[R] Jaggerとキーワード付きトピックモデル(keyATM)を用いたテキストマイニング
高速な形態素解析器であるJaggerのRラッパーであるRcppJaggerと、キーワードとして事前知識を利用できるトピックモデルであるkeyATMを用いて、Rでテキストマイニングを行います。
トピックモデルとして最も標準的なLatent Dirichlet Allocation (LDA)と違い、keyATMパッケージで実装されているKeyword-Assisted Topic Modelsは、分析者の事前知識を活用できるだけでなく(半教師ありトピックモデル)、共変量や時系列情報を利用することができます。
インストール
以下は、macOS Monterey上のR 4.3.0で実行しています。
RcppJagger
RcppJaggerはJaggerのラッパーのため、まずJaggerをインストールします。公式サイトに従ってインストールしていきます。RcppJaggerのヘルプページでもインストール方法が説明されています。
Jaggerがインストールされると、ターミナルからJaggerを実行することができます。
$ jagger
(input: stdin)
日本語の文章
日本 名詞,地名,*,*,日本,にほん,*
語 名詞,普通名詞,*,*,語,ご,*
の 助詞,接続助詞,*,*,の,の,*
文章 名詞,普通名詞,*,*,文章,ぶんしょう,*
EOS
Jaggerがインストールされていることを確認したら、RでRcppJaggerをインストールします。
標準のdata.frameの代わりに、tibbleを利用するので、tidyverseパッケージがない場合は、ここでインストールします。
install.packages("RcppJagger")
install.packages("tidyverse")
keyATM
keyATMをインストールします。
install.packages("keyATM")
quanteda
Rでテキストを管理するquantedaをインストールします。
install.packages("quanteda")
kaigiroku
国会議事録データを用いた分析をするため、kaigirokuパッケージをインストールします。
install.packages("kaigiroku")
RcppJaggerを用いた形態素解析
パッケージの読み込み
library(quanteda)
library(RcppJagger)
library(keyATM)
library(kaigiroku)
データの読み込み
国会議事録データを読み込みます。
kokkai <- get_meeting(
house = "Lower", sessionNumber = 200,
meetingName = "予算委員会"
)
nrow(kokkai)
[1] 993
データの各行が1つの発言に対応しているため、第200回国会の衆議院予算委員会では、予算委員会での発言が993回あったことがわかります。
発言は、speechという列に保管されています。
kokkai$speech[10] # 10行目の`speech`
[1] "○棚橋委員長 質疑の申出がありますので、順次これを許します。坂本哲志君。"
データの前処理
空の発言や、○棚橋委員長 のような発言者名を取り除き、発言部分のみを残します。
kokkai <- kokkai[kokkai$speaker != "", ]
kokkai$speech <- gsub("^○\\S+\\s+", "", kokkai$speech)
kokkai$speech <- gsub("(.+?)|〔.+?〕", "", kokkai$speech)
kokkai$speech <- gsub("^\\s{2,}.+\n", "", kokkai$speech)
kokkai$speech <- gsub("(\\n|\\r)", "", kokkai$speech)
RcppJaggerによるトークン化
RcppJaggerを用いて、各発言をトークン化します。ここでは、kokkaiオブジェクトがtibble形式であるため、tokenize_tbl()を用います。発言が保存されている列名を指定し (ここではspeech)、3つの品詞に着目します。
kokkai_tkn <- tokenize_tbl(
kokkai, column = "speech",
model_path = "/usr/local/lib/jagger/model/kwdlc",
