪い。原因は β=−3.0 としたことでベースライン方策と評価方策が大きく異なるものになってしまっていたためであった。実際にログデータでの報酬の平均値を計算すると約 2.0 であり、評価方策の真の性能とは大きく異なる値であった。
β=0.1 に変更(実験 ID4)
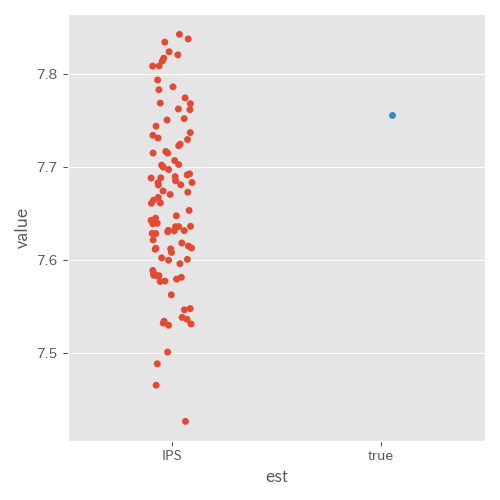
推定値にばらつきはあるもののそこまで悪くない結果に思える。例えば、推定したい1商品あたり期待利益が上図の1万倍の77500円だと仮定すると、75000 ~ 78000円位の範囲に推定値があるため、直感的には十分使えそうな精度に感じた。
また、ログデータでの報酬の平均値を計算すると約 6.2 であり、先ほどと比べて評価方策の真の性能との差が小さくなっていることも確認できた。
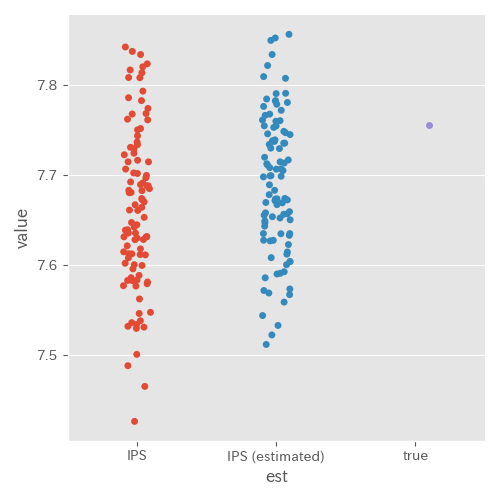
πb を推定した場合(実験 ID5)
実際の EC サイトではベースライン方策の行動選択確率をログとして残していない場合も考えられる。そこで、 πb を推定した場合にどうなるかを実験してみた。pib の推定にはロジスティック回帰を利用した。
πb 及び π を推定した場合(実験 ID7)
実際に EC サイトのデータに対してオフ方策評価の性能を確認する場合、過去のある時点をログデータ、それより先の過去のある時点をテストデータとしたい。このとき、テストデータ上での評価方策もログとして残していない場合が考えられる。そこで、 π も推定した場合の検証を行った。
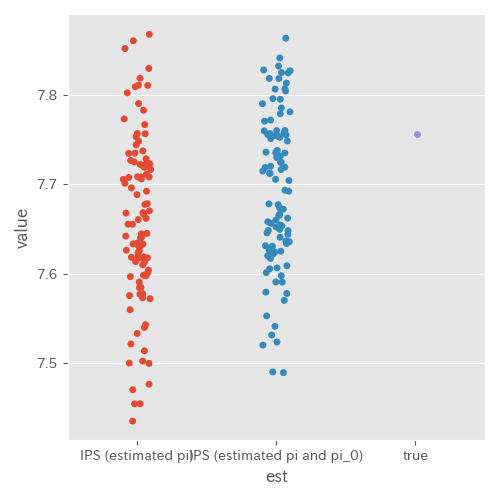
この場合も精度はあまり変わらなかった。



Discussion