Raspberry Pi 4B + ニューラルネットワーク(CNN)で自動運転を実装してみる
ドイツで自動車のソフトウェアエンジニアリングを学んでる奴 "shogura" です。
「Shaping the Future of mobility, together」を掲げ、自動車に関するソフトウェアエンジニアリングのプログラムを提供しているSEA:MEに参加しています。SEA:MEでは「組み込みシステム」「自動運転」「モビリティエコシステム」の3つのモジュールから自分の興味に合った分野を学習することができます。
本記事では、自動運転モジュールの一環であるPiRacer Standard(Raspberry Pi 4B) + CNNを使用して自動運転を実装するという課題についてどのように実装したのかをお話しします。
完成イメージ

開発環境
OS: Google Colaboratory Pro (Linux Ubuntu 22.04.2 LTS x86_64)
Python: 3.10.12
TensorFlow: 2.13.0
Keras: 2.13.1
Raspberry Pi 4B: 8GB RAM
マップ、コントローラーなどその他周辺機器はこちらのPiRacer AI Kitを使用しました。
実装フロー

モデルを実装するにはある程度のデータセットが必要です。今回走行するマップは実際の路上でないためデータセットがオンラインに落ちていなかったので、1からデータを収集しました。合計で1500枚程度の画像を収集しました。CNNモデルは回帰タイプのモデルではなく画像分類タイプのモデルを実装しています。今回は3つの選択肢を要しており1が左、2が直進、3が右となっています。
1. データセットの収集
1.1 Raspberry Pi 4B セットアップ
PiRacer AI Kitに付属するPi Cameraを通して画像を収集します。画像を撮影する前に必ずカメラのセットアップをRaspberry Pi内で行う必要があります。
sudo raspi-config
Go to Interfacing Options -> Camera -> Yes

Would you like the camera interface to be enabled?” -> YES
Pi Cameraに関するセットアップ方法はこちら↓
1.2 Pythonスクリプト実装
Raspberry PiをJoyStickでコントロールするためのpythonスクリプトを実装します
gamepad_input = gamepad.read_data()にてJoyStickのデータを取得。vehicle.set_throttle_percent()とvehicle.set_steering_percent()にてJoyStickのデータをRaspberry Piに送信します。 THROTTLE_PARAM, STEERING_PARAMは舵角とスロットルを調整するためのパラメータです。
次にPi Cameraから画像を取得して特定のディレクトリに保存するPythonスクリプトを実装します。今回は画像処理にOpenCVを使用しています。
cv2.VideoCapture(0)にてPi Cameraモジュールを取得します。画像を保存する際に以下の命名規則に従って保存します。これは画像名からラベルデータを取得しやすくするための工夫です。DirectionはPiRacerが走行する方向を表しており、1が左、2が直進、3が右となっています。取得が画像数が不十分である場合は画像に変化を加えて水増し(augmentation)するのも良いでしょう。
frame_{Index:04d}_{Direction (1 or 2 or 3):04d}.jpg
# frame_0001_0001.jpg
2. CNNモデル
2.1 CNNとは