keep = c("名詞", "動詞", "形容詞")
)
ベクトル形式を利用する場合は、tokenize()を用います。$を使うことで、tibbleの特定の列を指定できます。
kokkai_tkn_vec <- tokenize(
kokkai$speech,
model_path = "/usr/local/lib/jagger/model/kwdlc",
keep = c("名詞", "動詞", "形容詞")
)
RcppJaggerに用意されているそのほかの関数については、こちらのページを確認してください。
データの整形
quantedaを用いて、データを整形します。まず、corpus()でkokkai_tknを読み込んだ後に、RcppJaggerでのトークン化された結果を使ってtokensオブジェクトを作成します。既に上で品詞を指定しましたが、更に数字や日本語のストップワードを取り除いています。
kokkai_corpus <- corpus(kokkai_tkn, text_field = "tokenized")
kokkai_tokens <- tokens(
kokkai_corpus,
what = "fastestword",
remove_numbers = TRUE,
remove_punct = TRUE,
remove_symbols = TRUE,
remove_separators = TRUE,
remove_url = TRUE
) |>
tokens_remove(
stopwords("ja", source = "marimo")
)
次に、dfm()で文書単語行列を作成します。低頻度のトークン、ひらがなだけ・カタカナだけのトークンを除き、最後にこれまでの処理の結果トークンが残らず、空になってしまった文章(発言)を取り除きます。
kokkai_dfm <- dfm(kokkai_tokens) |>
dfm_trim(min_termfreq = 5, min_docfreq = 2) |>
dfm_remove(pattern = "^[あ-ん]+$", valuetype = "regex") |>
dfm_remove(pattern = "^[ア-ン]+$", valuetype = "regex")
kokkai_dfm <- dfm_subset(kokkai_dfm, ntoken(kokkai_dfm) > 0)
この文章単語行列に、トピックモデルを適用します。
最後に、
keyATM_read()を用いてkeyATMに必要なデータ形式に変換します。
keyATM_docs <- keyATM_read(kokkai_dfm)
Latent Dirichlet Allocation
トピックモデルに事前情報を利用した場合の結果と比べるため、初めに最も標準的なトピックモデルであるLatent Dirichlet Allocation(LDA)を適用します。
keyATMパッケージでは、weightedLDA()という関数がLDAに対応しています。
out_lda <- weightedLDA(
docs = keyATM_docs,
model = "base",
number_of_topics = 15, # トピック数
options = list(seed = 1000) # 再現性確保のための`seed`
)
ここでは、議事録に含まれるトピック数が15であると仮定しています。トピック数を変えることで、結果の解釈が変わる可能性があることに気をつける必要があります。
各トピックを解釈するために、Top Wordsという、各トピックにおいて出現確率が高い単語の一覧を表示します。
top_words(out_lda)
| Topic_1 | Topic_2 | Topic_3 | Topic_4 | Topic_5 | Topic_6 | Topic_7 | Topic_8 | Topic_9 | Topic_10 | Topic_11 | Topic_12 | Topic_13 | Topic_14 | Topic_15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 日本 | 思い | 委員 | 憲法 | 試験 | 大臣 | 報告 | 金 | 米 | 消費 | 船 | 年金 | 参考人 | 災害 | 思い |
| 環境 | 大臣 | 会 | 議論 | 民間 | 思い | 関電 | 企業 | 交渉 | 経済 | 北朝鮮 | 保障 | 理事 | 支援 | 思って |
