関数型プログラミングメモ
書籍「なっとく!関数型プログラミング」を読みながら、感想を流すスクラップです。
進捗 📝
- 5章: 36
- 6/2(日) 1/36 ~ 36/36
- 6章: 52
- 6/2(日) 1/52 ~ 22/52 (11:33)
- 6/2(日) 22/52 ~ 52/55 (16:07)
- 7章: 39
- 6/3(月) 1/39 ~ 6/39
- 6/8(土) 6/39 ~ 18/39
- 6/12(水) 18/39 ~ 24/39
- 6/17(月) ~ 38/39
- 8章: 39
- 6/22(土) ~ 20/39
- 6/23(日) ~ 39/39 (※ 38の課題は、9章終了後にやること!)
- 9章: 29
- 10章: 28
- 11章: 23
- 12章: 42
純粋関数の特徴
- 戻り値は常に1つだけ
- 引数だけを使う
- 既存の値を変更しない
関数の戻り値は常に1つだけ/関数は既存の値を変更する
以下のコードは以下に反している
- 関数の戻り値は常に1つだけ
- addItemメソッドはvoid型で、値を返却していない
- 関数は既存の値を変更する
- itemsフィールドの内部構造をaddメソッドで変更している
public class ShoppingCart {
private List<String> items = new ArrayList<>();
private boolean bookAdded = false;
public void addItem(String item) {
items.add(item);
if (item.equals("Book")) {
bookAdded = true;
}
}
関数は引数にのみ基づいて戻り値を計算する
以下のコードは以下に反している
- 関数は引数にのみ基づいて戻り値を計算する
- bookAddedというクラスのフィールドの基づいて計算を行っている
public class ShoppingCart {
private List<String> items = new ArrayList<>();
private boolean bookAdded = false;
public int getDiscountPercentageBad() {
if(bookAdded) {
return 5;
} else {
return 0;
}
}
関数型
- 関数の戻り値は常に1つだけ
- 関数は引数にのみ基づいて戻り値を計算する
- 関数は既存の値を変更しない
public class ShoppingCart {
public static int getDiscountPercentage(List<String> items) {
if(items.contains("Book")) {
return 5;
} else {
return 0;
}
}
}
クラスメソッドにとってクラスフィールドに格納された値は、外部の値なんだよな。
純粋関数にするには以下のテクニックが必要そう
- 格納せずに再計算
- 状態を引数として渡す
- 既存の値を変更せず、変更済みのコピーを戻り値として返す
2.12
信頼される純粋関数
- 関数ができることは全てのそのシグネチャに書いてある
- 関数は引数を受け取り、値を返す。それ以外は特になもしない。
プログラミングでの純粋関数の存在は、数学関数にヒントを得たらしい。確かに数学関数として意識すると純粋関数のイメージがつきやすいと感じた。
2.18
ScalaなどのFP言語では、ifは式であるため、returnキーワードはない。関数内の最後の式が戻り値として使われる
Rustだけだと思っていました
純粋関数のメリット
- 単一責任
- 副作用がない
- 参照透過性
単一責任
副作用がない
(副作用とは)
引数に基づいて戻り値を計算する以外に関数が行うことは全て副作用がある
- HTTP呼び出し
- グローバル変数やインスタンスフィールドの変更
- データベース挿入
- 標準出力
- ログの記録
- スレッドの作成
- 例外のスロー
- 画面に描画
参照透過性
式の構成要素がすべて同じなら、式の値は常に同じになるということ
アプリケーションの状態は何か、データベースが稼働しているかどうかに関わらず 同じ値を返す。
以下の例は、1つ値を返し、既存の値を変更しないが、引数だけを使うに反する。渡された引数以外のものに基づいて、ランダムデータを生成(副作用)
static double randomPart(double x) {
return x * Math.random()
}
以下の例は、Stringが空の場合は例外をスローするため、戻り値は常に1つだけに反する
static char get FirstCharacter(String s) {
return s.charAt(0);
}
3.4.
可変性(ミュータブル)が危険という話。TSだとイミュータブルに書くように気をつけないといけないところはあるよね、、
この具体例はいいね。lapTimes.remove(0);がavgTimeでも呼ばれているから、既存の値を変更していて、ラプスタイムの先頭1つだけを削除したんだけど、totalTime -> avgTimeと呼び出すことで先頭2つ削除されてしまう。
package com.sample.main;
import java.util.*;
public class RapTimes {
static double totalTime(List<Double> lapTimes) {
lapTimes.remove(0);
double sum = 0;
for (double x: lapTimes) {
sum += x;
}
System.out.printf("sum: %f\n", sum);
return sum;
}
static double avgTime(List<Double> lapTimes) {
double time = totalTime(lapTimes);
int laps = lapTimes.size();
System.out.printf("%f %d\n", time, laps); // 42.4 / 2
return time / laps;
}
}
// -- main
ArrayList<Double> lapTimes = new ArrayList<>();
lapTimes.add(31.0);
lapTimes.add(20.9);
lapTimes.add(21.1);
lapTimes.add(21.3);
System.out.printf("Total: %.1fs\n", RapTimes.totalTime(lapTimes));
System.out.printf("Avg: %.1fs\n", RapTimes.avgTime(lapTimes));
avgTimeとか2回リストのコピーが走っていて、冗長には見えるけど確かに安全だ
public class RapTimes {
static double totalTime(List<Double> lapTimes) {
- lapTimes.remove(0);
+ List<Double> withoutWarmUp = new ArrayList<>(lapTimes);
+ withoutWarmUp.remove(0);
+
double sum = 0;
- for (double x: lapTimes) {
+ for (double x: withoutWarmUp) {
sum += x;
}
- System.out.printf("sum: %f\n", sum);
return sum;
}
static double avgTime(List<Double> lapTimes) {
double time = totalTime(lapTimes);
- int laps = lapTimes.size();
+
+ List<Double> withoutWarmUp = new ArrayList<>(lapTimes);
+ withoutWarmUp.remove(0);
+ int laps = withoutWarmUp.size();
System.out.printf("%f %d\n", time, laps); // 42.4 / 2
どちらも引数だけを使って計算された値を1つだけ返しているし、既存の値を変更しない。予想に近い振る舞いをするため、これらの関数に対する信頼性は高まっている。繰り返しにはなるが、このような特性を参照透過性と呼ぶ。まったく同じ引数が渡された場合、これらの関数は───たとえ何があろうと───まったく同じ値を返す
参照透過性はここまでやりきりないとだよね。自分が作る関数が、副作用を起こしてないかより意識する必要がありそう🐥
あー、でもDRY原則に違反しているって書いてあるな。多分withoutWarmUpを初期化するところかな 🤔
7章でやるみたいだから、到達したらここに戻ってこよう。
3.13
appended 非破壊的で良い
// 3.13
val appleBook = List("Apple", "Book")
val appleBookMongo = appleBook.appended("mongo")
// imutable!!!!!