CNNとはConvolutional Neural Networkの略でディープラーニングのアルゴリズムの一種です。CNNは特に画像から特徴抽出して違いを見分けるのに長けているアルゴリズムです。CNNは主に「畳み込み層(Convolution Layer)」「プーリング層(Pooling Layer)」「全結合層(Fully Connected Layer)」3つの層から成り立っています。
畳み込み層 Convolution Layer
誤解を恐れずに一言で説明すると畳み込み層の目的は、入力画像からエッジなどの高レベルの特徴を抽出することです。畳み込みニューラルネットワーク(CNN)は、必ず1つの畳み込み層に制限される必要はありません。通常、最初の畳み込み層はエッジ、色、勾配の方向などの低レベルの特徴を捉える役割を担当しています。

上記では、緑のセクションは私たちの5x5x1の入力画像を表しています。畳み込み層の最初の部分での畳み込み操作に関与する要素は、黄色で示されたカーネルと呼ばれます。多くの場合、3x3のカーネル行列が一般的です。
プーリング層 Pooling Layer
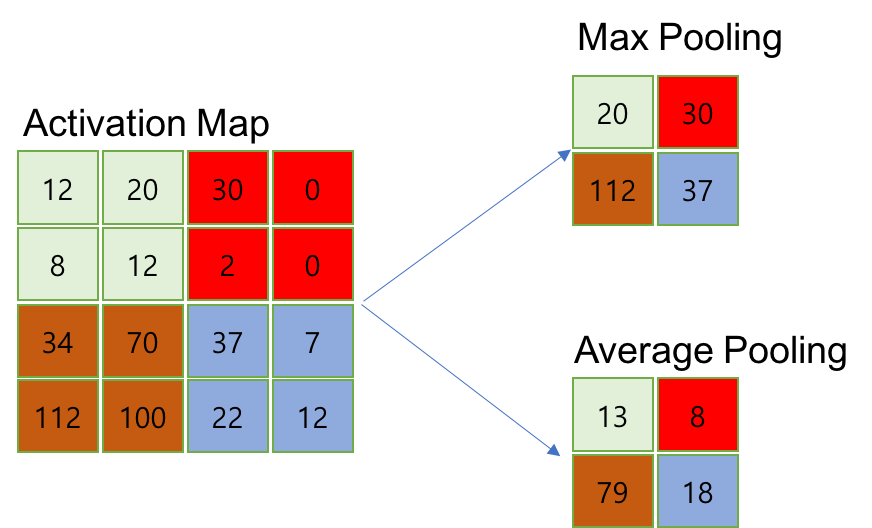
プーリング層は、一般的に畳み込み層の後に適用され、入力データをさらに扱いやすくするために情報を圧縮する層です。主に「MaxPooling」「Average Pooling」の2つの方法があります。MaxPoolingは入力画像の最大値を取得することで情報を圧縮します。Average Poolingは入力画像の平均値を取得することで情報を圧縮します。
全結合層 Fully Connected Layer
全結合層は、畳み込み層とプーリング層で抽出された特徴を元に、最終的な分類を行うために使用されます。それぞれの特徴量をノードに集約し、活性化関数を通して出力します。隣接する層のどのチャネルからどの程度の信号を受け取るべきなのか、(分類された結果と正解データの差から学習された)重み(w)およびバイアス(b)を使って計算していきます。

より詳しく正確にCNNを理解したい方はこちらの記事がおすすめです。
2.2 CNNモデルの実装
CNNのモデルの実装に入っていきます。NVidiaが提供しているCNNモデルを参考に実装しています。
Nvidiaモデルへの入力は車載のカメラからの映像であり、出力は車のハンドル角度です。モデルはビデオ映像から情報を抽出し、車のハンドル角度を予測します。映像をデータ、ハンドル角度をラベルとして扱う教師あり学習を行っています。通常、CNNは画像分類に使用され出力結果は複数のクラスに対する確率となることが多いですが、Nvdiaモデルは回帰タイプのモデルであり、出力結果はハンドル角度1つとなっています。
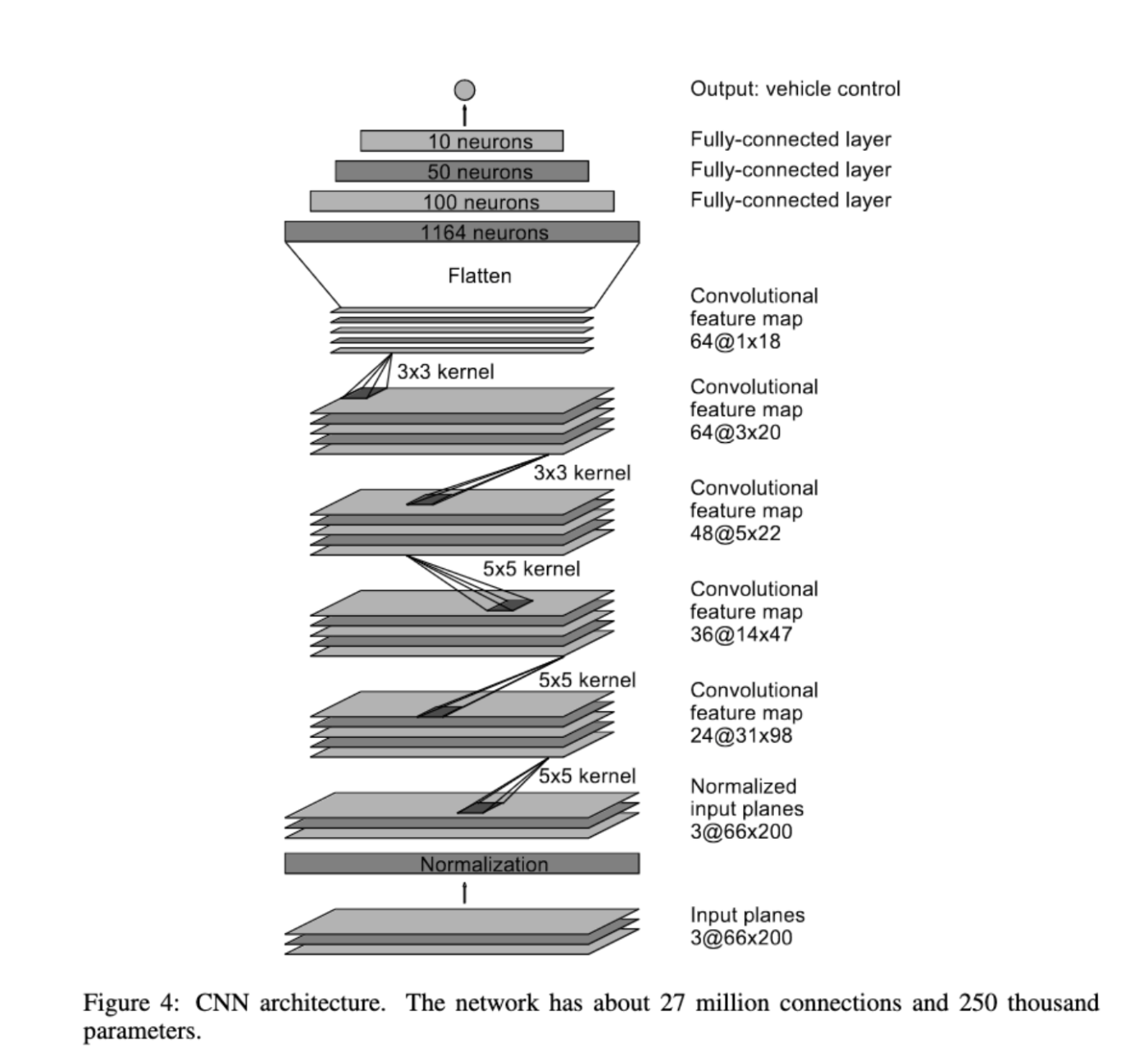
今回使用するマップはオーバルトラックであり、非常に簡素であるため詳細なハンドル角度を予想する必要はなかったため、直線、左右の3つのクラスに分類する画像分類タイプのモデルにしました。Nvidiaと異なる部分は全結合層の活性化関数にsoftmaxを使用している点と最終的な出力層のノード数が3つである点です。
今回使用したオーバルトラックのマップ↓

データセットの分類
!cd /content
data_dir = '/content/drive/My Drive/ads/dataset/'
file_list = os.listdir(data_dir)
angle_01 = []
angle_02 = []
angle_03 = []
pattern = "*.jpg"
for filename in file_list:
if fnmatch.fnmatch(filename, pattern):
angle = int(filename[-8:-4])
if (angle == 1): angle_01.append(os.path.join(data_dir, filename))