| 処理 | 今 | 長 | 改正 | 大学 | 総理 | 委員 | 税 | 協定 | 日本 | 漁船 | 社会 | 政府 | 台風 | 指摘 |
| 国 | 方 | 願い | 総理 | 英語 | 責任 | 調査 | 消費 | 関税 | 増税 | 水産庁 | 世代 | 大臣 | 被災 | 考えて |
| 水 | 問題 | 今井 | 会 | 受験 | 国民 | 会 | 話 | 日本 | 税 | 答え | 厚生 | 国務大臣 | 被害 | 検討 |
| 気候 | 総理 | ワーキンググループ | 国民 | 生 | 政治 | 会社 | 店 | 自動車 | データ | 沈没 | 三十 | 山本 | 避難 | 状況 |
| 変動 | 話 | 内閣 | 日本 | 採点 | 国会 | 第三者 | 事業 | 貿易 | 金融 | 通報 | 制度 | 補欠 | 対策 | 今後 |
| 世界 | 人 | 議事 | 自民党 | 大臣 | 会 | 事業 | 交付 | 撤廃 | 政策 | 抗議 | 高齢 | 辞任 | 思い | 今回 |
| 飼料 | 省 | 局長 | 審査 | 教育 | 議員 | 省 | 補助 | tpp | 社会 | 購入 | 議論 | 選任 | 復旧 | 会議 |
| 我が国 | 思う | 選定 | 安保 | 入試 | 説明 | 電力 | 料 | 協議 | 金利 | 載って | 国民 | 充 | 今回 | 行う |
Keyword-Assisted Topic Models
事前知識をキーワードとして活用する (keyATM Base)
予算委員会では、広く国政全般にわたる議題が登場することが知られています。ここで、事前知識を活用してキーワードを設定します。
keywords <- list(
`経済` = c("経済", "税"),
`災害` = c("災害", "台風", "被災"),
`教育` = c("教育", "試験", "大学"),
`貿易` = c("貿易", "関税"),
`年金` = c("年金"),
`憲法` = c("憲法", "改正")
)
キーワードはリスト形式で定義されます。ここでは6つのキーワード付きトピックが考えられており、それぞれに1つ以上のキーワードが設定されています。
visualize_keywords()を利用することで、それぞれのキーワードの頻度を確認できます。
p <- visualize_keywords(keyATM_docs, keywords)
save_fig(p, filename = "keywords.png", width = 5, height = 3)
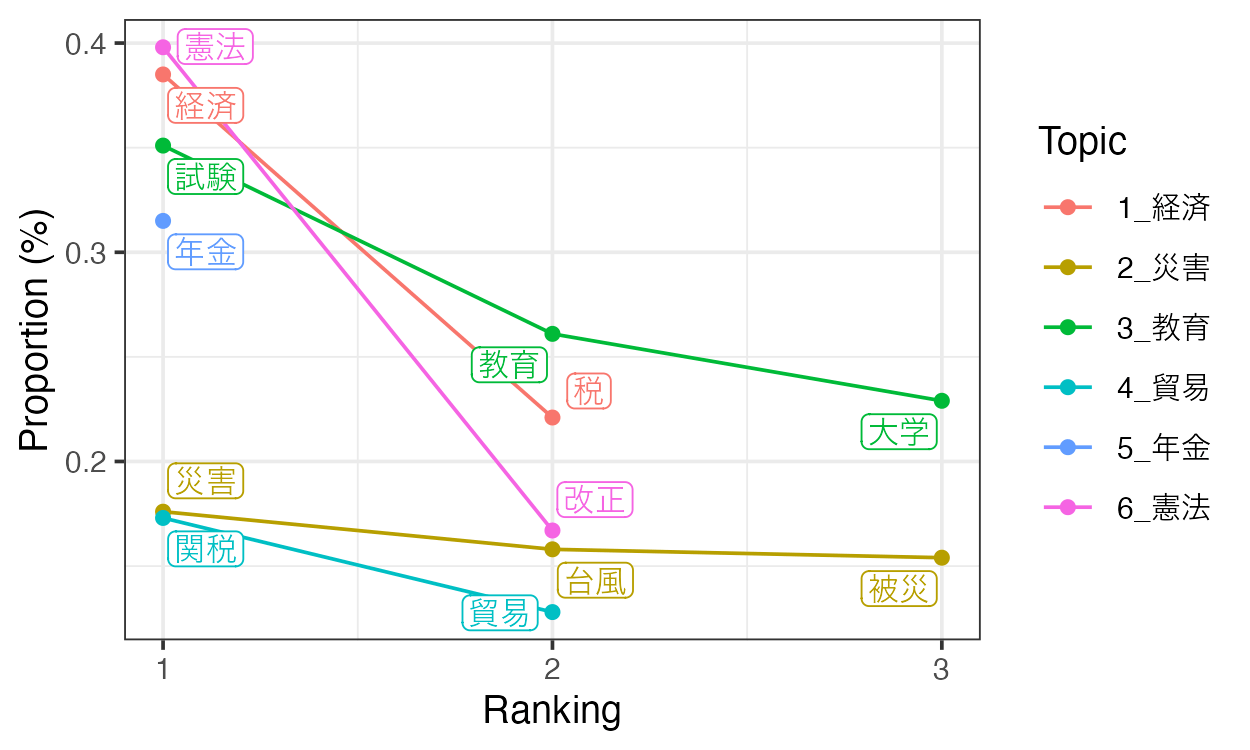
キーワード付きトピックが6つあるため、合計のトピック数を先ほどと同じ15に揃えるために、9個のキーワードなしトピックを追加します。
out_key <- keyATM(
docs = keyATM_docs,
keywords = keywords,
no_keyword_topics = 9, #キーワードなしトピックの数
model = "base",
options = list(seed = 1000)
)
# top_words(out_key) # 全てのトピックを表示
top_words(out_key)[, 1:6] # キーワード付きトピックのみを表示
| 1_経済 | 2_災害 | 3_教育 | 4_貿易 | 5_年金 | 6_憲法 |
|---|---|---|---|---|---|
| 消費 | 災害 [✓] | 試験 [✓] | 米 | 年金 [✓] | 憲法 [✓] |
| 税 [✓] | 台風 [✓] | 民間 | 日本 | 社会 | 議論 |
| 経済 [✓] | 被災 [✓] | 大学 [✓] | 交渉 | 世代 | 国民 |
| 考えて | 支援 | 英語 | 協定 | 保障 | 改正 [✓] |
| 状況 | 思い | 受験 | 関税 [✓] | 厚生 | 総理 |
| データ | 避難 | 教育 [✓] | 自動車 | 制度 | 国会 |
| 増税 | 被害 | 生 | 貿易 [✓] | 三十 | 会 |
| 税率 | 対応 | 採点 | 大統領 | 議論 | 議員 |
| 教育 [3] | 対策 | 制度 | 今回 | 負担 | 政権 |
| 社会 | 復旧 | 入試 | 撤廃 | 保険 | 自民党 |
