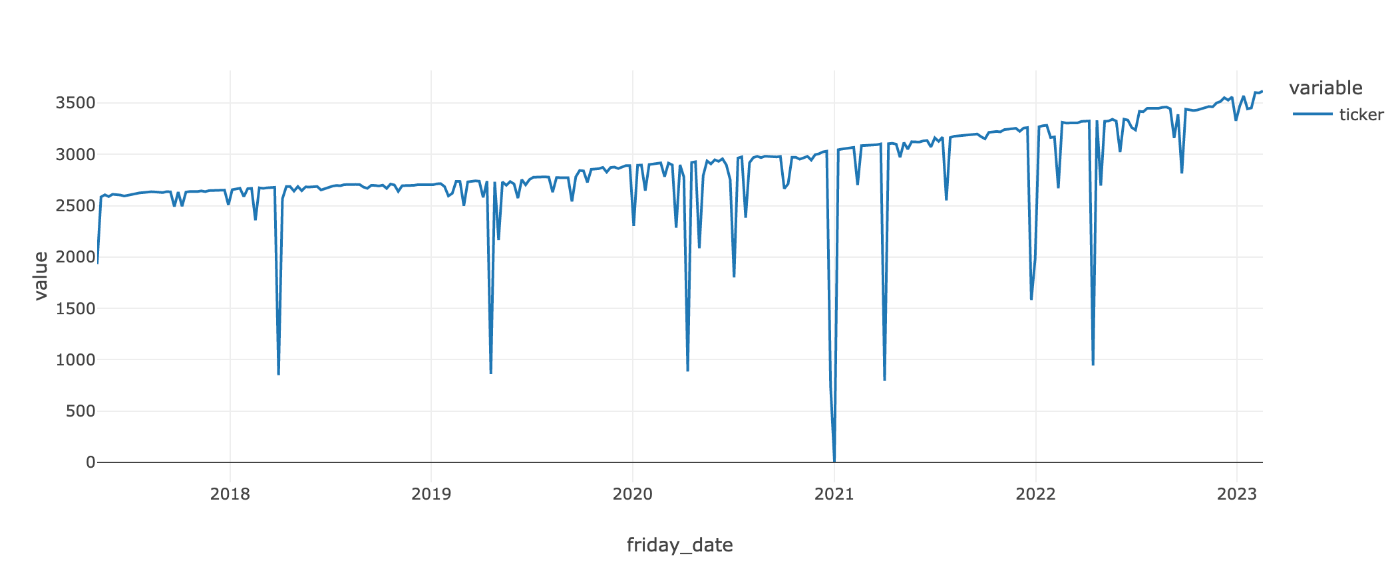
株価データの探索的データ分析
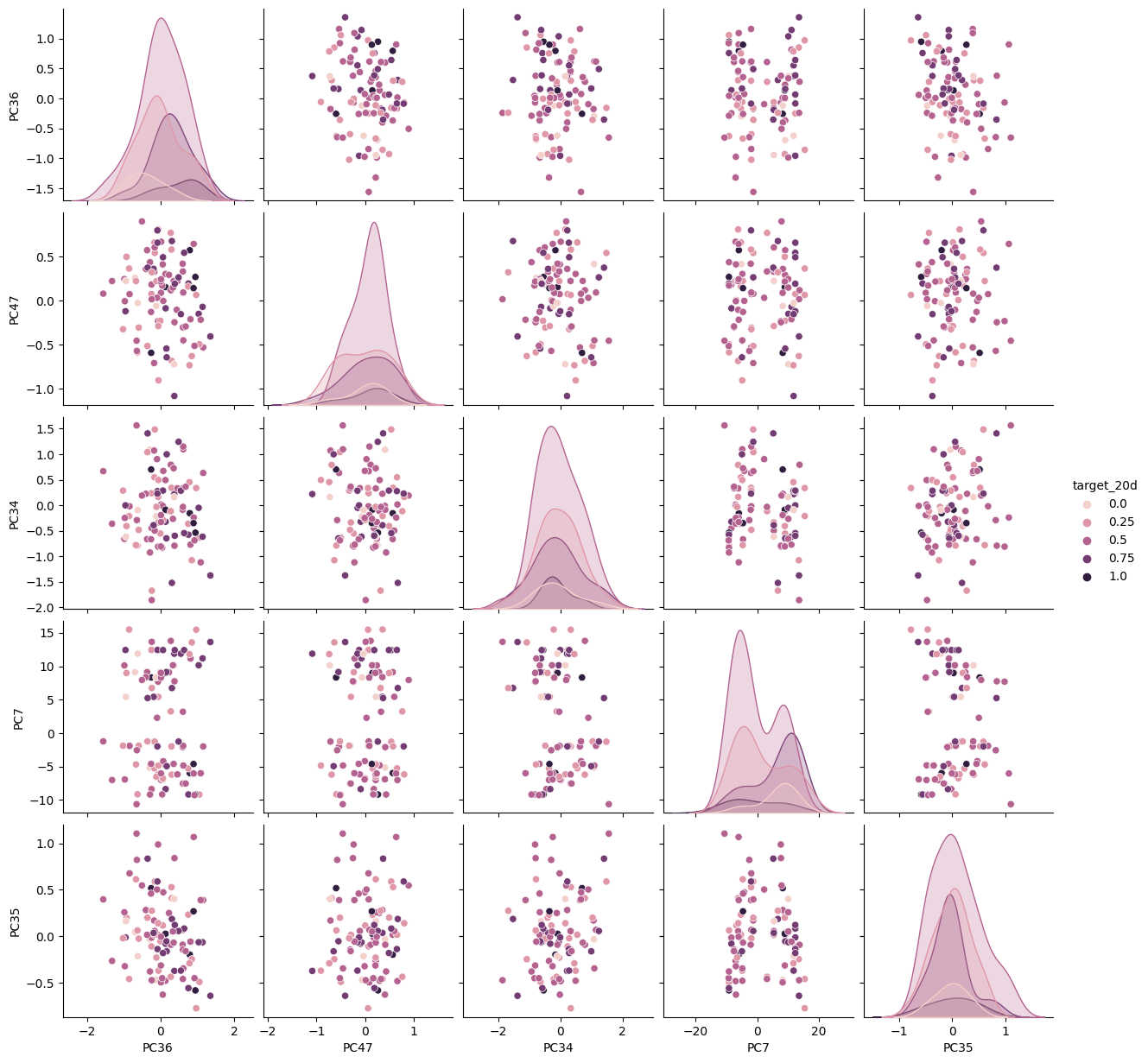
色々な処理をした結果このように説明変数がある程度ターゲットに