Googleが推奨するAndroidアーキテクチャを理解する
前提
- モバイルアプリはアクティビティやフラグメントなどの、さまざまなコンポーネントで成り立つ
- ユーザーはいろんなアプリを並行して操作するし、モバイルデバイスのリソースは限られているので、OSがアプリのプロセスを強制終了してくることがある。
- データや状態は、コンポーネント内部やメモリに保持するべきではない
- コンポーネント同士が依存してはならない
- サイズの大きいアプリはテストのしやすいアーキテクチャを定義することが重要
- アーキテクチャとは、アプリ内を分割したパーツの境界と、そのパーツが担う役割を定義したものである
重要な原則
アーキテクチャ設計をする上で守るべき原則
1. 関心の分離
最重要。
そのクラスが責任を持つ範囲を限定しシンプルにすること。
全てのコードを一つのActivityに記述したらライフサイクルの管理やテストが大変になることは想像に難くない。
例えばUIベースのクラスでは、UIやOSとのやり取りだけを含むことでシンプルになる。
あとそもそもクラスはOSからいつでも破棄されうる存在なので、クラスに依存するな。
2. UIをデータモデルで操作する
UIで表示されるデータはデータモデルで操作するべき。
データモデルはUI要素やその他のコンポーネントから独立させる。
するとテストのしやすさと堅牢性が生まれる。
以下の理由でデータモデルの中でも永続モデルがおすすめ。
- OSがアプリを破棄してもリソースを解放した時にデータが失われない。
- ネットワーク接続がない時でもアプリが動く
3. 信頼できる唯一の情報源(SSOT)を使う
アプリ内で新しいデータ型を定義するときは信頼できる唯一の情報源(SSOT)を割り当てろ。
要はデータの変更はSSOT経由でのみ行われ、SSOTから提供されるデータは不変のものにするべき。
こうすることでのメリット
- 特定のデータ型の変更箇所を集約できる
- データが意図せず改竄されることから保護できる
- データの変更を追跡しやすくなり、デバッグ時に便利
(加藤:ここよくわからなかった)
オフラインファーストのアプリでは、SSOTは通常DBだ。場合によってはViewModelやUIが担うこともある。
ViewModelは百歩譲ってわかるとしても、UIがSSOTになることなんてあるのか、、、、?
4. 単方向データフロー(UDF)
単方向データフローに従うと、状態とイベントは互いに一方向に流れるだけで交わらない。
一般的に状態は上位スコープから下位スコープに流れる。
イベントはその逆で下位スコープから上位スコープに流れる。
上位スコープとはデータモデルなどの型のこと、下位スコープとはUIなどのこと。
パッと思いつくのは、ユーザーの操作を反映して画面を更新するとき。
viewModel内の関数を呼び出すことになるが、その返り値を直接UIに返して画面を更新するのはダメで
その関数からUI Stateを操作して、そのUI Stateに応じてUIが更新されるようにするようなことかな?
