株価データの非定常性に対するロバスト性
MA 100によりトレンド除去
従来法
Mean Correlation: 0.0107
Median Correlation: 0.0118
Standard Deviation: 0.0224
Mean Pseudo-Sharpe: 0.4788
Median Pseudo-Sharpe: 0.5278
Hit Rate (% positive eras): 65.57%
提案法
Mean Correlation: 0.0097
Median Correlation: 0.0106
Standard Deviation: 0.0224
Mean Pseudo-Sharpe: 0.4344
Median Pseudo-Sharpe: 0.4713
Hit Rate (% positive eras): 63.93%
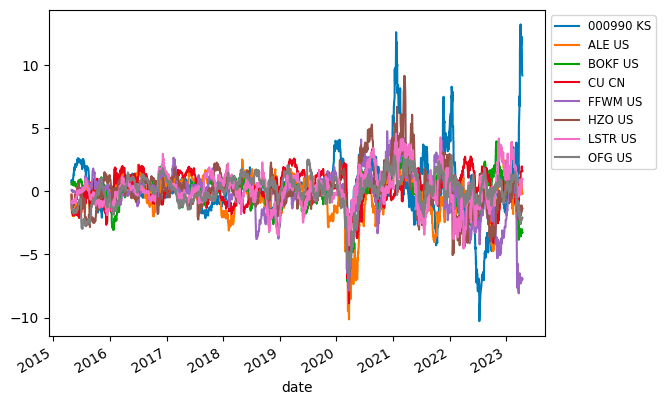
従来法
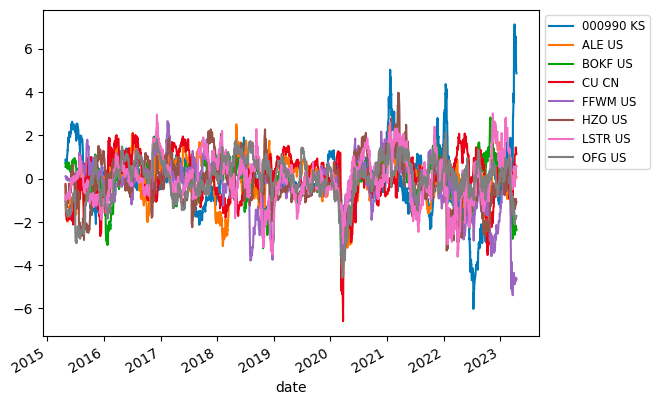
提案法
elif SCALING == "RemoveMovingAverageAndStandardLobast":
df = df - df.rolling(window=PCT_DIFF).mean()
split_date_first = "2019-01-01"
split_date_second = "2022-01-01"
train_df__ = df[df.index<split_date_first]
test_df__ = df[(df.index>=split_date_first) & (df.index<split_date_second)]
scaler = StandardScaler()
train_df__ = pd.DataFrame(scaler.fit_transform(train_df__),
index=train_df__.index, columns=train_df__.columns) # normalize for clustering
test_df__ = pd.DataFrame(scaler.fit_transform(test_df__),
index=test_df__.index, columns=test_df__.columns) # normalize for clustering
train_df__ = pd.concat([train_df__,test_df__])
# split_date = "2022-01-01"
train_df = df[df.index<split_date_second]
test_df = df[df.index>=split_date_second]
scaler = StandardScaler()
scaler.fit(train_df)
test_df = pd.DataFrame(scaler.transform(test_df),
index=test_df.index, columns=test_df.columns) # normalize for clustering
df = pd.concat([train_df__,test_df])
elif SCALING == "RemoveMovingAverageAndStandard":
df = df - df.rolling(window=PCT_DIFF).mean()
split_date = "2019-01-01"
train_df = df[df.index<split_date]
test_df = df[df.index>=split_date]
scaler = StandardScaler()
train_df = pd.DataFrame(scaler.fit_transform(train_df),
index=train_df.index, columns=train_df.columns) # normalize for clustering
test_df = pd.DataFrame(scaler.transform(test_df),
index=test_df.index, columns=test_df.columns) # normalize for clustering
df = pd.concat([train_df,test_df])
あんまり変わんなかった

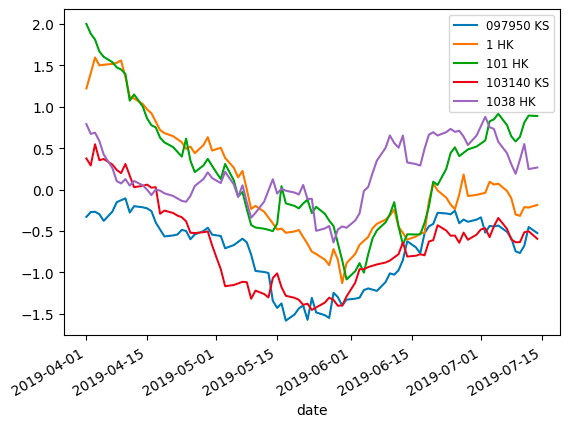
定常性を持たせるためにどれくらいの移動平均を引けばいいか、精度との関係性は??
rolling 100
Mean Correlation: 0.0097
Median Correlation: 0.0106
Standard Deviation: 0.0224
Mean Pseudo-Sharpe: 0.4344
Median Pseudo-Sharpe: 0.4713
Hit Rate (% positive eras): 63.93%

rolling 30
Mean Correlation: 0.0076
Median Correlation: 0.0096
Standard Deviation: 0.0216
Mean Pseudo-Sharpe: 0.3499
Median Pseudo-Sharpe: 0.4441
Hit Rate (% positive eras): 64.52%
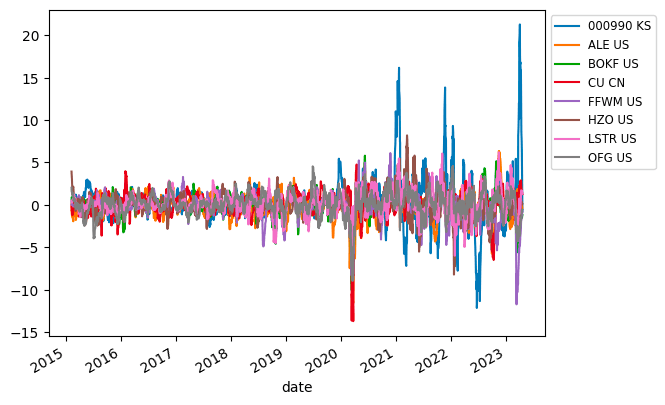
大きい方がいい可能性がある
これはなんとなく予想できる