対して識別可能な分布をしていることがわかる
しかしT-SNEではあまり違いが見られない
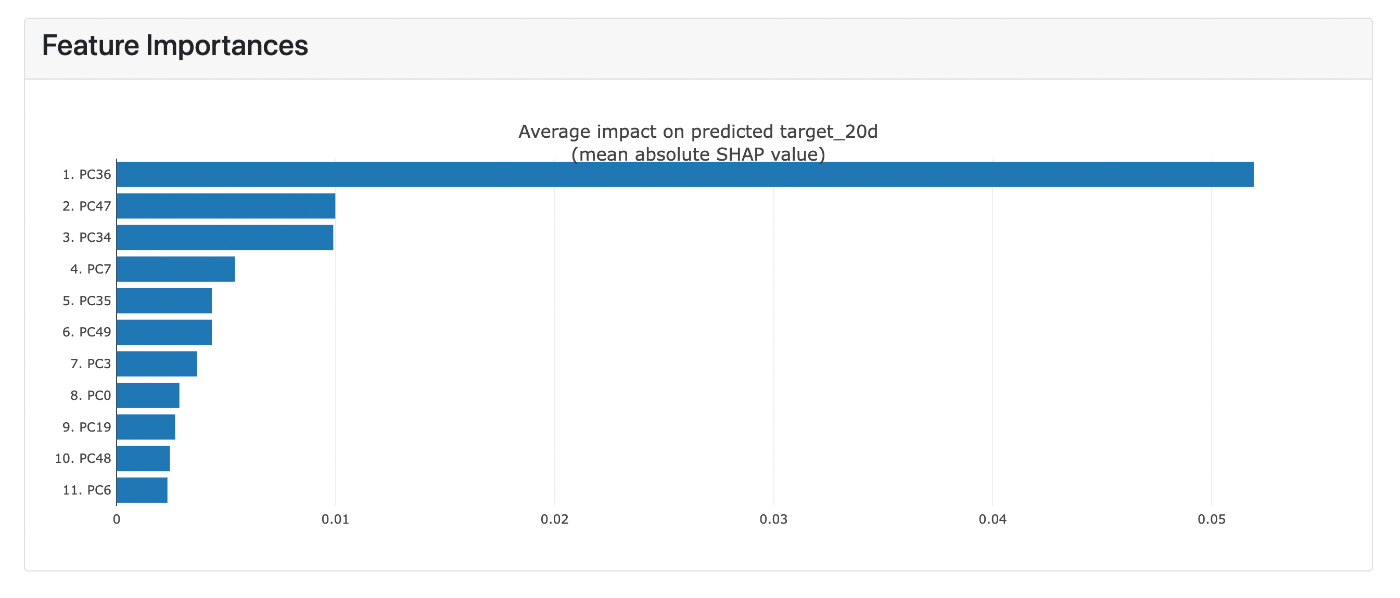
モデルの入力が出力に与える影響もある程度はっきりしてきた
