話題のEntropixについて解説!
はじめに
株式会社PrefabでCTOをしているYonemotoです。Entropixのデコーディング方式を動的に変えるという斬新なアイデアがとても興味深かったので記事にしました。確かにそうすればLLMのトークン生成の際に(ざっくりとした表現ですが)自信の有無を出力にうまく反映させることができるだろうと思い、その手があったか!と感動しました。
Entropixの概要
事前学習済みLlamaの推論時において、次のtoken候補それぞれの確率からエントロピーとバレントロピーを定義し、その値によってサンプリング方式を動的に変えることによって精度を向上させたというものです。
背景: 推論時のScaling Lawとサンプリング方式
ChatGPT o1の登場により、学習時から推論時へとScaling Lawの注目が移っています。その中で、サンプリングを複雑にすることは推論をスケールさせる手法の1つです。以下、各種サンプリング方式について説明します。
(画像の出展:各種デコード方式について)
Greedy Decoding
推論の各ステップにおいて、最も確率の高いtokenを選択する手法です。例えば、次の図では、("The", "nice", "woman")が選ばれます。

Beam Search
確率の高いものから上位n個のtokenを選んだ上で、それぞれのtokenからさらに次のtokenを探索し、その確率を掛け合わせたものがn個の中で最も高いものを選択する手法です。例えば、次の図では、n=2において、("The", "nice", "woman")と("The", "dog", "has")の2経路を探索したところ、前者の確率は0.50.4=0.2であり、後者は0.40.9=0.36であるため、Greedy Decodingの時とは違い("The", "dog", "has")が選ばれます。
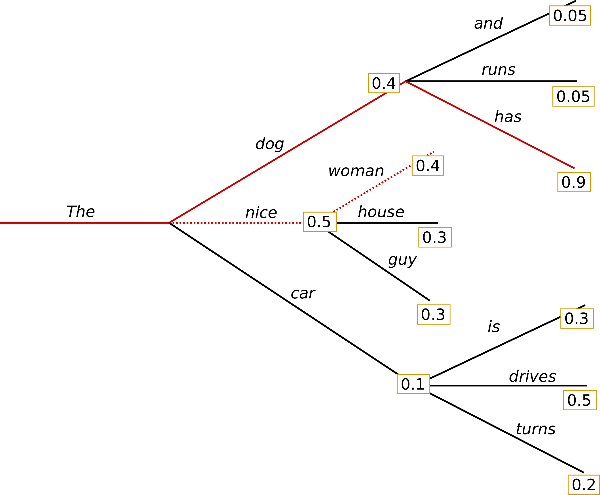
Random Sampling
次のtokenの確率通りにサンプリングし、出力するtokenを選択する方式です。次の3つの概念が関わってきます。
Top p
サンプリングする際、候補を確率の高い上位から累積で確率がpを超えるところまでに限定。
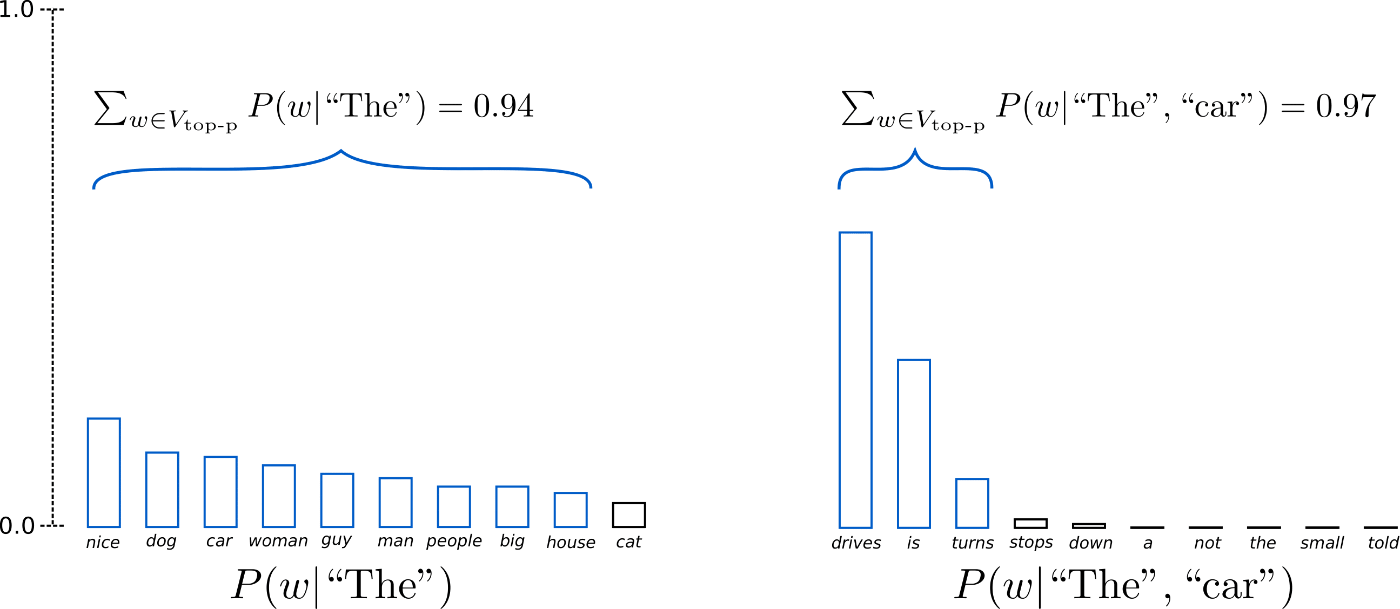
Top k
サンプリングする際、候補を確率の高い上位k個に限定。

Temperature (温度)
生成確率
この数式における
Entropixの手法
さて、ついに本題です。従来のLLMでは、上で紹介したサンプリング方式はユーザーが決定するハイパーパラメータとされていました。実際に、モデルを推論するときには引数としてdo_sample=Trueやtemperature=0.5などをユーザーが入力します。しかし、Entropixではエントロピーおよびバレントロピーを内部で計算し、サンプリング方式を動的に変更します。両者は以下のように計算されます。
エントロピー (Entropy)
ChatGPTによる説明
エントロピーは、確率分布がどれだけ不確実であるかを定量化する指標です。高いエントロピーは多くの可能性が均等にあることを示し、低いエントロピーは特定の結果に集中していることを示します。
バレントロピー (Varentropy)
ChatGPTによる説明
バレントロピーはエントロピーのばらつきを表します。
実装
まず、
def calculate_varentropy_logsoftmax(logits: torch.Tensor, axis: int = -1) -> Tuple[torch.Tensor, torch.Tensor]:
"""Calculate the entropy and varentropy of the probability distribution using logsoftmax."""
log_probs = F.log_softmax(logits, dim=axis)
probs = torch.exp(log_probs)
その後、probsとlog_probsを用いてメトリクスを計算します。
entropy = -torch.sum(probs * log_probs, dim=axis) / LN_2 # Convert to base-2
