はじめに
「数百件のデータを一括で登録したいんだけど、どの方法が一番良いんだろう?」
Rails開発で大量データの一括登録機能を実装する際、こんな疑問を持ちどれを選定するべきか頭を悩ませる出来事がありました。TODOアプリで既存のタスクを新しいプロジェクトに一括移行する機能を実装する際に、パフォーマンスと保守性どちらもバランスよく実装したいなと思い3つの選択肢について少し深ぼったので共有します。
insert_all!、activerecord-importのimport!、そしてeach_sliceを使った分割処理。それぞれにメリット・デメリットがあり、どれを選ぶべきか悩みました。
この記事では、実際の実装経験を通じて学んだ3つの手法の特徴と使い分けの基準を、具体的なコード例とともに解説します。同じような技術選択で悩んでいる方の参考になれば幸いです。
開発環境
- Ruby 3.3.4
- Rails 6.1.7.10
- gem activerecord-import 2.1.0
- MySQl 8.0
背景:大量データ一括登録の必要性
実装したかった機能
既存のタスクを新しいプロジェクトに一括で移行する機能を実装していました。
# 実装したかった処理の概要
def bulk_migrate_tasks(task_ids:, target_project_id:)
# 1. タスクIDのバリデーション
# 2. 重複チェック(既に移行済みのタスクを除外)
# 3. 一括でProjectTaskレコードを作成
# 4. 作成したレコードを返却
end
想定される要件
- 大量データ対応: 一度に数百〜数千件のタスクを処理する可能性
- パフォーマンス重視: ユーザー体験を損なわない処理速度
- データ整合性: バリデーションエラーの適切な処理
- 保守性: 将来的な機能拡張に対応できる実装
この要件を満たすために、3つの手法を検討しました。
3つの手法の特徴比較
Railsで一括登録を実装する方法は、生SQL(例: ActiveRecord::Base.connection.execute)を使えば究極のパフォーマンスを追求することも可能ですが、今回は保守性や可読性も考慮し、ActiveRecordの機能を活用した代表的な3つの手法に絞って比較します。
1. Rails 6+ の insert_all!
Rails 6で追加された公式の一括挿入メソッド
def bulk_migrate_with_insert_all(task_ids, target_project_id)
current_time = Time.current
records = task_ids.map do |task_id|
{
task_id: task_id,
project_id: target_project_id,
priority: calculate_priority,
created_at: current_time,
updated_at: current_time
}
end
ProjectTask.insert_all!(records)
end
insert_all!のメリット
- ✅ 最速: 単一のSQLで完結するため、非常に高速。
- ✅ 公式機能: Railsに標準搭載されており、gemを追加する必要がない。
- ✅ シンプル: ハッシュの配列を渡すだけで直感的に使える。
insert_all!のデメリット
- ❌ バリデーションが効かない: ActiveRecordのバリデーションは一切実行されない。
- ❌ コールバックが動かない: before_createやafter_createなどのコールバックはトリガーされない。
- ❌ エラー特定が困難: DBレベルのエラーが発生した場合、どのレコードが原因か特定しづらい。
2. activerecord-import の import!
大量データの一括登録に特化した老舗gem
def bulk_migrate_with_import(task_ids, target_project_id)
project_tasks = task_ids.map do |task_id|
ProjectTask.new(
task_id: task_id,
project_id: target_project_id,
priority: calculate_priority
)
end
# バリデーション実行、コールバックは一部制限あり
result = ProjectTask.import!(project_tasks)
# エラーハンドリング
if result.failed_instances.any?
error_details = result.failed_instances.map do |instance|
"Task ID #{instance.task_id}: #{instance.errors.full_messages.join(', ')}"
end.join('; ')
raise StandardError, "バリデーションエラー: #{error_details}"
end
result
end
import!のメリット
- ✅ バリデーション実行: ActiveRecordのバリデーションを有効にできる。
- ✅ 詳細なエラー情報: 失敗したレコードのインスタンスとエラー内容を取得できる。
- ✅ 高速: insert_all!ほどではないが、十分に高速。
- ✅ 豊富なオプション: 重複キー更新(upsert)など、多彩な機能を持つ。
import!のデメリット
- ❌ 外部gemへの依存: activerecord-importを導入する必要がある。
- ❌ コールバック制限: before_validation / after_validation は実行されるが、それ以外のコールバック(before_saveなど)は実行されない。
3. each_slice での分割処理
Rubyの標準メソッドを使い、データを小さなバッチに分割してcreate!で登録していく安全・確実な手法
def bulk_migrate_with_each_slice(task_ids, target_project_id)
batch_size = 100
created_records = []
task_ids.each_slice(batch_size) do |batch_task_ids|
ActiveRecord::Base.transaction do
batch_task_ids.each do |task_id|
record = ProjectTask.create!(
task_id: task_id,
project_id: target_project_id,
priority: calculate_priority
)
created_records << record
end
end
end
created_records
end
each_sliceのメリット
- ✅ 全機能利用可能: バリデーション、コールバックなど、ActiveRecordの全機能が完全に動作する。
- ✅ メモリ効率: バッチ処理により、大量のデータを一度にメモリに乗せる必要がない。