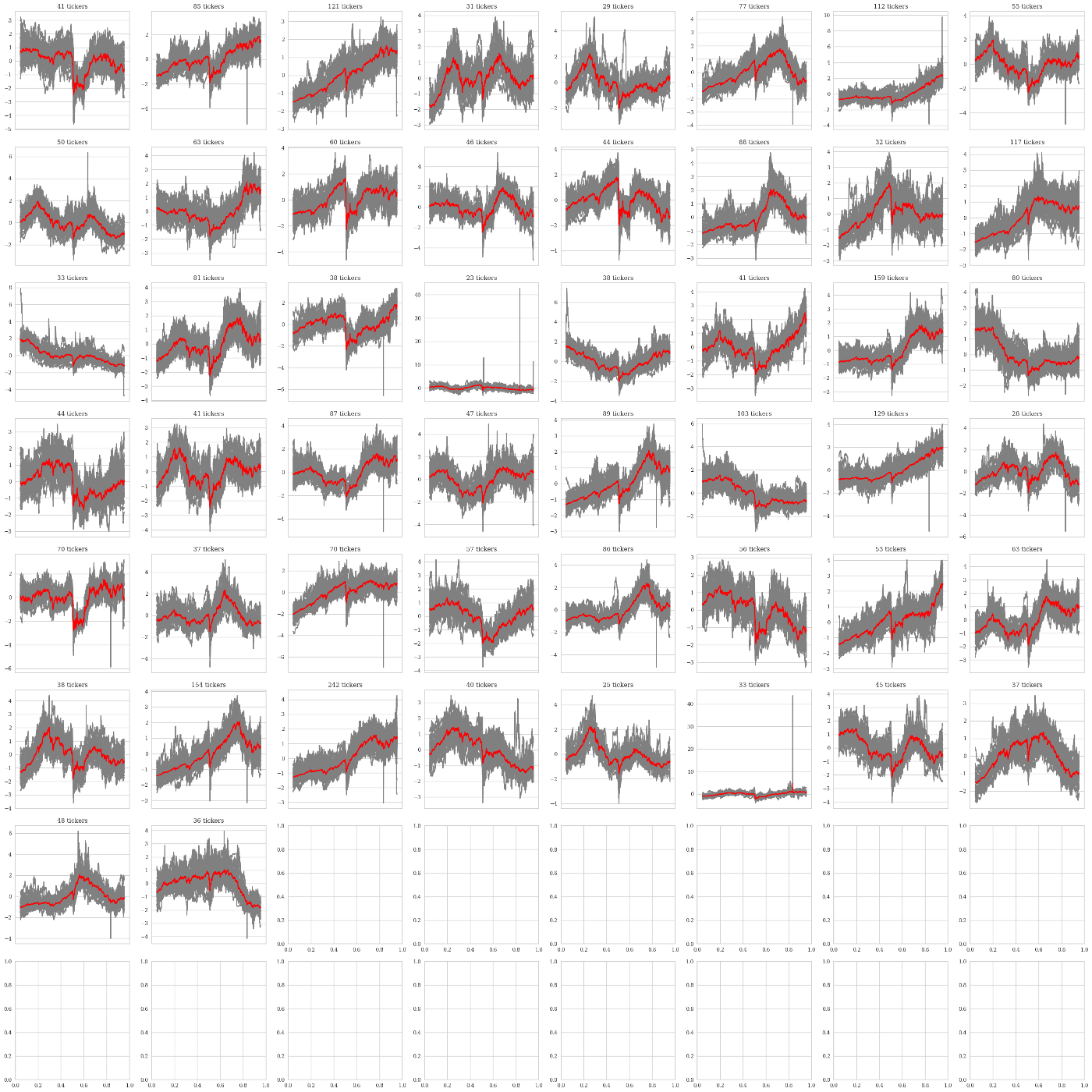
Clustering for huge signal universe
Results from PCA after calclating popular technical indicators.
