Polars の maintain_order について
こんにちは!shu421と言います。
Polars Advent Calendar 2023 の 14 日目です。今回は Polars の maintain_order 引数について書きたいと思います。簡単な Tips 的な内容なのでさらっと読んでいただけると嬉しいです。また今回は version 0.19.5 を対象に記事を書きましたが、 Polars はアップデート頻度が多く、仕様がよく変わります。将来的にこの記事とは異なる仕様になる可能性もあるので、最新の仕様は公式ドキュメントを追っていただけると幸いです。
目次
- maintain_order とは
- maintain_order を引数に持つメソッド
- パフォーマンス比較
- まとめ
maintain_order とは
処理前後の順番を保証するための引数です。
maintain_order 引数は複数のメソッドに提供されていますが、例えば group_by の公式ドキュメントには
Ensure that the order of the groups is consistent with the input data. This is slower than a default group by.
と書かれています。group_by の場合、 maintain_order を True とするとグループ化した後の順番を保証しますが、デフォルトのグループ化よりも遅くなります。
maintain_order を引数に持つメソッド
公式ドキュメントによると、maintain_order を引数に持つメソッドは以下の通りです。
- デフォルトが
maintain_order=Truepartition_bypivot
- デフォルトが
maintain_order=Falsebottom_k-
group_by-
groupbyにもmaintain_orderがありますが、version 0.19.0 からはgroupbyは削除されるのでgroup_byを使いましょう。
-
top_kuniqueupsample
抜け漏れがあれば教えてください。ちなみに私は unique に maintain_order があることを知らずにバグらせたことがあります。
パフォーマンス比較
(よく使われていそうな) group_by を対象として、maitain_order が True の場合と False の場合のパフォーマンスを比較してみます。
実験環境は以下の通りです。
- Apple M2 Macbook Air
- メモリ 16GB
- Python 3.10.10
- Polars 0.19.5
- これより新しいバージョンだと私の環境では import 時にカーネルクラッシュします。
データフレームの行数とグループの数を変えて比較
実験は、maintain_order が True の場合と False の場合で、group_by を実行し、それぞれの処理時間を比較します。データフレームの行数は 1,000,000, 10,000,000, 100,000,000 で、グループの数は 100, 1,000, 10,000 です。また、各条件で 10 回実行し、平均を取ります。
実験コード
import polars as pl
import numpy as np
import time
from tqdm.notebook import tqdm
import matplotlib.pyplot as plt
plt.style.use("ggplot")
# Parameters for testing
data_sizes = [1_000_000, 10_000_000, 100_000_000]
group_sizes = [100, 1_000, 10_000]
num_runs = 10
# Store the results
results = []
for data_size in data_sizes:
for group_size in group_sizes:
time_sum_true = 0
time_sum_false = 0
for _ in tqdm(range(num_runs)):
np.random.seed(0)
# Generate dataset
df = pl.DataFrame({
