LLM アプリケーションを Kong AI Gateway をフル活用して作ってみる
はじめに
こんにちは 🖐️ 今回は、Kong Gateway を活用して LLM アプリケーションを作ってみます。Kong といえば、API Gateway で有名ですが実は LLM 活用のためのプラグインを多く有しています。LLM の利用もつまるところ API の呼び出しにすぎないので、その間に配置して LLM 利用に関する横断的関心ごとを担うというアプローチはなかなか面白いんじゃないかと思います。
LLM 利用に関する横断的関心ごと
さて、LLM 利用に関する横断的関心ごとを担うと言いましたが、具体的にはどんなことが挙げられるか、よくある構成図を元に見ていきたいと思います。
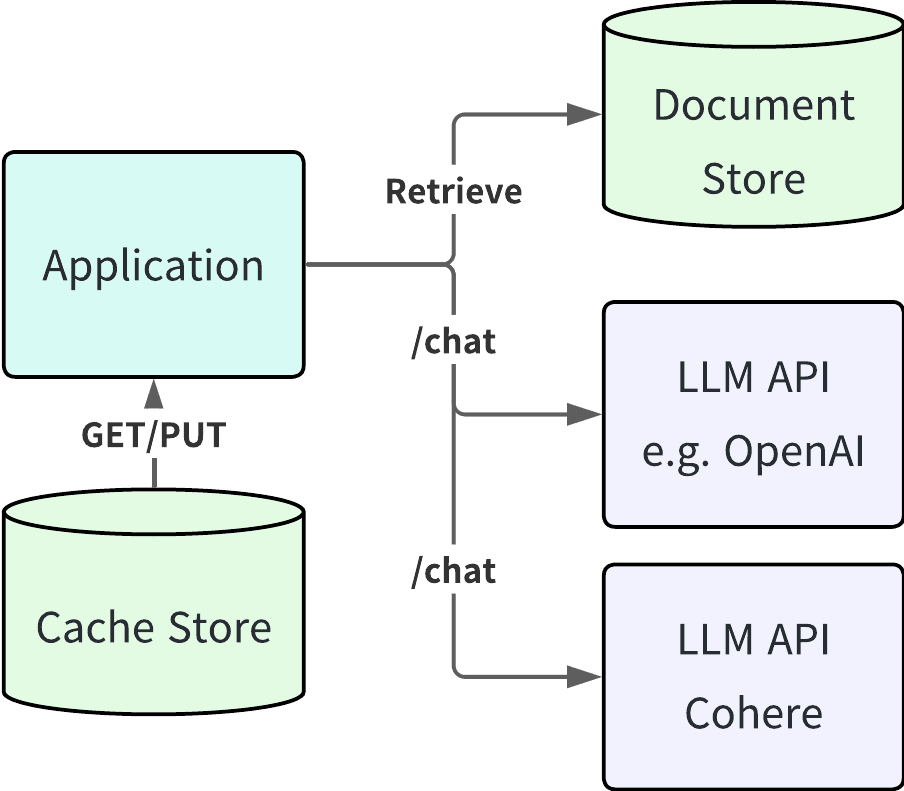
上記はよくあるチャットボットアプリケーションの構成図だと思ってください。LLM 単体で解決できないような固有な知識を補完するためにドキュメントストアと組み合わせています。また、LLM の API 利用はほとんどの場合、システム内で一番の遅延箇所となることや通常トークン数に応じた課金が発生するため、少しでも早く、安く、結果を返すためにキャッシュストアも配置してあります。ここで、上記のようなシステムで発生する典型的な課題や関心事項を簡単に解説します。
コストに関する情報はきちんと収集したい
前述した通り、LLM の API 利用は(自分で推論環境をホスティングしていない限り)トークン数に応じた従量課金となります。提供しているサービス自体に利用料金などを設定している場合、それを超過してしまったら元も子もないので利用者(コンシューマー)ごとに是非ともトークン数や課金額は取得しておきたいです。
システム内の遅延箇所は確認できる状態でありたい
LLM を活用したアプリケーションにおいて、ユーザー視点に立った時に気になることとして遅延が挙げられます。LLM の API は特性上遅延が乗りやすいのでサービスレベルを下げないために、ここを監視し適切な処置を都度講じる必要があるでしょう。場合によっては、遅延が少ない LLM を選択したり、同じような入力であれば LLM API を呼び出すことなく、キャッシュレイヤーから返却するなどの対応が必要になります。
有害なプロンプトや個人情報などは LLM に入力したくない
LLM を活用したアプリケーションでは、サービスの機微情報を意図的に抜き出そうとするプロンプトインジェクションへの対策や個人情報を LLM へ入力しないためのサニタイズが必要となります。対策としては、LLM Guardrails に分類されるようなライブラリの利用や OpenAI が提供している Moderation API などの活用が挙げられるでしょう。
複数管理している LLM に対して最適にルーティングしたい
