QBoostでKaggleのtitanicに挑戦してみる
はじめに
早速ですがみなさん、量子アニーリングってご存知でしょうか?世界は組合せ最適化問題で溢れています。「巡回セールス問題」や「ナップサック問題」は典型的な例です。組合せ最適化では、膨大な選択肢からベストな選択肢を選択する必要があります。下の図が巡回セールスマン問題の一例であり、どの地点をどの順番で回れば最短距離になるかは一種の組合せ最適化問題です。
量子アニーリングは、組合せ最適化問題を効率的に解くことができる手法の1つとして注目されています。アニーリングは日本語では「焼き鈍し」という意味です。金属を高温の状態にして、徐々に温度を下げることで秩序がある構造を作り出す焼き鈍しの技術をコンピュータ上で再現したアルゴリズムとして、SA(シミュレーテッド・アニーリング)と呼ばれるものがあります。量子効果を使ってSAを発展させたものがQA(クオンタム・アニーリング)であり、SAとは計算時間や解の質の面で違いがあると言われています。さらに近年は、GPUを使ったアニーリング技術も登場しています。無料で使えるアニーリングマシンがたくさんあるので、汎用ソルバーとして広く使われるようになる日も遠くないかもしれません。

さて、ここからが本題です。筆者は機械学習初学者のため、取っ掛かりとしてアニーリングを応用したMLを実装してみたいなと考えていました。調べたみたところ、QBoostと呼ばれる手法がありました!QBoostは量子アニーリングを用いたアンサンブル学習の1つです。アンサンブル学習は、弱い学習器を多数用意して、その予測器の各予測結果を組み合わせて最終的な予測結果を求めます。QBoostでは、与えられた学習データに対して最適な学習器の組合せを、量子アニーリングを使って求めます。
今回は練習として、KaggleのtitanicにQBoostを応用してみます!(もし説明の中で間違いがありましたらコメントで教えていただきたいです!勉強させていただきます!)
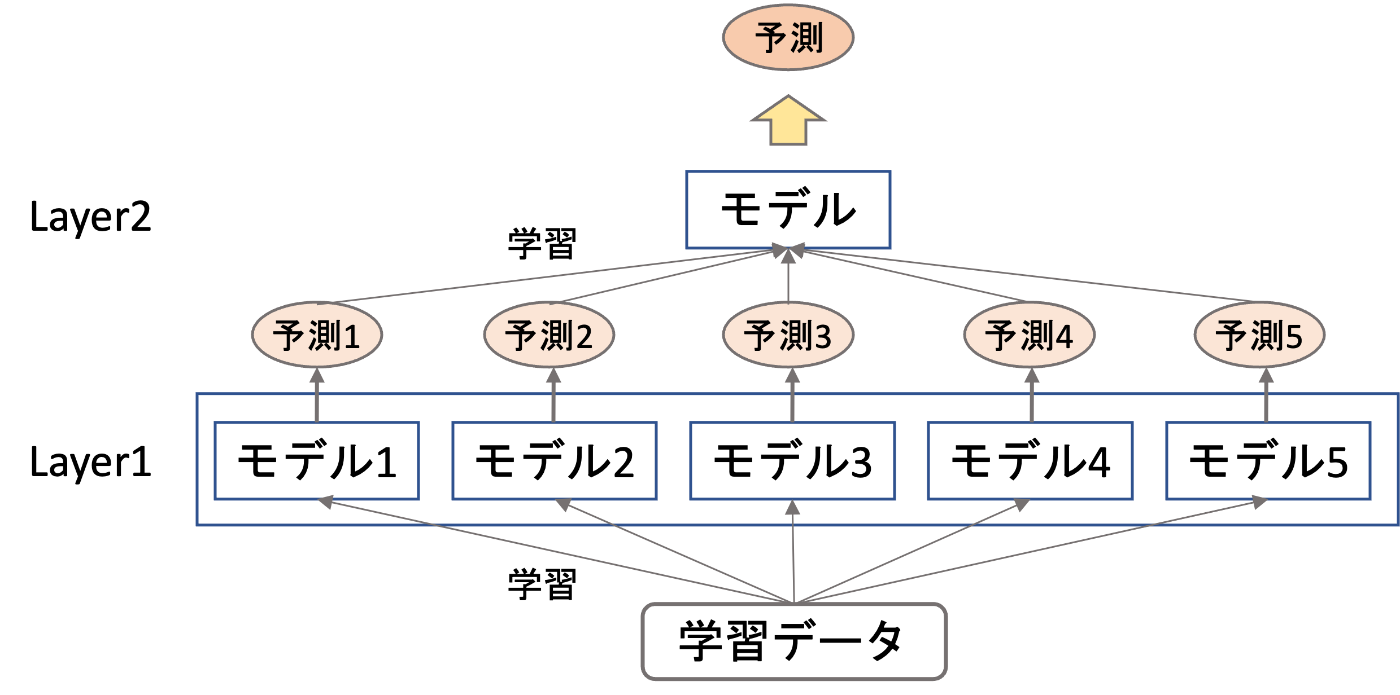
画像出典1, 2
Kaggleのtitanicについて
詳しくまとめられてる方がいらっしゃいましたので、初見の方はこちらをご覧ください。
titanicは与えられた特徴量を使って、乗船客の生存率を予測するコンペです。特徴量には年齢や性別、運賃など数値的なものから、名前やチケット番号など定量的でないものまで含まれています。工夫次第で定量的でないものからも数値的な特徴量を取り出すことができます。例として、姓から家族をグルーピングして、家族の人数を特徴量にされてる方がいらっしゃいました。
QBoostの定式化手法
各弱学習器の予測結果を
式は複雑ですが、PyQUBOというライブラリを利用することで以下のような簡潔なクラスで記述することができます。
from pyqubo import Array, Constraint, Placeholder, solve_qubo
class QBooster():
def __init__(self, y_train, ys_pred):
self.num_clf = ys_pred.shape[0]
# define binary variables
self.Ws = Array.create("weight", shape = self.num_clf, vartype="BINARY")
