🔎
HTMLタグを抽出する正規表現, 読めますか?
HTMLタグの抽出する正規表現として以下がよく挙げられます.
さて、みなさん読めますか? (時間はかかっても良い)
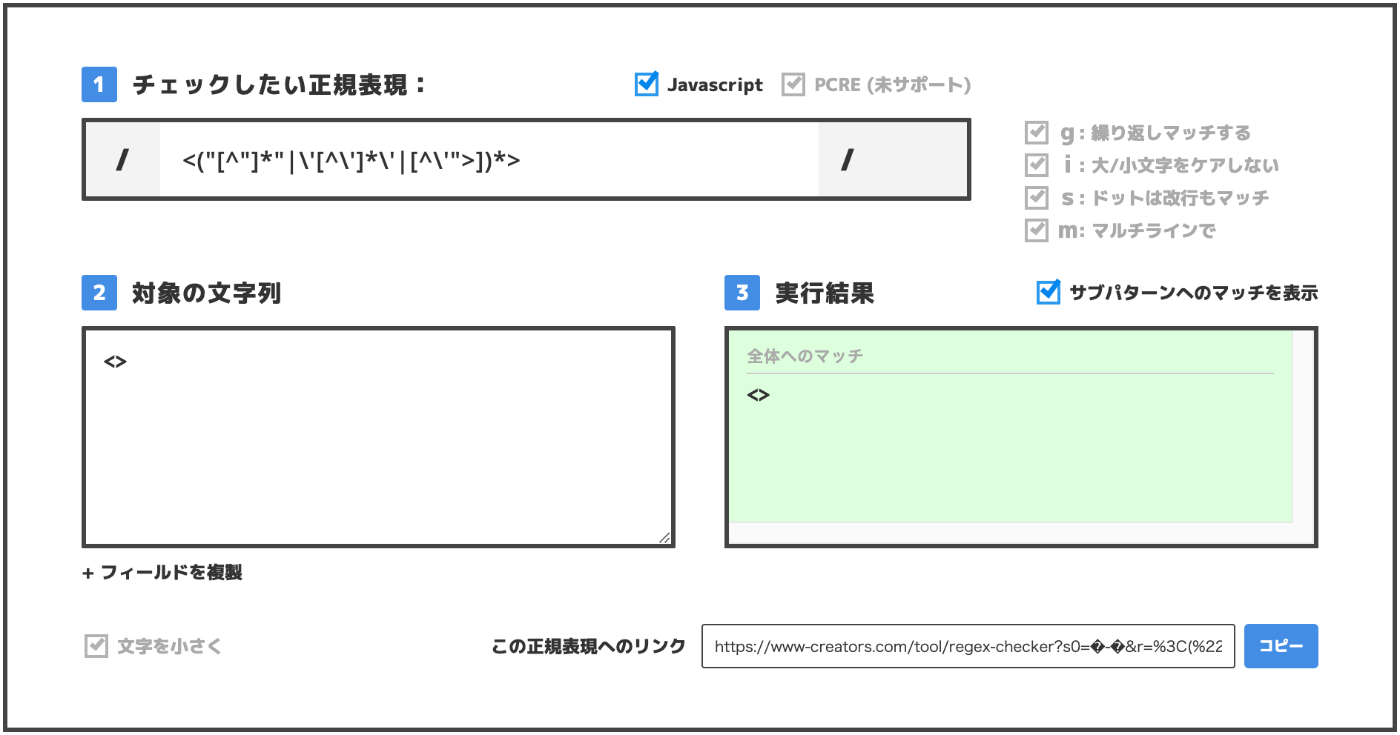
<("[^"]*"|\'[^\']*\'|[^\'">])*>
解説
このパターンは以下のパターンの0回以上の繰り返しを<>で囲っています
(“[^”]*”|\’[^\’]*\’|[^\’”>])
- 0回以上なので
<>もマッチする
この部分は以下の三つが使われています.