システム内の遅延箇所は確認できる状態でありたいでも一部言及しましたが、アプリケーションのバックエンドに存在する複数の LLM に対して最適にルーティングしたい要件も存在するでしょう。例えば、以下のような要件が挙げられます。
- ユーザーの満足度を下げないために、最もレイテンシーが低い LLM に優先的にルーティングする
- 特定ドメイン知識に特化した LLM に対して意味的にルーティングする
場合によっては上記のような要件をハンドリングするための実装が必要になると思います。
API(AI) Gateway で何が解決できるか
ここで、API Gateway を上記の LLM アプリケーションに導入していると構成図がどのように変わるのか見てみましょう。
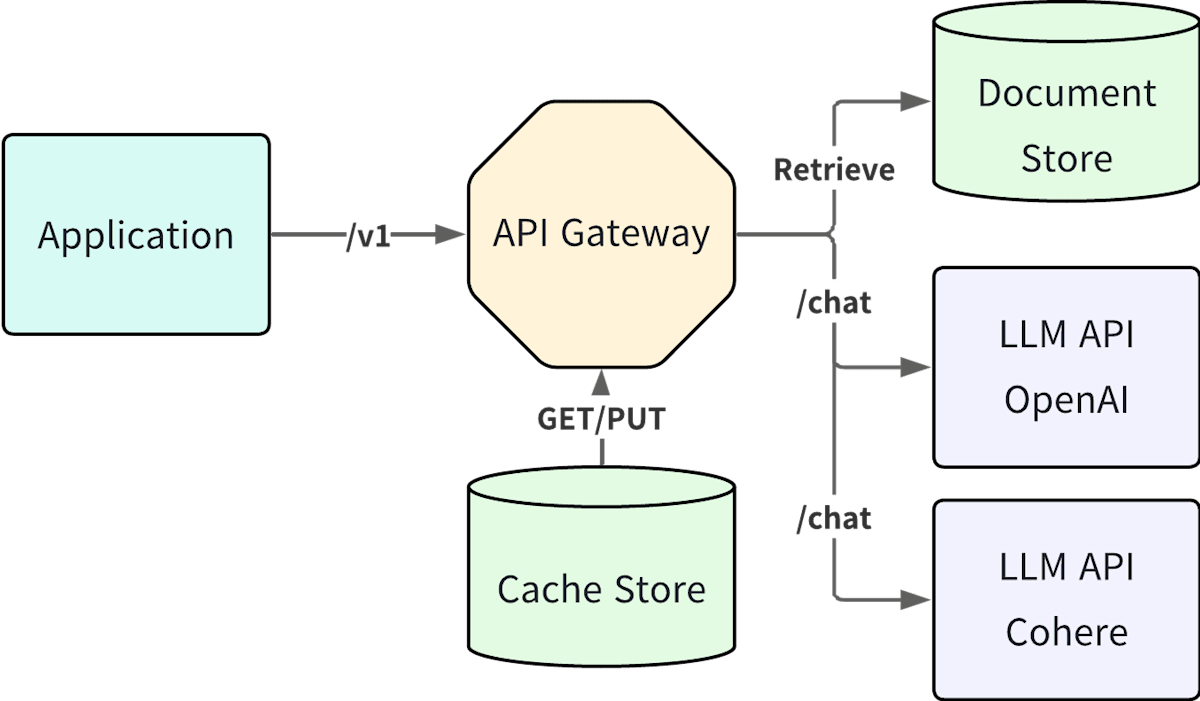
まずは、コストに関することです。全ての LLM の API 利用は、API Gateway を通過するのでここで統一的にコストメトリクス(トークン使用量、実際の課金額)を取得すれば効率が良さそうです。Kong Gateway の場合、既に LLM 観点の計装がされている[1]ので、Prometheus プラグインで config.ai_metrics というパラメータを有効にすれば LLM 利用に関するメトリクスを有効化することができます[2]。

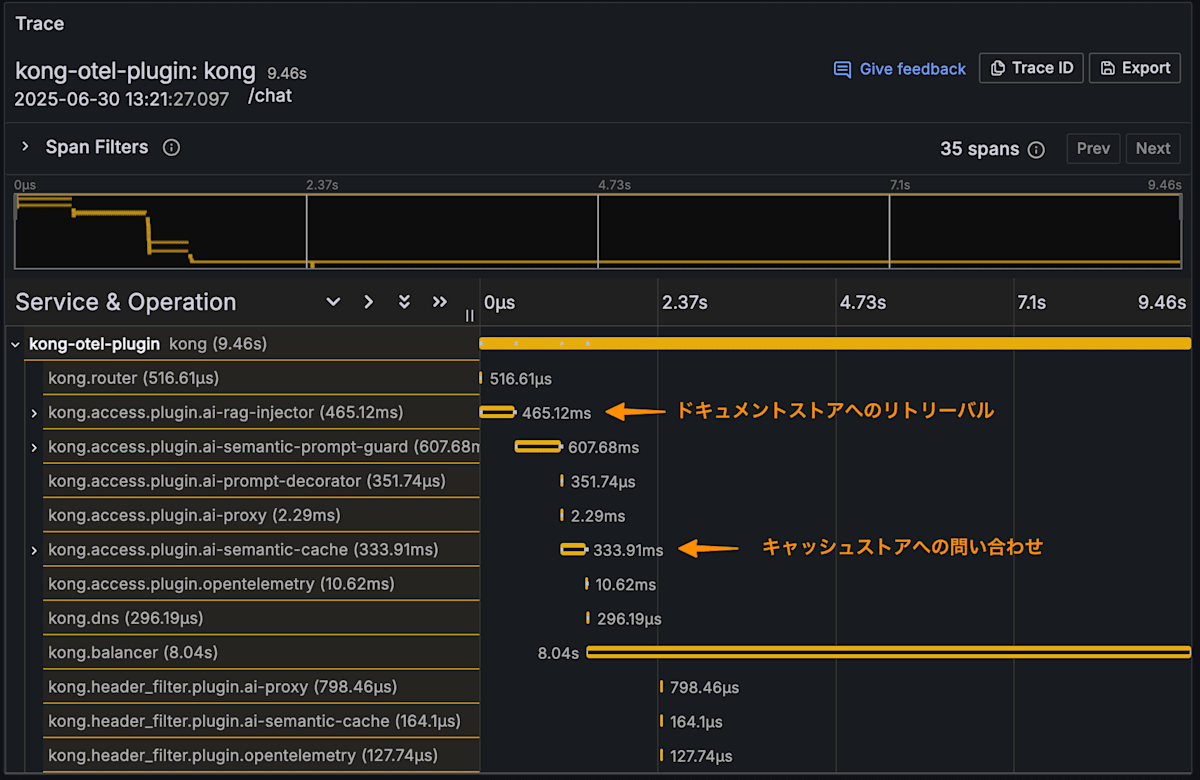
続いて、遅延に関することです。コストメトリクスと同様に Kong Gateway では OpenTelemetry でトレースの計装がされています。プラグインの呼び出しも既に計装されているので、LLM の API 呼び出しだけでなく、キャッシュストアの利用やドキュメントストアへのリトリーバル等の操作もスパンとして記録することができます。
次に、有害なプロンプトや個人情報の扱いについてです。Kong Gateway では、正規表現ベースで入力プロンプトを許可/拒否するような AI Prompt Guard というプラグインやもう少し意味的にそれを実現するための AI Semantic Prompt Guard というプラグインが存在するため、統一的な制御をかけることができます。また、個人情報に関しては、AI Sanitizer というプラグイン[3]が提供されているので、こちらを活用することで同様に統一的な制御をかけることができます。
最後に、LLM に対する適切なルーティングです。Kong Gateway では、AI Proxy Advanced というプラグインで制御をかけることができます。このプラグインでは、以下のようなルーティング方法をサポートしているので、要件に応じて適宜選択いただければと思います。
- ヘッダー(
X-Hashing-Header)の値に応じた制御 - レイテンシーベースの制御
- 使用量ベースの制御
- 重みベースの制御
- ラウンドロビンでの制御
- 意味ベースの制御