modified pca results
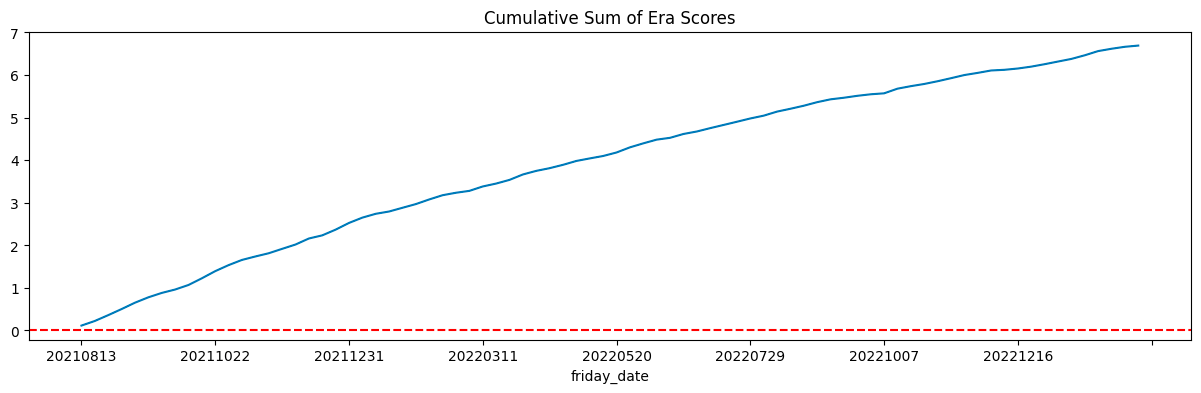
Result on test data

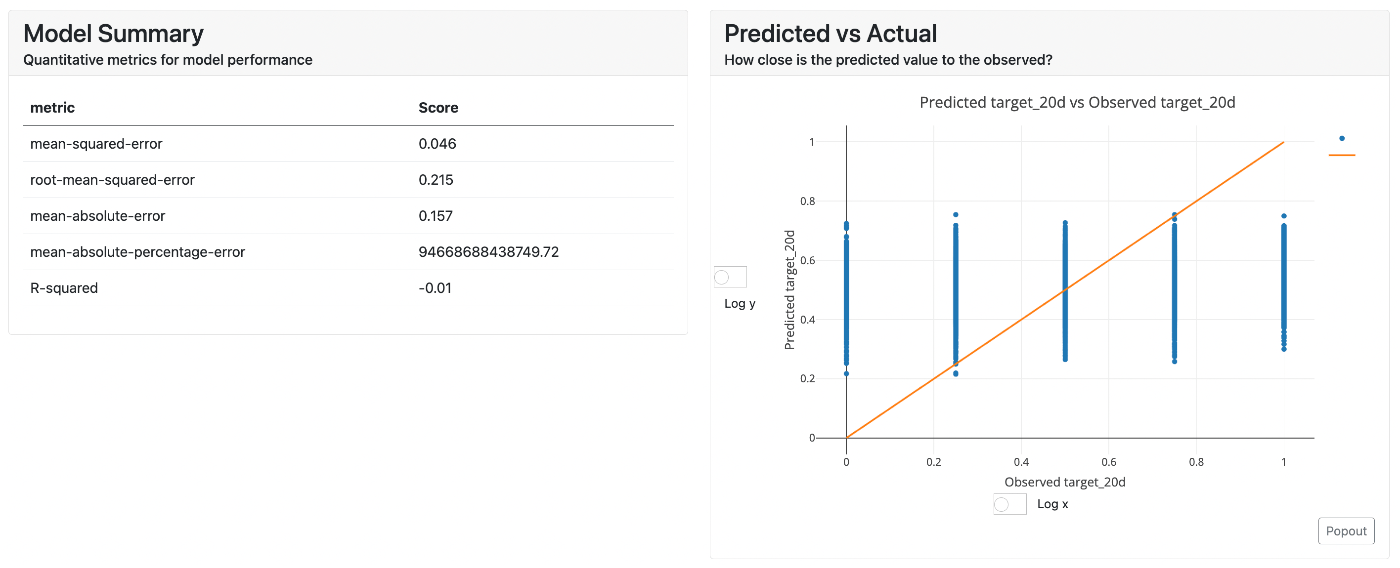
Regression result
Based on my experience so far, it seems that we don't have to force us to use data including old stock price. Trainig models on relatively recceent data makes better accracy to forecast future from now.
無理に過去のデータを使うより新しめのデータを使った方が未来の予測精度は上がるかもしれない
How does PCA effects gradient boosting regressor??
I'm now rewriting code from notebook to normal python file
I just found there was a leakage in my stock market predicting process. I was suspicious because the accuracy was unusually high.
