【参加記】Web Speed Hackathon 2025で優勝した話
はじめに
先日、CyberAgent主催のWeb Speed Hackathon 2025に出場しました。
Web Speed Hackathonはお題となるWebアプリケーションのパフォーマンス改善を行い、そのスコアで競い合うハッカソンです。似たようなものにISUCONがありますが、Web Speed Hackathonは主にフロントエンドの改善がメインとなっています。
ここでは参加記として改善の流れや感想などを書きます。
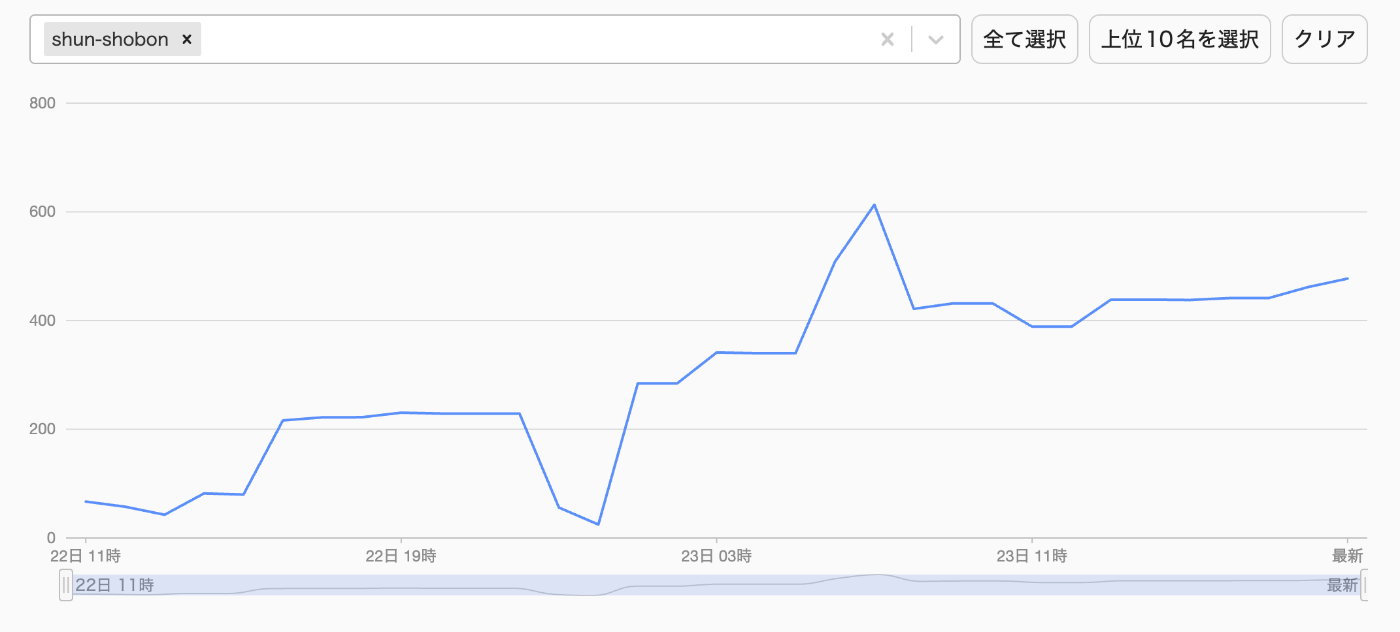
先にスコアの推移を載せます。途中でスコアが大きく伸びている部分がありますが、これは改善によってアプリがエラーで表示できなくなってしまった事によるものです。
また、リポジトリは以下のURLです。
環境構築・デプロイ・初期計測
以下のリポジトリをforkして始めます。アプリの内容は仮想の動画配信サービス「AREMA」だそうです。(なんか似た名前のサービスをCyberAgentが作っていたような…?)