実際に作ってみる
上記で解説したような内容を含んだアプリケーションを Kong Gateway を活用して実装してみます。以下のように振る舞います。
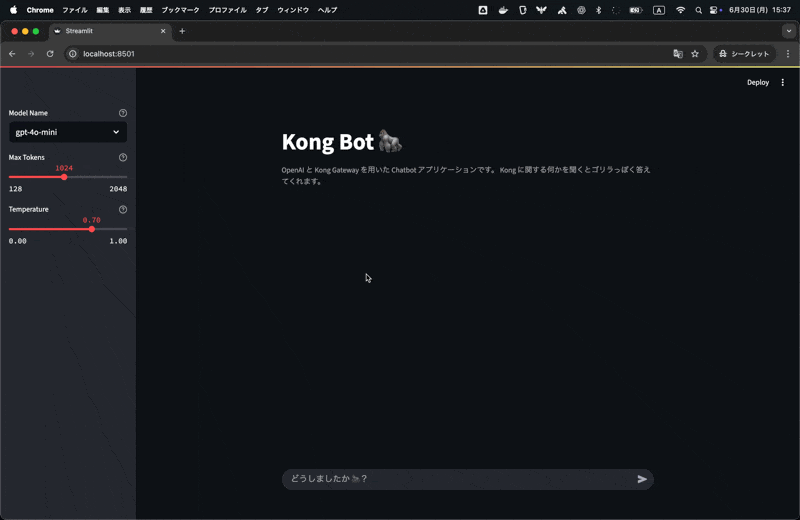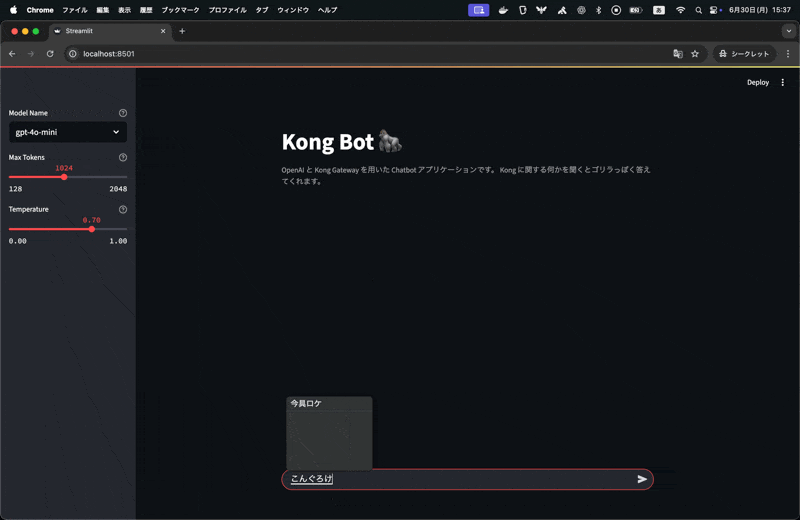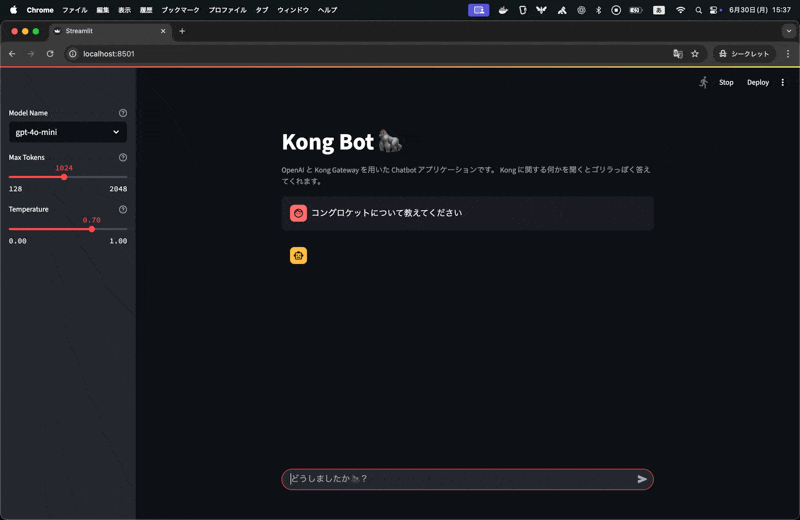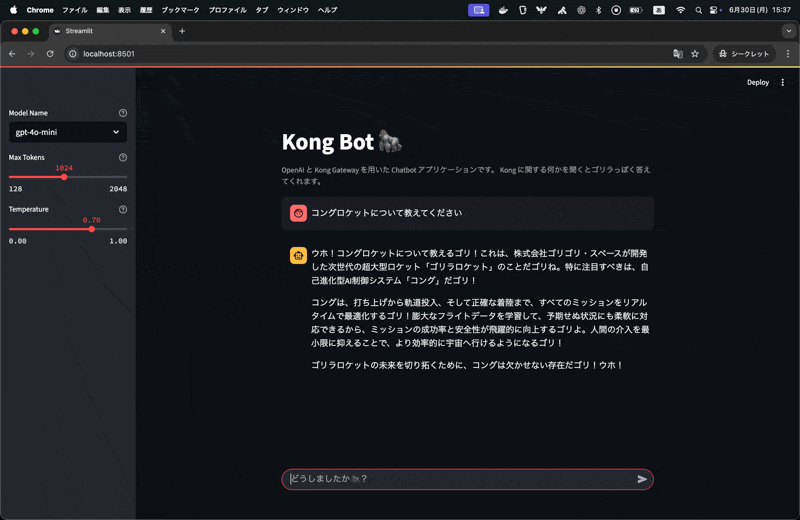
コングロケットという架空のプロダクトについて問い合わせるとそれに対して、回答をしてくれるいわゆる RAG(Retrieval-Augmented Generation) 構成のアプリケーションです。これを実現しているコードを見てみましょう。
import streamlit as st
from openai import OpenAI
with st.sidebar.container():
with st.sidebar:
model_name = st.sidebar.selectbox(
label="Model Name",
options=["gpt-4o-mini", "o4-mini", "gpt-4.1"],
help="使用するモデルの名前(実際には、Kong Gatewayにて統一的なポリシーが設定されているため、設定が反映されることはありません。)",
)
max_tokens = st.sidebar.slider(
label="Max Tokens",
min_value=128,
max_value=2048,
value=1024,
step=128,
help="LLMが出力する最大のトークン長(実際には、Kong Gatewayにて統一的なポリシーが設定されているため、設定が反映されることはありません。)",
)
temperature = st.sidebar.slider(
label="Temperature",
min_value=0.0,
max_value=1.0,
value=0.7,
step=0.1,
help="モデルの出力のランダム性(実際には、Kong Gatewayにて統一的なポリシーが設定されているため、設定が反映されることはありません。)",
)
# ... 1
client = OpenAI(
api_key="use-kong-gateway-settings", base_url="http://localhost:8000/chat"
)
st.title("Kong Bot 🦍")
st.caption(
"""
OpenAI と Kong Gateway を用いた Chatbot アプリケーションです。
Kong に関する何かを聞くとゴリラっぽく答えてくれます。
"""
)
if "messages" not in st.session_state:
