Grafana スタックと Amazon CloudWatch のログ監視基盤としての実用性
はじめに
初めまして、木村俊星 です。この度、某S社の SRE を専門とする事業部のインターンに参加しました。インターンでは、Grafana Loki によってログの収集基盤を構築する方法と、Amazon CloudWatch Logs と比較したときの得失について調査しました。本記事では、その調査結果を紹介します。
環境構築と調査結果を1つの記事に書くと長くなりすぎてしまうため、以下の2部構成としました。
-
第1部
- Grafana Loki について
- AWS 検証環境の構築
- 第2部
- 検索性の比較
- アラート機能の比較
- 金銭コストの比較
本記事は第2部の内容です。
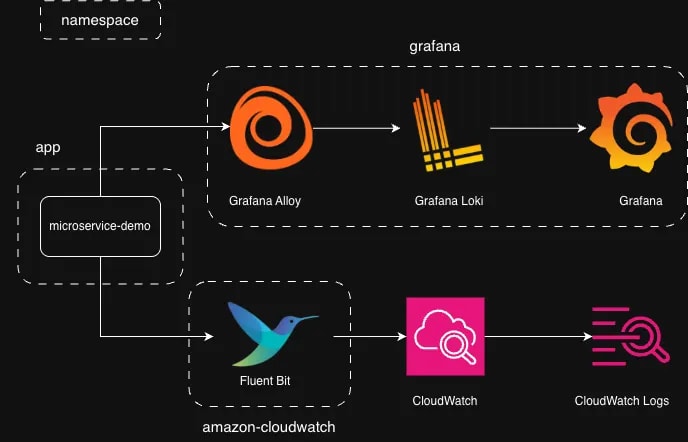
検証環境の再掲
第1部 では以下の環境を EKS クラスター上に構築しました。
まえおき
本来であれば、何を明らかにするためにどういう方法で比較するかを最初に述べるべきですが、私は監視の経験が乏しく、どういう観点で比較すれば実用性を評価できるのか、どういう違いがありそうかを見通せませんでした。そのため、まず実際に使ってみて、その経験から分かった違いや優位性について考察するという流れで進めました。
検索性の比較
本節では主にクエリ言語の機能を比較します。比較するクエリ言語は以下の通りです。
| 技術 | クエリ言語 |
|---|---|
| Grafana スタック | LogQL |
| Amazon CloudWatch | Logs Insights QL |
各クエリ言語の構文は以下のドキュメントを参考にしました。
それぞれのクエリ言語の全ての機能を取り上げて比較することはできないため、機能を以下の3つに分解し、それぞれのカテゴリーにおいて同じ目的を達成するための手段を比較します。
- 絞り込み
- 集計
- 出力
絞り込み機能の比較
本節では以下のシナリオを通してログを絞り込む機能を比較します。
Grafana スタック
先の目的を達成するための LogQL のクエリを以下に示します。
# app の frontend-** という名前の Pod から出力されたログに絞る
{namespace="app", pod=~"frontend-.+"}
# ログを JSON として解釈
# ログのプロパティがラベルとして使用できるようになる
| json
# severity がエラーであるログに絞る
| severity="error"
LogQL のクエリは以下の構成をとります。

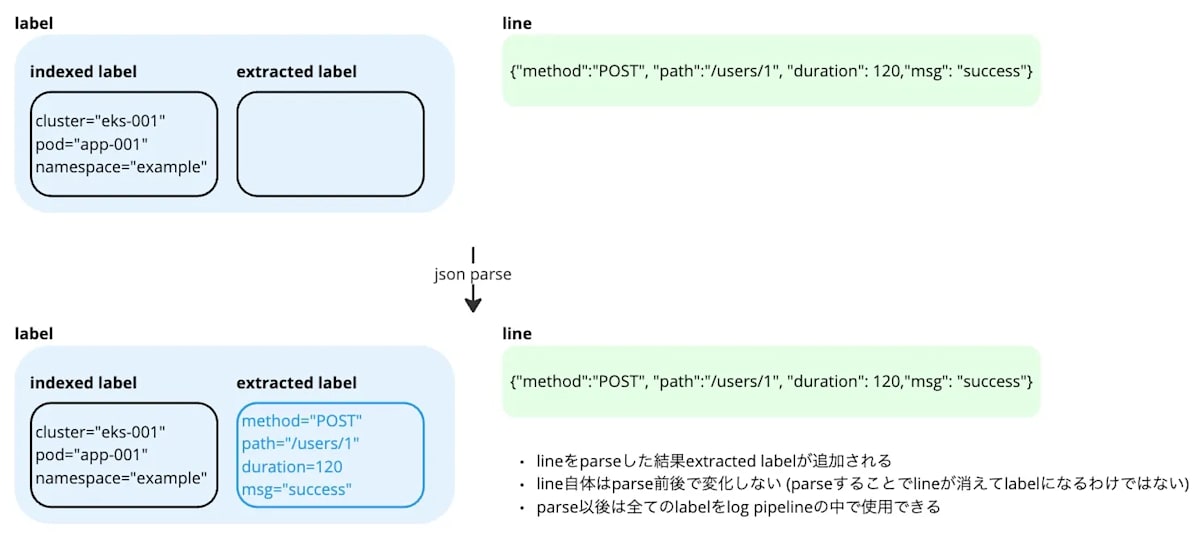
まずストリームを絞るための stream selector があり、ログを絞るための log pipeline が後ろに続きます。stream selector ではログに付与されているラベルでストリームを絞り込みます。今回は「namespace」と「pod」のラベルを使います。json の挙動は GO さんの Grafana LokiのLogQLを理解する が分かりやすいので、こちらをお読みください。今回はログがJSON形式なので、json を挟むことで JSONのプロパティがラベルに追加され、そのラベルでログを絞り込むことができるようになります。
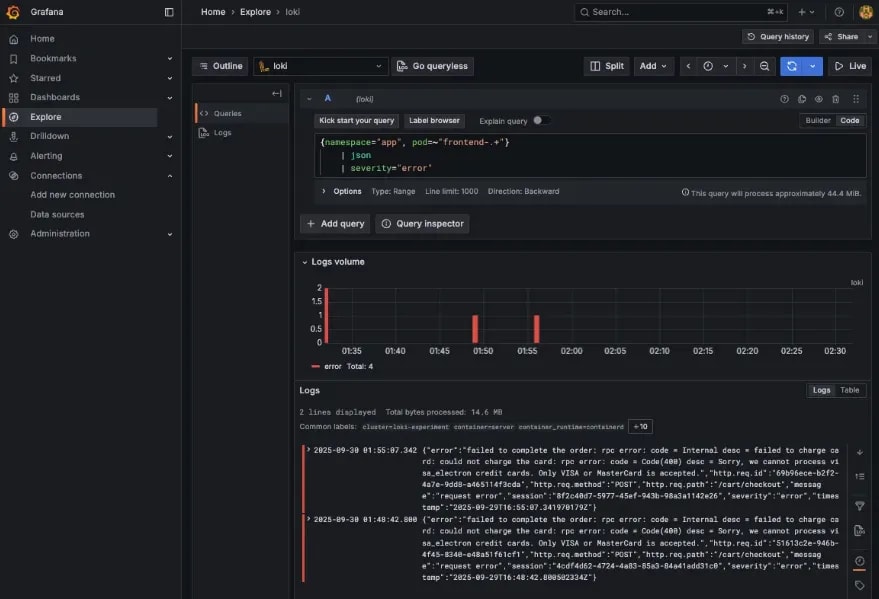
このクエリを Explore で実行した結果を以下に示します。
Amazon CloudWatch
Logs Insights QL のクエリを以下に示します。
filter kubernetes.namespace_name = "app" and kubernetes.pod_name like /frontend-.+/
| fields jsonParse(log) as json_log
| filter json_log.severity = "error"
Logs Insights QL にはコマンドがいくつか用意されており、それらのコマンドを連ねてクエリを組み立てます。クエリの各行でやっていることは LogQL と同じです。Logs Insights QL のログにはラベルと似たような「フィールド」と呼ばれる値が付随しています。上記のクエリでは Pod と namespace のフィールドを使ってログを絞り込んでいます。