アプリの構成はフロントエンドがReact + React Router、バックエンドがFastify + Drizzleです。フロントエンドはWebpackによってビルドされています。
デプロイ先は運営側がいくつか提案しており、推奨は運営のHerokuアカウントへのデプロイとなっていました。しかし、ログが見れなかったり、後でインフラ系の改善をするときにめんどくさそうだったので、自分のHerokuアカウントを作成してそこにデプロイしました。有料にはなってしまいますが、コンテストは2日間だけなので大したコストにはなりません。
デプロイが完了したら運営側のリポジトリにIssueを作ることで参加登録ができます。Issueに「/retry」とコメントすることでGitHub Actionが回り、計測ができるようになっています。(便利な仕組みですね)
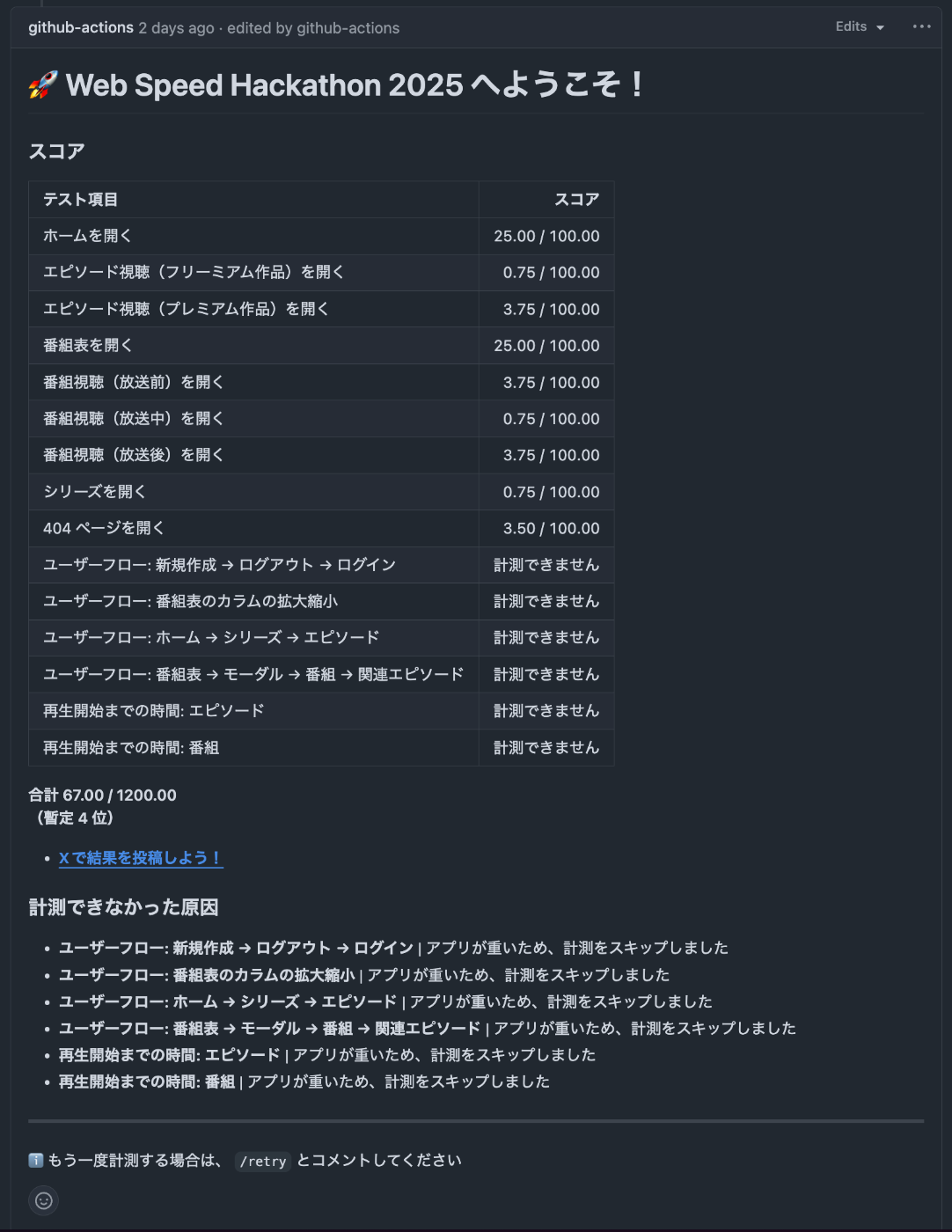
計測は各ページのLighthouseスコアになっています。単純なページ表示の測定が100点満点×9、ログインやページ遷移などのユーザーフローでの測定が50点満点×4、動画再生での計測が50点満点×2あり、合計1200点で計算されます。
初期スコアは67点でした。ホームを開くと番組表を開くが25点で初期計測の割には得点が高いですが、 これはアプリがあまりにも重すぎて指標の一つであるCLS(Cumulative Layout Shift)の計測がタイムアウトし、結果としてCLSが満点になっているようです。 これのせいでチューニングしていくと逆にスコアが下がるという現象が起こります。
改善の流れ
一応計測を取りつつ、改善をしていったのですが、割と行き当たりばったりに改善を入れています(そのせいで最後までスコアが伸びなかったのですが…)。そのため、これから書く内容も時系列とは一致していないので注意してください。
アプリをざっと見てみる
とりあえずアプリを軽く確認してみます。DevToolのネットワークタブを見ているとhtmlが57MB、main.jsは161MBもあります。また、大量の画像や動画再生用の.tsファイル(TypeScriptではなく、ストリームファイルです)が読み込まれています。他にもAPIリクエストが57MBあり、とにかく大きいサイズのダウンロードがあることが分かります。
また、React Scanを使って再レンダリングを調べると、ほぼ全てのコンポーネントが常に再レンダリングされていて、パット見でも何やらヤバそうな実装がされていそうです。
バンドルサイズを計測する
とにかく降ってくるjsファイルが大きすぎるので小さくしましょう。Webpackなのでwebpack-bundle-analyzerを入れてバンドルサイズを確認してみます。ざっと見た感じでも超巨大なmain.tsxとffmpeg-core.wasm、@iconify/jsonあたりがサイズを圧迫していることが分かります。

(どうでもいい話ですが、アナライザーが途中でビルドを止めてしまうせいでHerokuのビルドがいつまで経っても終わらないという問題が生じたので後で環境変数が設定されているときだけ実行されるように変えています)
バンドラの設定を見直す・不要なポリフィルを削除
WSHではお馴染みのおかしなバンドラの設定を修正します。具体的には、
- mode: none → productionへ
- inline-source-mapをsource-mapにして別ファイルに分割
- babelで古いバージョンへ対応させる処理を全て削除
- NODE_ENVが未設定になるようになっていたのでその設定を削除
- チャンク分けが無効化されていたのを止める
- .pngをinlineで読み込んでたのをresourceにして別ファイルになるようにする
といったことを行いました。また、ソースコードにcore.jsとView Transitionのポリフィルが入っていたのでそれを削除しました。今回はChrome最新版での動作が条件なので古いブラウザへの対応は必要ありません。setImmediateのポリフィルはソースコードで使用されていたので削除しませんでしたが、後でsetImmediateを使う必要がなくなったのでそのタイミングで削除しています。
FFmpegを消す
バンドルサイズの大部分を占めていたFFmpegを消します。使用箇所を見てみると、useSeekThumbnail.tsというファイルで使われているようです。
動画プレイヤーでシークバーにホバーしているときに表示されるサムネ画像の生成で使用されています。
やっていることは動画読み込み→1秒ごとのサムネを抜き出して全部横並びの画像にして出力しているだけなので、これはローカルで事前生成しちゃいます。ffmpegの使い方はそこまで詳しくないのですが、ChatGPTに聞いたら答えてくれました。
いらないpreloadの削除
返ってくるHTMLでは全ての画像へのpreloadタグが含まれていますが、無駄なのでさっさと削除しちゃいます。
不要な遅延処理を削除
React Routerの各ページコンポーネントへの動的importとfetchには意図的に読み込みが遅延されるようになっているため、削除します。
キャッシュの設定を見直し
Fastifyに全てのレスポンスにcache-control: no-storeが付与されているため、これを削除します。また、静的ファイルに対してキャッシュされるように設定します。
CSSで表現できるものをCSSに移す
HoverableとAspectRatioというコンポーネントがありますが、これらはそれぞれCSSで表現可能なため、CSSに書き換えて削除します。
useSubscribePointerを削除する
トップレベルのレイアウトコンポーネントで使用されているuseSubscribePointerはマウスポインターの位置を毎フレーム追跡し、状態管理ライブラリであるZustandのストアを更新しています。