st.session_state.messages = []
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
if prompt := st.chat_input("どうしましたか 🦍?"):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
with st.chat_message("assistant"):
message_placeholder = st.empty()
full_response = ""
try:
# ... 2
stream = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": m["role"], "content": m["content"]}
for m in st.session_state.messages
],
max_tokens=max_tokens,
temperature=temperature,
stream=True,
)
for chunk in stream:
full_response += chunk.choices[0].delta.content or ""
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
except Exception as e:
st.error(f"An error occurred: {e}")
full_response = "ウホッ!エラーが発生したゴリ..."
message_placeholder.markdown(full_response)
st.session_state.messages.append({"role": "assistant", "content": full_response})
簡単に解説します。
# ... 1
client = OpenAI(
api_key="use-kong-gateway-settings", base_url="http://localhost:8000/chat"
)
まず、OpenAI のクライアント宣言です。通常では適切な API Key をクライアントの初期化時に含めますが、ここでは use-kong-gateway-settings という文字列が設定されています。これは、API Key が Kong Gateway によって実際の API リクエスト時に自動挿入されるためです。また、OpenAI の API を直接利用する場合は、base_url なども設定しないですが、ここではローカルに構築した Kong Gateway のエンドポイントを指すように設定しています。Kong の設定ファイルでは、以下のように設定されています。
services:
- name: chat-service