ここだけ読むとわからないので一旦先に進む
推奨アーキテクチャ
上述の前提を満たした形での推奨アーキテクチャは、下の図。
よく見るやつ。
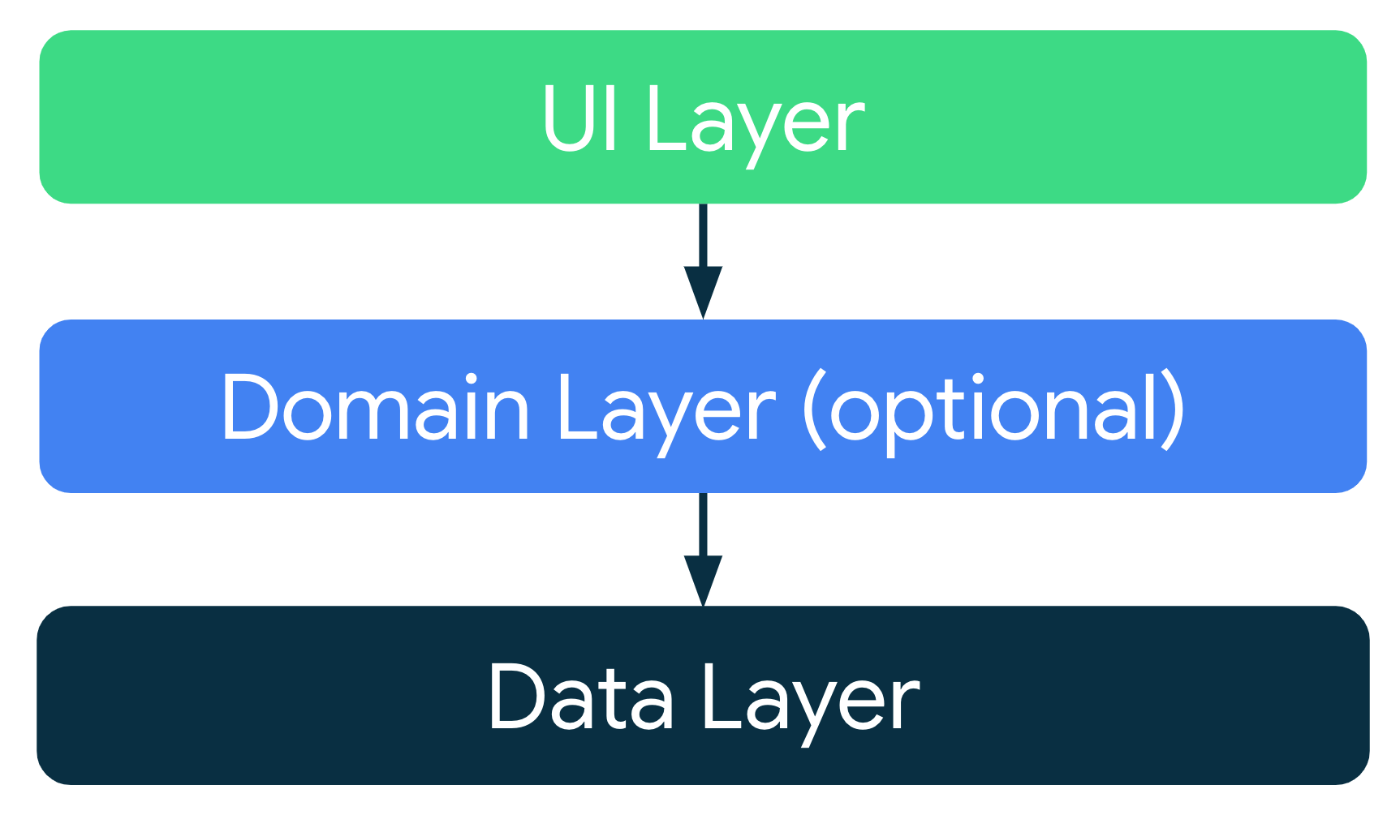
注目すべきは
- レイヤーに分かれている
- Data LayerにDomainやUIが依存しており、逆はない。
UIレイヤ
役割としては、アプリデータを画面に表示すること。
ユーザー操作や外部入力によってデータが変更されたら画面に反映する仕組みも必要。
構成しているのは以下の二つ
- UI Elements: UI要素
- State Holders: データの状態を保持してUI要素に渡しつつ、ロジックを処理する

データレイヤー
ビジネスロジックがメイン。
アプリがデータを作成、保存、変更する方法が入っている。
構成しているのは以下の要素
- Repositories: データの処理を行う。データの公開や変更、ビジネスロジックを含む
- Data Sources: ファイルやネットワーク、ローカルなどのデータベースから一つのデータソースのみを抽出しRepositoriesと橋渡しする