このクエリを CloudWatch Logs Insights で実行した結果を以下に示します。
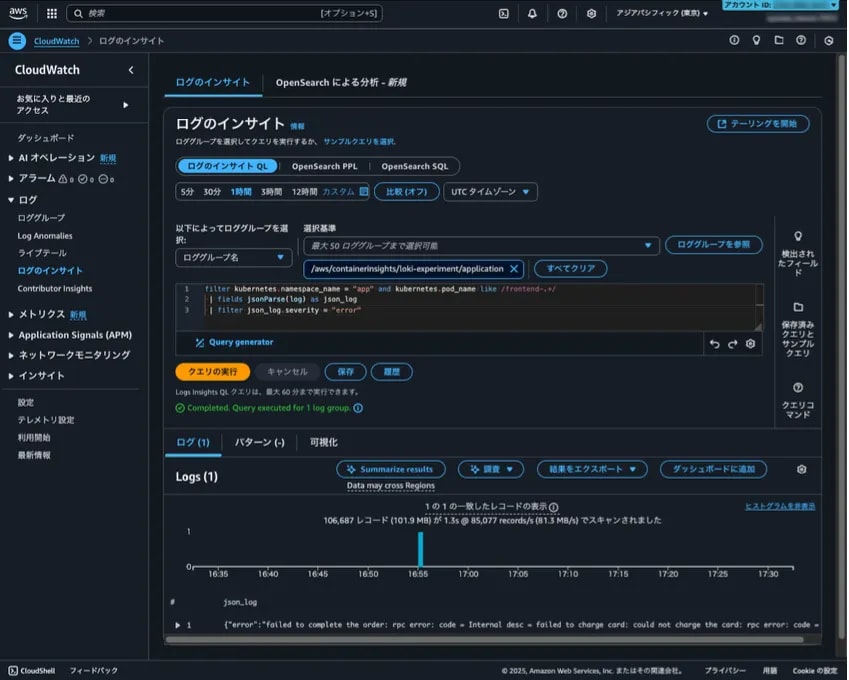
Grafana とヒットしたログの数が異なるのは、デプロイしたタイミングが異なるからです。Grafana スタックのデプロイが完了してから Fluent Bit のデプロイが完了するまでに間に出力されたログは CloudWatch ではヒットしません。
分かったこと
絞り込みの比較を通して分かったことを2つ書きます。
1つ目は PromQL を知らない人にとって LogQL の挙動を理解するのが難しいことです。LogQL は PromQL をベースにして作られており [ 1 ]、私は PromQL を使ったことがなかったため、クエリの挙動を理解するまでに苦労しました。特に後ほど登場する Metric Query はクエリの内容と挙動の対応が掴めず、難しいと感じました。逆に Logs Insights QL は SQL と構文が似ていることもあり、すんなり理解できました。
2つ目は LogQL ではクエリ結果のストリーム数に上限があることです。ストリームとはラベルとその値の一意な組み合わせのことです。デフォルトでは上限が500になっており、501以上のストリームを出力しようとすると、maximum of series (500) reached for a single query というエラーになります。このエラーを避けるために、検証環境では Loki の values.tftpl で上限を1000に引き上げています。
loki:
limits_config:
allow_structured_metadata: true
volume_enabled: true
retention_period: 24h
max_query_series: 1000 # ストリーム数の上限
この制約は、Loki に過大な負荷をかけないための機能ですが、障害が発生した時などの緊急時には足枷になります。一方で、CloudWatch は AWS が管理してくれるため、負荷の大きさを気にする必要はありません。
集計機能の比較
本節では以下のシナリオを通してログからメトリクスを計算する機能とそれを可視化する機能を比較します。
Grafana スタック
LogQL のクエリを以下に示します。
quantile_over_time (
0.95,
{namespace="app", pod=~"frontend-.+"}
| json
| http_req_path="/cart/checkout" and http_req_method="POST"
# レスポンスタイムのみを取り出す
| unwrap http_resp_took_ms
[10m]
) by (pod)
max_over_time (
{namespace="app", pod=~"frontend-.+"}
| json
| http_req_path="/cart/checkout" and http_req_method="POST"
| unwrap http_resp_took_ms
[10m]
) by (pod)
LogQL で複数のメトリクスを1つのクエリで計算する方法は見つからなかったので、複数のクエリを定義しました。Explore で「Add query」を選択すればクエリを追加することができます。
これらのクエリを Explore で実行した結果を以下に示します。
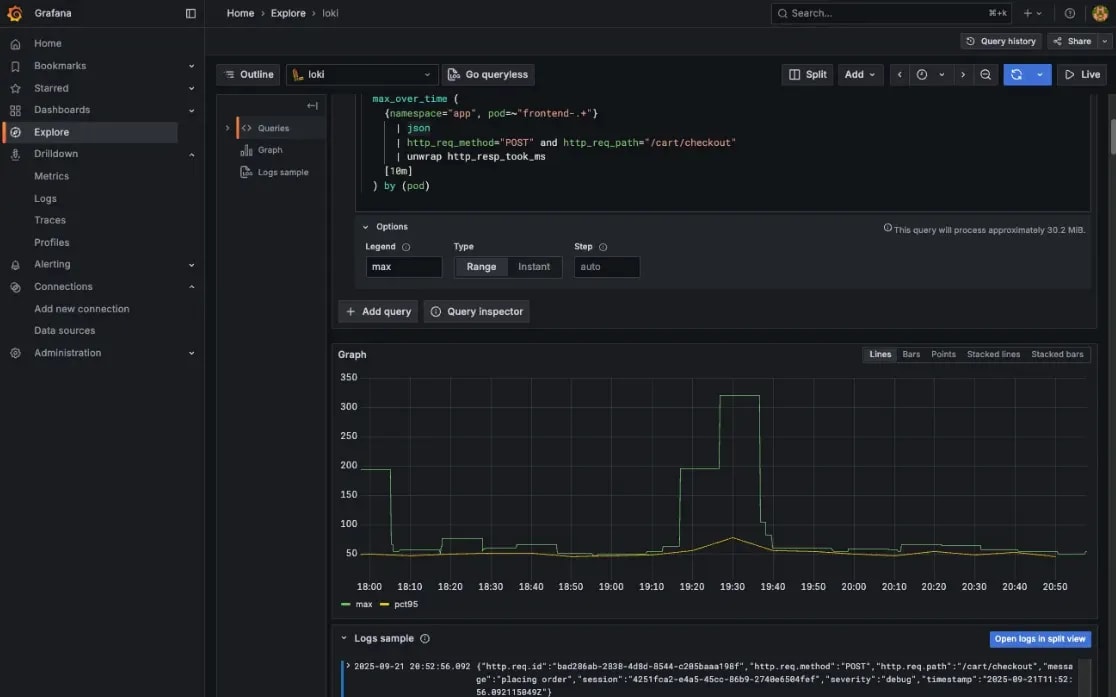
Amazon CloudWatch
Logs Insights QL のクエリを以下に示します。
filter kubernetes.namespace_name = "app" and kubernetes.pod_name like /frontend-.+/
| fields jsonParse(log) as json_log
| filter json_log.`http.req.path` = "/cart/checkout" and json_log.`http.req.method` = "POST"