キーワード付きのトピックには、チェックマークで表されたキーワードだけではなく関連する単語が表示されていることがわかります。keyATMでは、それぞれのトピックが分析前にキーワードによってラベル付されているため、解釈が容易になります。
共変量を利用したモデル (keyATM Covariate)
keyATMでは、共変量や時系列情報を利用することができます。ここでは、記録されている発言数が多い「自由民主党・無所属の会」と「立憲民主・国民・社保・無所属フォーラム」に着目に着目して分析します。
dplyrパッケージを使って発言を抽出したのち、トークン化と前処理を行います。
library(dplyr)
# "自由民主党・無所属の会"と"立憲民主・国民・社保・無所属フォーラム"に着目
kokkai_part <- as_tibble(kokkai) |>
filter(speakerGroup %in% c("自由民主党・無所属の会", "立憲民主・国民・社保・無所属フォーラム")) |>
mutate(Party = ifelse(speakerGroup == "自由民主党・無所属の会", "Ruling", "Opposition"))
kokkai_tkn <- tokenize_tbl(kokkai_part, column = "speech", keep = c("名詞", "動詞", "形容詞"))
kokkai_corpus <- corpus(kokkai_tkn, text_field = "tokenized")
kokkai_tokens <- tokens(
kokkai_corpus,
what = "fastestword",
remove_numbers = TRUE,
remove_punct = TRUE,
remove_symbols = TRUE,
remove_separators = TRUE,
remove_url = TRUE
) |>
tokens_remove(
stopwords("ja", source = "marimo")
)
kokkai_dfm <- dfm(kokkai_tokens) |>
dfm_trim(min_termfreq = 5, min_docfreq = 2) |>
dfm_remove(pattern = "^[あ-ん]+$", valuetype = "regex") |>
dfm_remove(pattern = "^[ア-ン]+$", valuetype = "regex")
kokkai_dfm <- dfm_subset(kokkai_dfm, ntoken(kokkai_dfm) > 0)
keyATM_docs <- keyATM_read(kokkai_dfm)
party_data <- kokkai_part |> select(Party)
out_cov <- keyATM(
docs = keyATM_docs,
no_keyword_topics = 9,
keywords = keywords, # 先ほど実行したkeyATM Baseと同じキーワードです
model = "covariates",
model_settings = list(
covariates_data = party_data,
covariates_formula = ~ Party
),
options = list(seed = 1000)
)
top_words(out_cov)[, 1:6] # キーワード付きトピックのみ表示
| 1_経済 | 2_災害 | 3_教育 | 4_貿易 | 5_年金 | 6_憲法 |
|---|---|---|---|---|---|
| 経済 [✓] | 災害 [✓] | 試験 [✓] | 米 | 年金 [✓] | 憲法 [✓] |
| 消費 | 思い | 民間 | 交渉 | 社会 | 議論 |
| 考えて | 被害 | 教育 [✓] | 協定 | 保障 | 改正 [✓] |
| 税 [✓] | 対応 | 受験 | 関税 [✓] | 世代 | 総理 |
| 思って | 今回 | 思い | 日本 | 三十 | 国民 |
| 指摘 | 対策 | 問題 | 自動車 | 議論 | 会 |
| 状況 | 台風 [✓] | 大学 [✓] | 貿易 [✓] | 制度 | 国会 |
| 検討 | 避難 | 生 | 撤廃 | 厚生 | 自民党 |
| データ | 支援 | 英語 | 協議 | 国民 | 飼料 |
| 今 | 被災 [✓] | 採点 | 大統領 | 高齢 | 議員 |
2つの会派では、発言内容に違いがあるのでしょうか?