よく見るLayerd ArchのInfra層はData Sourcesとしてデータレイヤーがもつ感じ。
ドメインレイヤ
複数のViewModelなどで使われる単純なロジックや、分割した方がわかりやすい複雑なビジネスロジックをカプセル化する役割。
これがオプショナルな理由は、単純なアプリでは必要ないから。
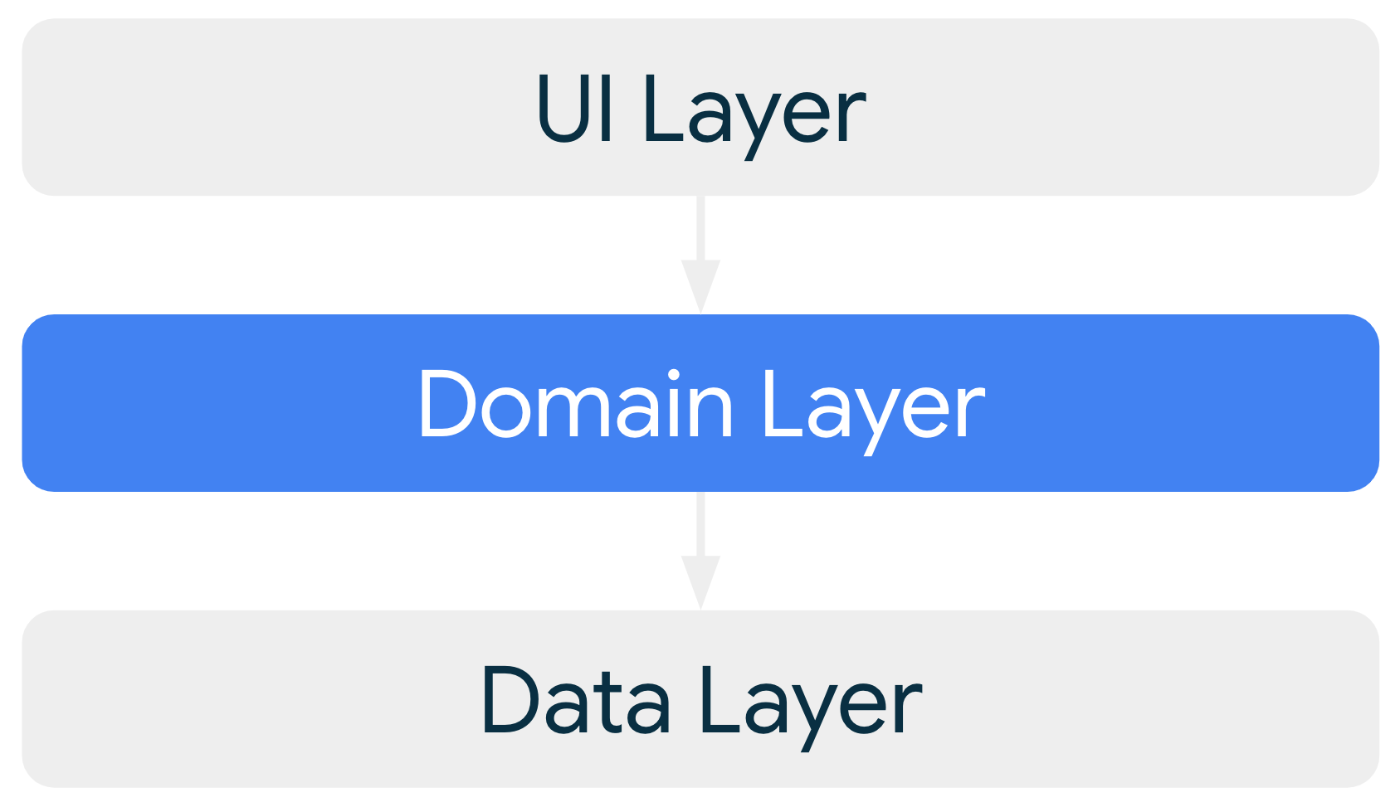
よく見るUsecaseなどはここに入れるイメージかな
依存関係の管理
コンポーネント間の依存関係を、切る方法としては二つある
- 依存関係注入(DI)
- サービスロケータ
サービスロケータについては全然知らなかったが、さっと調べると昔ながらのやり方で今は主流じゃなさそうなので一旦無視しておく。
Googleではシンプルな手動、複雑ならHiltライブラリの導入を勧めている。
調べていると疑問が湧いた。
Data層にDomainやUIが依存して良いのか?というかClean Architecureのアンチパターンなのでは?