"group": np.random.randint(0, group_size, data_size),
"value": np.random.rand(data_size)
})
# Measure time for maintain_order=True
start_time = time.time()
df.group_by("group", maintain_order=True).mean()
time_sum_true += time.time() - start_time
# Measure time for maintain_order=False
start_time = time.time()
df.group_by("group", maintain_order=False).mean()
time_sum_false += time.time() - start_time
# Calculate average time
avg_time_true = time_sum_true / num_runs
avg_time_false = time_sum_false / num_runs
# Record the results
results.append((data_size, group_size, avg_time_true, avg_time_false))
# Convert results to a DataFrame
result_df = pl.DataFrame(results, schema=["data_size", "group_size", "time_true", "time_false"])
# Plotting
fig, ax = plt.subplots(figsize=(10, 6))
color_map = {100: "r", 1_000: "g", 10_000: "b"}
for group_size in group_sizes:
subset = result_df.filter(pl.col("group_size") == group_size)
ax.plot(subset["data_size"], subset["time_true"], label=f"Group Size {group_size} (True)", color=color_map[group_size])
ax.plot(subset["data_size"], subset["time_false"], label=f"Group Size {group_size} (False)", linestyle="--", color=color_map[group_size])
ax.set_xlabel("Data Size")
ax.set_ylabel("Time (s)")
ax.set_title("Group By Performance")
ax.legend()
plt.show()
実験結果
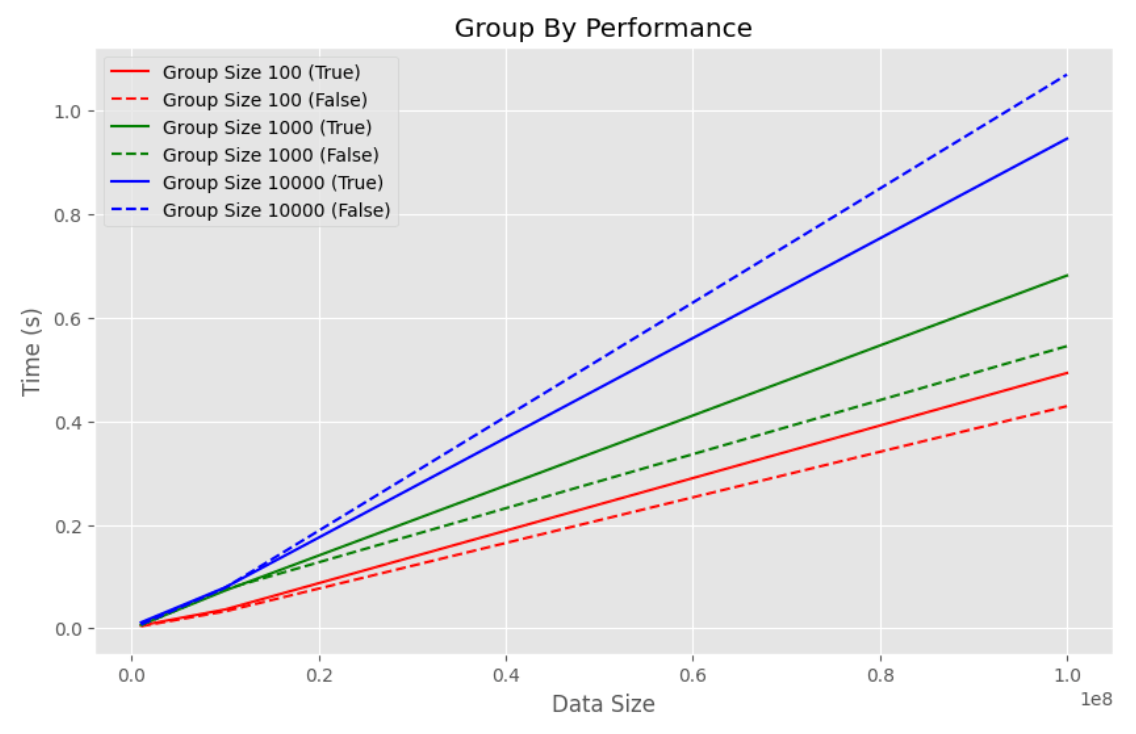
データフレームの行数が増えるとmaintain_order が True 、 False どちらの場合も実行時間は増えますが、大小関係が変わることはありませんでした。一方で、グループの数が増えると maintain_order=False の方が処理が早くなります。
group_by(maitain_order=True) と group_by(maintain_order=False).sort() の処理速度を比較
maintain_order=False を使う場合、処理前後の順番を保証するために group_by と sort を組み合わせて使うことがあります。そこで、group_by(maintain_order=True) と group_by(maintain_order=False).sort() の処理速度を比較してみます。
実験コード
import polars as pl
import numpy as np
import time
from tqdm.notebook import tqdm
import matplotlib.pyplot as plt
plt.style.use("ggplot")
# Parameters for testing
data_sizes = [1_000_000, 10_000_000, 100_000_000]