これのせいで各コンポーネントが大量の再レンダリングを引き起こしていたようです。
ポインターの位置を使っていたコンポーネントは先程消したHoverableの他に動画のシークバーに使用されていました。シークバーの方はポインターのステートをコンポーネント内に移し、シークバーのみが再レンダリングされるように変更します。
これでポインターの位置を使っていたコンポーネントはなくなったので、useSubscribePointerを削除します。
UnoCSSのランタイムを消す
今回のアプリケーションではスタイリングライブラリとしてUnoCSSが入っています。UnoCSSはTailwindに似たアトミック志向なスタイリングライブラリですが、カスタマイズ性が高く、Tailwindと同じようなプリセットも用意されています。
またランタイムモードが存在し、DOMの変更を検知して<style>を動的に変更する仕組みが存在します。しかし今回のアプリケーションでは各コンポーネントの再レンダリングが非常に多く、それによってUnoCSSの更新も大量に生じています。そのためUnoCSSをランタイムモードで実行するのではなく、Tailwindのようにビルド時にCSSファイルを生成し、それを読み込む方式に変更します。
変更するにあたって、まずはclassの動的変更を消します。具体的にはこのようになっているのを
<div key={item.id} className={`w-[${itemWidth}px] shrink-0 grow-0`}>
{item.series != null ? <SeriesItem series={item.series} /> : null}
{item.episode != null ? <EpisodeItem episode={item.episode} /> : null}
</div>
このように変更します。
<div key={item.id} className="shrink-0 grow-0" style={{ width: itemWidth }}>
{item.series != null ? <SeriesItem series={item.series} /> : null}
{item.episode != null ? <EpisodeItem episode={item.episode} /> : null}
</div>
クラスを動的に生成する方法はビルド時にCSSを生成する方法では使用できないため、style propsに移して対応します。他にもbooleanで分岐しているものはclassNamesを使って対応しました。
動的変更が消えたらWebpackにUnoCSSの設定を入れてビルド時にCSSを生成するようにします。WebpackにはCSSを生成する設定が入っていなかったので、MiniCssExtractPluginとcss-loaderも追加しました。
このタイミングでUnoCSSが読み込んでいた@iconify/jsonがクライアントで読み込まれなくなるのでバンドルサイズも大幅に削減することができます。
WebpackからViteへ載せ替え
ここで自分がWebpack設定をミスっているようで動的importしていてもJSファイルが分割されないという問題に気づきました。また、UnoCSSのサポートがViteの方が手厚いのと、Webpackのbabel-loaderだとビルドにものすごく時間がかかってしまうのでこのタイミングでViteに載せ替えました。
設定方法はChatGPTにWebpackの設定を渡して、「これと同じように動作するConfigを書いて!」とお願いして設定しています。
recommendedのレスポンスを削減
ネットワーク通信を見ていると/api/recommended/:idという通信が数十MBもありとても重たいことが分かります。バックエンドの方を見てみると、明らかにヤバそうなクエリを実行していることが分かります。
const modules = await database.query.recommendedModule.findMany({
orderBy(module, { asc }) {
return asc(module.order);
},
where(module, { eq }) {
return eq(module.referenceId, req.params.referenceId);
},
with: {
items: {
orderBy(item, { asc }) {
return asc(item.order);
},
with: {
series: {
with: {
episodes: {
orderBy(episode, { asc }) {
return asc(episode.order);
},
},
},
},
episode: {
with: {
series: {
with: {
episodes: {
orderBy(episode, { asc }) {
return asc(episode.order);
},
},
},
},
},
},
},
},
},
});
レコードの全てのカラムが必要になるわけではないので、フロントエンドのコンポーネントと見比べつつ、不要なフィールドを落としてあげます。また、ホーム以外ではrecommendedModuleの配列の1件目しか使用していなかったので、クエリにlimitをつけれるようにして対応します。他にもdescriptionがレスポンスの増大につながっていたので、これも必要なところ以外はAPIで返さないようにしています。
- recommendedのレスポンスを大幅削減
- recommendedをちょっと削減
- recommendedの件数を制限できるように
- recommendedを更に削減
- recommendedの削減の仕方を工夫
