ディープラーニングで肉体変化のタイムラプスを劇的に見やすくした
はじめに
トレーニー(筋トレを愛している人)の多くが習慣化している「自撮り(肉体)」。トレーニング後にパンプした肉体を撮りためて、後で見返すのが至福のときですよね。さらに、撮りためた画像をタイムラプスのようにアニメーションで表示させたら、より筋肉の成長が手に取るようにわかりますよね!
この記事はディープラーニングを使って、肉体のタイムラプスを劇的に見やすくした話を書いています。
まずは結果から
2017/12~2020/3の体の変化
※データサイズの都合上、画像をクロップ&圧縮しています。
目次
- 1.手作業での補正
- 2.ディープラーニングを用いた自動補正
- 2-1.アノテーションデータ作成
- 2-2.学習
- 2-3.未知画像への適用
- 2-4.後処理
- 2-4-2.オブジェクト分割する
- 2-4-3.クラスタが4つ以上の場合は、面積の大きい順に3つ選択し、残りを破棄する
- 2-4-4.各クラスタの重心を求める
- 2-4-5.各クラスタの重心のx座標が小さい順に並べ替える(右乳首→おへそ→左乳首)
- 2-5.結果
- まとめ
概要
撮りためた画像からタイムラプスの作成を行いました。しかし、画像間のズレが気になるため、手作業で補正を行い、なめらかなタイムラプスを作成しました。さらに、手作業の手間を省くために、ディープラーニングを用いて自動で補正を行いました。
1.手作業での補正
1-1.そのまま表示
とりあえず、そのままの画像を連続で切り替えるだけのタイムラプスを作ってみます。
# opencvでもで動画は作れますが、
# google colabの環境で、discord上で再生できるmp4ファイルを作るためには、
# skvideoを使うやり方が楽ちんでした。
import skvideo.io
def create_video(imgs, out_video_path, size_wh):
video = []
vid_out = skvideo.io.FFmpegWriter(out_video_path,
inputdict={
"-r": "10"
},
outputdict={
"-r": "10"
})
for img in imgs:
img = cv2.resize(img, size_wh)
vid_out.writeFrame(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
vid_out.close()
imgs = load_images("images_dir")
create_video(imgs, "video.mp4", (w,h))
結果は、下記の通りです。

ズレが気になって我が子(肉体)に集中できません。
1-2.位置の固定
なんとかして楽にこのズレを解消したい。身体のどこかに基準点を設けてそれを固定すれば、、、と考えて0.1秒くらいで「乳首」と「おへそ」という解にたどり着きました。
乳首とおへそをどのように固定するかを以下に説明します。
1-2-1.乳首おへそ座標付与ツール
まず、乳首とへそのUV座標を付与するツールを作ります。cvatなどを使っても実現できるかもしれませんが、使いこなすまでの時間とツールを自作する時間を見積もると、今回は自作した方が早いという結論になったので作りました。
ツールの仕様は、フォルダを指定すると、画像が連続して表示されるので各画像に対して、乳首とおへその3点をクリックしていき、クリックした座標をcsvファイルに出力する、というものになります。GUIはtkinterを利用しました(ソースはしょっぼいんで省略)。
※後述で利用するディープラーニング用のアノテーションデータの場合は、画像とアノテーションデータが1:1になったほうが取り回しが良いと思います。が今回はさくっと済ませるために作り込みませんでした。
1-2-2.動画作成
乳首とおへその場所は、1枚目の画像に合わせてアフィン変換することにより固定します。
def p3affine_img(img, src_p, dst_p):
h, w, ch = img.shape
pts1 = np.float32([src_p[0],src_p[1],src_p[2]])
pts2 = np.float32([dst_p[0],dst_p[1],dst_p[2]])
M = cv2.getAffineTransform(pts1,pts2)
dst = cv2.warpAffine(img,M,(h, w))
return dst
df = read_annotationd() # 省略
imgs = []
src_p = None
for index, row in df.iterrows():
img = cv2.imread(row.file)
dst_p = [ [row.p1x, row.p1y], # 左乳首
[row.p2x, row.p2y], # 右乳首
[row.p3x, row.p3y]] # おへそ
if src_p is None:
src_p = dst_p
else:
img = p3affine_img(img, dst_p, src_p)
imgs.append(img)
write_video(imgs) # 省略
結果は以下の通りです。

期待通りのタイムラプスを作ることができました、めでたしめでたし。ではありません!