この記事がドンピシャだった。
自分なりに要約すると
「複雑なアプリじゃなければDomain層は必要ない」+「Domain層があるかどうかわからないならそこに依存するのはおかしい」的な話だと理解した。
ただ、Clean ArchitectureのDomain層とGoogle推奨アーキテクチャのDomain層は厳密には違うものだとも感じる。
Clean Architectureはロジック部分を、厳密にDomainレイヤーに集約するのに対して
Google推奨アーキテクチャの方では、ロジック部分は基本的にUIレイヤーのViewModelが担う。ViewModelの中で繰り返し使うものや、複雑すぎて分割した方がわかりやすいものだけDomain層に置くという違いがある。
ただどちらにしても、google推奨アーキテクチャの方はdata層に依存しているので違うものであることには変わりない。
clean architectureでは依存先をdomainに集めており、仮にgoogle推奨アーキテクチャの方ではviewModelがdomainに対応しているとしてもも、viewModelはUI層に属する時点で、全然違う。
ここからは自分の解釈
クリーンアーキテクチャは昔ながらのレイヤードアーキテクチャの弱点(presentation層が変更されやすいdata層に依存していること)を
依存性逆転によってdomainに依存先を集めることで解消した。
一方でGoogle推奨の方では、適切な抽象化や依存性のコントロールによって、大元のレイヤードアーキテクチャのシンプルさをのこしたまま解決した。
ということだと思う。
一般的なベストプラクティスまとめ
必ずしも必要ではないが、大体のコードに適応しておくとアプリの堅牢性やテスト、保守のコストを下げるものたち。
全部重要だとは思うが、当たり前なものも多い気がする。
今回は冗長だが例をいっぱい使って書いてみた。
アプリコンポーネントにデータを格納しない
めちゃくちゃわかりづらい書き方をされているが、要はデータ管理とコンポーネントの責務を分離しようというもの。
ユーザーの操作を受け付けるアクティビティなどのコンポーネントにはデータを含ませず、データの管理を行うための別のコンポーネント(ViewModelがメイン)がその責務を全て負う必要がある。
理由は、コンポーネントのライフサイクル的にめちゃくちゃ短くなる可能性があるので、そこにデータを置いてしまうと意図せず破棄されてしまう可能性があるからとのこと。
Android クラスへの依存を減らします。
ContextやToastなどAndroidフレームワークに依存するものは、できるだけ減らしつつ
もし使うなら抽象化して依存性を減らすようにしよう。
理由はテストをしやすくなるから
要は、Androidクラスに依存するのは、UIレイヤーの一部だけにする
+
以下のコードのみたいに抽象化することで直接依存させるのをやめる?
やりすぎな気もするが例えばこんな感じかな?