| stats
pct(json_log.`http.resp.took_ms`, 95) as pct95_took_ms
max(json_log.`http.resp.took_ms`) as max_took_ms
by bin(10m), kubernetes.pod_name
Logs Insights QL では stats コマンドで一度に複数のメトリクスを計算することができます。
stats コマンドの結果を可視化する時は by で指定するフィールドの順序に注意が必要です。どうやら by で指定した最初のフィールドがグラフの横軸になるようです。最初はグラフの横軸が時刻にならず、色々試した結果 by の順序を変更すると解決しました。
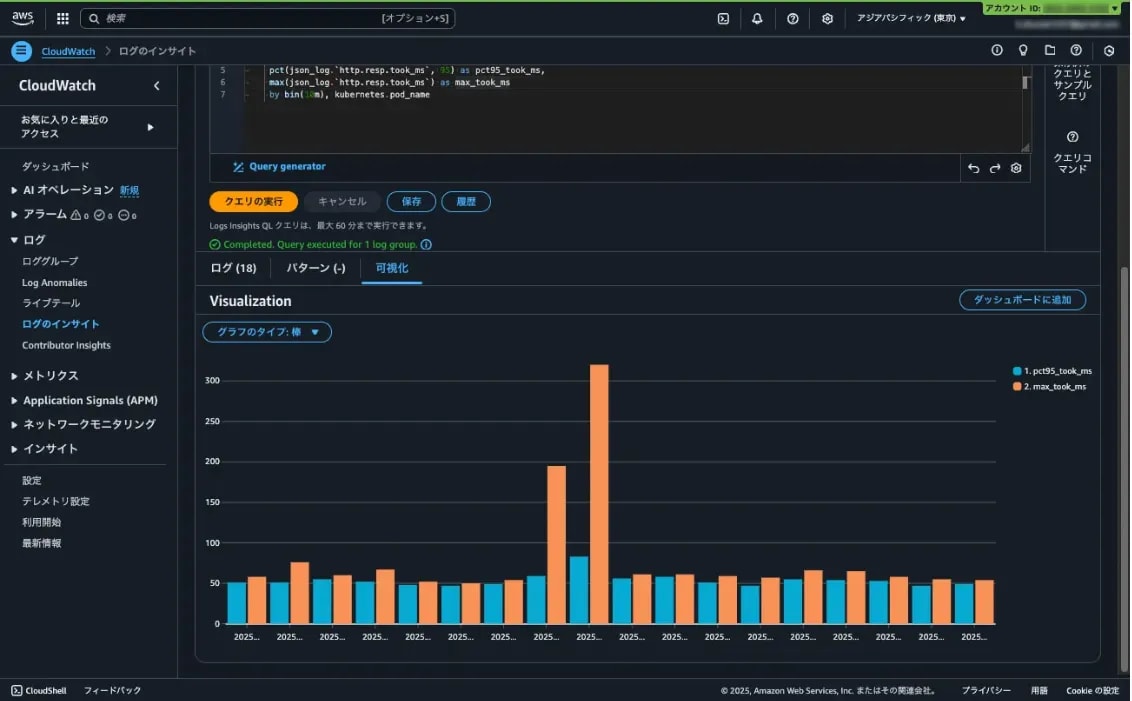
Logs Insights では折れ線グラフで表示できなかったので棒グラフにしました。ドキュメント には折れ線グラフを出せる条件として
- 1つ以上の 集計関数 が含まれている
-
bin()関数を使用して1つのフィールドでデータをグループ化する
と書かれています。bin() 関数で @timestamp をグループ化しているので、@timestamp と kubernetes.pod_name の2つの軸で集計したことが折れ線にできなかった原因だと考えています。
分かったこと
集計機能の比較を通して、両ツールでは重点が置かれている機能が異なることが分かりました。
Grafana の Exploreは、クエリの結果を対話的に操作する機能が充実しています。具体的には以下のような機能を備えています。
- ペインを左右分割表示
- クエリの定期実行
- Live Tail
- 横軸(時刻)の間隔を調節
- 範囲選択でグラフ拡大
このようなグラフを対話的に操作できる UI は、障害の原因調査やパフォーマンスチューニングなど、ログを探索的に分析したい場合に特に役立つと思います。
一方で CloudWatch Logs Insights は、クエリの記述を補助する機能が充実しています。画面右側のサンプルクエリやコマンドリファレンスに加え、自然言語でクエリを生成する機能も備えています。典型的な集計やフィルタリングであれば、ドキュメントを調べる手間を省いてより手軽に分析を始めることができます。
出力機能の比較
本節では以下のシナリオを通してログをソートする機能と出力を制御する機能を比較します。
Grafana スタック
結論から言うと LogQL で上記の目的を達成することはできませんでした。
LogQL には line_format と label_format というコマンドでログとラベルをフォーマットすることができます。しかし、LogQL ではメトリクスを計算する過程でログ本体の情報は失われてしまうため、メトリクスを計算した後に元のログをフォーマットできません。
line_format と label_format を使用せず同じ目的を達成するには、出力に含めたいラベルでメトリクスを集計します。具体的なクエリを以下に示します。
topk(
10,
max_over_time(
{namespace="app", pod=~"frontend-.+"}
| json
# レスポンスタイムがあるログに絞る
| http_resp_took_ms > 0
# レスポンスタイムのみを取り出す
| unwrap http_resp_took_ms
[1h]
) by (
# これらのラベルで集計する
http_req_path,
http_req_method,
http_resp_status
)
)
フロントエンドの Pod からのログに絞っている理由は、クライアントからのリクエストの情報をログに含めているのがこの Pod のみだったからです。ログメッセージはとりうる値が多いと予想され、実務でもメッセージで集計したいことは少ないだろうと考えたので、集計の軸から外しました。
このクエリを Explore で実行した結果を以下に示します。直近1時間の値のみを知りたいので、「Options」でクエリのタイプを「Instant」に変更しています。

Amazon CloudWatch