今回座標を付与した枚数は、120枚(期間は2019/9〜2020/3)。しかし手元には2017/12から撮りためた、座標付与していない画像がまだ281枚もあるのです。更に今後数十年に渡って筋トレを行う、つまり数十年に渡って座標を付与し続ければいけないのです。想像しただけでもコルチゾールが分泌されカタボリックに陥ってしまいます。これを解決するために糖質補給して考えました。
そうだ、ジム行こうディープラーニングだ。
2.ディープラーニングを用いた自動補正
「乳首」と「おへそ」の位置推定をするモデルを作ります。これが実現すればあとは先ほどの通りアフィン変換をかけるだけです。乳首とおへその検出には、セグメンテーションタスクとしてアプローチします。姿勢推定のようなキーポイント検出のほうが筋が良さそうですが、個人的にセグメンテーションタスクの経験の方が多いのでそちらをチョイスしました。
データセットは下記のとおりです。2019/9〜2020/3は座標付与済みなのでこれを訓練画像と検証画像に利用して、残りの期間に対して自動的に座標を求めます。
2-1.アノテーションデータ作成
「右乳首」「左乳首」「おへそ」「背景」の4クラス分類で解くことも考えられますが、今回は「右乳首・左乳首・おへそ」「背景」の2クラス分類にしました。3点の検出さえできればルールベースでそれらをクラス分類することは簡単だと考えたからです。
では、早速マスク画像を作ります。先ほど作成した座標データを元に、座標点を少し大きくして1で埋めます。それ以外は背景なので0とします。
for index, row in df.iterrows():
file = row.file
mask = np.zeros((img_h, img_w), dtype=np.uint8)
mask = cv2.circle(mask,(row.p1x, row.p1y,), 15, (1), -1)
mask = cv2.circle(mask,(row.p2x, row.p2y,), 15, (1), -1)
mask = cv2.circle(mask,(row.p3x, row.p3y,), 15, (1), -1)
save_img(mask, row.file) # 省略
視覚的にする(1を白、0を黒にする)と下記のようなデータになります。
これらを肉体画像とペアになるように作ります。
2-2.学習
学習は、DeepLab v3(torchvision)を使いました。120枚の画像を訓練と検証のために8:2になるように分けました。だいぶ枚数は少ないですが、下記の理由より、データ拡張はしませんでした。
- 肉体画像は同じカメラで撮影している
- カメラ姿勢や照明環境が画像間である程度揃っている
ただし、本来はデータ拡張はした方が良いと思います(めんどくさくてしてないだけです)。
class MaskDataset(Dataset):
def __init__(self, imgs_dir, masks_dir, scale=1, transforms=None):
self.imgs_dir = imgs_dir
self.masks_dir = masks_dir
self.imgs = list(sorted(glob.glob(os.path.join(imgs_dir, "*.jpg"))))
self.msks = list(sorted(glob.glob(os.path.join(masks_dir, "*.png"))))
self.transforms = transforms
self.scale = scale
def __len__(self):
return len(self.imgs_dir)
@classmethod
def preprocess(cls, pil_img, scale):
# グレースケールにしても良さそうだけど、めんどうだからしない
# pil_img = pil_img.convert("L")
w, h = pil_img.size
newW, newH = int(scale * w), int(scale * h)
pil_img = pil_img.resize((newW, newH))
img_nd = np.array(pil_img)
if len(img_nd.shape) == 2:
img_nd = np.expand_dims(img_nd, axis=2)
# HWC to CHW
img_trans = img_nd.transpose((2, 0, 1))
if img_trans.max() > 1:
img_trans = img_trans / 255
return img_trans
def __getitem__(self, i):
mask_file = self.msks[i]
img_file = self.imgs[i]
mask = Image.open(mask_file)
img = Image.open(img_file)
img = self.preprocess(img, self.scale)
mask = self.preprocess(mask, self.scale)
item = {"image": torch.from_numpy(img), "mask": torch.from_numpy(mask)}
if self.transforms:
item = self.transforms(item)
return item
from torchvision.models.segmentation.deeplabv3 import DeepLabHead
def create_deeplabv3(num_classes):
model = models.segmentation.deeplabv3_resnet101(pretrained=True, progress=True)
model.classifier = DeepLabHead(2048, num_classes)
# グレースケールにしても良さそうだけど、めんどうだからしない
#model.backbone.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
return model
def train_model(model, criterion, optimizer, dataloaders, device, num_epochs=25, print_freq=1):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_loss = 1e15
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch+1, num_epochs))
print('-' * 10)
loss_history = {"train": [], "val": []}