printf("appleBook size: %d\n", appleBook.size)
printf("appleBookMongo size: %d\n", appleBookMongo.size)
4.4. 関数のシグネチャは事実をありのままに伝えるべきである
List<String> myWords2 = Arrays.asList("ada", "haskell", "scala", "java", "rust");
System.out.println(myWords2);
List<String> convertedMyWords2 = WordScore.rankedWords2(myWords2);
System.out.println(convertedMyWords2);
List<String> myWords3 = Arrays.asList("ada", "haskell", "scala", "java", "rust");
System.out.println(myWords3);
// scoreCompartorへ依存性を明らかにした。
List<String> convertedMyWords3 = WordScore.rankedWords3(WordScore.scoreComparator, myWords3);
System.out.println(convertedMyWords3);
これはわかるんだけど、どこまでやるべきかも悩むな。ビジネスロジックが多いと、引数で渡すものも増えそう 🤔
ただ依存性を注入しているので、テストはしやすそうに見える
4.5
よりエレンガントだね。シグネチャを見ればどういうソートアルゴリズみでソートされるかわかりやすい。
// よりエレガント
List<String> convertedMyWords5 = WordScore.rankedWords3((w1, w2) -> Integer.compare(WordScore.score(w2), WordScore.score(w1)), myWords3);
System.out.println(convertedMyWords5);
4.9. ユーザー定義の関数を引数として渡す
バージョン5のスコアリング関数を渡す。リファクタリングしたコード。
rankedWords3では、Comparator全体を渡していたが、rankedWords4ではより単純なワードのスコアリングロジックを渡すようにした。ビジネスロジックの切り出しという意味では比較するComparatorを隠蔽するのは良いし、見通しが良くなりそう。
static List<String> rankedWords3(Comparator<String> comparator, List<String> words) {
return words.stream().sorted(comparator).collect(Collectors.toList());
}
// Comparator全体を渡すことは、複雑なのでもう少し単純なものを渡せるようにリファクタリングする
static List<String> rankedWords4(Function<String, Integer> wordScore, List<String> words) {
Comparator<String> wordComparator = (w1, w2) -> Integer.compare(wordScore.apply(w2), wordScore.apply(w1));
return words.stream().sorted(wordComparator).collect(Collectors.toList());
}
純粋関数のシグネチャは嘘をつかない。というのはわかるんだけど、限界はあるよなとも思う。頑張っても中身見ないとわからないということにはなりそう。
そこで諦めず、よりドメインに近い処理を切り出して、シグネチャだけで理解できるように考え尽くすことが重要なのかなと感じた。
Javaは非オブジェクト指向パラダイムでもプログラムを表現できる、非常に融通の効く言語であることを裏付けている (中略) 残念ながら、関数型プログラミングをJavaで使うことには現実的な問題もある。コードを大量に書かなければならないし、ミュータブルなListを使うことになる。
static List<String> rankedWords4(Function<String, Integer> wordScore, List<String> words) {
Comparator<String> wordComparator = (w1, w2) -> Integer.compare(wordScore.apply(w2), wordScore.apply(w1));
return words.stream().sorted(wordComparator).collect(Collectors.toList());
}
Scalaだと圧倒的に簡潔に書けすぎてすごい
スコアが負になることに配慮する必要があるが、これは逆順のソートに関する実装の詳細にすぎない。つまりソースコードの順序を逆にするためのレシピである。そして、「何を行う必要があるか」ではなく、「どのように行うか」に気を取られると、常にソースコードが読みにくくなる。
これは最初でもあった宣言型でない例になっている。文章を読むだけで解釈できた方が良い。この負にする処理は、手続的で読みにくいということ。
val score = (word: String) => word.replaceAll("a", "").length
def rankedWords(
wordScore: String => Int,
words: List[String]
): List[String] = {
def negativeScore(word: String): Int = -wordScore(word)
words.sortBy(negativeScore)
}
// --- 実行 ---
{
// 4.16
val words = List("rust", "java")
val sortedWords = rankedWords(score, words)
assert(
sortedWords == List("rust", "java")
) // 4, 2なのでrust -> javaの順で並ぶ必要あり
}
4.21
scoreWithBounsが内部でscore関数を使い、その上にボーナスの計算をしており、複数のことを行っている。
こういう場合は、関数をインラインで渡す。確かにこれだと拡張しやすそう 😌
String => Intにscore(w) + bouns(w)が突っ込めるという、、関数が値感ある。
{
// 4.20
val score = (word: String) => word.replaceAll("a", "").length
val bouns = (word: String) => if (word.contains("c")) 5 else 0
def rankedWords(
wordScore: String => Int,
words: List[String]
): List[String] = {
words.sortBy(wordScore).reverse
}
// --- 使う処理 ---
val words = List("rust", "java")
val sortedWords = rankedWords(score, words)
assert(
sortedWords == List("rust", "java")
)
val sortedBounusWords = rankedWords(w => score(w) + bouns(w), words)
assert(
sortedBounusWords == List("rust", "java")
)
}
4.23.