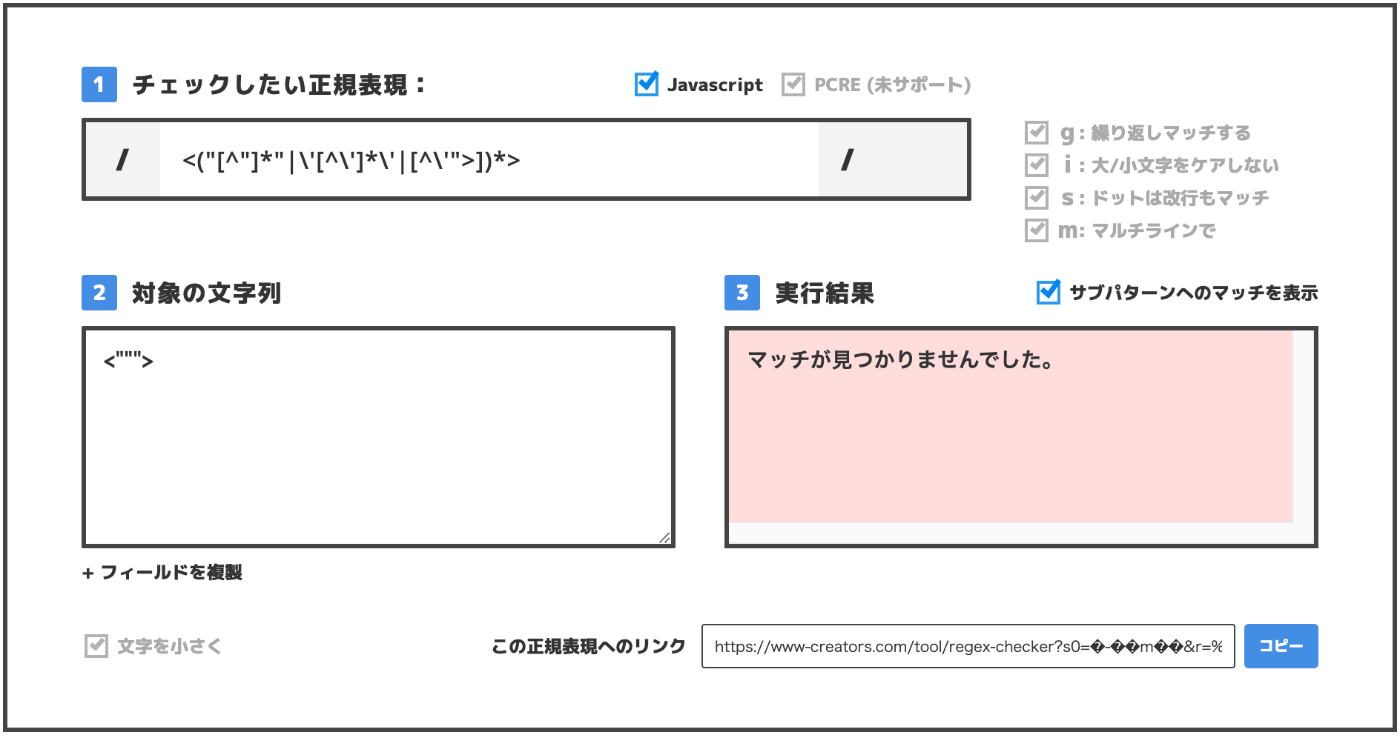
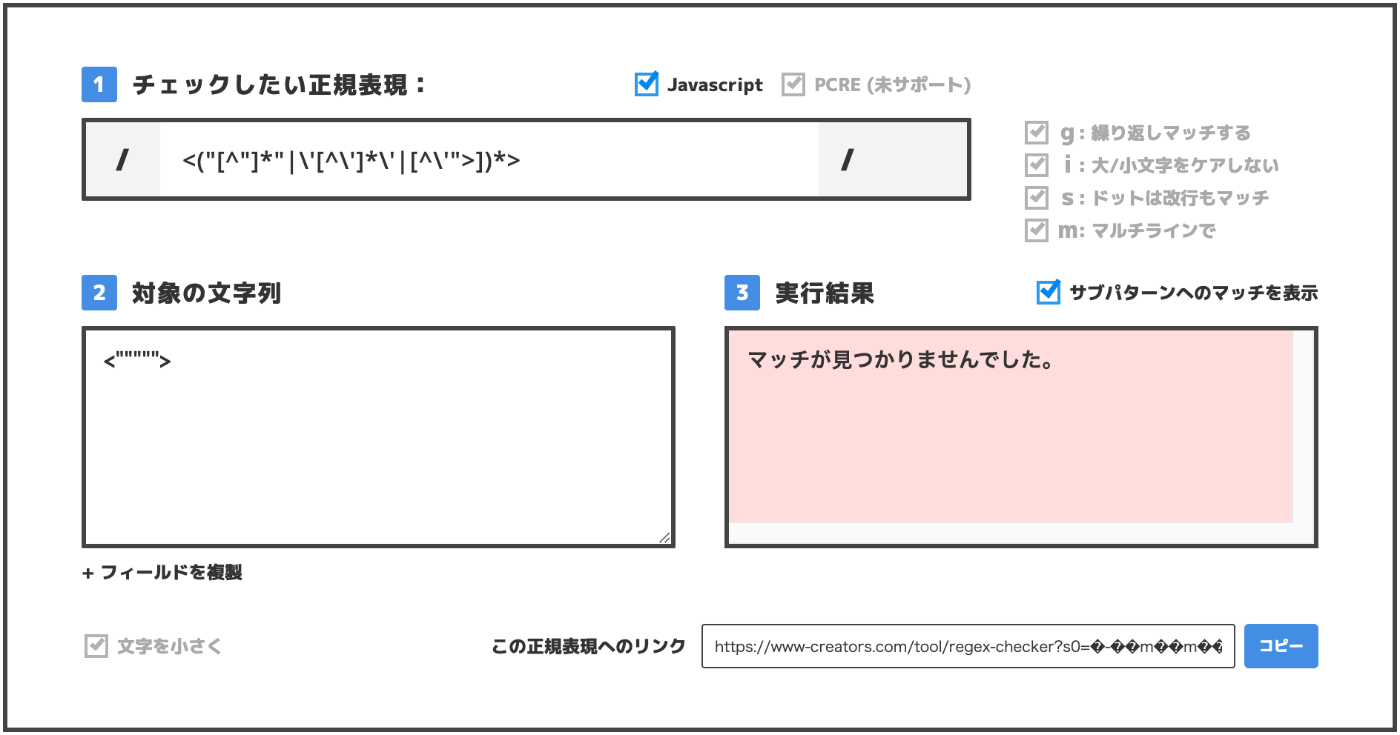
- ダブルクオート(“”)で囲われた”以外の文字全ての0回以上の繰り返し
“[^”]*”
- 逆に