strata_topic <- by_strata_DocTopic(
out_cov, by_var = "PartyRuling",
label = c("野党系", "与党系")
)
fig_doctopic <- plot(strata_topic, var_name = "Party", show_topic = 1:6)
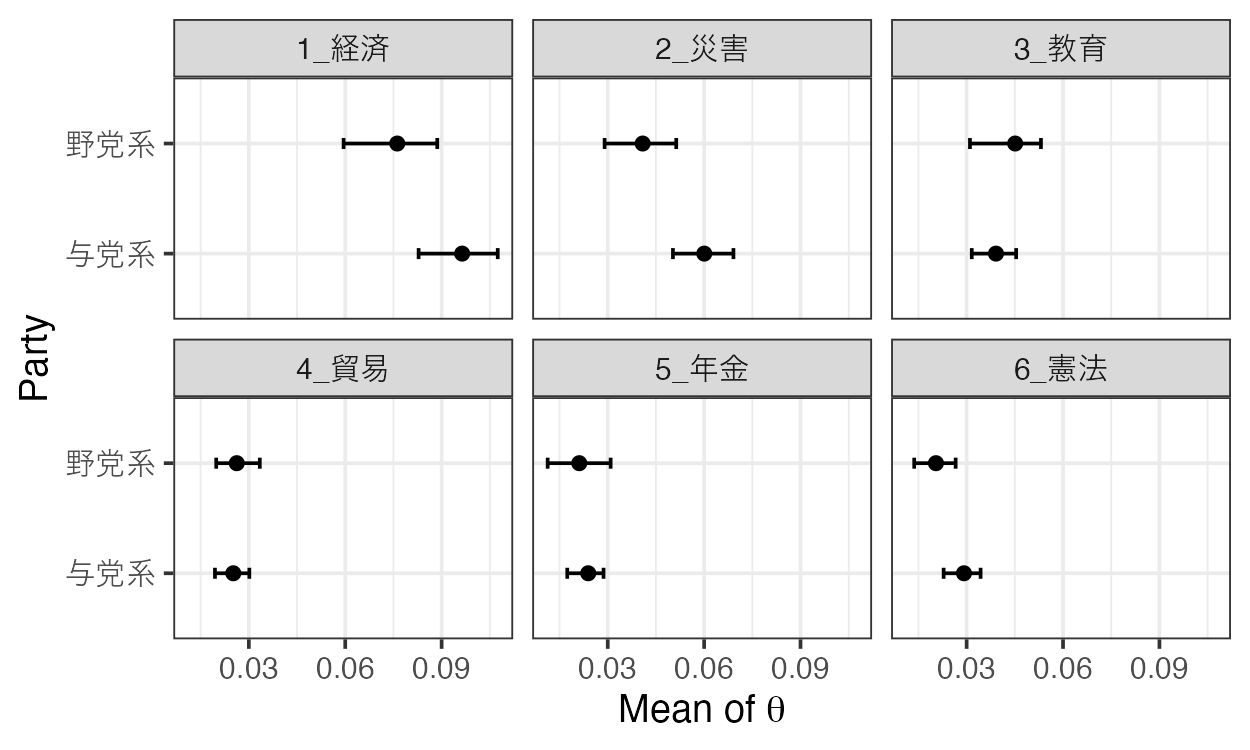
"Mean of
推定の再開
データのサイズが大きくなると、keyATM()やweightedLDA()の実行に時間がかかることがあります。以下のようにresumeオプションを使用することで、100回のイテレーションで一度推定結果を保存し、再度同じコードを実行することで推定を101回目のイテレーションから再開することができます。
out_key <- keyATM(
docs = keyATM_docs,
keywords = keywords,
no_keyword_topics = 9,
model = "base",
options = list(seed = 250, iterations = 100, resume = "./keyATM_resume.rds")
)
この機能については、こちらのページのコードを参考にしてください。
さらに詳しく知るために
- Jaggerについて
- keyATMについて
* 論文とそのarXiv版
* keyATMパッケージ
* keyATM Base: 本稿で紹介したキーワード付きトピックモデル
* keyATM Covariate: 本稿で紹介した共変量を利用できるモデル
* keyATM Dynamic: 時系列情報を利用できるモデル
Discussion
JaggerのRcppラッパーがあるということを知って、大変参考になりました。
記事について一点だけ指摘すると、
quanteda::tokensは、とくに何も指定しない場合、あらかじめ半角スペースで分かち書きされたテキストを必ずしも尊重してくれないと思います。たとえば次の例文では、素直に
quanteda::tokensに渡してしまうと、「入り浸って」がquantedaによって再分割されてしまいます。あくまでJaggerで分かち書きされた通りのtokensオブジェクトを作成したい場合、たとえば次のようにする必要があります。
重大な見落としをご指摘いただいてありがとうございます!コメントいただいてから時間が経ってしまいましたが、本文を修正しました。