これ誤植っぽいなぁ。。正誤表にはなかったけど。
scalaとadaは同率2位。同じランタイム使ってこれが逆に出力されるのは謎い。
{
// 4.22
val score = (word: String) => word.replaceAll("a", "").length
val bouns = (word: String) => if (word.contains("c")) 5 else 0
val penalty = (word: String) => if (word.contains("s")) 7 else 0
def rankedWords(
wordScore: String => Int,
words: List[String]
): List[String] = {
words.sortBy(wordScore).reverse
}
{
// --- 使う処理 ---
val words = List("rust", "java", "sss")
val sortedBounusWords =
rankedWords(w => score(w) + bouns(w) - penalty(w), words)
// (score) 4 2 3
// (bonus) 4 2 3
// (penalty) -3 2 -4
println(sortedBounusWords)
assert(
sortedBounusWords == List("java", "rust", "sss")
)
}
{
// --- 使う処理(2) ---
val words = List("scala", "haskell", "rust", "java", "ada")
val sortedBounusWords =
rankedWords(w => score(w) + bouns(w) - penalty(w), words)
println(sortedBounusWords)
// (score) 3 6 4 2 1
// (bonus) 8 6 4 2 1
// (penalty) 1 -1 -3 2 1
// FIXME: scalaとadaが同率2位なので書籍のassertと異なる
assert(
sortedBounusWords == List(
"java",
"ada",
"scala",
"haskell",
"rust"
)
)
}
}
scalasiteでも同じだな。まぁここは時間があったら深ぼってFB送ろう。。
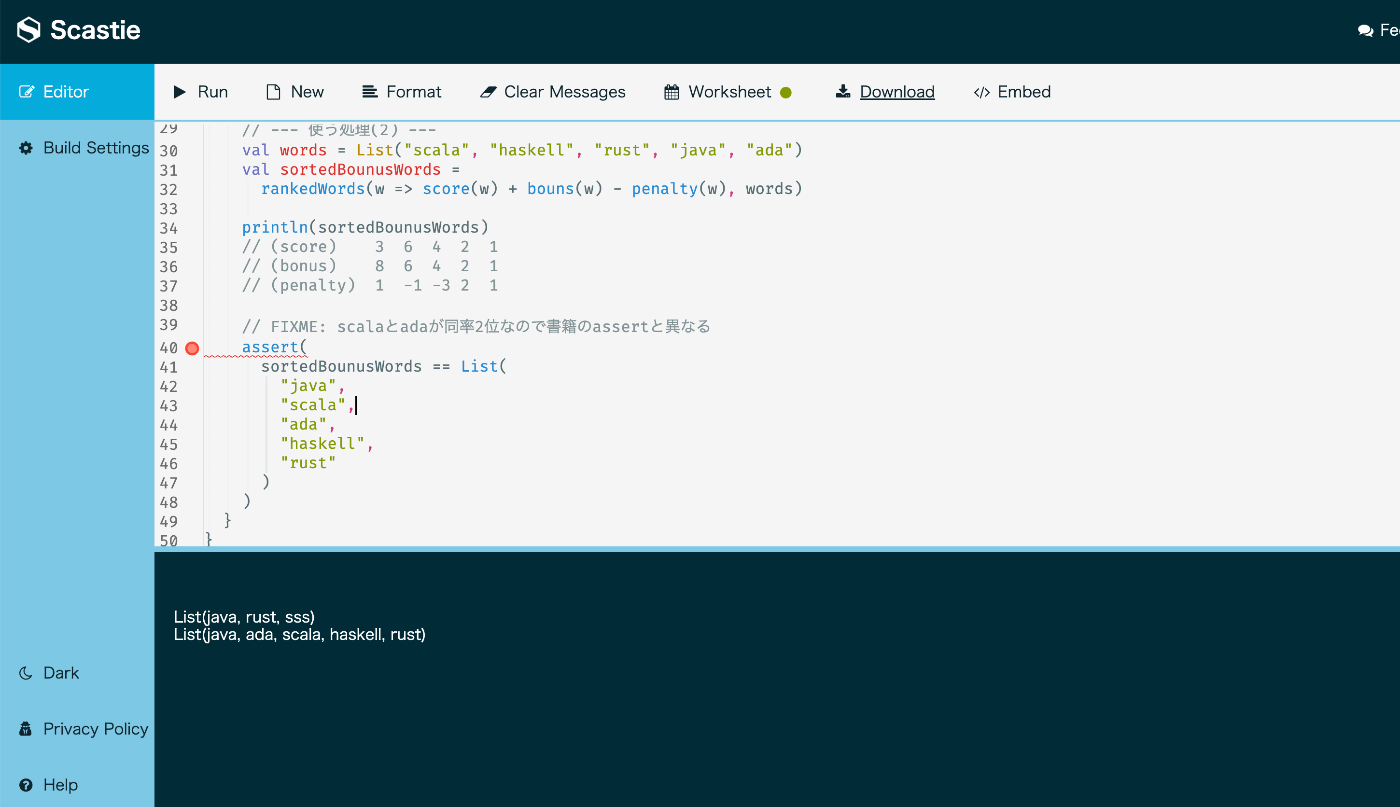
4.39 関数を返すことができる関数を使う
val wordWithScoreHigherThan: Int => List[String] がポイントかな。関数から関数を作ってその関数を汎用的に取り回す。wordWithScoreHigherThan(1)のような形で。
val score = (word: String) => word.replaceAll("a", "").length
val bouns = (word: String) => if (word.contains("c")) 5 else 0
val penalty = (word: String) => if (word.contains("s")) 7 else 0
def highScoringWords(
wordScore: String => Int,
words: List[String]
): (Int) => List[String] = { (higherThan) =>
words.filter(word => wordScore(word) > higherThan)
}
// --- 使う処理 ---
val words = List("scala", "haskell", "rust", "java", "ada")
val wordWithScoreHigherThan: Int => List[String] =
highScoringWords(w => score(w) + bouns(w) - penalty(w), words)
val highWords = wordWithScoreHigherThan(1)
assert(
highWords == List(
"java"
)
)
4.47
わかるけど少し複雑かもなぁ...