Logs Insights QL には出力をフォーマットする機能がないので、先の形式でログを出力することはできません。代わりに出力に含めたいフィールドのみを display コマンドで出力しました。
filter kubernetes.namespace_name = "app" and kubernetes.pod_name like /frontend-.+/
| fields jsonParse(log) as json_log
# レスポンスタイムでソート
| sort json_log.`http.resp.took_ms` desc
# 上位10件のみを出力
| limit 10
| display
json_log.`http.req.method`,
json_log.`http.req.path`,
json_log.`http.resp.status`,
json_log.`http.resp.took_ms`,
message
このクエリを CloudWatch Logs Insights で実行した結果を以下に示します。
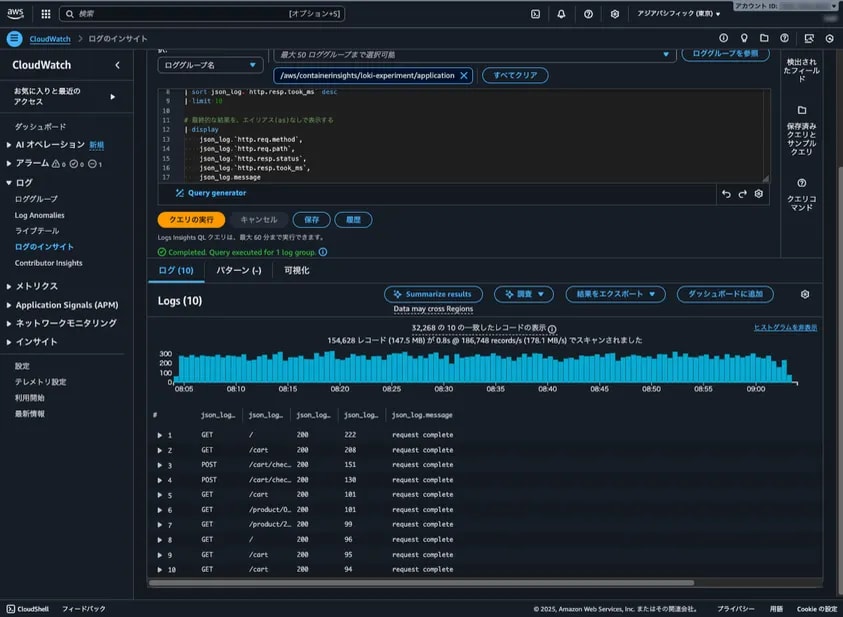
分かったこと
出力の比較を通して、LogQL と Logs Insights QL ではログをソートする機能に違いがあることが分かりました。
LogQL にはログをラベルの値でソートする機能はありません。sort と sort_desc という演算子が用意されていますが、これは Metric Query の結果をソートするための機能です。そのため、上記のクエリでは max_over_time と topk を使って間接的にソートを実現しています。Logs Insights QL にはフィールドの値でログをソートするための sort コマンドが用意されており、このコマンドを使うだけで済みました。
LogQL でログに含まれている値が大きい or 小さいログを上位N件だけ表示するといったクエリは 書きづらいです。しかし、今は生成AIに聞けば概ね正しいクエリを出力してくれるので、そこまで困ることもないだろうと思います。
アラート機能の比較
本節では Grafanaスタックと Amazon CloudWatch のアラート機能を以下の観点から比較します。
- アラート条件の柔軟性
- 通知ロジックの柔軟性
これらの違いを明らかにするために、以下の条件が成立した時にアラートを発生させます。
Grafana スタックのアラート機能
先の目的を達成するだけであれば、Alert Rule と Contact Point を設定するだけで済みますが、今回はあえて Notification Policy を間に挟むことで、アラートを柔軟に設定できることを確認します。基本的な手順は Multi-dimensional alerts and how to route them をご参照ください。以下ではこの記事と設定内容が異なる部分のみを説明します。
Notification Policy の作成
Notification Policy はアラートの条件が成立した時に生成される Alert Instance をどの Contact Point にルーティングするかを決める設定です。Notification Policy で通知ロジックを一元管理しておけば、Alert Rule が増えても通知ロジックを簡単に変更することができます。
ドキュメント では device というラベルでルーティングしていますが、今回は pod というラベルの値が frontend の Alert Instance を Contact Point へとルーティングします。この設定を済ませたダイアログの画面を以下に示します。
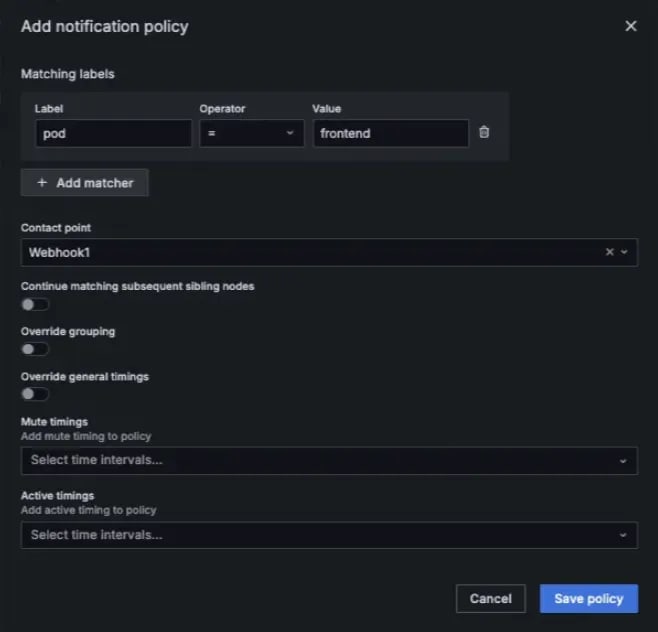
Alert Rule の作成
ドキュメントと設定内容が異なる部分が2つあります。
1つ目はクエリの内容です。ドキュメント では「Define query and alert condition」でメトリクスを計算するクエリとアラートの条件を定義します。Data Source に Loki が選択されていない場合は選択し直しましょう。今回使用するクエリを以下に示します。
sum(
count_over_time(
{namespace="app", pod=~"frontend-.+"}