# set the Hyperparameter size of the normalization term with PyQUBO's Placeholder
self.param_lamda = Placeholder("norm")
# set the Hamiltonian of the combination of weak classifiers
self.H_clf = sum( [ (1/self.num_clf * sum([W*C for W, C in zip(self.Ws, y_clf)])- y_true)**2 for y_true, y_clf in zip(y_train, ys_pred.T)])
# set the Hamiltonian of the normalization term as a constraint
self.H_norm = Constraint(sum([W for W in self.Ws]), "norm")
self.H = self.H_clf + self.H_norm * self.param_lamda
self.model = self.H.compile()
def to_qubo(self, norm_param=1):
self.feed_dict = {'norm': norm_param}
return self.model.to_qubo(feed_dict=self.feed_dict)
第一項目は、弱分類器と正解ラベルの差分を表現しています。第二項目は最終的な分類器に採用する弱分類器の個数の程度を決める正則化項です。このハミルトニアンをアニーリングによって最小化することで最適な弱学習器の組合せを求めていきます。
こちらの記事を参照させていただきましたので、詳しく知りたい方は見ていただければと思います。
データの前処理
本記事のメインではありませんが、学習のために不可欠な工程なので、データの前処理に取り組んで行きます。こちらの記事を踏襲していきます。
まずは欠損値の補完です。年齢と運賃に関しては中央値で補完します。出港地に関してはSで補完します。今回は前処理用のクラスを用意したので、各処理はクラス内メソッドとして実装していきます。
def fillna_by_median(self, column: str):
self.dataset[column].fillna(self.dataset[column].median(), inplace=True)
def fillna_by_specific_value(self, column: str, value):
self.dataset[column].fillna(value, inplace=True)
これらのメソッドを使って以下のようにデータを補完していきます。
preprocessor.fillna_by_median(column="Age")
preprocessor.fillna_by_median(column="Fare")
preprocessor.fillna_by_specific_value(column="Embarked", value="S")