{
val score = (word: String) => word.replaceAll("a", "").length
val bouns = (word: String) => if (word.contains("c")) 5 else 0
val penalty = (word: String) => if (word.contains("s")) 7 else 0
def highScoringWords(
wordScore: String => Int
): (Int) => List[String] => List[String] = { (higherThan) => words =>
words.filter(word => wordScore(word) > higherThan)
}
// -- 使う処理(リファクタあと)
val words = List("ada", "haskell", "scala", "java", "rust")
val words2 = List("football", "f1", "hockey", "basketball")
val wordsWithScoreHigherThan: Int => List[String] => List[String] =
highScoringWords(w => score(w) + bouns(w) - penalty(w))
assert(wordsWithScoreHigherThan(1)(words) == List("java"))
assert(wordsWithScoreHigherThan(5)(words) == List())
assert(
wordsWithScoreHigherThan(1)(words2) == List("football", "f1", "hockey")
)
assert(
wordsWithScoreHigherThan(0)(words2) == List(
"football",
"f1",
"hockey",
"basketball"
)
)
// --- 使う処理(リファクタ前) ---
// val words = List("ada", "haskell", "scala", "java", "rust")
// val wordsWithScoreHigherThan: Int => List[String] =
// highScoringWords(w => score(w) + bouns(w) - penalty(w), words)
// assert(wordsWithScoreHigherThan(1) == List("java"))
// assert(wordsWithScoreHigherThan(5) == List())
// val words2 = List("football", "f1", "hockey", "basketball")
// val words2WithScoreHigherThan: Int => List[String] =
// highScoringWords(w => score(w) + bouns(w) - penalty(w), words2)
// assert(words2WithScoreHigherThan(1) == List("football", "f1", "hockey"))
// assert(
// words2WithScoreHigherThan(0) == List(
// "football",
// "f1",
// "hockey",
// "basketball"
// )
// )
// assert(words2WithScoreHigherThan(5) == List("football", "hockey"))
}
4.48. 関数で複数のパラメータリストを使う
パラメータリストのリファクタリング..これは慣れが必要そう...
// def highScoringWords(
// wordScore: String => Int
// ): (Int) => List[String] => List[String] = { (higherThan) => words =>
// words.filter(word => wordScore(word) > higherThan)
// }
// パラメータリストを使って視認性を上げる
def highScoringWords(
wordScore: String => Int
)(higherThan: Int)(
words: List[String]
): List[String] = {
words.filter(word => wordScore(word) > higherThan)
}
4.49 カリー化
// カリー化されていない関数
df f(a: A, b: B, c: C): D
// -- カリー化された関数 --
def f(a: A): B => C => D
// B=> C=> D // この関数は引数を1つ受け取り、さらに別の関数を返す
// C=> D // その関数は引数を1つ受け取り、型Dの値を返す
// --
// -- カリー化された関数(複数のパラメータリスト構文を利用) --
def f(a: A)(b: B)(c: C): D
// (b: B)(c: C):D // この関数は引数を1つ受け取り、さらに別の関数を返す
// (c: C):D // その関数は引数を1つ受け取り、型Dの値を返す
// --
これは同義だな。わかるんだけど、脳に馴染むまで時間がかかりそう🥹
- B を受け取って C=>D を返却
- (b: B)をうけとって(c: C):D を返却
4.49 カリー化
やはりカリー化が複雑見える点としての関数になったときの責務を、脳が理解していないからな気がする
このカリー化のメリットは、wordsWithScoreHigherThanを作って、1のスコアリングアルゴリズムを部分適用した関数を作ったことだよね。共通化の極地だ。
val words = List("ada", "haskell", "scala", "java", "rust")
val words2 = List("football", "f1", "hockey", "basketball")
val wordsWithScoreHigherThan: Int => List[String] => List[String] =
highScoringWords(w => score(w) + bouns(w) - penalty(w))
assert(wordsWithScoreHigherThan(1)(words) == List("java"))
assert(wordsWithScoreHigherThan(5)(words) == List())
assert(
wordsWithScoreHigherThan(1)(words2) == List("football", "f1", "hockey")
)
assert(
wordsWithScoreHigherThan(0)(words2) == List(
"football",
"f1",
"hockey",
"basketball"
)
)
- スコアリングアルゴリズム(wordScore: String => Int)
- 高いスコアの閾値(higherThan: Int)
- 単語リスト(words: List[String])
def highScoringWords(
wordScore: String => Int
)(higherThan: Int)(
words: List[String]
): List[String] = {
words.filter(word => wordScore(word) > higherThan)
}
4.57
直積型の話。Scalaではcase class。Kotlinではdata class
6/1(土) 19:04 パート1全4章終了!お疲れ様でした。まぁまだ1/3くらいなんですけどね。
5.24
最後の課題は少し複雑すぎると感じるかもしれないが、この方法ならではのメリットもある。すべてのコアロジックが小さな関数の中で定義されることだ。それらの関数はより大きなアルゴリズムを構築するためにfor内包表記の中で使われる。
最後のfor内包表記メリット重要だなぁ
// -- 5.24
case class Point(x: Int, y: Int)
val points = List(Point(5, 2), Point(1, 1))
val riskyRadiuses = List(-10, 0, 2)
def isInside(point: Point, radius: Int): Boolean = {
radius * radius >= point.x * point.x + point.y * point.y
}
assert(
(for {
r <- riskyRadiuses.filter(_ > 0)
point <- points.filter(p => isInside(p, r))
} yield s"$point is within a radius of $r") == List(
"Point(1,1) is within a radius of 2"
)
)
assert(
(for {
r <- riskyRadiuses
if r > 0
point <- points.filter(p => isInside(p, r))
} yield s"$point is within a radius of $r") == List(
"Point(1,1) is within a radius of 2"
)
)
def validRadius(radius: Int): List[Int] =
if (radius > 0) List(radius) else List.empty
def insideFilter(point: Point, r: Int): List[Point] =
if (isInside(point, r)) List(point) else List.empty
assert(
(for {
r <- riskyRadiuses
validRadius <- validRadius(r)
point <- points
inPoint <- insideFilter(point, validRadius)
} yield s"$point is within a radius of $r") == List(
"Point(1,1) is within a radius of 2"
)
)
ンギモッヂィイイイイイイイイイイイイイイイ
OptionalはflatMap持っているから、for内包でunwrapしなくていいというね。
しかもfor内包部分のいずれかがNoneを返したら、for内包自体がNoneを返す!!!