| json
| severity="info"
[1m]
)
)
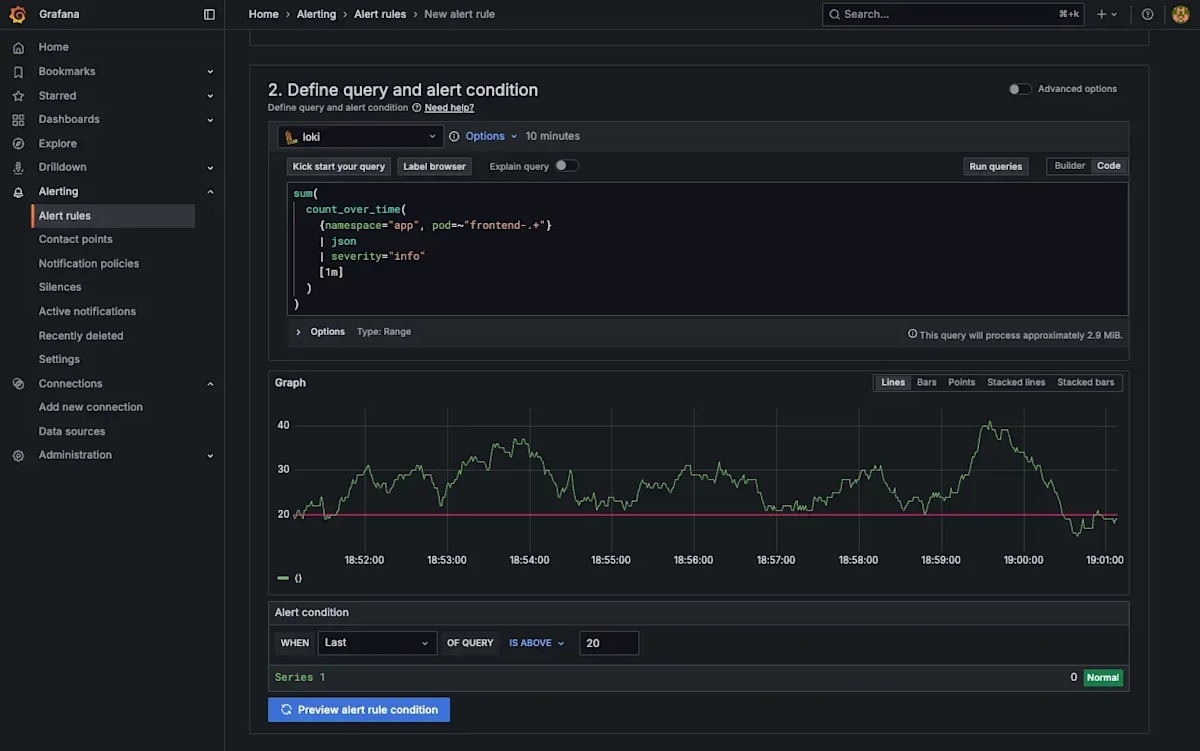
21回以上発生した場合にアラートを発生させるため閾値は20とします。この設定で「Preview alert rule condition」を選択した画面を以下に示します。
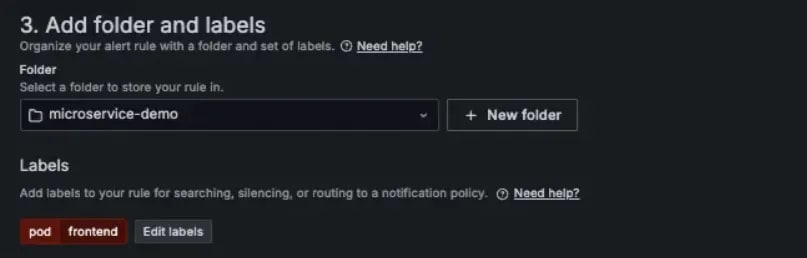
2つ目はルーティングに使用するラベルです。ドキュメント では「Add folder and labels」で Alert Instance を保存するフォルダーと Alert Instance に付与するラベルを設定します。今回は Notification Policy の設定に合わせて pod というラベルに frontend という値を持たせます。
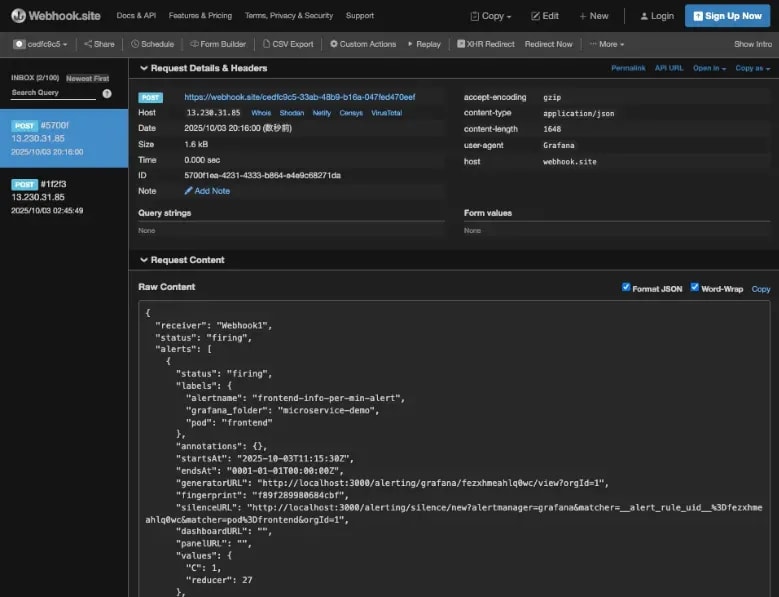
Alert Rule を作成できたらWebhook.site に戻ってアラート通知が来るのを待機します。実際にアラート通知が来た様子を以下に示します。
Amazon CloudWatch のアラート機能
アラートの条件と通知先を別で定義するところは Grafana と同じです。しかし、アラートの条件を設定する方法が Grafanaとは根本的に異なります。
Amazon CloudWatch ではまず「メトリクスフィルター」を作成します。これは、特定のパターンを含んだログを検出する機能です。このメトリクスフィルターによって検出されたログの数に基づいてアラートの条件を定義します。
基本的な手順はカチシステムプロダクツさんの CloudWatch のメトリクスフィルタとアラームを設定する をご参照ください。以下ではこの記事と設定内容が異なる部分のみを説明します。
メトリクスフィルターの作成
CloudWatch ではカウント対象のログのパターンを「フィルターパターン」と呼ばれる Logs Insights QL とは全く別の構文で記述します。Grafana のようにクエリ用の言語を流用できないため、追加の学習コストがかかります。今回使用するフィルターパターンを以下に示します。
{
($.kubernetes.namespace_name = "app")
&& ($.kubernetes.pod_name = "frontend-*")
&& ($.log_processed.severity = "info")
}
上記のパターンを「3-3. メトリクスフィルタを設定」のところで入力します。
CloudWatch アラームの作成
アラームの設定方法は同じくカチシステムズさんの CloudWatch Alarm の設定のやり方 の「4-3. CloudWatchアラームを設定する」をご参照ください。
CloudWatch アラームを作成できたら、SNS トピックのサブスクリプションで設定したメールアドレス宛に AWS からメールが送られてくるのを待機します。実際に届いたメールを以下に示します。

複合アラームについて
Amazon CloudWatch でも Grafana の Notification Policy のようにルーティングを柔軟に設定することができないのか調べたところ、複合アラームという機能を使えば同じことができそうでした。
複合アラームは、複数のアラームの状態を論理演算で組み合わせて新しいアラームの条件を定義する機能です。個別のアラームをアクションなしで作成し、それらのアラームを OR で連結した条件で複合アラームを作成すれば、複数のアラームの通知先をまとめて定義できます。
ただし、以下の制限があります。
- CloudWatch にはラベルという概念がないので、Notification Policy のようにラベルによるルーティングはできず、複合するアラームを明示的に指定する必要がある
- 複合アラームが発生した時に、具体的にどのアラームが発報したのかまで通知できるかは不明
詳しくは Combining alarms をご参照ください。
Embedded Metrics について