次に、敬称を使って特徴量を作ります。名前から敬称を取り出して、分類していきます。one-hotエンコーディングは最後に実行します。
def create_title(self):
self.dataset['Title'] = self.dataset['Name'].map(lambda x: x.split(', ')[1].split('. ')[0])
self.dataset['Title'].replace(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer', inplace=True)
self.dataset['Title'].replace(['Don', 'Sir', 'the Countess', 'Lady', 'Dona'], 'Royalty', inplace=True)
self.dataset['Title'].replace(['Mme', 'Ms'], 'Mrs', inplace=True)
self.dataset['Title'].replace(['Mlle'], 'Miss', inplace=True)
self.dataset['Title'].replace(['Jonkheer'], 'Master', inplace=True)
最後に、家族ごとにグルーピングをして、家族の人数を特徴量として追加します。
def grouping_familiy(self):
self.dataset['Surname'] = self.dataset['Name'].map(lambda name: name.split(',')[0].strip())
self.dataset['FamilyGroup'] = self.dataset['Surname'].map(self.dataset['Surname'].value_counts())
# Familiy = SibSp + Parch + 1 and then categorize
self.dataset['Family'] = self.dataset['SibSp'] + self.dataset['Parch'] + 1
self.dataset.loc[(self.dataset['Family']>=2) & (self.dataset['Family']<=4), 'FamilyLabel'] = 2
self.dataset.loc[(self.dataset['Family']>=5) & (self.dataset['Family']<=7) | (self.dataset['Family']==1), 'FamilyLabel'] = 1
self.dataset.loc[(self.dataset['Family']>7), 'FamilyLabel'] = 0
最終的に利用するのは以下の特徴量です。one-hotエンコーディングした上で、学習器に渡します。
'Pclass', 'Sex', 'Age', 'Fare', 'Embarked', 'Title', 'FamilyLabel'
まだまだ工夫はできますが、本記事のメインではないので前処理はここまでにします。
普通にアンサンブル学習をしてみる