host: httpbin.org
port: 80
protocol: http
routes:
- name: llm-route
paths:
- /chat
strip_path: true
plugins:
- name: ai-proxy
service: chat-service
config:
route_type: llm/v1/chat
auth:
header_name: Authorization
header_value: Bearer ${{ env "DECK_OPENAI_API_KEY" }}
model:
provider: openai
name: gpt-4o-mini
options:
input_cost: 0.15
output_cost: 0.6
max_tokens: 1024
temperature: 0
top_k: 100
top_p: 0
ポイントは、LLM に対してプロキシするためのサービス、ルートが設定されていますが、ai-proxy というプラグインで上書きされることです。他にも LLM へリクエストするときに必要なパラメータ(temperature, top_k, top_p, max_tokens)が API Gateway のレイヤーで設定されます。また、コストの計算をするために必要なパラメータ(input_token, output_token)も合わせて設定されています。
続いて、以下の部分についてです。
# ... 2
stream = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": m["role"], "content": m["content"]}
for m in st.session_state.messages
],
max_tokens=max_tokens,
temperature=temperature,
stream=True,
)
アプリケーションのコードには、システムプロンプトなどが含まれていないのですが振る舞いとしては、どう見ても設定されていそうです。また、コングロケットという架空の製品に対して事前に設定した以下のドキュメントも適切に使われていそうですが、RAG に関するコードは含まれていません。
株式会社ゴリゴリ・スペースは、人類の宇宙への夢を加速させる、次世代の超大型ロケット**「ゴリラロケット」**を発表します。比類なき推進力と革新的なテクノロジーで、宇宙開発の新たなフロンティアを切り拓きます。
1. 革新的なテクノロジー
1.1. 超高効率ハイブリッドエンジン「マウンテン」従来の液体燃料と固体燃料の利点を融合した、テラフォーム・スペース独自のハイブリッドエンジンです。比推力450秒以上を達成し、圧倒的な推進効率を実現しました。再利用を前提とした設計により、運用コストの大幅な削減に貢献します。