We cannot use test data to calclate mean and std for normalization process, also PCA process
PCA after caring about LEAKAGE

:(
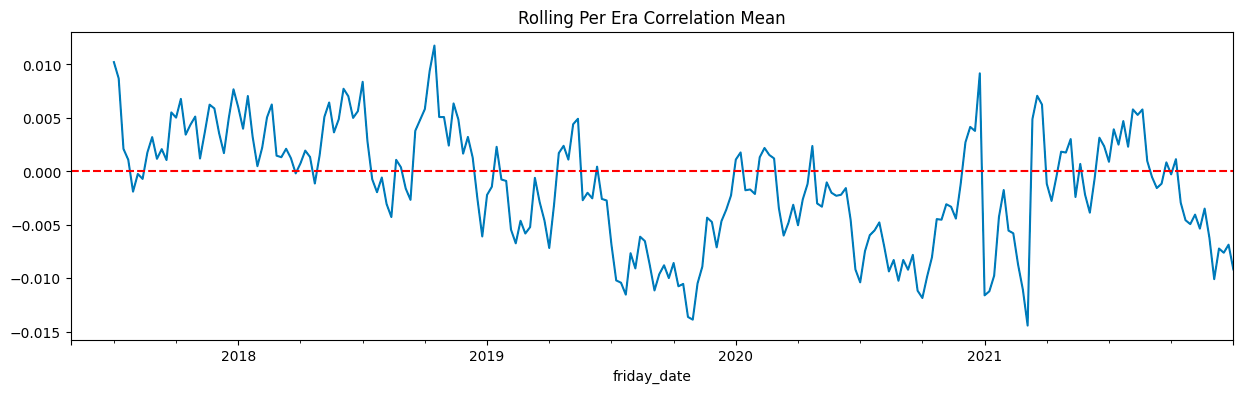
Mean Correlation: 0.0204
Median Correlation: 0.0189
Standard Deviation: 0.0182
Mean Pseudo-Sharpe: 1.1241
Median Pseudo-Sharpe: 1.0400
Hit Rate (% positive eras): 91.53%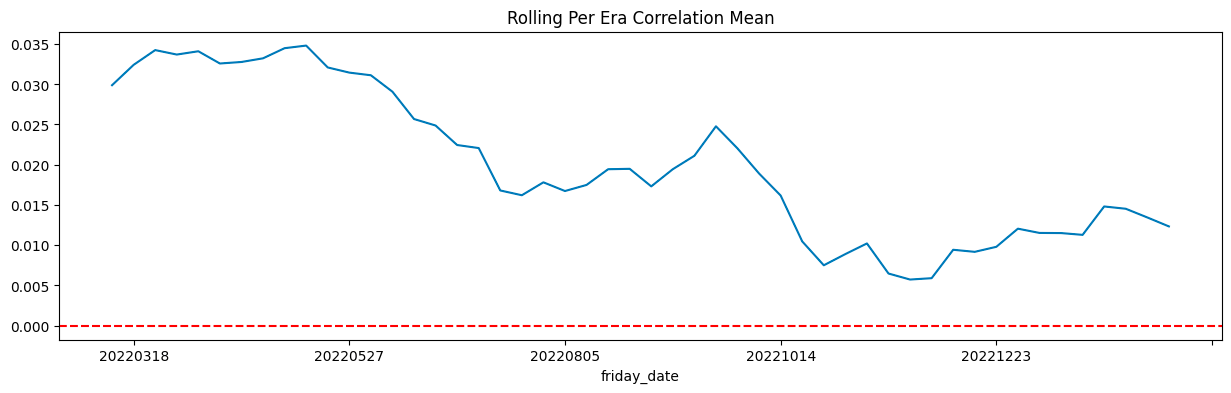
Preprocessing takes long time.... ::(((
on train data
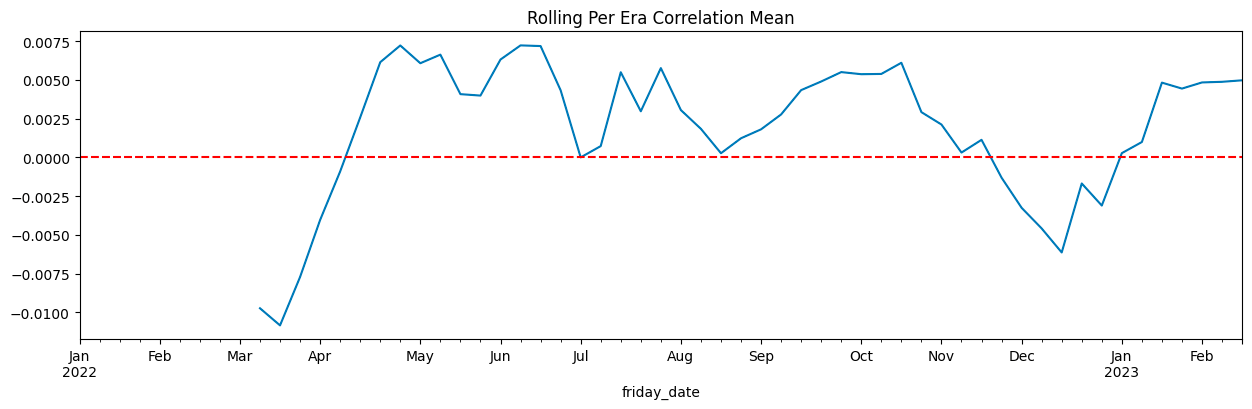
Mean Correlation: -0.0013
Median Correlation: -0.0002
Standard Deviation: 0.0229
Mean Pseudo-Sharpe: -0.0589