case class Event(name: String, start: Int, end: Int)
def validateName(name: String): Option[String] =
if (name.size > 0) Some(name) else None
def validateEnd(end: Int): Option[Int] =
if (end < 3000) Some(end) else None
def validateStart(start: Int, end: Int): Option[Int] =
if (start <= end) Some(start) else None
def parse(name: String, start: Int, end: Int): Option[Event] = {
for {
validName <- validateName(name)
validStart <- validateStart(start, end)
validEnd <- validateEnd(end)
} yield Event(validName, validStart, validEnd)
}
assert(
parse("Apollo Program", 1961, 1972) == Some(
Event("Apollo Program", 1961, 1972)
)
)
assert(
parse("", 1961, 1972) == None
)
5章終了
Scala is 神
6.5
Parseってなんとなく使うけどこの説明いいな
解析はStringなどの生データをドメインモデルに変換する操作であり、パースとも呼ばれる。通常、ドメインモデルは直積型(イミュータブルな値)で表される。ここでは、解析を使って外部からのデータをどのように処理するのかを示す。つまり、あらゆる種類の「問題のあるシナリオ」に対処する必要がある。
6.11
人間工学的に非常にまずい。今関数を使う開発者は、ビジネスロジックに焦点を合わせるのではなく、この関数の2つの振る舞いについて考えなければならない。
TvShow show = parseShow(ivalidRawShow);
if (show != null) {
// showを使って他の処理を行う
}
こんなの関数型ではない。いかなる場合も、戻り値として考えられるものを全て表すのがシグネチャである。ユーザーには常に値が返される。
6.22 Option、for内包表記、検査例外
Optionは便利そうだが、Javaの普通のthrows Excptionよりも本当に良いものだろうか。なぜOptionを優先すべきなのだろうか。
関数型エラー処理と検査例外
6.27.
検査例外と関数型のエラー処理の主な違いは、検査例外の合成がうまく以下ないのに対し、関数型のハンドラの合成が非常にうまくいくことにある。
命令型だと例外を明示的にキャッチする必要がある。
関数と値はうまく合成可能。
AndThenはorElseの真似か
6.40. OptionのListをListのOptionに畳み込む
もはや芸術味を感じてきた
parseShowsをオールオアナッシング戦略に書き換える。List[Option[TvShow]]の中のOption[TvShow]のいずれかでNoneがあったら、Noneを返したい。
List[Option[TvShow]]の時点で、Option[TvShow]は高階関数で取り出せることをヒントに、、
発想として、Option[List[TvShow]]を引数に、Option[TvShow]を加えて、どちらかがNoneだったらNoneを返却する関数を考える。
これはfoldLeftで畳み込むために、floldLeft(初期値)(アキュームレーター, 値)の形でfloldLeft(Option[List[TvShow]])(Option[List[TvShow]], Option[TvShow]) にする。
タイトルの通り、List[Option[TvShow]](リストのオプション)をOption[List[TvShow]](オプションのList)にする
def addOrResgin(
parsedShows: Option[List[TvShow]],
newParsedShow: Option[TvShow]
): Option[List[TvShow]] = {
for {
shows <- parsedShows
show <- newParsedShow
} yield shows.appended(show)
}
def parseShows(rawShows: List[String]): Option[List[TvShow]] = {
val initailValue: Option[List[TvShow]] = Some(List.empty)
rawShows
.map(parseShow) // List[Option[TvShow]]
.foldLeft(initailValue)((total, show) => addOrResgin(total, show)) // Option[List[TvShow]]
}
6.42. 何が失敗したのかはどうすればわかるのか
Eitherの書き換えはうん。ほぼOptionをEitherに変えるだけでできたな。
7.3
とりあえず通るように書いてみたけど、、自分の実装手続き型すぎて引く...