<""">のようなパターンはマッチしない- (引用符が閉じていない)
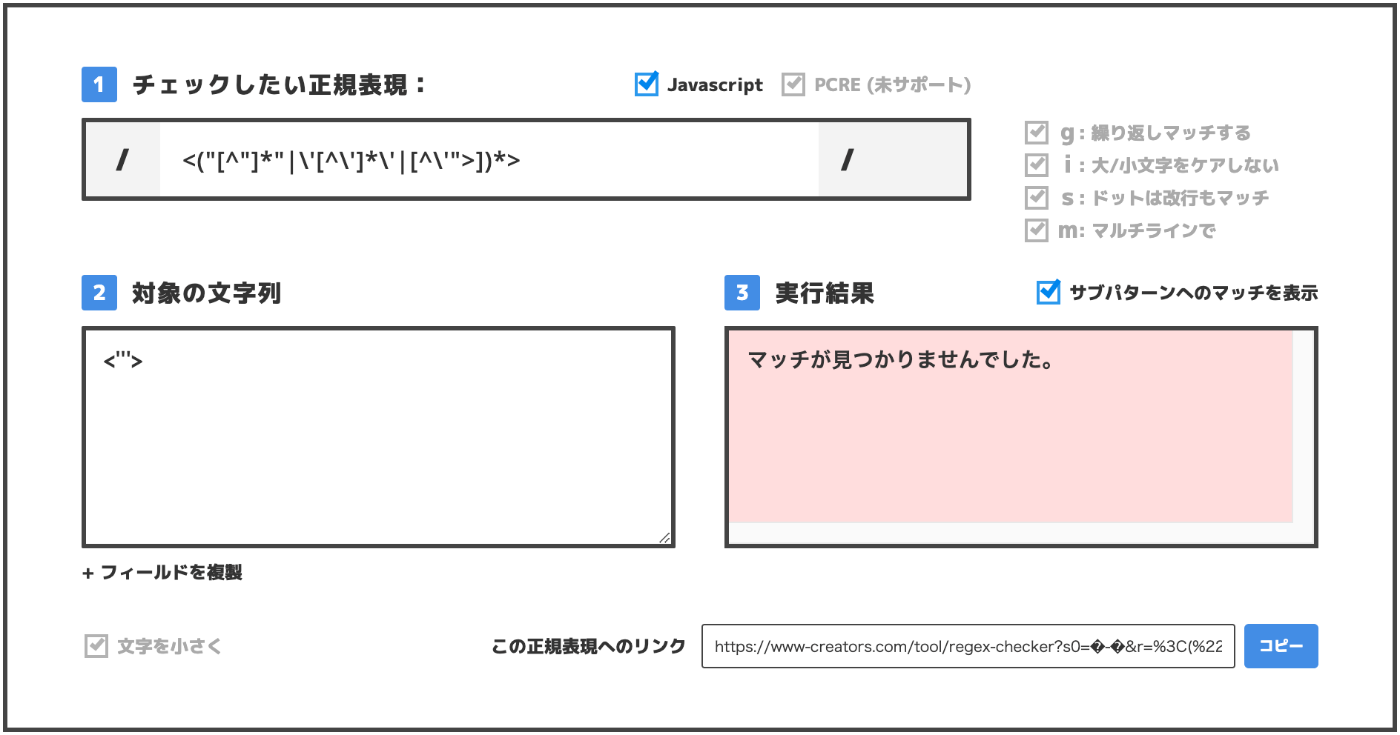
- シングルクオート(‘’)で囲われた’以外の文字全ての0回以上繰り返し
\は直後のmeta文字をエスケープする表現.