group_sizes = [10_000, 100_000]
num_runs = 10
# Store the results
results = []
for data_size in data_sizes:
for group_size in group_sizes:
time_sum_true = 0
time_sum_false_sort = 0
for _ in tqdm(range(num_runs)):
np.random.seed(0)
# Generate dataset
df = pl.DataFrame({
"group": np.random.randint(0, group_size, data_size),
"value": np.random.rand(data_size)
})
# Measure time for maintain_order=True
start_time = time.time()
df.group_by("group", maintain_order=True).mean()
time_sum_true += time.time() - start_time
# Measure time for maintain_order=False
start_time = time.time()
df.group_by("group", maintain_order=False).mean().sort("group")
time_sum_false_sort += time.time() - start_time
# Calculate average time
avg_time_true = time_sum_true / num_runs
avg_time_false = time_sum_false_sort / num_runs
# Record the results
results.append((data_size, group_size, avg_time_true, avg_time_false))
# Convert results to a DataFrame
result_df = pl.DataFrame(results, schema=["data_size", "group_size", "time_true", "time_false"])
# Plotting
fig, ax = plt.subplots(figsize=(10, 6))
color_map = {10_000: "b", 100_000: "y"}
for group_size in group_sizes:
subset = result_df.filter(pl.col("group_size") == group_size)
ax.plot(subset["data_size"], subset["time_true"], label=f"Group Size {group_size} (True)", color=color_map[group_size])
ax.plot(subset["data_size"], subset["time_false"], label=f"Group Size {group_size} (False Sort)", linestyle="-.", color=color_map[group_size])
ax.set_xlabel("Data Size")
ax.set_ylabel("Time (s)")
ax.set_title("Group By Performance")
ax.legend()
plt.show()
実験結果
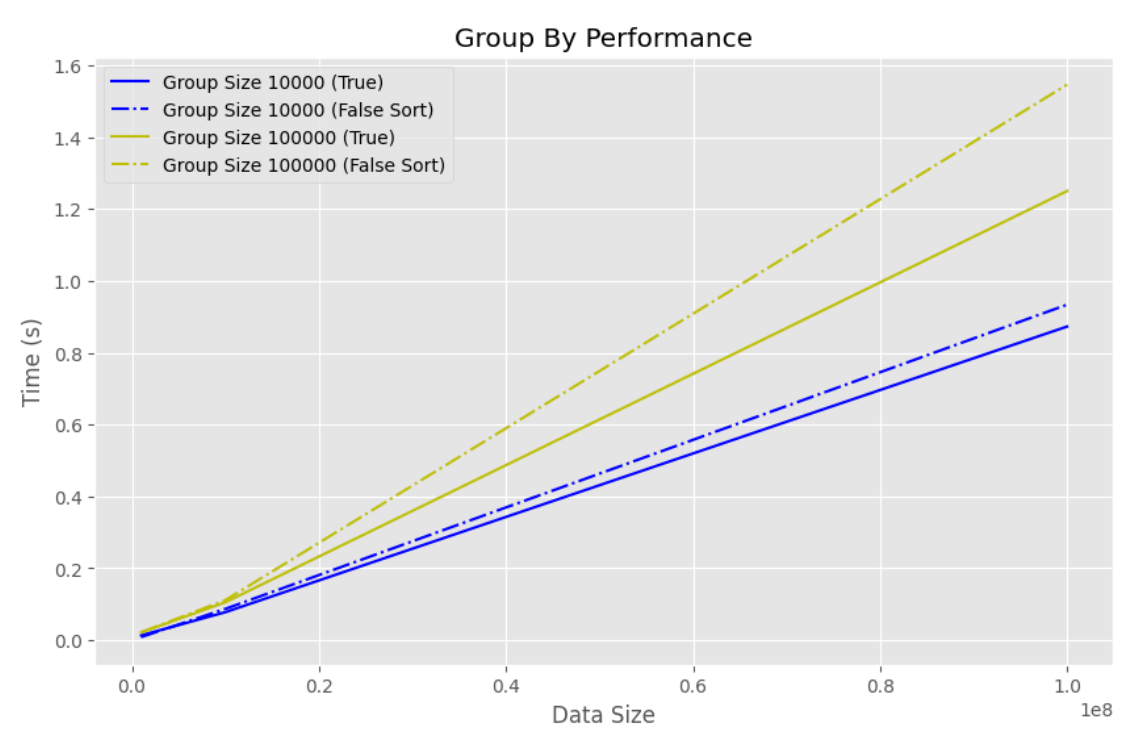
maintain_order=True の方が maintain_order=False と sort を組み合わせた場合よりも処理が早いことがわかりました。この差はグループ数が増えるほど大きくなりそうです。
まとめ
グループ数が多い時は maintain_order=False の方が処理が早くなるためこちらを使用した方が良さそうです。また、処理前後の順序関係を維持したい場合は sort と組み合わせるのではなく、maintain_order=True を使用する方が処理速度が速いためおすすめです。
Discussion