{
case class Artist(
name: String, // 名前
genre: String, // ジャンル
origin: String, // 出身地
yearsActiveStart: Int, // 活動開始年
isActive: Boolean, // 活動中
yearsActiveEnd: Int // 活動停止年(活動中の場合 0)
)
def searchArtists(
artists: List[Artist],
genres: List[String],
locations: List[String],
searchByActiveYears: Boolean,
activeAfter: Int,
activeBefore: Int
): List[Artist] = {
val genFiltered = if (genres.nonEmpty) {
for {
artist <- artists
if genres.contains(artist.genre)
} yield artist
} else {
artists
}
val genOrLocFiltered = if (locations.nonEmpty) {
for {
artist <- genFiltered
if locations.contains(artist.origin)
} yield artist
} else {
genFiltered
}
if (searchByActiveYears) {
val applyed = genOrLocFiltered.filter(artist => {
if (artist.yearsActiveEnd == 0) {
(artist.yearsActiveStart >= activeAfter &&
artist.yearsActiveStart <= activeBefore) ||
(Int.MaxValue >= activeAfter &&
Int.MaxValue <= activeBefore)
} else {
(artist.yearsActiveStart >= activeAfter &&
artist.yearsActiveStart <= activeBefore) ||
(artist.yearsActiveEnd >= activeAfter &&
artist.yearsActiveEnd <= activeBefore)
}
})
applyed
} else {
return genOrLocFiltered
}
}
val artists = List(
Artist("Metallica", "Heavy Metal", "U.S.", 1981, true, 0),
Artist("Led Zeppelin", "Hard Rock", "England", 1968, false, 1980),
Artist("Bee Gees", "Pop", "England", 1958, false, 2003)
)
assert(
searchArtists(
artists,
List("Pop"),
List("England"),
true,
1950,
2022
) == List(
Artist("Bee Gees", "Pop", "England", 1958, false, 2003)
)
)
assert(
searchArtists(
artists,
List.empty,
List("England"),
true,
1950,
2022
) == List(
Artist("Led Zeppelin", "Hard Rock", "England", 1968, false, 1980),
Artist("Bee Gees", "Pop", "England", 1958, false, 2003)
)
)
assert(
searchArtists(
artists,
List.empty,
List.empty,
true,
1981,
2003
) == List(
Artist("Metallica", "Heavy Metal", "U.S.", 1981, true, 0),
Artist("Bee Gees", "Pop", "England", 1958, false, 2003)
)
)
assert(
searchArtists(
artists,
List.empty,
List("U.S."),
false,
0,
0
) == List(
Artist("Metallica", "Heavy Metal", "U.S.", 1981, true, 0)
)
)
assert(
searchArtists(
artists,
List.empty,
List.empty,
false,
2019,
2022
) == List(
Artist("Metallica", "Heavy Metal", "U.S.", 1981, true, 0),
Artist("Led Zeppelin", "Hard Rock", "England", 1968, false, 1980),
Artist("Bee Gees", "Pop", "England", 1958, false, 2003)
)
)
}
ミスの修正...このアルゴリズムでも紙に書かないとわからなくなるの多分プログラミングを忘れている 🥹
条件的には1,2,4を適用でテストは全部通った。
diff --git a/scala-plyaground/src/main/scala/Main.scala b/scala-plyaground/src/main/scala/Main.scala
index cfff17a..2080266 100644
--- a/scala-plyaground/src/main/scala/Main.scala
+++ b/scala-plyaground/src/main/scala/Main.scala
@@ -49,17 +49,16 @@ def ch7() = {
if (searchByActiveYears) {
val applyed = genOrLocFiltered.filter(artist => {
- if (artist.yearsActiveEnd == 0) {
- (artist.yearsActiveStart >= activeAfter &&
- artist.yearsActiveStart <= activeBefore) ||
- (Int.MaxValue >= activeAfter &&
- Int.MaxValue <= activeBefore)
- } else {
- (artist.yearsActiveStart >= activeAfter &&
- artist.yearsActiveStart <= activeBefore) ||
- (artist.yearsActiveEnd >= activeAfter &&
- artist.yearsActiveEnd <= activeBefore)
- }
+ val yearsActiveEnd =
+ if (artist.yearsActiveEnd == 0) Int.MaxValue
+ else artist.yearsActiveEnd
+
+ (activeAfter <= artist.yearsActiveStart &&
+ activeBefore >= artist.yearsActiveStart) ||
+ (activeAfter <= yearsActiveEnd &&
+ activeBefore >= yearsActiveEnd) ||
+ (activeAfter >= artist.yearsActiveStart &&
+ activeBefore <= yearsActiveEnd)
})
applyed
7.6
あー、案の定回答と違うわ、、||(Or)演算子でshort-circuitで作るように 🧠チューニングが必要そう、、
isEmptyはtrueと解釈するあたりコツが入りそう、、
Int.MaxValueをyearActiveEndに代入するの完全に無駄やった、、isActiveで判定すればいい。。isActiveがfalseなら、yearsActiveEndが、activeAfterより未来かを見れば良い。。
以下のケースをANDで見てるっぽいな。対偶とってる感じがして、、
- activeAfterがartist.yearsActiveEndより、過去
- activeAfterから見たら、artist.yearsActiveStartは過去にあっても未来にあっても成立する
- activeBeforeがartist.yearsActiveStartより、未来
artist.yearsActiveStart <= activeBefore
activeAfter <= artist.yearsActiveEnd
def searchArtists(
artists: List[Artist],
genres: List[String],
locations: List[String],
searchByActiveYears: Boolean,
activeAfter: Int,
activeBefore: Int
): List[Artist] = {
artists.filter(artist =>
(genres.isEmpty || genres.contains(artist.genre)) &&
(locations.isEmpty || locations.contains(artist.origin)) &&
(!searchByActiveYears || ((artist.isActive || artist.yearsActiveEnd >= activeAfter) && (artist.yearsActiveStart <= activeBefore)))
)
}
7.16
さまざまな高階関数を覚えることは、関数型プログラマの本業とも言える
7.20
「アーティストが活動していた、またはまだ活動している期間」という1つの概念を表す。このような結論に達したしたら、それはさらに別の直積型を作成する必要があるという兆候だ。
この考え方いいな
7.20
p249のソースコードダブルクォーテーションがない。誤植かな。
7.21 有限の可能性をモデル化する
なんかすごそう
7.20の誤植は、7.21を適用しているな 😆
有限集合の値だけを取ることができる型 -> 直和型(sum type)
enumって有限集合の値だけ取ることができる型という見方をしたことがなかったが、言われてみるとそうだな、、
こういう整理か
- 直和型(enum)
- newtype(opaque type)
- 直積型(case class)
7.25 直積型 + 直和型 = 代数的データ型(ADT)
関数型ドメイン設計に置いて最も影響力が大きく、有益な概念の1つである代数的データ型(algebraic data type: ADT)であると知ったら驚くかもしれない
ほー。この図が大事だなぁ。
プログラミングや型理論に関連する集合論では、型を値の集合として扱うことができる。関数型プログラミングの多くの名前は数学に由来する。
📝
代数的データ型(Algebraic Data Types, ADTs)という名前は、データ型の定義が数学的な計算式に似ていることから来るんだな。
和型->足し算
積型->掛け算
7.30.