Amazon CloudWatch のメトリクスフィルターはパターンマッチングによってログを検知する機能であり、ログから値を抽出することはできません。CloudWatch でログに含まれる値をメトリクス化することはできないのか調べたところ、Embedded Metrics という機能が見つかりました。
CloudWatch には Embedded Metrics Format(以下、EMF と略す)と呼ばれる形式でログを出力すれば、CloudWatch 側で自動的にメトリクスを生成してくれる機能があります。EMF の具体例を以下に示します [ 2 ]。
{
"_aws": {
"Timestamp": 1574109732004,
"CloudWatchMetrics": [
{
"Namespace": "lambda-function-metrics",
"Dimensions": [["functionVersion"]],
"Metrics": [
{
"Name": "time",
"Unit": "Milliseconds",
"StorageResolution": 60
}
]
}
]
},
"functionVersion": "$LATEST",
"time": 100,
"requestId": "989ffbf8-9ace-4817-a57c-e4dd734019ee"
}
この機能を使えば、CloudWatch 側でログをパースする必要なく、アラート条件に使いたい値をメトリクス化できます。分類上はログということになっていますが、メトリクスをプッシュ型で収集する方法に近いと思います。
まとめ
Grafana スタックと CloudWatch の機能の対応を以下に整理します。
| 機能 | Grafana スタック | Amazon CloudWatch |
|---|---|---|
| 通知先の管理 | Contact Point | Amazon SNS |
| アラート条件の定義方法 | LogQL | Amazon CloudWatch メトリクス |
| アラート条件の最小評価間隔 | 10秒 | 10秒 |
| ルーティング機能 | Notification Policy | 複合アラームで擬似的に実現可能 |
最も大きな違いがあったのはアラート条件の定義方法です。Grafana では LogQL で計算したメトリクスでアラートの条件を定義しました。Amazon CloudWatch ではフィルターパターンと呼ばれる Logs Insights QL とは別の構文でメトリクスフィルターを定義し、メトリクスフィルターから生成されたメトリクスを用いてアラートの条件を定義しました。この定義方法の違いにアラート条件の柔軟性と運用負荷のトレードオフが現れています。
Grafana スタックはアラート条件の柔軟性が強みです。LogQL の豊富な機能を利用して様々なメトリクスを定義することができます。柔軟性が高い反面、重いクエリで可用性を損なうリスクがあります。極端な例を考えると、1年間のログをスキャンするクエリを10秒間隔で実行すれば、Loki に高い負荷がかかります。Querier などのクエリを処理するコンポーネントの数が不十分であれば、他のアラートや分析業務に支障を来すことになります。つまり、Grafana スタックではアラート条件の柔軟性と引き換えに、可用性を維持する責任が伴います。
Amazon CloudWatch は監視基盤を運用することなく高い可用性を得られるのが強みです。その代わり、ログベースのアラートを設定するときに、メトリクスフィルターでは表現できない条件を定義するには工夫が必要です。例えば、ログに含まれる値を使用したい場合は、前述の Embedded Metrics や Prometheus を併用し、最初からログではなくメトリクスとして収集するという方法があります。
以上の議論より、Grafana スタックは以下のケースに適し、
- CloudWatch のメトリクスフィルターでは物足りない
- Grafana スタックを運用できる体制がある
- もしくは体制を整えられる余裕がある
Amazon CloudWatch は以下のケースに適すると言えます。
- CloudWatch のメトリクスフィルターで事足りる
- 監視基盤の運用は AWS にお任せしたい
金銭コストの比較
本節では Grafana スタックと Amazon CloudWatch それぞれで24時間ログを保存し続けたときの金銭コストを比較します。