\’[^\’]*\’
- ‘, “, >以外の任意の1文字
[^\’”>]
まとめ
以上より, この正規表現は "<>" で囲まれた文字列に対してマッチします. しかし, その中に閉じられていない引用符(つまり " のペアがない状態)が存在している場合はマッチしないという仕組みであることがわかりました. よってHTML tagの抽出に使えることがわかります.
<("[^"]*"|\'[^\']*\'|[^\'">])*>
ちょっと実践的な話
ここまで読んで以下がマッチしてしまうことに気づいた方もいると思います.
<あいうえお>
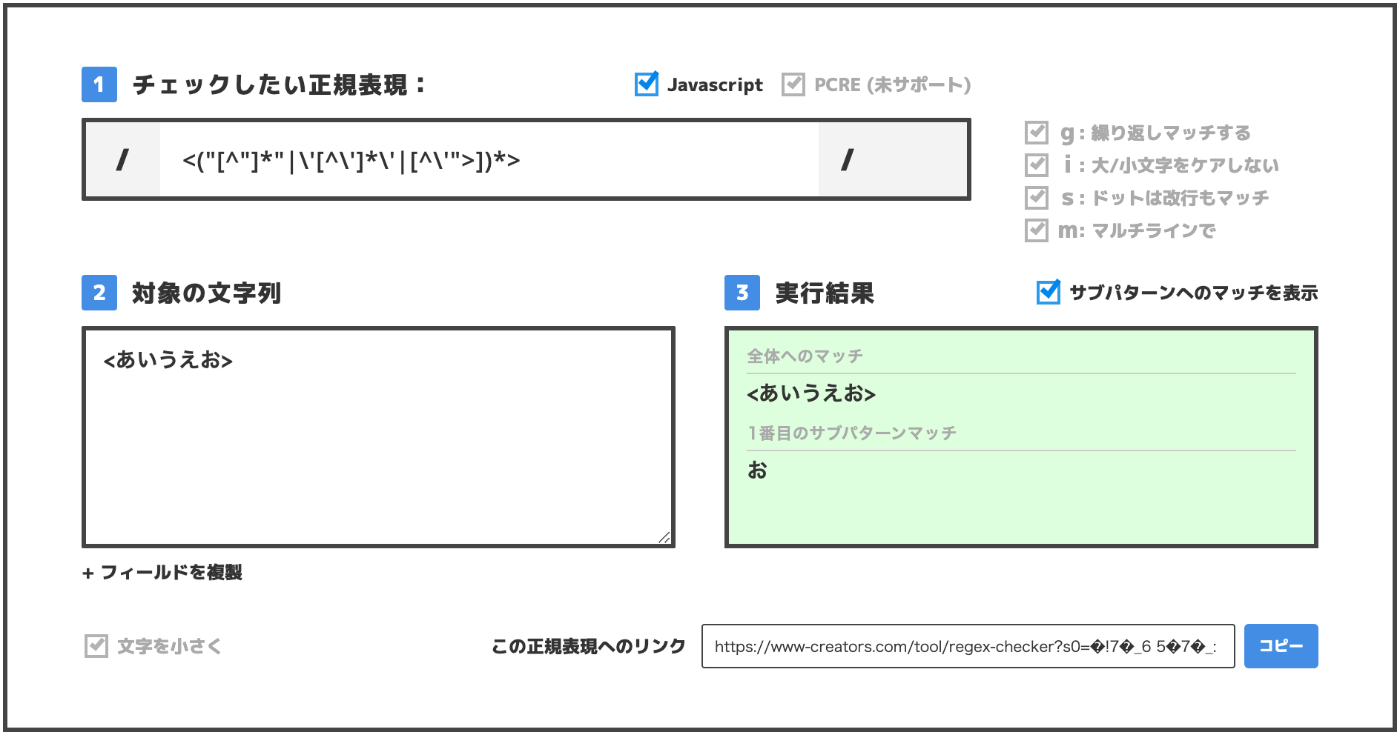
その理由はこの部分です.