F#とHaskellの例がある。かっこいい
7.31
OOPの継承の概念とADTはよく似ているかもしれないが、それらが全く異なるものであることはすぐに明らかになる。
ADTには振る舞いが含まれないが、OOPでは、データ(ミュータブルフィード)と振る舞い(それらのフィールドを変更するメソッド)が1つオブジェクトにまとめられる(中略)
OOP -> データと振る舞いをまとめる
関数型プログラミング -> データと振る舞いは別々のエンティティ
この整理いいな
データはイミュータブルな値(ADT, 生の値など)をモデル化
振る舞いは独立した純粋関数
OOPは、ミュータブルデータと振る舞いを紐づけてドメインと戦う。
FPは、イミュータブルデータをADTでモデル化、振る舞いは純粋関数でドメインと戦う。
7.33
始まりの中括弧がない
7.34.
関数のシグネチャと直積型の定義を見てすぐ説明がつくものではない
これは他の言語でも強く感じていた。関数のパラメーターの意味的な組み合わせがいくつもある。第二引数と第三引数は一緒に使わないとダメとか。
これを伝えるには、言語の機能だけでは難しくて、コメントでフォローしてたな。
7.36.
要件をデータとして扱う。エレガントすぎるな。
以下の要件をふるまいとして直和型で表現する
- アーティストの中からジャンルで検索する
- アーティストの中から出身地で検索する
- アーティストの中から在籍期間で検索する
enum SearchCondition {
case SearchByGenre(genres: List[MusicGenre])
case SearchByOrigin(locations: List[Location])
case SearchByActiveYears(start: Int, end: Int)
}
肝は、引数にリスト型で SearchByGenre(List(Pop)), SearchByOrigin(List(Location("England"))) , SearchByActiveYears(1950, 2022) を指定しているところ。
これを1つずつパターンマッチで評価し、forallは全てtrueで初めてtrueを返すので、3つのCondtionが一致したときのみtrueがfilterに返され、AND条件を作っている。
def searchArtistsKai(
artist: List[Artist],
requiredConditions: List[SearchCondition]
): List[Artist] = {
artists.filter(artist => {
requiredConditions.forall(condition => {
condition match {
case SearchByGenre(genres) => genres.contains(artist.genre)
case SearchByOrigin(locations) =>
locations.contains(artist.origin.name)
case SearchByActiveYears(start, end) =>
wasArtistActive(artist, start, end)
}
})
})
}
searchArtistsKai(
artists,
List(
SearchByGenre(List(Pop)),
SearchByOrigin(List(Location("England"))),
SearchByActiveYears(1950, 2022)
)
)
7.38
previousPeriodsなんやねん!と思ったけど、StillActiveでも休止期間ある場合普通に考えてなかった。。
enum YearsActive {
case StillActive(since: Int, previousPeriods: List[PeriodInYears])
case ActiveInPast(betweens: List[PeriodInYears])
}
8.3
- API呼び出しが同じ引数に対して異なる結果を返すことがある
- API呼び出しが接続(または別の)エラーで失敗することがある
- API呼び出しの完了に時間がかかりすぎることがある
8.4.
lengthHours = 2
8 < (16 - 2 +1 = 15)
(8, 10), (9, 11), (10, 12), (11, 13), (12, 14), (13, 15), (14, 16)
static MeetingTime schedule(String person1, String person2, int lengthHours) {
List<MeetingTime> person1Entries = calendarEntiresApiCall(person1);
List<MeetingTime> person2Entries = calendarEntiresApiCall(person2);
List<MeetingTime> scheduleMeetings = new ArrayList<>();
scheduleMeetings.addAll(person1Entries);
scheduleMeetings.addAll(person2Entries);
List<MeetingTime> slots = new ArrayList<>();
for (int startHour = 8; startHour < 16 - lengthHours + 1; startHour++) {
slots.add(new MeetingTime(startHour, startHour + lengthHours));
}
List<MeetingTime> possibleMeetings = new ArrayList<>();
for (var slot: slots) {
var meetingPossible = true;
for (var meeting: scheduleMeetings) {
if (slot.endHour > meeting.startHour && slot.endHour > slot.startHour) {
meetingPossible = false;
break;
}
}
if (meetingPossible) {
possibleMeetings.add(slot);
}
}
if (!possibleMeetings.isEmpty()) {
createMeetingApiCall(List.of(person1, person2), possibleMeetings.get(0));
return possibleMeetings.get(0);
} else return null;
}
8.7
入力アクション -> IOアクション -> 出力アクション
- calendarEntiresApiCall ... 安全と言えない場所から値を読み取る入力アクション
- createMeetingApiCall ... 安全と言えない場所に値を書き込む出力アクション
schdule関数は、以下の処理になっている。
- 引数で指定された人のカレンダーを取得(calendarEntiresApiCall)
- 空いている予定を見つける
- 予定を作成(createMeetingApiCall)
1の処理の着目すると
私たちとって本当に重要なのは結果であり、アクションそのものではない
ミーティングをスケジュールするためのListを得ることが目的なのに、その過程でネットワークエラーやデシリアライズのエラーが起きてしまう。
8.8
List<MeetingTime> person1Entries = null;
try {
person1Entries = calendarEntiresApiCall(person1);
} catch (Exception e) {
person1Entries = calendarEntiresApiCall(person1);
}
関心事のもつれ
8.9
IO[A]は、副作用を持つ可能性があるIOアクション(または別の安全ではない演算)を表す値であり、成功した場合にA型の値を生成する
8.14
def castTheDitImpure(): Int = {
val rand = new Random()
return rand.nextInt(6) + 1;
}
def castTheDie(): IO[Int] = IO.delay(castTheDitImpure())
val dieCast: IO[Int] = castTheDie()
for {
a <- aOption
b <- bOption
} yield a + b
def castTheDieTwice(): IO[Int] = {
for {
firstCast <- castTheDie()
sencondCast <- castTheDie()
} yield firstCast + sencondCast
}
val value3 = castTheDieTwice()
IO同士の計算をOptionよろしくfor内包で対応。これはまだIOアクションが実行されていないので、例外が発生する可能性がゼロというのが面白いところ。
8.19
8.33
8.36
なるほど。foldreftでorElseを多段で実装できるのか。
def retry[A](action: IO[A], maxRetries: Int): IO[A] = {
List
.range(0, maxRetries)
.map(_ => action)
.foldLeft(action)((program, retryAction) => {
program.orElse(retryAction)
})
}
8.37
特定のメソッドチェーンで使われるような関数が、ライブラリをimportすることで使えるようになるのなんか不思議な感覚がある。
TSとかだとクラス自体インポートしたら、チェーンするメソッドは全て使えるだろうし...