まずは共通のMessageDisplayerインターフェース
interface MessageDisplayer {
fun showMessage(message: String)
}
Androidフレームワークに唯一依存するAndroidMessageDisplayerクラス
class AndroidMessageDisplayer(private val context: Context) : MessageDisplayer {
override fun showMessage(message: String) {
Toast.makeText(context, message, Toast.LENGTH_SHORT).show()
}
}
使う時
class ExampleViewModel(private val messageDisplayer: MessageDisplayer) {
fun onButtonClicked() {
messageDisplayer.showMessage("ボタンがクリックされました")
}
}
テスト用のモック
class MockMessageDisplayer : MessageDisplayer {
val messages = mutableListOf<String>()
override fun showMessage(message: String) {
messages.add(message) // テスト用にメッセージをリストに追加
}
}
テストする時
class ExampleViewModelTest {
@Test
fun `onButtonClicked displays correct message`() {
val mockMessageDisplayer = MockMessageDisplayer()
val viewModel = ExampleViewModel(mockMessageDisplayer)
viewModel.onButtonClicked()
assertEquals("ボタンがクリックされました", mockMessageDisplayer.messages[0])
}
}
アプリの各種モジュール間の役割の境界を明確にする
例えばあるネットワークからデータを読み込むコードがあるなら、それは一つのクラスにまとめようという話。
複数箇所に点在してしまうと、修正時に該当箇所を探すのが大変だし、バグの発見が遅れてしまう。
また逆に関連のない複数の処理を同じクラスに定義しないようにしよう。
一つのクラスに意味の違うコードがあると、そのクラスの役割がわかりづらくなって読みづらいコードになってしまう。
各モジュールの内部を他のモジュールに公開して、楽するのをやめよう
時々、「実装するのがめんどくさいから、モジュールの内部のプロパティや関数を公開して、他のモジュールで直接使ってしまおう」と魔がさすかもしれない。
絶対にやめよう。
例えば、直接呼び出してしまうと、そのクラスのメソッドを変更したときに、意図しない別の箇所のバグを引き起こす可能性がある。
モジュール間の依存関係も強まってしまう。
悪い例
**悪い例:内部実装を公開するショートカットを作成する**
```java
// DataModule.java
public class DataModule {
public Helper helper = new Helper(); // 内部クラスを公開している
public void performOperation() {
// 一部の処理
}
}
// Helper.java
public class Helper {
public void assist() {
// 補助的な処理
}
}
// 他のモジュールからの利用
DataModule dataModule = new DataModule();
dataModule.helper.assist(); // 内部実装に直接アクセスしている
良い例
// DataModule.java
public class DataModule {
private Helper helper = new Helper(); // 内部クラスを非公開にする
public void performOperation() {
helper.assist();
// その他の処理
}
}
// Helper.java
class Helper {
public void assist() {
// 補助的な処理
}
}
// 他のモジュールからの利用
DataModule dataModule = new DataModule();
dataModule.performOperation(); // 公開されたメソッドのみ利用可能
できるだけ再利用してサボろう
コードはできるだけ楽して書こうという話。
再利用できるコンポーネントなどは再利用し、同じことを何度も書く時間を
アプリのクオリティ向上に当てよう。
ユニットテストがやりやすいコードを書こう
例えばネットワークからデータを取得する部分と、そのデータをローカルに保存する部分を同じ箇所に書いたらテストしづらい。
機能ごと、レイヤーごとに細かくコードを分割しよう。
悪い例
// ネットワークとデータベース処理が混在したクラス
class DataManager {
private val apiService = ApiService()
private val localDatabase = LocalDatabase()
suspend fun refreshData() {
val response = apiService.getDataFromNetwork()
if (response.isSuccessful) {
localDatabase.saveData(response.body())
}
}
}
これだとDataManagerクラスをテストしようと思った時に、ApiSericeやLocalDatabaseの実装に依存しているので、とてもめんどくさい。
モックに差し替えられるようにすれば、ユニットテストがしやすくなる。
良い例
ネットワークとのインターフェース
interface NetworkService {
suspend fun fetchData(): List<DataModel>
}
ローカルに保存するためのレポジトリ
class DataRepository(private val networkService: NetworkService, private val localDatabase: LocalDatabase) {
suspend fun refreshData() {
val data = networkService.fetchData()
localDatabase.saveData(data)
}
}
実際にテストするとき
// テスト用のモックNetworkService
class MockNetworkService : NetworkService {
override suspend fun fetchData(): List<DataModel> {
// テスト用のデータを返す
return listOf(DataModel(id = 1, name = "Test"))
}
}
// テストケース
class DataRepositoryTest {
@Test
fun testRefreshData() = runBlocking {
val mockNetworkService = MockNetworkService()
val mockLocalDatabase = MockLocalDatabase()
val repository = DataRepository(mockNetworkService, mockLocalDatabase)
repository.refreshData()
// データベースに正しくデータが保存されたか確認
assertEquals(1, mockLocalDatabase.getData().size)
}
}
型は同時実行ポリシーに関する責任を負う
これ一番わかりづらい。
AIに聞くと、型っていうのはクラスやコンポーネントのことらしい???
