🈴
PostgREST: CheatSheet / JOIN Table Query
PostgRESTではPostgreSQLをREST形式で扱うことができます. これを用いることでDBをREST形式で扱えるほか, 言語によっては組み込み関数でDBを扱うことができます. 近年注目を集めているServerlessDBのSupabaseはPostgRESTを使うことができます.
しかし, Documentを見たときにJOINの文法をDocumentから見つけることができなかった他, 日本語記事が少なかったため対応表を記します.
Read
SELECT文は以下のように書くことができます.
SELECT name, score FROM table_name WHERE id > 10 ORDER BY score DESC
// GET /table_name?select=name,score&id=gt.10&order=score.desc
注意点
- SELECTの部分について
-
SELECT * from table_nameをtable_name?select=*というように書ける. - 尚,
/table_name?id=gt.10はselect=*と同じ結果
-
- 演算子は以下が使えます
- PostgREST Operators
- AND/OR文は
and=(filter1,filter2,...)/or=(filter1, filter2,...)のように書くことができます. (filterの部分にtarget=gt.10のように条件式を入れる)
- 省略したが書けるもの
- limit句
- array columns
- virtucal columns
JOINの使い方
結論からいうとJOINはanother_table_name(column)で取得できます. 以下は私が試した時に作成したQueryとTableです.
GET /task?select=*,status_name(name),tag_name(name),task_deadline(dead_line)
Tableを可視化したものです. dbdiagramでMySQLから生成したものであり細かい部分を修正していることを念頭にみてください.
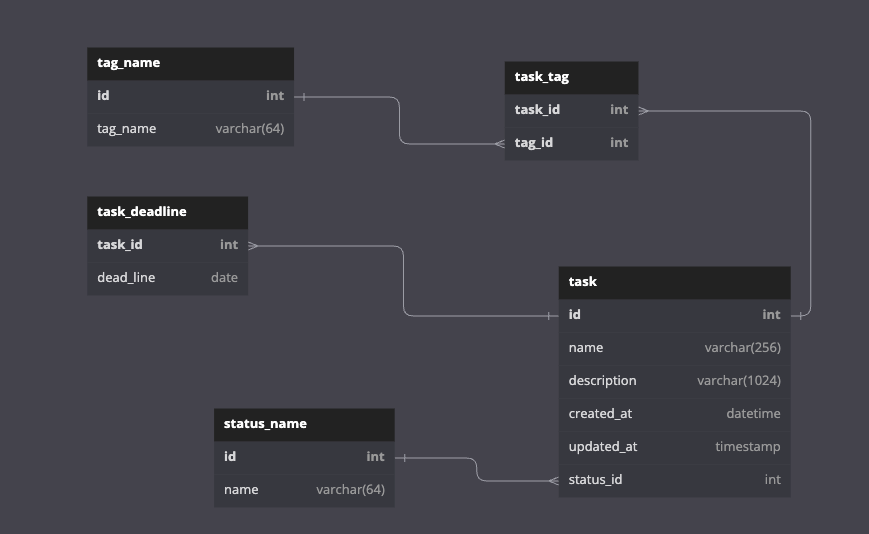
正確な定義は以下です. (長いのでToggleにしています)
Table Definition
CREATE TABLE "tag_name" (
"id" SERIAL PRIMARY KEY,
"tag_name" varchar(64) UNIQUE NOT NULL
);
CREATE TABLE "status_name" (
"id" SERIAL PRIMARY KEY,
"name" varchar(64) UNIQUE NOT NULL
);
CREATE TABLE "task" (
"id" SERIAL PRIMARY KEY,
"name" varchar(256) UNIQUE NOT NULL,
"description" varchar(1024) NOT NULL,
"created_at" timestamp DEFAULT current_timestamp,
"updated_at" timestamp DEFAULT current_timestamp,
"status_id" int NOT NULL
);
CREATE TABLE "task_tag" (
"task_id" int NOT NULL,
"tag_id" int NOT NULL,
PRIMARY KEY ("task_id", "tag_id")
);
CREATE TABLE "task_deadline" (
"task_id" int PRIMARY KEY NOT NULL,
"dead_line" date NOT NULL
);
CREATE INDEX "status_id_index" ON "task" ("status_id");
CREATE INDEX "task_id_index_on_task_tag" ON "task_tag" ("task_id");
CREATE INDEX "tag_id_index" ON "task_tag" ("tag_id");
CREATE INDEX "task_id_index_on_task_deadline" ON "task_deadline" ("task_id");
ALTER TABLE "task" ADD FOREIGN KEY ("status_id") REFERENCES "status_name" ("id") ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE "task_tag" ADD FOREIGN KEY ("task_id") REFERENCES "task" ("id") ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE "task_tag" ADD FOREIGN KEY ("tag_id") REFERENCES "tag_name" ("id") ON DELETE CASCADE ON UPDATE CASCADE;
ALTER TABLE "task_deadline" ADD FOREIGN KEY ("task_id") REFERENCES "task" ("id") ON DELETE CASCADE ON UPDATE CASCADE;
Write
WriteはPOSTのデータにJSON Object形式で記載します.
POST /table_name HTTP/1.1
{ "id": "aiueo", "name": "akstn", ...}
注意事項
- PUTについて
- PUTも基本は同じです
- PUTを使う場合はPRIMARY KEYを演算子
=eq.で指定することに気をつけてください.
- DELETEについて
- DELETEも基本同じです
- WHERE句などのHorizontal Filtering(Rows)を使うことができます.
-
Prefer: return=representationをHeaderに加えることで削除したデータを見ることができます.
Bulk Insert
Bulk InsertはJSONで配列を扱う他にCSVを使うことができます.
POST /people HTTP/1.1
Content-Type: text/csv
name,score
Taro,45
Jiro,30
Saburo,92
最後に
この記事のタイトルは🈴でしたが, なぜだか気づいた方はいますか?
そうです. JOINだからですね(笑)
Discussion