if (angle == 2): angle_02.append(os.path.join(data_dir, filename))
if (angle == 3): angle_03.append(os.path.join(data_dir, filename))
train_list = [x for x in angle_01]
train_list.extend([x for x in angle_02])
train_list.extend([x for x in angle_03])
df_train = pd.DataFrame(np.concatenate([
['1']*len(angle_01),
['2']*len(angle_02),
['3']*len(angle_03)]),
columns = ['label'])
df_train['image'] = [x for x in train_list]
df_train
df_train['image']にデータセットのパスを、df_train['label']にラベルデータを格納しています。
データセットの加工 / 分割
path = '/content/drive/MyDrive/ads/dataset'
data_img = []
img_list = list(df_train['image'])
for each in img_list:
each_path = os.path.join(path, each)
image = cv2.imread(each_path)
height, _, _ = image.shape
image = image[int(height/5):, :, :]
image = cv2.GaussianBlur(image, (3,3), 0)
image = cv2.resize(image, (200, 66))
image = image / 255
data_img.append(image)
X = np.array(data_img)
y = OneHotEncoder(dtype='int8', sparse=False).fit_transform(df_train['label'].values.reshape(-1,1))
実際データセットを分類する前にモデルの正確さを担保するためトレーニングを行いやすくするために、各画像に画像加工を行っています。image = image[int(height/5):, :, :]は画像上部の不要な部分を削除しています。NVDIAのモデルではwidth200,height66を採用しているためそれに沿ってcv2.resize(image, (200, 66))で画像サイズを変更しています。image = image / 255は画像のピクセル値を0~1の範囲に標準しています。y = OneHotEncoder(dtype='int8', sparse=False).fit_transform(df_train['label'].values.reshape(-1,1))はラベルデータをOneHotEncodingしています。
モデルの宣言
def nvidia_model():
model = Sequential(name='Nvidia_Model')
# Convolution Layers
model.add(Conv2D(24, (5, 5), strides=(2, 2), input_shape=(66, 200, 3), activation='elu'))
model.add(Conv2D(36, (5, 5), strides=(2, 2), activation='elu'))
model.add(Conv2D(48, (5, 5), strides=(2, 2), activation='elu'))
model.add(Conv2D(64, (3, 3), activation='elu'))