比較方法
最初は使用するサービスの料金体系を調べて、具体的なシナリオを想定した時の料金を算出するつもりでした。しかし、前提条件が揃っていない状態でシナリオを設計するのが難しく、理論値よりも実際に計測してみた結果の方が価値があるだろうと考えたので、実際にデモ用のアプリを動かして金額を測定するというアプローチをとりました。
比較方法は以下の通りです。
EKS クラスターの設定には 検証環境と同じ YAML を使用します。Grafana スタックと Amazon CloudWatch それぞれの設定を以下に示します。
| 設定項目 | Grafana スタック | Amazon CloudWatch |
|---|---|---|
| ノード数 | 3 | 2 |
| EC2 インスタンスタイプ | t3.large | t3.large |
| EC2 AMI | AmazonLinux2023 | AmazonLinux2023 |
| EBS ボリュームタイプ | gp3 | gp3 |
| EBS ボリュームサイズ | 80 GB | 80 GB |
前回の記事 で説明したように、Loki にはデプロイのモードが3つあります。モードに応じて必要となる最小ノード数が異なるため、本来であれば全てのモードについて計測すべきですが、時間と資金の都合上、Simple Scalable に絞らせていただきました。Simple Scalable を採用した理由は Monolothic mode の手軽さと Microservices mode の拡張性を併せ持つため、最も多くのケースにおいて参考になると考えたからです。
ノード数はそれぞれのリソースをデプロイするために最低限必要な数にしました。Simple Scalable で必要なノード数については、Deploy the Loki Helm chart on AWS に最低でも3つ必要だと記載されており、実際にノード数を2にするとノード数不足のエラーが出て Pod を起動できませんでした。Amazon CloudWatch の方は、ノード数が1の時は CPU 不足のエラーになり、ノード数が2のときに初めて全ての Pod を起動することができました。
それぞれの場合でデプロイする Terraform モジュールを以下に示します。
| Terraform モジュール | Grafana スタック | Amazon CloudWatch |
|---|---|---|
| app | o | o |
| aws | o | o |
| grafana | o | |
| fluent-bit | o |
比較結果
金銭コストの計測結果を以下に示します。
| AWSサービス | Grafana スタック [$] | Amazon CloudWatch [$] | 差額 [$] |
|---|---|---|---|
| EC2 | 10.47 | 7.23 | 3.24 |
| EKS | 2.46 | 2.39 | 0.07 |
| ELB | 1.94 | 0.64 *1 | 1.3 |
| CloudWatch | 2.19 | -2.19 | |
| VPC | 1.56 | 0.6 | 0.96 |
| Data Transfer | 0.79 | 0.06 | 0.73 |
| S3(スタンダード) | 0.04 | 0.04 | |
| 課税前 | 17.26 | 13.11 | 4.15 |
| 税額 | 1.726 | 1.311 | |
| 総額 | 18.99 | 14.42 | 4.57 |
*1 デモ用アプリによる課金です
Amazon CloudWatch よりも Grafana スタックの方が高額となりました。EC2 のノード数が Grafana スタックの方が1つ多いことが最大の要因です。全体的に見ても EC2 の料金が支配的なので、金銭コストを抑えるには EC2 のパラメーターを最適化するのが効果的だと言えます。