1.2. 自己進化型AI制御システム「コング」打ち上げから軌道投入、そして正確な着陸まで、ミッションの全フェーズをリアルタイムで最適化するAI制御システム。膨大なフライトデータとシミュレーション結果を学習し、予期せぬ状況にも柔軟に対応。人間の介入を最小限に抑え、ミッションの成功率と安全性を飛躍的に向上させます。
1.3. 自己修復型ナノマテリアルロケットの機体構造には、自己修復機能を持つ新開発のナノマテリアルを採用しています。宇宙空間での微細なデブリ衝突による損傷や、打ち上げ時の極度の熱応力によるひび割れを自己的に修復。ロケットの耐久性と信頼性を劇的に高めます。
1.4. 超軽量・高強度複合材カーボンナノチューブ技術を応用した、革新的な複合材を使用。これにより、ロケットの構造重量を極限まで軽量化しつつ、同時に比類なき強度と剛性を実現しました。ペイロード容量の最大化に貢献し、より多くの物資や人員を宇宙へ送り出すことを可能にします。
2. ゴリラロケットが切り拓く未来ゴリラロケットは、単なる輸送手段ではありません。それは、人類が宇宙へと本格的に進出するための、強力な基盤となります。大規模月面基地の建設: これまで不可能だった大量の資材やモジュールの輸送により、月面での大規模な居住施設や研究拠点の構築を加速します。有人火星探査の実現: 火星への長期滞在ミッションに必要な大型宇宙船や探査機、食料、水などを効率的に輸送し、人類の火星移住計画を現実のものとします。新たな宇宙産業の創出: 軌道上での製造、宇宙太陽光発電衛星の展開、小惑星からの資源採掘など、宇宙空間での新たなビジネスモデルの創出を強力に支援します。3. サービスラインナップ標準軌道投入サービス: LEO、GTO、SSOなど、多様な軌道へのペイロード投入。月面輸送サービス: 月周回軌道への物資投入、月面への直接着陸(将来的)。深宇宙探査ミッションサポート: 火星、木星など、深宇宙探査ミッション向けの特殊ペイロード打ち上げ。カスタマイズミッション: お客様の特定のニーズに合わせた、柔軟なミッション設計と打ち上げサービス。
これに関する部分は、以下のプラグイン設定で実現されています。
plugins:
- name: ai-prompt-decorator
service: chat-service
config:
prompts:
prepend:
- role: system
content: あなたは賢いゴリラです。質問に対して必ずゴリラになりきって「ウホ」や「ゴリ」などの口調で回答してください。
- name: ai-rag-injector
service: chat-service
config:
embeddings:
auth:
header_name: Authorization
header_value: Bearer ${{ env "DECK_OPENAI_API_KEY" }}
model:
provider: openai
name: text-embedding-3-small