for phase in ["train", "val"]:
if phase == "train":
model.train()
else:
model.eval()
for sample in tqdm(iter(dataloaders[phase])):
imgs = sample["image"].to(device, dtype=torch.float)
msks = sample["mask"].to(device, dtype=torch.float)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == "train"):
outputs = model(imgs)
loss = criterion(outputs["out"], msks)
if phase == "train":
loss.backward()
optimizer.step()
epoch_loss = np.float(loss.data)
if (epoch + 1) % print_freq == 0:
print("Epoch: [%d/%d], Loss: %.4f" %(epoch+1, num_epochs, epoch_loss))
loss_history[phase].append(epoch_loss)
# deep copy the model
if phase == "val" and epoch_loss < best_loss:
best_loss = epoch_loss
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since
print("Training complete in {:.0f}m {:.0f}s".format(time_elapsed // 60, time_elapsed % 60))
print("Best val Acc: {:4f}".format(best_loss))
model.load_state_dict(best_model_wts)
return model, loss_history
dataset = MaskDataset("images_dir", "masks_dir", 0.5, transforms=None)
# 訓練用と検証用に分ける
val_percent= 0.2
batch_size=4
n_val = int(len(dataset) * val_percent)
n_train = len(dataset) - n_val
train, val = random_split(dataset, [n_train, n_val])
train_loader = DataLoader(train, batch_size=batch_size, shuffle=True, num_workers=8, pin_memory=True, drop_last=True )
val_loader = DataLoader(val, batch_size=batch_size, shuffle=False, num_workers=8, pin_memory=True, drop_last=True )
dataloaders = {"train": train_loader, "val": val_loader}
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# BCEWithLogitsLossを使う際に2値分類だと1と指定
num_classes = 1
model = create_deeplabv3(num_classes)
# pre trained用
#model.load_state_dict(torch.load("model.pth"))
model.to(device)
# 背景が圧倒的に多いのでpos_weightで調整する
criterion = nn.BCEWithLogitsLoss(pos_weight=torch.tensor(10000.0).to(device))
params = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.Adam(params)
total_epoch = 50
model, loss_dict = train_model(model, criterion, optimizer, dataloaders, device, total_epoch)
今回は50エポックほど回すとある程度学習が収束しました。
2-3.未知画像への適用
結果としては、概ね良好で、3点がちゃんと反応していましたが、たまに下記のような結果もありました(ヒートマップ表現)。
当然、左乳首が2つあることはないので、一番右上の小さな点がFalse Positiveです。
ちなみに、False Negativeはありませんでした。
2-4.後処理
先ほどの推論結果から、後処理では以下を行います。
- 各ピクセルの出力値が閾値以下のものは切り捨てる
- オブジェクト分割する
- クラスタが4つ以上の場合は、面積の大きい順に3つ選択し、残りを破棄する
- 各クラスタの重心を求める
- 各クラスタの重心のx座標が小さい順に並べ替える(右乳首→おへそ→左乳首)
2-4-1.各ピクセルの出力値が閾値以下のものは切り捨てる
次の処理のために、明確な確度をもったピクセル以外は切り捨てます。今回の閾値は経験的に、0.995にします。
2-4-2.オブジェクト分割する
オブジェクト分割(クラスタに分ける)には、cv2.connectedComponentsを使います。詳細は、OpenCV - connectedComponents で連結成分のラベリングを行う方法 - pynoteをご参考ください。
2-4-3.クラスタが4つ以上の場合は、面積の大きい順に3つ選択し、残りを破棄する
事例から、乳首とおへそ以外にでたFalse Positiveは面積が小さいことがわかりました。よって、面積の大きい3つを選択することにします。本当はこのような対処はあまり頑健性がない気がしますが、今回はうまくいったので採用します。
2-4-4.各クラスタの重心を求める
各クラスタの重心を求めるのは、cv2.momentsを使います。詳細は、Python+OpenCVで重心を求める - CV画像解析入門をご参考ください。
2-4-5.各クラスタの重心のx座標が小さい順に並べ替える(右乳首→おへそ→左乳首)
アフィン変換する際に点が対応する必要があるため、画像間で乳首とおへその座標順を統一する必要があります。今回の画像は、全て直立して撮ったものであり、横軸方向で乳首→おへそ→乳首が出現することは間違いないため、単純にx座標で並び替えます。
#マスクから3点検出
def triangle_pt(heatmask, thresh=0.995):
mask = heatmask.copy()