なお、最終的にレスポンスサイズは削れましたが、レスポンスに結構な時間がかかっていました。これはDBにIndexが貼られていなかったのが原因だったようです。しかし最後まで気づきませんでした…大会終了後にIndexを張ったらレスポンス時間がローカルでも10倍位速くなったのでさっさといれるべき改善でした(手元のLighthouseでも初回のレスポンスが遅いとずっと言われていました)。
プレイヤーを一つにする
今回のアプリケーションは動画配信サービスということで動画再生用のライブラリが入っているのですが、何故か3つも入っています。それぞれShaka Player、hls.js、Video.jsなのですが、特に使い分ける理由はなかったので一つにしてしまいます。ライブラリの大きさを見比べた結果、hls.jsが一番小さそうだったのでhls.jsだけを残しました。
大会終了後に気づいたのですが、hls.jsのオプションでWebWorkerが意図的に無効化されていました。これを有効にすることでもスコアが伸びたかもしれません。
画像の圧縮&キャッシュが効くように設定
配信されている画像のサイズが非常に大きく、数MBあるものもあったので全て圧縮します。今回はAVIFを使用しました。AVIFはWebPよりも更にサイズを小さくできますが、エンコードにものすごく時間がかかるというデメリットがありオンデマンドで生成するには向いていません(去年のWSHであった罠です)。今回は使用される画像が事前わかっていたため、エンコードに時間をかけても問題ありません。そのためImageMagickで一括変換してしまいます。
また、縦横の大きさも無駄に大きかったので適切なサイズにリサイズしています。これでサイズを数MBから数KBまで小さくすることができます。
ちなみに画像のサイズや画質などのパラメータはImageMagickなどのCLIツール上からは調整が難しいため、自分はいつも先にSquooshで1枚だけ読み込んでパラメータを調整した後、ImageMagickで一括変換しています。
各画像は動画のサムネイルデータとして使われていますが、サムネURLに?version={ランダムなID}がつくようになっており、これがキャッシュを妨害します。そのためDBのシードデータを書き換えて?versionがつかないようにします。
注意点として、シードデータはfakerを使って生成されているのですが、ランダムなIDの生成に使われていたfaker.string.nanoid()を消してしまうと乱数生成器のシード値が変わってしまいます。これだとサムネURL以外のデータも変わってしまうのでfaker.string.nanoid()を空打ちして対応します。(これをしないせいでレギュレーション違反になっていた参加者が結構いました)
CLSを起こさないようにする・画像の遅延読み込み
今回の計測指標の一つであるCLS(Cumulative Layout Shift)は画像などのリソースの非同期読み込みによって画面内の要素が移動することでスコアが下がります。特に画像や動画プレイヤーといったものは読み込みに時間がかかるため、読み込みのタイミングで要素がずれるとスコアがどんどん下がってしまいます。
対策としては画像のサイズを決め打ちする、アスペクト比を渡して読み込み前に画像がどれくらい占有されるか事前に分かるようにする、object-fitで画像サイズがレイアウトの計算に寄与しないようにするなどが挙げられます。今回は画像がほぼ全て16:9であったため、UnoCSSでaspect-videoを指定して対応します。
また、画像サイズが事前に分かるようにすることで画像読み込みの遅延が効果的に効くようになります。<img>タグにloading="lazy"をつけることで画像の読み込みがビューポートに入る直前まで遅延されるようになります。今回のアプリではほぼすべてのページで大量の画像が使用されていたので、これによって初回のリクエスト数を大幅に削減することが可能です。
不要なライブラリを削除
CSSやJSで書き換えられそうなライブラリを削除します。具体的には
- lodash → debounceは不要になったので削除、mergeはdeepmergeに置き換え
- react-flip-toolkit → View Transitionに置き換え
- react-ellipsis-component → UnoCSSの
line-clamp-[n]で書き換え
を行っています。
またカルーセルには@epic-web/restore-scrollというページ遷移してもスクロール位置を保存してくれるライブラリが入っていましたが、VRTには寄与しなかったり、レギュレーションチェックのテスト項目にカルーセルのスクロール位置の保存は含まれていなかったため、まるっと削除しました(そもそも最初からうまく動いてなかったような気がします)。
クライアントでのAPIのバリデーションを削除
今回のアプリではAPIのフェッチにbetter-fetchというものが使われています。これはzodなどのスキーマを渡してあげるとリクエストやレスポンスを自動的にスキーマでバリデーションしてくれるのですが、スキーマがdrizzleのDBスキーマファイルを使用しているのでクライアントで使用するとdizzleがバンドルの中に含まれてしまいます。また、クライアントサイドではtypemapを使ってvalibotやtypeboxなどに変換していますが、better-fetchはStandard Schemaに対応しているのでこれも不要です。
そもそもクライアントサイドでバリデーションする必要性が特にないため、全て削除してTSのType Assertionで対応します。Type Assertionで必要なスキーマもtype importしてしまえばバンドルに含まれません。
CDNを挟む
このあたりでCDNを挟みました。始めからCDNを使うつもりでCloudflareのDNSを使っていたのですが、まだコードを把握していない段階でCDNを挟んでしまうとデグレを起こしたときに原因の切り分けが大変になるのでこの時点まではCDNのProxyをOFFにしていました。