そう考えると、クラスはメソッドが処理されるスレッドを意識して管理する必要があるという意味だとわかる。
メインスレッドから呼び出せるし、メインスレッドをブロックしないということが最低条件らしい
悪い例
何も意識せずメインスレッドから呼び出しているので、UIをブロックする可能性がある
class DataRepository(private val apiService: ApiService) {
fun fetchData(): List<DataItem> {
return apiService.getData()
}
}
良い例
明示的にIOスレッドで実行しているので、メインスレッド=UIをブロックする可能性がない。
あと、その処理に最適化されているスレッドを適切に呼び出している(今回でいえばネットワーク系の処理をIOスレッドから呼び出す)
class DataRepository(private val apiService: ApiService) {
suspend fun fetchData(): List<DataItem> = withContext(Dispatchers.IO) {
apiService.getData()
}
}
データは最新のものを表示するようにしつつ、オフラインでも使えるようにしよう
これを実現するには以下の三つの要素が必要だろう
- オフラインでも動作させるためのローカルデータベース
- オンラインに復帰した時に最新のデータを画面に反映するためのLiveData
- ネットワークが不安定な時でもアプリがクラッシュしないような例外処理
ネットワークの状態によって処理を分ける例
ネットワーク状態のチェック関数
fun isNetworkAvailable(context: Context): Boolean {
val connectivityManager =
context.getSystemService(Context.CONNECTIVITY_SERVICE) as ConnectivityManager
val networkInfo = connectivityManager.activeNetworkInfo
return networkInfo != null && networkInfo.isConnected
}
上記の処理を利用してネットワークの状態によって処理を分けるようにしたレポジトリ
suspend fun refreshUsers() {
if (isNetworkAvailable(context)) {
// ネットワークからデータ取得処理
} else {
// ネットワークが利用できない場合の処理
}
}
そもそもなぜアーキテクチャが必要なのか
よくアーキテクチャをリファクタリングするときに、影響範囲の広さ、アプリが崩壊するリスク、人材の不足、直接的な金銭メリットの少なさなどの要因によって後回しになっているのを見る。
これは本当に合理的な判断なのだろうか?
Googleによると、優れたアーキテクチャには以下のメリットがある
- アプリ全体の保守性、品質、堅牢性の向上
- アプリのスケーリングが可能になる→チームメンバーを増やして生産性を向上させることを見込める
- 新メンバーが参加した時に、戦力になるまでの時間が短くなる
- テストが簡単になる
- バグが起きた時の、原因把握、修正の時間が短くなる
アーキテクチャへ投資すると、チーム全体の生産性が上がることでコストメリットがあるだけでなく、ユーザー体験の向上などビジネスのコアになりうるメリットもある。
とはいえ
アーキテクチャの刷新を急に始めることはできない。
関係部署に根回ししたり、事前にエンジニアに調査してもらったりする準備時間が必ず必要になる。
参考
もし上司を説得する必要が出てきたときには、このユースケースは役立つかもしれない。
アーキテクチャを整備することで成功した事例が載っているそうだ。
ここからは各レイヤを細かくみていこうと思うが、もはやスクラップではないので記事にまとめる。
乞うご期待。
データレイヤーについて書いた記事はこれ
google推奨Androidアーキテクチャを理解する「データレイヤ」編