# 2-4-1.各ピクセルの出力値が閾値以下のものは切り捨てる
mask[mask>thresh] = 255
mask[mask<=thresh] = 0
mask = mask.astype(np.uint8)
# 2-4-2.オブジェクト分割する
nlabels, labels = cv2.connectedComponents(mask)
pt = []
if nlabels != 4:
# 少ない場合は、何もしない
# 本当は閾値さげてやりたいけど、めんどいので
if nlabels < 4:
return None
# 2-4-3.クラスタが4つ以上の場合は、面積の大きい順に3つ選択し、残りを破棄する
elif nlabels > 4:
sum_px = []
for i in range(1, nlabels):
sum_px.append((labels==i).sum())
# 背景分+1する
indices = [ x+1 for x in np.argsort(-np.array(sum_px))[:3]]
else:
indices = [x for x in range(1, nlabels)]
# 2-4-4.各クラスタの重心を求める
for i in indices:
base = np.zeros_like(mask, dtype=np.uint8)
base[labels==i] = 255
mu = cv2.moments(base, False)
x,y= int(mu["m10"]/mu["m00"]) , int(mu["m01"]/mu["m00"])
pt.append([x,y])
# 2-4-5.各クラスタの重心のx座標が小さい順に並べ替える(右乳首→おへそ→左乳首)
sort_key = lambda v: v[0]
pt.sort(key=sort_key)
return np.array(pt)
def correct_img(model, device, in_dir, out_dir,
draw_heatmap=True, draw_triangle=True, correct=True):
imgs = []
base_3p = None
model.eval()
with torch.no_grad():
imglist = sorted(glob.glob(os.path.join(in_dir, "*.jpg")))
for idx, img_path in enumerate(imglist):
# めんどいのでバッチサイズ1
full_img = Image.open(img_path)
img = torch.from_numpy(BasicDataset.preprocess(full_img, 0.5))
img = img.unsqueeze(0)
img = img.to(device=device, dtype=torch.float32)
output = model(img)["out"]
probs = torch.sigmoid(output)
probs = probs.squeeze(0)
tf = transforms.Compose(
[
transforms.ToPILImage(),
transforms.Resize(full_img.size[0]),
transforms.ToTensor()
]
)
probs = tf(probs.cpu())
full_mask = probs.squeeze().cpu().numpy()
full_img = np.asarray(full_img).astype(np.uint8)
full_img = cv2.cvtColor(full_img, cv2.COLOR_RGB2BGR)
# 三角形
triangle = triangle_pt(full_mask)
if draw_triangle and triangle is not None:
cv2.drawContours(full_img, [triangle], 0, (0, 0, 255), 5)
# ヒートマップ
if draw_heatmap:
full_mask = (full_mask*255).astype(np.uint8)
jet = cv2.applyColorMap(full_mask, cv2.COLORMAP_JET)
alpha = 0.7
full_img = cv2.addWeighted(full_img, alpha, jet, 1 - alpha, 0)
# アフィン変換
if correct:
if base_3p is None and triangle is not None:
base_3p = triangle
elif triangle is not None:
full_img = p3affine_img(full_img, triangle, base_3p)
if out_dir is not None:
cv2.imwrite(os.path.join(out_dir, os.path.basename(img_path)), full_img)
imgs.append(full_img)
return imgs
imgs = correct_img(model, device,
"images_dir", None,
draw_heatmap=False, draw_triangle=False, correct=True)
2-5.結果
補正直前のタイムラプスは下記の通りです。
補正後のタイムラプスは下記の通りです。
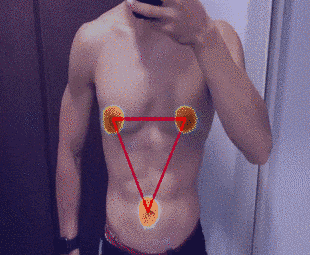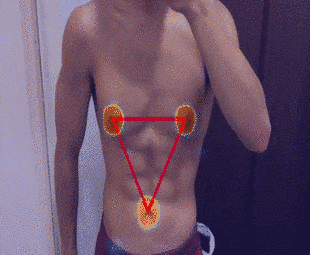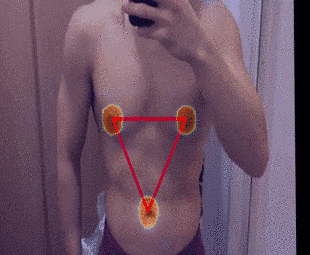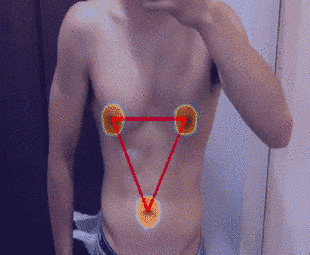
まとめ
ディープラーニングを用いて乳首とおへその検出を行い、自動で画像補正することによって、タイムラプスを劇的に見やすくしました。これでさらにトレーニングに対するモチベーションが上がりました。
当然、**「こんなの非ディープなCVでできんじゃね?」**と思われる方もいると思いますが、私の場合はルールを考える暇があったらバーベルを挙げたいと思ってしまうので力技で解決した感じです。
開発は、座標付与ツールを除いて全部google colabで行いました、3150ぅう!
課題としては、
- 他の人の肉体でうまくいくのかは不明(まあ学習させればいいのですが)
- 全体的に大きくなった場合は非対応(乳首・おへそ以外の基準点が必要)
- 陰影除去
- アプリリリース(これはしたい!!!)
などがありますが、コルチゾールが分泌されるのであまり硬いことは気にしないようにします!
それでは、楽しい筋トレライフを!
Discussion