[^\'">]
これは実務にも影響する可能性があります.
例えば, ネットスーパーの広告ページのHTMLデータからタグを消したいというタスクがあったとします. このとき, <店長オススメの一品>〇〇県産 たまご (8個入) 299円 [おひとり様一点まで]のような文章があった場合, <店長のオススメ>はHTML tagと判定されてしまいます.
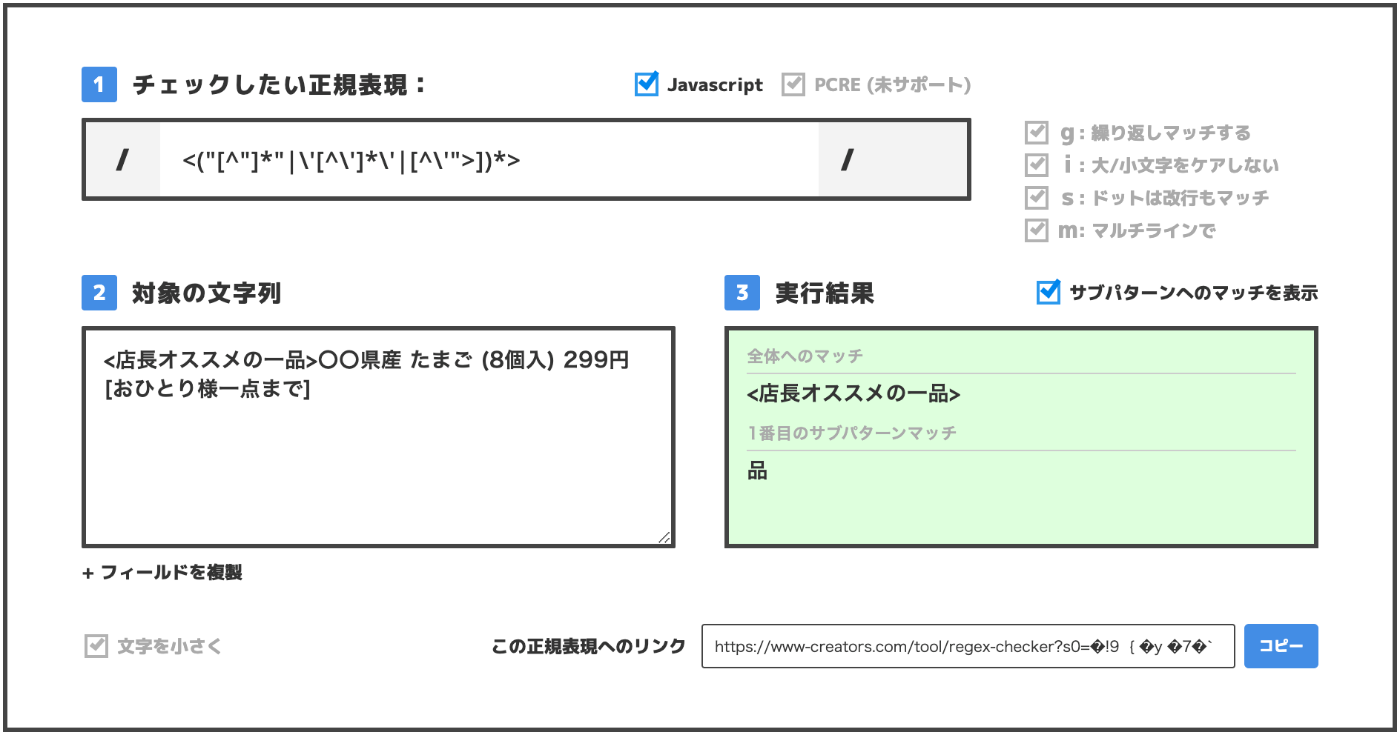
対処法としてUnicodeの範囲を指定するなどの方法があると考えられます.
正規表現をよく読むとともに実データをきちんと見て実践したいものです.
Discussion