varentropy = torch.sum(probs * (log_probs / LN_2 + entropy.unsqueeze(-1))**2, dim=axis)
return entropy, varentropy
サンプリング方式の選択
token生成時、2つのメトリクスを計算した後、毎回それらの値に応じて以下の図のようにサンプリング方式を選択し次のtokenを生成します。

(出展:Entorpix GitHub)
- 低エントロピー・低バリエントロピー:「暗黙の意図に従う」
確実な状態。モデルは次のトークンを確定的に選択します。 - 高エントロピー・低バリエントロピー:「慎重に質問する」
不確実だが選択肢は明確。質問トークンを挿入するか、温度を調整して探索します。 - 低エントロピー・高バリエントロピー:「分岐の探索」
選択肢が多く、どの道に進むかを検討。温度とk値(Top-k)を増やして多様なトークンを探索します。 - 高エントロピー・高バリエントロピー:「霧の中で再サンプリング」
不確実で多様な未来を模索。温度をさらに上げ、柔軟なサンプリングを行います。
メトリクスによる場合分けは、sample関数内で以下のように実装されています。なおsample関数は、entropix/entropix/torch_main.pyのgenerate関数から呼び出されて利用されます。
def sample(gen_tokens: torch.Tensor, logits: torch.Tensor, attention_scores: torch.Tensor,
temperature=0.666, top_p=0.90, top_k=27, min_p: float = 0.0,
generator: torch.Generator = torch.Generator(device=device).manual_seed(1337)) -> torch.Tensor:
metrics = calculate_metrics(logits, attention_scores)
ent, vent = metrics["logits_entropy"], metrics["logits_varentropy"]
attn_ent, attn_vent = metrics["attn_entropy"], metrics["attn_varentropy"]
agreement = metrics["agreement"]
interaction_strength = metrics["interaction_strength"]
# Low Entropy, Low Varentropy: "flowing with unspoken intent"
if ent < 0.1 and vent < 0.1:
return torch.argmax(logits[:, -1], dim=-1, keepdim=True).to(torch.int32)
# High Entropy, Low Varentropy: "treading carefully, asking clarifying questions"
elif ent > 3.0 and vent < 0.1:
# Insert a clarifying question token if not already present
if not torch.isin(gen_tokens[:,-1], torch.tensor([2564], device=device)).any():
return torch.tensor([[2564]], dtype=torch.int32, device=device) # Assuming 2564 is our "ask clarifying question" token
else:
# If we've just asked a question, sample with slightly higher temperature
temp_adj = 1.3 + 0.2 * attn_ent # Increase temperature based on attention entropy