Median Pseudo-Sharpe: -0.0073
Hit Rate (% positive eras): 49.59%
Mean Correlation: 0.0009
Median Correlation: 0.0013
Standard Deviation: 0.0166
Mean Pseudo-Sharpe: 0.0568
Median Pseudo-Sharpe: 0.0784
Hit Rate (% positive eras): 55.93%
Baseline method
Mean Correlation: 0.0207
Median Correlation: 0.0212
Standard Deviation: 0.0208
Mean Pseudo-Sharpe: 0.9946
Median Pseudo-Sharpe: 1.0223
Hit Rate (% positive eras): 83.05%
[[Original Method 1]]
Mean Correlation: 0.0205
Median Correlation: 0.0199
Standard Deviation: 0.0181
Mean Pseudo-Sharpe: 1.1319
Median Pseudo-Sharpe: 1.0976
Hit Rate (% positive eras): 89.83%
[[Original Method 2]]
Mean Correlation: 0.0009
Median Correlation: 0.0013
Standard Deviation: 0.0166
Mean Pseudo-Sharpe: 0.0568
Median Pseudo-Sharpe: 0.0784
Hit Rate (% positive eras): 55.93%
工夫する前, before applying my idea

自分なりに工夫した後, after applying my idea
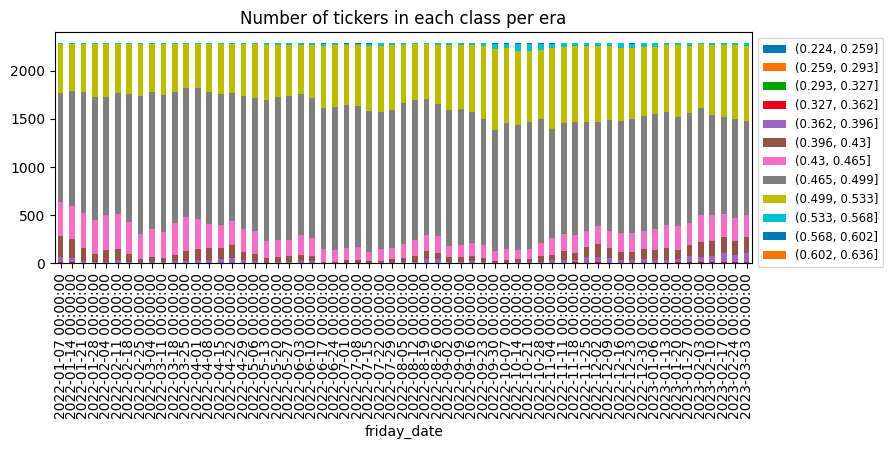
株価のような非定常なデータに対して正規化を行うのは結構難しい
テストデータと訓練データでリーケージがないようにしないといけないからだ
訓練データの平均と分散を用いてテストデータの正規化を行うと
テストデータが訓練データとあまりにも異なる値になってしまう
これは株価は大きく変動するから、非定常なデータであるからだ
この問題のせいで
テストデータに対して精度が出ないという問題がある
さらに、そもそも訓練データ内でリーケージが起きるという問題がある
私はこれからpct_change()を使ってみようと思う
これを用いることで定常性を持たせることができる
これを試してみたが精度が出なかった