CDNを挟むことでCDNのキャッシュから配信できたり、HTTP/2やHTTP/3で並列ダウンロードができたり、zstdなどで通信を圧縮できたりと利点がたくさんあります。
特に今回は画像やストリームファイルが大量にあったのと、APIのレスポンスが大きかったので並列ダウンロードと圧縮が効果的です。
ただ、私がCDNの設定をミスっているのか、main.jsやmain.cssがCDNのキャッシュに残ったきり更新されないという問題が生じました。一応オリジンではこれらのファイルのキャッシュはmax-age=30にしていたので更新されるはずなのですが…
仕方がないのでデプロイの度にCloudflareのダッシュボードからキャッシュの手動パージを行って対処しました。当たり前ですが、パージしてしまうとCDNによるキャッシュの恩恵が得られなくなってしまいます。そのためパージした後、手元でデプロイ先に向けてE2Eテストを走らせてある程度CDNにキャッシュが乗るようにしてから計測を行うようにしました。
Zustandのセレクタを修正する
Zustandの値を使用したい場合は useStore() というhookを使うのですが、引数としてストアのどの値を購読するのかをセレクタとして選択することができます。これにより、ストアが更新された際に、セレクタで選んでいる部分のストアが更新されていない場合は再レンダリングを抑えることができます。
しかし、今回のアプリでは全ての useStore() が useStore((s) => s) というようにセレクタが指定されていました。これだとストアの一部分が更新されただけでもストアに依存している全てのコンポーネントが更新されてしまいます。
そのため、セレクタを適切なものに書き換えて、再レンダリングがなるべく起きないようにしました。
SSRするようにする
バックエンドのHTMLを返しているハンドラを見るとReactの renderToString() を呼び出してはいるものの、その結果を全く使っていません。
app.get('/*', async (req, reply) => {
// @ts-expect-error ................
const request = createStandardRequest(req, reply);
const store = createStore({});
const handler = createStaticHandler(createRoutes(store));
const context = await handler.query(request);
if (context instanceof Response) {
return reply.send(context);
}
const router = createStaticRouter(handler.dataRoutes, context);
renderToString(
<StrictMode>
<StoreProvider createStore={() => store}>
<StaticRouterProvider context={context} hydrate={false} router={router} />
</StoreProvider>
</StrictMode>,
);
reply.type('text/html').send(/* html */ `
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charSet="UTF-8" />
<meta content="width=device-width, initial-scale=1.0" name="viewport" />
<script src="/public/main.js"></script>
</head>
<body></body>
</html>
<script>
window.__staticRouterHydrationData = ${htmlescape({
actionData: context.actionData,
loaderData: context.loaderData,
})};
</script>
`);
});
最初は renderToString() をまるまる消してCSRだけで通していたのですが、長時間真っ白な画面が続くためFCP(First Contentful Paint)にかなりの悪影響が出ていました。そのため、renderToString() の結果を返してSSRするように変更しました。
また、window.__staticRouterHydrationData でReact Routerのloader関数の結果をクライアント側に渡すような実装がされていますが、クライアント側でそれを使っていないので全く意味がない実装になっています。
最終的にはloader関数の結果は全て捨て、loaderを実行したことによるZustandのストアデータをクライアントサイドに渡し、クライアントサイドではZustandにデータがある場合はfetchを行わないように修正して対応しました。
これによってクライアントサイドではloaderの処理時間を大幅に削減することができ、なおかつSSRでFCPの改善もすることができました。
なお、最後までスコアが上がらない原因を何故かSSRだと仮定して、loaderの実行方法を変えたり、CSRに戻してみたり、HTMLの構造を変えてみたりと色々試しています。…がどの改善も大したスコアには繋がらなかったです。正直この時間をもっと他の調査に使うべきでした。
最終的なHTMLを返す処理は以下の通りです。
app.get('/*', async (req, reply) => {
// @ts-expect-error .................