注目すべきは CloudWatch と S3 の料金の差です。同じ量のログを保存しているにも関わらず、CloudWatch の方が約50倍の値段がかかっています。Amazon CloudWatch は様々な機能をフルマネージドで提供しており、その運用負荷を低減する価値が料金に含まれています。一方、Loki のように S3 をバックエンドとする構成は、ストレージコストを大幅に抑えられる代わりに、Loki 自体の運用コストが発生します。どちらを選択するかは、ログの量や保持期間だけでなく、運用にかけられる人的コストも考慮して判断することが重要です。
損益分岐点の考察
今回の比較では計測中に一切クエリを実行していないので、クエリの実行にかかるコストが含まれていません。このコストを考慮することで損益分岐点を算出できないか考えてみます。クエリの実行に伴って発生する東京リージョンの金銭コストを以下に整理します。
| 課金対象 | 課金単位 | 課金額 | Grafana スタック | Amazon CloudWatch |
|---|---|---|---|---|
| クロス AZ 通信 | 1GB | $0.01 | o? | |
| S3 からのログ取得 | 1000リクエスト | $0.0047 | o | |
| ログのスキャン量 | 1GB | $0.0076 | o |
クロス AZ 通信は Grafana と Loki を異なる AZ に配置した場合に課金されます。
計算を簡単化するために以下を仮定します。
- 単一の AZ で Grafana スタックを稼働させる
- 1回のクエリで S3 に対して1回リクエストが発生する
- 1回のクエリで
V
1日あたりのクエリの実行回数を
CloudWatch の金銭コストは
| V [GB] | x [回] |
|---|---|
| 1 | 542 |
| 0.1 | 5,446 |
| 0.01 | 57,695 |
| 0.001 | 1,418,495 |
検証中に1回のクエリでスキャンされるログの量が100MBを超えることはあまりなかったので、多めに見積もって毎回のクエリで0.1GBのログがスキャンされると仮定しても、1日に5446回クエリを実行するまでは CloudWatch の方が安いです。1日に5000回もクエリを実行するケースは少ないと思うので、ほとんどのケースにおいて CloudWatch の方が安く済むでしょう。
まとめ
これまでの比較を通して特に違いがあった要素を以下にまとめます。
| 利用技術 | Grafana スタック | Amazon CloudWatch |
|---|---|---|
| 管理すべきリソースの数 | 多い *1 | 少ない |
| クエリ言語 | LogQL | Logs Insights QL |
| ↑と似ている言語 | PromQL | SQL |
| グラフの対話的操作 | できる | できない |
| アラート条件の柔軟性 | LogQL で柔軟に定義できる | パターンにマッチしたログの数に基づいて定義する |
| 最低限必要なノード数 | 3 | 2 |
| ログ保存料金 | 安い *2 | 高い |
- *1 AWS Managed Grafana を使えば抑えられるかも
- *2 S3 をオブジェクトストレージとして使う前提
この表から、Grafana スタックは充実した機能とログの保存料金に強みがあり、Amazon CloudWatch は学習コストと運用負荷に強みがあることが分かります。以上の考察を踏まえて、それぞれの技術が適する場合を以下に箇条書きでまとめます。
Grafanaスタックが適しているケース
- すでに Grafana スタック や Prometheus の運用経験がある場合
- GUI で探索的にログを分析をしたい場合
- ログベースで複雑なアラートを定義したい場合
- 大量のログを長期間保存する必要がある場合
Amazon CloudWatch が適しているケース
- とにかく素早くログの監視基盤を構築したい場合
- 運用負荷を最小限に抑えたい場合
- 基本的なログ検索と監視で十分な場合
- ログ監視基盤と他の AWS サービスを連携させたい場合
読者にとって本記事が自身の状況に適したログ基盤を選択する一助となれば幸いです。
謝辞
この記事は某S社のインターンで調査した内容をまとめたものです。個人ではなかなか手を出せない技術に触れる機会を与えてくださり、ありがとうございました。また、調査の過程でアドバイスをくださった方々、記事を丁寧にレビューしてくださった方々に心から感謝いたします。
Discussion