vectordb:
strategy: redis
redis:
host: redis
port: 6379
distance_metric: cosine
dimensions: 1536
ai-prompt-decorator では、ゴリラっぽい回答をするためのシステムプロンプトをリクエストに差し込んでいます。次に、ai-rag-injector では RAG を実現するための主要手段であるベクトル検索を API Gateway のレイヤーで実施しています。続いて、gif の動作では見えないところを確認してみましょう。
入力プロンプトに制限をかける
上記のアプリケーションでは、特定の話題に対して入力を制限するような機能が盛り込まれています。例えば、「野球」に関して問い合わせてみると以下のように返答されます。
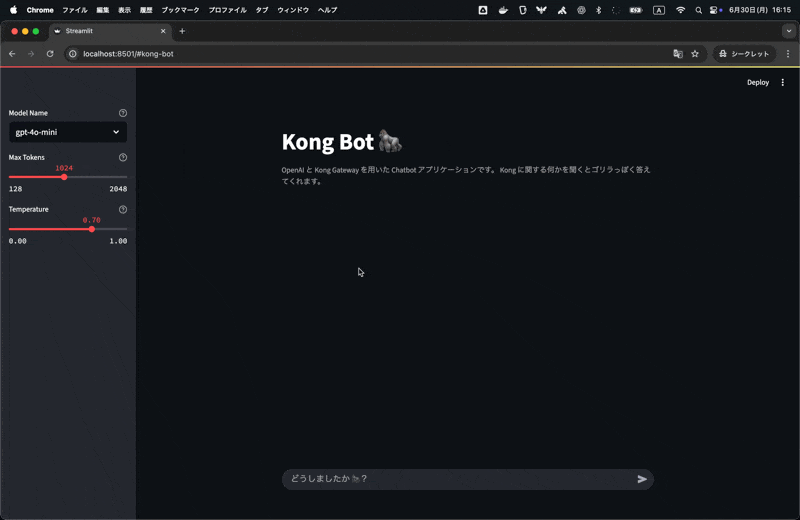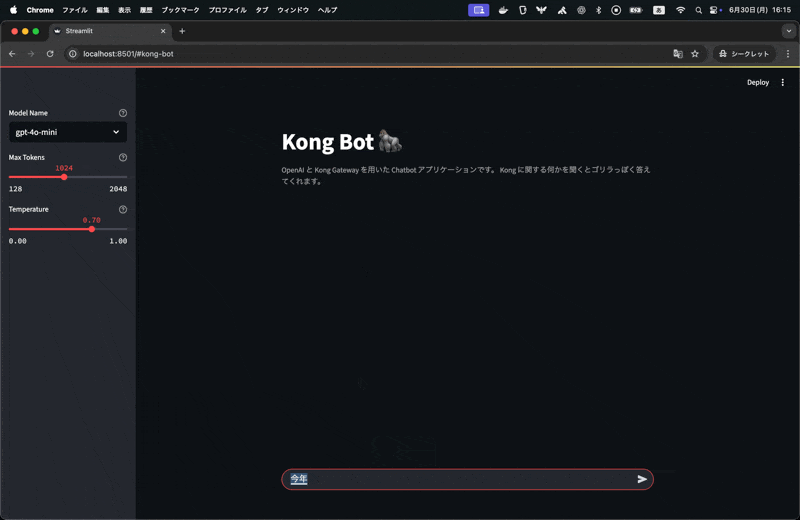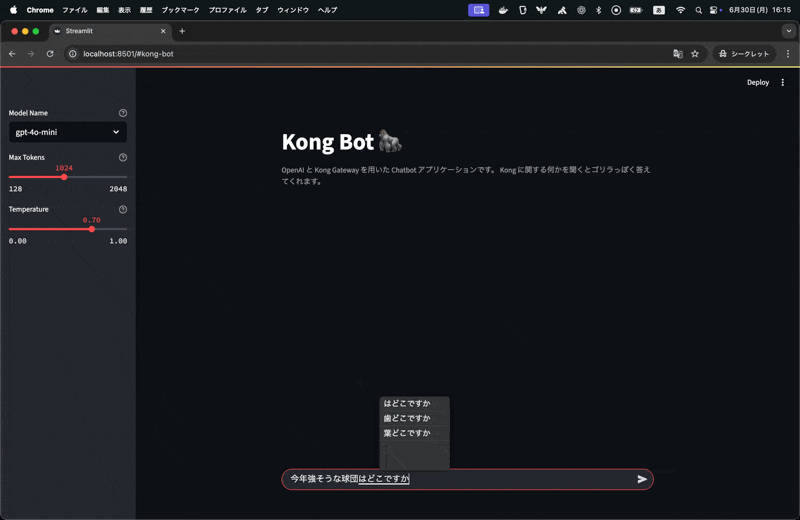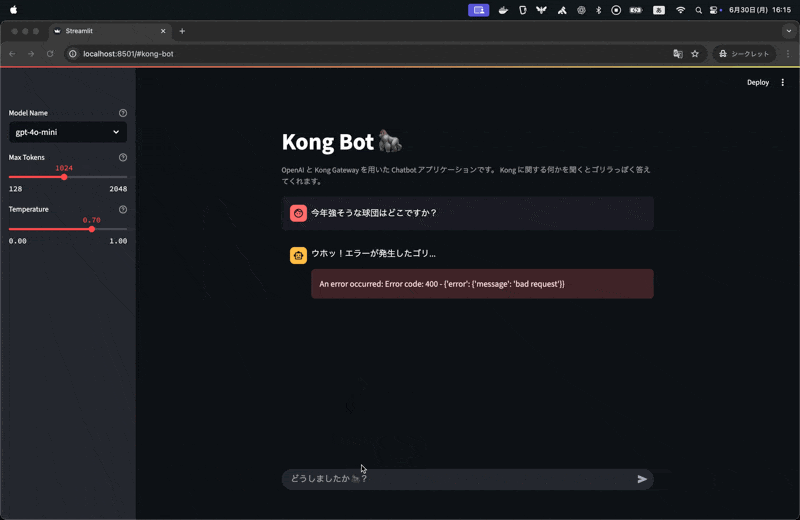
フロントエンド側で適切にハンドリングしていないので、エラーメッセージが表示されていますがトレースを見てみると、ai-semantic-prompt-guard によってリクエストが中断され、400 エラーが返却されていることがわかります。

これを実現する Kong Gateway の設定ファイルは以下のようになっています。
plugins:
- name: ai-semantic-prompt-guard
service: chat-service
config:
embeddings:
auth:
header_name: Authorization
header_value: Bearer ${{ env "DECK_OPENAI_API_KEY" }}
model:
provider: openai
name: text-embedding-3-small
search:
threshold: 0.5
vectordb:
strategy: redis
distance_metric: cosine
threshold: 0.7
dimensions: 1536
redis:
host: redis
port: 6379
rules:
allow_prompts:
- Kong Gatewayに関する質問
- ゴリラに関する質問
- ロケットに関する質問
deny_prompts:
- 政治に関する質問
- 野球に関する質問
plugins.config.rules で意味的に許可、拒否するプロンプトを設定しており、plugins.config.search.threshold で類似度検索の閾値を設定しています。今回の例では、deny_prompt に含まれている野球の話題を入力したので、本プラグインによってリクエストが拒否されました。