const request = createStandardRequest(req, reply);
const store = createStore({});
const handler = createStaticHandler(createRoutes(store));
const context = await handler.query(request);
if (context instanceof Response) {
return reply.send(context);
}
const router = createStaticRouter(handler.dataRoutes, context);
const content = renderToString(
<StrictMode>
<StoreProvider createStore={() => store}>
<StaticRouterProvider context={context} router={router} />
</StoreProvider>
</StrictMode>,
);
reply
.type('text/html')
.send(
`<!DOCTYPE html>${content}<script>window.__zustandHydrationData = ${htmlescape(store.getState())}</script>`,
);
});
クライアントではこのように読み込んでいます。
declare global {
var __zustandHydrationData: unknown;
var __staticRouterHydrationData: HydrationState;
}
const store = createStore({
hydrationData: window.__zustandHydrationData,
});
const router = createBrowserRouter(createRoutes(store), { hydrationData: window.__staticRouterHydrationData });
hydrateRoot(
document,
<StrictMode>
<StoreProvider createStore={() => store}>
<RouterProvider router={router} />
</StoreProvider>
</StrictMode>,
);
- SSR
- prefetchの返り値を捨てる
- クライアントはprefetchを待たない
- prefetchを修正
- zustand捨てる
- SSRでPrefetchしない
- Revert "SSRでPrefetchしない"
- ZustandのHydration
- Reapply "SSRでPrefetchしない"
- Revert "ZustandのHydration"
- 一回SSR止める
- SSRを戻す
- hydration忘れてた
- SSRを一旦止める
- Revert "SSRを一旦止める"
(こうやって見ると本当にずっとSSRいじってるな…)
番組視聴画面の再レンダリング抑制・APIの呼び出しを削減
番組視聴画面では放送前、放送中、放送後でそれぞれ挙動が異なり、放送前は「〇時〇分に放送予定です」という文言を表示して、放送時間になると自動的に放送画面になり、放送終了時、次の番組があればそれに自動的に遷移するようになっています。また、すでに放送終了した番組の場合は見逃し視聴画面へのリンクを表示します。
まず、放送前、放送中、放送後を判別する処理がsetTimeout()によって250msごとにコンポーネントを再レンダリングすることで行われていました。放送状態は放送開始時刻と終了時刻に変化するため、現在時刻との差分を取ってsetTimeout()一回で済むように変更しました。
また、次の番組があるかどうか調べるために(この時点で)数MBもある番組表のデータを全件取得していたので、API側で番組情報のレスポンスに次の番組のIDを含めるようにして、番組表のデータを取得しないように変更しました。
プレイリストのかさ増しを削除
なんとなく視聴画面のネットワークを見ていると、/streams/channel/:channelId/playlist.m3u8 のレスポンスサイズが数十MBあることに気づきました。 .m3u8 はTSファイルの一覧が列挙されているだけのファイルなので通常は数KB程度に収まるはずです。バックエンドを見てみると、何やら X-AREMA-INTERNAL というものにrandameBytes() で巨大な文字列が書き込まれています。 .m3u8 の具体的なフォーマットについては知りませんでしたが、 X-AREMAとなっていて標準化されたフィールドではなさそうな点、リポジトリ内で X-AREMA-INTERNAL で検索してもここしかヒットしない点からただのかさ増しだと判断して削除しました。