8.37
def scheduledMeetings(
attendees: List[String]
): IO[List[MeetingTime]] = {
attendees
.map(attendee => retry(calenderEntries(attendee), 10)) // List[IO[List[MeetingTime]]]
.sequence // IO[List[List[MeetingTime]]]
.map(_.flatten) // IO[List[MeetingTime]]
}
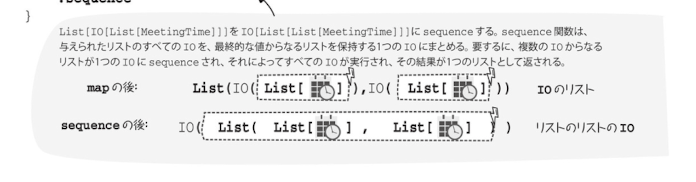
sequenceの挙動はこの図がわかりやすい。IOのリストを、リストのリストのIOにする!
8.38 課題
TODO!! いい課題なので、9章終わったら戻ってくる。
9.12
ratesが連続して前の値より大きい傾向があることを判定するのに、zipを使うのがなかなか目から鱗
- zip(rates.drop(1): (0.1, 0.2, 0.3) zip (0.2, 0.3)
- forall and match : ((0.1, 0.2), (0.2, 0.3)) <-- (1つ目のレート, 2つ目のレート), (2つ目のレート, 3つ目のレート)がループで周りmatchで判定
def trending(rates: List[BigDecimal]): Boolean = {
rates.size > 1 && rates
.zip(rates.drop(1))
.forall(ratePair =>
ratePair match {
case (previousRate, rate) => rate > previousRate
}
)
}
9.15
カリー化と部分適用でmapの引数まわり省略できるのか...
def add(x: Int)(y: Int): Int = x + y
val numbers = List(1, 2, 3, 4)
// 通常の書き方
val add5ToList = numbers.map(n => add(5)(n))
// 簡潔な書き方
val add5ToListSimplified = numbers.map(add(5))
println(add5ToListSimplified) // List(6, 7, 8, 9)
def extractSigleCurrencyRate(currencyToExtract: Currency)(
table: Map[Currency, BigDecimal]
): Option[BigDecimal] = {
table.get(currencyToExtract)
}
def exchangeTable(from: Currency): IO[Map[Currency, BigDecimal]] = {
IO.delay(exchangeRatesTableApiCall(from.name))
.map(table =>
table.map(kv =>
kv match
case (currencyName, rate) => (Currency(currencyName), rate)
)
)
}
val a = exchangeTable(Currency("USD")).map(table =>
extractSigleCurrencyRate(Currency("EUR"))(table)
)
val b = exchangeTable(Currency("USD")).map(
extractSigleCurrencyRate(Currency("EUR"))
)
9.18
for内包表記を使った再帰関数
def exchangeIfTrending(
amount: BigDecimal,
from: Currency,
to: Currency
): IO[Option[BigDecimal]] = {
for {
rates <- lastRates(from, to)
result <-
if (trending(rates)) IO.pure(Some(amount * rates.last))
else exchangeIfTrending(amount, from, to)
} yield result
}
9.19
:message
章題と関係ないが for 内包表記を書くとき、resultから先に書かないとLSPがうまく補完を拾わない
for {
} yield result <-- 先に書く
:::
9.24
9.35
def numbers(): Stream[Pure, Int] = {
Stream(1, 2, 3).append(numbers())
}
val infinite123s = numbers()
assert(infinite123s.take(8).toList == List(1, 2, 3, 1, 2, 3, 1, 2))
Streamで再帰呼び出しが発生するのは、コンシューマが値をリクエストしたときであり、その前には何も起きない。つまり遅延評価される
9.37
evalはIOを受け取り、Streamを返す。このStramはリクエスト応じてこのIOに基づく値を1つだけ生成する
9.40
-
Listの合計をfoldLeftでやろうと思ったけど、普通にmap(_.sum)で事足りるっぽい。そもそも使えなかった
-
3で使えなかったが、StreamだとfoldLeftじゃなくてscanって名前になるっぽい
9.48.
高レベルのAPIを提供することで、以下のことの詳細を隠蔽可能。実装上の詳細をカプセル化することは、特にMapReduceのようなビックデータパラダイムよく使われている
- ページング
- バッファリング
- チャンク化
- バッチ処理
- ワークロードの分散
9.46.
このストリームの利点は、次の値の生成を待機している間、実行中のスレッドをブロックしないことである。IOベースのプラグラムは、実行中はフェアプレイに徹し、必要なとき以外はスレッドプールのスレッドを使わない。
これ最初よくわからなかった。
多分zipで1秒おきのUnit型の値の生成ストリームと、ratesのStream[IO, BigDecimal]のストリームを合成しても、rates側をブロックせず、最小きっかり1秒に1回リクエストできる。例えばリクエストしてから、sleep(1)挟むのと処理をブロッキングしているわけだから、ストリームベースの方が賢そう理解した。
リクエストして1秒待つだと1秒以上はかかるわけだしね。1秒ごとにAPI呼び出しがそれ以上かかったらそれが終わるまで、とした方がリアルタイム性は上がるんだろうな。ただAPIの負荷は大きい気がするけど。
一旦Closeとする 10章以外はまた今度!