前処理の結果、計15個の特徴量が作られました。弱学習器なので深さ1の決定木を使います。特徴量は15個の中からランダムに、ランダムに決めた数だけ選択します。今回は使用する特徴量の種類と数が異なる32個の特徴量を用意しました。32個の学習器の予測結果の平均を、最終的な予測結果として利用します。ここで求めた予測精度をベースラインとします。
QBoostで学習器を取捨選択する
さて、先ほどは全ての学習器を使いましたが使わない方がいい学習器も当然あるはずです。ここで組合せ最適化の出番です。各学習器を採用するかしないかを0か1で表して、予測精度が高くなるような学習器の組合せをアニーリングで求めていきます。
各学習器の予測結果と正解ラベルを使って、QUBOを作成します。実際の量子アニーリングマシンを使って解くこともできます。興味がある方はこちらの記事を参照していただければと思います。筆者は無料枠を使い切ってしまったので、今回の記事で扱うのはCPU上で動作するシミュレーテッド・アニーリングです。Openjijという最適化ライブラリを利用していきます。
import openjij as oj
qboost = QBooster(y_train=y, ys_pred=y_pred_list_train)
qubo = qboost.to_qubo(norm_param=2)[0]
sampler = oj.SASampler()
sample_set = sampler.sample_qubo(Q=qubo, num_reads=100, num_sweeps=5000)
solution = sample_set.first.sample
solutionには、各学習器を採用するかしないかを示す0と1の配列が含まれています。1が立っている学習器のみを最終的な予測に反映すれば、予測精度を上げられるという訳です。
性能評価
では実際に予測精度がどの程度向上するかを見ていきます。全ての学習器を使用した場合の精度を基準として、何パーセント精度が向上したかをヒストグラムに示します。これは50回学習と評価を実行した結果です。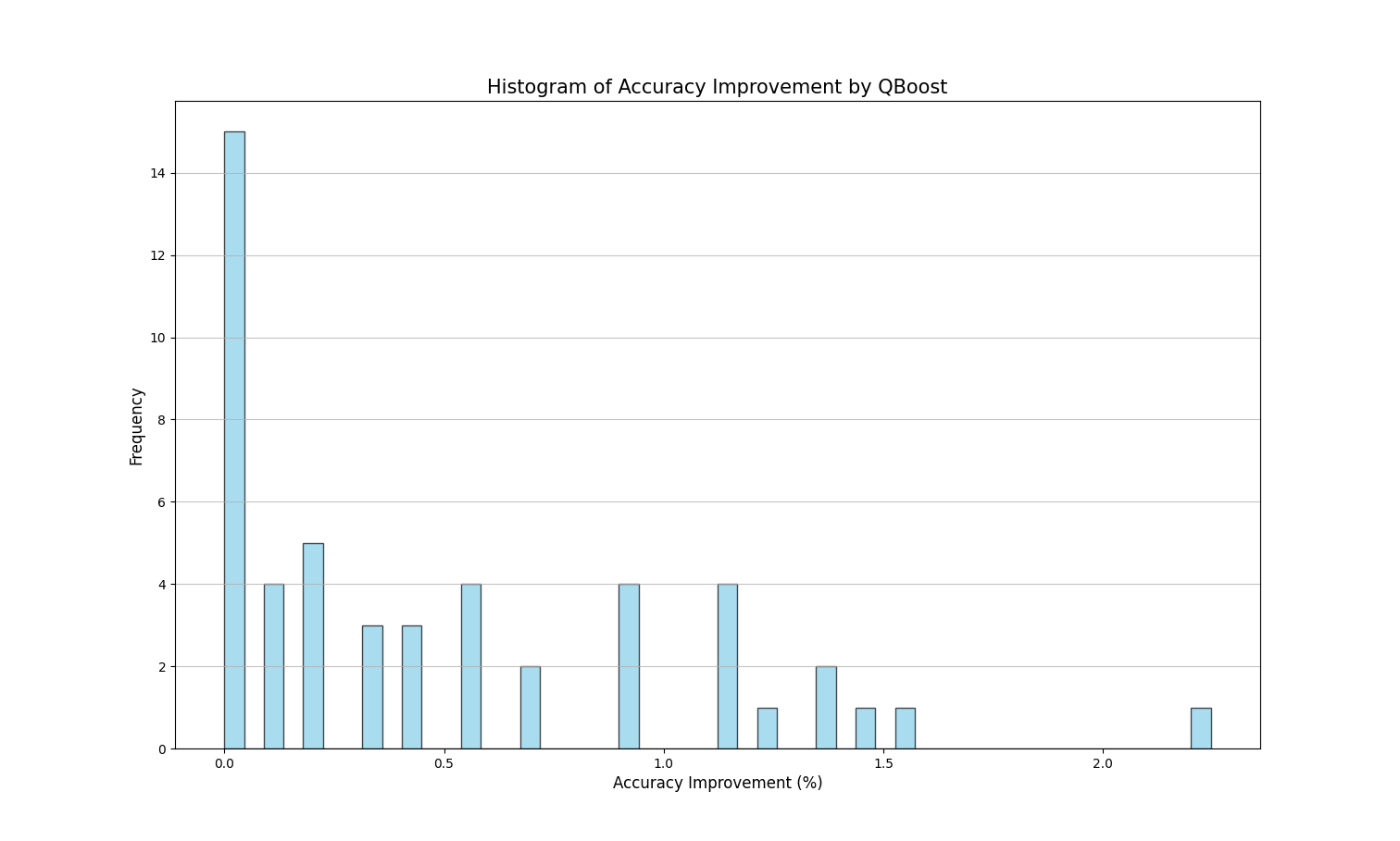
ほとんどのケースで予測精度の向上が見られました。使用する学習器の数は20個程度になりました。予測精度を上げられて、学習器の数も抑えられるのでお得ですね。
訓練データでは80%前後、テストデータでは77%前後の精度が得られました。現状では他のブースティングアルゴリズムに軍配が上がりそうですね。QBoostを使うなら、前後の処理を工夫する必要がありそうです。今後の課題とさせてください!
最後に
少し機械学習を触ってみて、研究開発されてきた最適化アルゴリズムの多様さに感動しました。用途に応じて使い分ける必要があり、データサイエンスの難しさと面白さを感じることができました。一方で、まだまだ開拓されていない分野があることも事実だと思います。量子アニーリングだけでも、色々な応用方法を思い付きます。データ数が増えたときの計算時間の感覚がまだ掴めていないので確証は持てませんが、量子アニーリングが活躍する場面がたくさんありそう?で少しワクワクしました。
次は大規模なデータセットに量子アニーリングを応用した記事を書いてみようと思います。機械学習もアニーリングもまだまだ勉強中なので、厳しいコメントお待ちしております!
ソースコードはこちらに公開しているので試されてい方はどうぞ
Discussion