playlist.push(
dedent`
${chunkIdx === 0 ? '#EXT-X-DISCONTINUITY' : ''}
#EXTINF:2.000000,
/streams/${stream.id}/${String(chunkIdx).padStart(3, '0')}.ts
#EXT-X-DATERANGE:${[
`ID="arema-${sequence}"`,
`START-DATE="${sequenceStartAt.toISOString()}"`,
`DURATION=2.0`,
`X-AREMA-INTERNAL="${randomBytes(3 * 1024 * 1024).toString('base64')}"`,
].join(',')}
`,
);
ところでこのエンドポイントのハンドラを見てみるとfor文の中でDBへのクエリを実行していて、N+1問題になっていたようです。大会中にも気づいてはいたのですが、初回アクセス時に使われるエンドポイントではないので放置しました。
番組表の再レンダリングを抑制
番組表は新聞の番組表のように各チャンネルごとに時系列順に番組が並んでいます。また、放送前、放送中、放送後で番組の色が変わったり、各チャンネルの幅をドラッグで調整できる機能もあります。
React Scanを差してみると全番組のコンポーネントが毎フレーム再レンダリングを引き起こしています。これも先程の番組視聴画面と同様に、放送状態のステートをリアルタイムで更新するためのようです。こちらは setInterval() を使って対応しました(今思えばなぜ setTimeout() にしなかったのかは謎です)。ただし、setInterval() 時に今の状態と異なっていた場合のみステートの更新を行うようにしていたので再レンダリングは大幅に抑えられています。
また、番組表にサムネが載るのですが、コンポーネントの高さがサムネを表示できるほど大きい場合にのみ表示されるというような処理になっています。作問者側の想定解はCSSで表示非表示を切り替える実装だったようですが、画像の高さは横幅から求められることを利用して(アスペクト比が分かっているため)高さを計算し、それを用いて表示非表示を切り替える実装にしています。これの利点として、画像を透明度0にして非表示にするのではなく、完全にDOMの要素として削除することができます。透明度0でも画像は読み込まれてしまいますが、DOMごと削除すれば画像の読み込みは発生しないため、番組表での画像読み込みを大幅に削減することができます。
番組表のAPIリクエストの削減
番組表を開くと数MB程度のAPIが複数飛んでいます。これはそもそも番組一覧のレスポンスが大きいのと、番組をクリックした際に出現するモーダルで使われる番組のエピソードデータの取得も合わせて行われているためです。モーダルで使われるデータはモーダル出現前まで使用されないため、APIのフィールドから落として削減します(特にdescriptionが巨大なので消せると恩恵が大きい)。また、モーダルクリック時のデータは、専用にエンドポイントを一つ用意して対処しています。
また、ここでエピソードデータの取得をバッチ処理で行うためのbatshitというライブラリを削除することが可能になるのでこのタイミングで削除しています。これのせいでAPIの取得が最低でも1秒遅延していました。
luxonを捨てる
今回のアプリでは日付ライブラリとしてluxonが入っていました。luxonは日付ライブラリの中でも比較的サイズが大きく、バンドルサイズを圧迫していました。そのためより軽量なday.jsに置き換えてしまいます。
APIは似ているので比較的移行は簡単ですが、タイムゾーンの扱いとフォーマットの文字列が微妙に違う点に注意します。レギュレーション違反で失格になった参加者の中にもタイムゾーンの扱いをミスって9時間ズレて表示されていた方がいたようです。
Zodを捨てる
APIのバリデーションで使われていたzodは消しましたが、まだログインや新規登録のフォームバリデーションでzodが使われていたのでバンドルの中には含まれています。zodも比較的大きいライブラリなので、より軽量なvalibotに置き換えてしまいました。今回は簡単なメールアドレスとパスワードのバリデーションだけなので自前で書いてしまっても良かったかもしれません。