return _sample(logits, temperature=min(1.5, temperature * temp_adj), top_p=top_p, top_k=top_k, min_p=min_p, generator=generator)
# Low Entropy, High Varentropy: "exploring forks in the path"
elif ent < 5.0 and vent > 5.0:
temp_adj = 1.2 + 0.3 * interaction_strength # Increase temperature based on interaction strength
top_k_adj = max(5, int(top_k * (1 + 0.5 * (1 - agreement)))) # Increase top_k when agreement is low
return _sample(logits, temperature=min(1.5, temperature * temp_adj), top_p=top_p, top_k=top_k_adj, min_p=min_p, generator=generator)
# High Entropy, High Varentropy: "resampling in the mist"
elif ent > 5.0 and vent > 5.0:
# Use high temperature and adjusted top_p based on attention metrics
temp_adj = 2.0 + 0.5 * attn_vent # Increase temperature based on attention varentropy
top_p_adj = max(0.5, top_p - 0.2 * attn_ent) # Decrease top_p when attention entropy is high
return _sample(logits, temperature=max(2.0, temperature * temp_adj), top_p=top_p_adj, top_k=top_k, min_p=min_p, generator=generator)
# Middle ground: use adaptive sampling
else:
return adaptive_sample(
logits,
metrics,
gen_tokens,
n_samples=5,
base_temp=temperature,
base_top_p=top_p,
base_top_k=top_k,
generator=generator
)
Entropixの今後
リポジトリを3つに
-
entropix-local
・単一の4090 GPUやApple Metalを対象に、小規模モデルでのローカルな研究とテストに特化します。
・"frog" ブランチにあるものより簡易なサンプラーを搭載しますが、研究やプロトタイピングのための優れたテスト環境を提供します。
・専用のUIも構築され、JAX、PyTorch、MLX のフルバージョンもサポートされます。 -
entropix(大規模版)
・8x H100 / TPU v4-16 -> 70BやTPU v4-64 -> 405B向けの推論実装を目指します。
・Anthropic風のチャットUIやプレイグラウンドも提供します。
・TPUにはJAX、GPUにはPyTorchを使用し、展開やシャーディングの複雑さに対応します。
・高度なサンプラー実装が必要で、OpenAI互換のサービングレイヤーも含まれます。 -
entropix-trainier
「登場するかもしれません。」とのことです。
モデルサポートの拡大
- 現在のモデル: llama3.1+
- サポート予定のモデル: DeepSeekV2+ Mistral Large (123B)
おわりに
この手法がマルチモーダルかつ大規模モデルに使われるようになるのが楽しみですね!なにか間違いにお気付きの場合、コメントをいただけますと幸いです。
Discussion