改善案
1ある日付の株価でRankを計算
2それぞれの日付において標準化する、時間方向には標準化しないことに注意
3深層学習モデルに入力する
訓練データに対してはいい結果だが、テストデータに対しては悪かった
わざとリーケージを起こしてみると、精度は
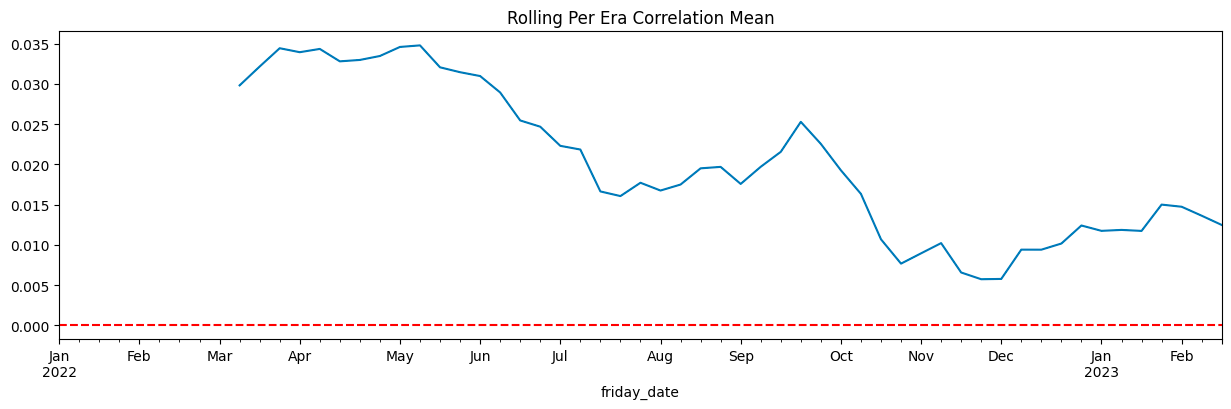
Mean Correlation: 0.0245
Median Correlation: 0.0272
Standard Deviation: 0.0230
Mean Pseudo-Sharpe: 1.0657
Median Pseudo-Sharpe: 1.1815
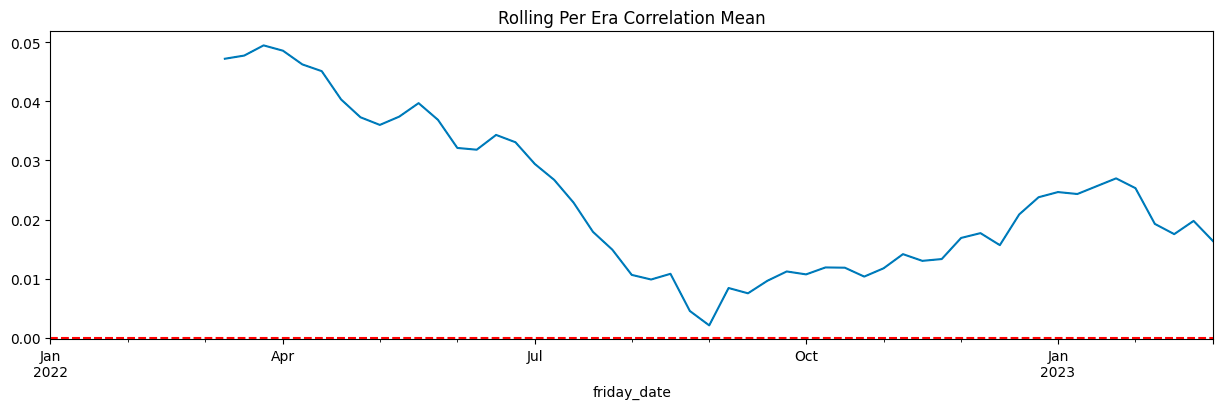
から
Mean Correlation: 0.0008
Median Correlation: 0.0033
Standard Deviation: 0.0246
Mean Pseudo-Sharpe: 0.0325
Median Pseudo-Sharpe: 0.1338
Hit Rate (% positive eras): 50.82%
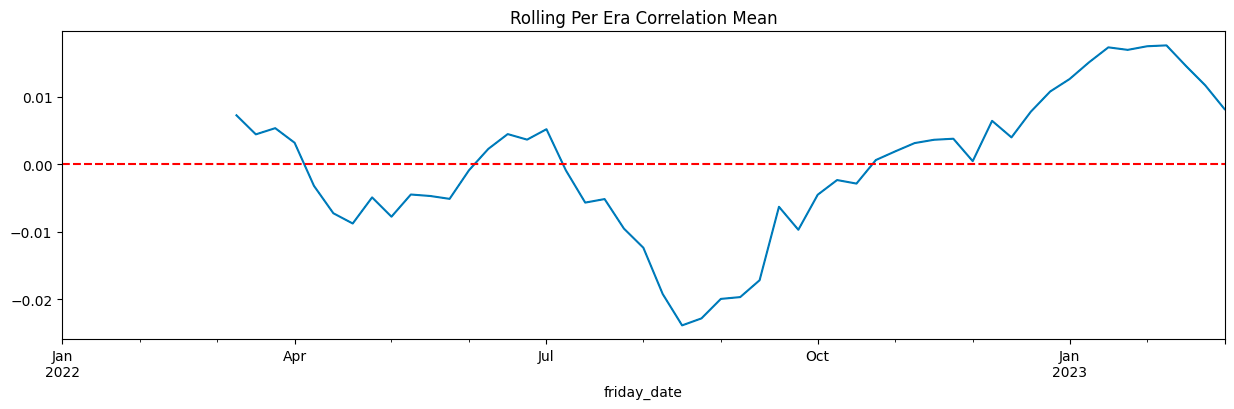
になった
このことから
訓練データにテストデータの情報が漏れていることがわかる