なお、バリデーションで使われていた正規表現にはReDoSがあったようです。大会中になんとなく気づいてはいたのですが、去年はReDoSの解消のために正規表現を書き換えたせいでレギュレーション違反で失格になってしまったので、安全のために今回は触りませんでした。そもそもログインのユーザーフローテストは1項目しかなく、50点満点なのでそこまで全体のスコアに影響はしないと判断しました。
レギュレーションチェック
このあたりでスコアが伸び悩んでいて、あらかた思いついた改善策も入れ終わっていたのでレギュレーションチェックで失格にならないようにVRTと手動テスト項目を確認します。
これによって入れていた改善のいくつかをrevertしました。
まずカルーセルのサイズ計算ですが、本来はリサイズに応じて子要素の大きさが変わるはずでしたが、自分がCSSで実装していたものはリサイズしても大きさが変わっていないようだったのでrevertしました。作問者的にはコンテナクエリなどを組み合わせて実装するのが想定解だったようですが、とてもじゃないけどあの実装を競技時間中に思いつくのは無理です。
また、ログインや新規登録のモーダルはreact-final-formが使われており、それがバンドルサイズを圧迫していたのですが、Reactのlazy()を用いて遅延読み込みにするとVRTが落ちてしまうためこれも戻しています。
他にも細かいデグレポイントを見つけて修正していきました。
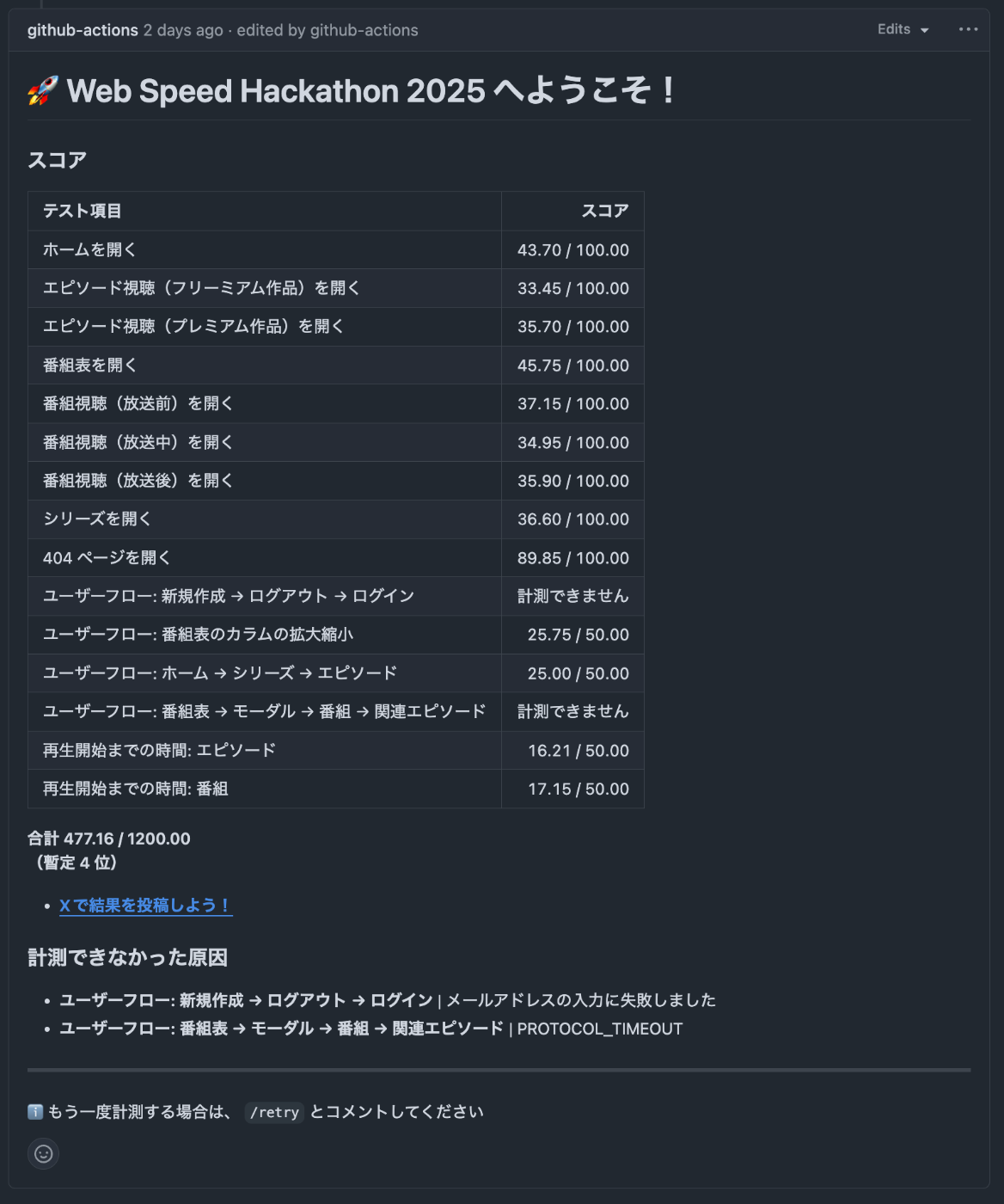
最終計測
最終計測は477.16点でした。アカウント系の計測が通っていないのはReDoSを放置したからだと思われます(番組表の方は不明ですが一度も通りませんでした)。
最終的なバンドルサイズも載せておきます。初回で読み込まれる main.js は964KBまで小さくできています。最初が161MBだったことを考えると、100倍以上の軽量化に成功しています。
結果・順位
最終結果としては全体・学生1位、スコア順位でも4位を獲得することができました! レギュレーションチェックを受けた上位17名の中で唯一レギュレーションチェックを通過し、単独での入賞となりました。去年はスコア順位2位だったのにも関わらず、レギュレーション違反で失格だったので去年の屈辱を果たすことができとても嬉しかったです。

その他大会中に気付けなかった・時間がなかった改善ポイント
番組表のリサイズ
番組表のリサイズ処理は時間がなくて手をつけられませんでした(ユーザーフローなので蔑ろにしてたのもありますが…)。リサイズでは横幅の値が各番組のコンポーネントで使われていましたが、一番親のコンポーネントでのみ横幅を指定してあげれば各コンポーネントの再レンダリングを大幅に削減することができたのかな?と思っています。
TBTの改善
結局ナビゲーション系のテスト項目も最後まで50点以上を獲得することができませんでした(404ページを除く)。手元のLighthouseでは100点近い高得点だったのですが、PageSpeed Insightsなどで計測する限り、TBT(Total Blocking Time)の評価がものすごく悪かったようです。そこでDevToolのPerformanceタブでCPUの処理速度を落として計測してみると…

はい、原因はカルーセルのサイズ計算処理とスクロールスナップ処理が重く、long taskと判断されてTBTのスコアが落ちていたようです。特にサイズ計算処理では window.getComputedStyle() を呼び出していたため、ここでCSSのスタイル計算処理が割り込んでいたようです。これを requestIdleCallback() に分離するとlong taskがなくなったため、ほぼこれが原因として間違いないと思っています。
自分がPerformanceタブを見るのが不慣れだったのが悪いですが、もっとちゃんと計測を行うべきでした…
また、ホーム画面などではカルーセル内の画像がLCP(Largest Contentful Paint)と認識されていましたが、前述の理由からカルーセルの表示に時間がかかるため、LCPのスコアも悪くなっていたようです。
おわりに・感想など
まずは優勝できて良かった!という気持ちです。去年はレギュレーション違反で失格になってしまいましたが、今年はVRTやテスト項目が充実していたため、去年よりも参加者側のレギュレーションチェックはやりやすかったのかなと思っています(それでもレギュレーション違反者は大量に出てしまいましたが…)
また、去年はとにかくコードの物量が多くてやることが無限にあり、やればやるほどスコアが上がっていくような感じでしたが、今年は原因を調べながらじゃないとスコアが全く上がらず、より考察や調査が求められるようになっていて、より競技性があったと思っています。
優勝できて良かったとはいえスコア的には全く満足できていないので、スコアリングツールが公開され次第、感想戦でより高得点を目指したいと思います!
Discussion