- ✅ gem不要: RailsとRubyの標準機能だけで実装できる。
each_sliceのデメリット
- ❌ 低速: データ1件ごとにINSERT文が実行されるため、処理速度が最も遅い(N+1 INSERT問題)。
- ❌ 実装が複雑: トランザクション管理など、コードがやや複雑になる。
パフォーマンス比較
開発環境で実際の処理時間を測定してみました(1000件のレコード挿入)。
| 手法 | 処理時間 | SQL実行回数 | メモリ使用量 | console実行結果 |
|---|---|---|---|---|
insert_all! |
78.58ms | 1回 | 低 | 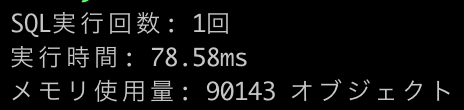 |
import! |
906.1ms | 2001回 | 中 | 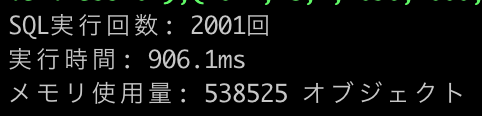 |
each_slice |
1936.98ms | 4020回(100件ずつ) | 高 | 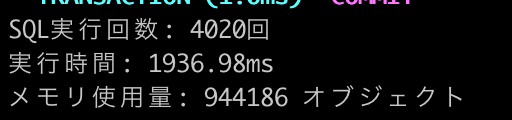 |
※ 環境:MySQL、1000件のレコード、バッチサイズ100
結果: insert_all!の圧勝。import!も十分に高速ですが、each_sliceはSQL発行回数が多く、顕著に遅くなることが分かります。
今回の技術選択:import! を選んだ理由
要件に対する各手法の評価
各手法を要件と照らし合わせて評価しました。
| 要件 | insert_all! |
import! |
each_slice |
|---|---|---|---|
| 大量データ処理 | ✅ 高速 | ✅ 高速 | ❌ 低速 |
| バリデーション | ❌ 無効 | ✅ 有効 | ✅ 有効 |
| エラーハンドリング | ❌ 困難 | ✅ 詳細 | ✅ 詳細 |
| 保守性 | ✅ シンプル | ✅ 中程度 | ❌ 複雑 |
決定要因
1. バリデーションの重要性
データ整合性を担保するため、validates :task_id, uniqueness: { scope: :project_id }のような一意性制約のチェックは不可欠でした。この時点で、バリデーションが効かないinsert_all!は選択肢から外れました。
2. コールバックの現状確認
ProjectTaskモデルには現時点でafter_createのようなコールバックが実装されていませんでした。将来追加される可能性はありますが、今の要件ではimport!のコールバック制限は問題になりませんでした。
3. エラーハンドリングの必要性
# import!なら詳細なエラー情報が取得可能
if result.failed_instances.any?
error_details = result.failed_instances.map do |instance|
"Task ID #{instance.task_id}: #{instance.errors.full_messages.join(', ')}"
end.join('; ')
# ユーザーに分かりやすいエラーメッセージを返せる
end
大量データ処理では、どのレコードでエラーが発生したかの特定が重要。import!の詳細なエラー情報は非常に有用でした。
4. パフォーマンスと安全性の両立
-
insert_all!: 最速だがバリデーション不可 -
import!: 高速でバリデーション可能 -
each_slice: 安全だが低速
each_sliceは安全ですが、数千件のデータに対してはパフォーマンスが懸念されました。import!はバリデーションを有効にしつつ、十分な速度を確保できる最適なバランスでした。
結論: バリデーションとパフォーマンスのバランスを考慮し、import!を選択。
判断フローチャート
要件に応じて最適な手法を選ぶためのフローチャートです。
【結論】ユースケース別・使い分けガイド
insert_all! を選ぶべき場面
バリデーションやコールバックは不要。とにかく速さが正義というケースに最適です。
- ✅ ログデータの一括挿入
- ✅ マスターデータの初期投入
- ✅ 外部APIからの大量データ同期
- ✅ パフォーマンス最優先の場面
# ログデータの例
AccessLog.insert_all!(
api_requests.map do |req|
{
endpoint: req.endpoint,
status_code: req.status,
response_time: req.duration,
created_at: req.timestamp
}
end
)
import! を選ぶべき場面
パフォーマンスとデータ整合性を両立させたいという、実務的なケースで候補となります。
- ✅ ユーザーが入力したデータ(CSVインポートなど)の一括登録
- ✅ バリデーションが必須のビジネスデータ処理
- ✅ どのデータでエラーが起きたか正確に知りたい場合
# CSV インポート機能の例
def import_products_from_csv(csv_data)
products = csv_data.map { |row| Product.new(row) }
result = Product.import!(products, validate: true)
handle_import_errors(result) if result.failed_instances.any?
result
end
each_slice を選ぶべき場面
速度は最優先ではない。ActiveRecordの機能をフル活用して、安全に処理したいというケースに。
- ✅
after_createでメール送信やキャッシュ更新など、コールバック処理が必須の場合 - ✅ 1件ずつ複雑なビジネスロジックを伴う登録処理
- ✅ 外部gemの利用が制限されている環境
- ✅ メモリ使用量を厳密に制御したい
# 会員登録の例(メール送信コールバック付き)
def bulk_create_users_with_emails(user_data)
user_data.each_slice(50) do |batch|
ActiveRecord::Base.transaction do
batch.each do |data|
User.create!(data) # after_create でメール送信
end
end
end
end
まとめ
大量データの一括登録には銀の弾丸はなく、プロジェクトの要件に合わせた技術選定が何よりも重要です。
-
パフォーマンス重視 →
insert_all! -
バランス重視 →
import! -
安全性重視 →
each_slice
今回の選択が全てではありません。将来、モデルにコールバックが追加されたら import! から each_slice への変更を検討するかもしれません。常に要件を正しく理解し、それぞれのメリット・デメリットを天秤にかけることが、質の高い開発に繋がります。
この記事が、あなたの技術選定の助けになれば幸いです。
ツッコミどころがあれば教えていただけると喜びます🙇♂️

Discussion