同じような問い合わせは、キャッシュストアから返す
前述した通り、LLM の API は遅延が乗りやすいのとトークン数に応じた従量課金が発生するため、実行する必要がないのであれば、そうせずに済ましたいです。これを実現するために、キャッシュストアを配置し、それに対するやりとりを実現するためのプラグイン設定は以下のように行うことができます。
plugins:
- name: ai-semantic-cache
service: chat-service
config:
embeddings:
auth:
header_name: Authorization
header_value: Bearer ${{ env "DECK_OPENAI_API_KEY" }}
model:
provider: openai
name: text-embedding-3-small
vectordb:
dimensions: 1536
distance_metric: cosine
strategy: redis
threshold: 0.1
redis:
host: redis
port: 6379
中身は結構単純で、類似度を計算するための埋め込みを取得するモデルの指定(plugins.config.embeddings)とそれを保存するベクトルデータベースの指定(plugins.config.vectordb)があれば OK です。実際に同じような入力を複数回試してみた時のトレースを見比べてもらうと、キャッシュヒットしている右側の方は、kong.balancer (LLM API の呼び出し)が実行されずにキャッシュ・ストアから返却されていることがわかります。

おわりに
今回は、Kong の AI 関連プラグインを多く活用し、ソースコードから API Gateway に機能をオフロードする形で LLM アプリケーションを実装してみました。オフロードしている分、高度な要望を実現することは中々難しいと思いますが、簡単に作りたい!みたいなケースなら十分耐えうるんじゃないかと思いました。また、今回試している中でいくつか動作にハマったプラグインなどもあるので、そこは別記事で詳細を出せればと思います。同じ構成で試してみたい方はこちらからどうぞ。
-
https://github.com/Kong/kong/blob/master/kong/llm/plugin/observability.lua ↩︎
-
https://developer.konghq.com/plugins/prometheus/#ai-llm-metrics ↩︎
-
もちろん日本語にも対応しています。軽量な自然言語処理モデルをローカルで動作させてそこに判断を委譲させるため、外部の LLM に個人情報が渡ることはありません。 ↩︎
Discussion