model.add(Dropout(0.2))
model.add(Conv2D(64, (3, 3), activation='elu'))
# Fully Connected Layers
model.add(Flatten())
model.add(Dropout(0.2))
model.add(Dense(100, activation='elu'))
model.add(Dense(50, activation='elu'))
model.add(Dense(10, activation='elu'))
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
return model
model = nvidia_model()
print(model.summary())
過学習を防ぐのに役立ち、一般的にモデルをより堅実にするために、model.add(Dropout(0.2))ドロップアウトをしています。categorical_crossentropyは多クラス分類の損失関数で、クラスごとに確率分布を比較し、誤差を計算します。この損失を最小化することで、モデルはより正確な予測を行うようになります。rmspropは勾配降下法の一種であり、学習率を調整することで学習の効率を上げることができます。
モデルの学習
from tensorflow.keras import callbacks
from tensorflow.keras import optimizers
model_output_dir = '/content/drive/My Drive/ads/model/'
saved_model_path = os.path.join(model_output_dir, 'lane_navigation_check.h5')
epochs = 35
batch_size = 32
ch_pt = callbacks.ModelCheckpoint(filepath=saved_model_path ,monitor='val_loss',save_best_only=True,save_weights_only=True)
es_cb = callbacks.EarlyStopping(monitor='val_loss', patience=20, verbose=1, mode='auto')
rd_lr = callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=5, min_lr=0.001)
if os.path.exists(saved_model_path):
model = load_model(saved_model_path)
initial_epoch = model.optimizer.iterations.numpy() // epochs
print(f"Resuming training from epoch {initial_epoch}")
else:
initial_epoch = 0
history = model.fit(X_train, y_train, epochs=epochs, batch_size=batch_size,
validation_data=(X_valid, y_valid), callbacks=[ch_pt,rd_lr,es_cb])
model.save(os.path.join(model_output_dir, 'lane_navigation_final.h5'))
結果の可視化
history_df = pd.DataFrame(history.history)
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
plt.plot(history_df['loss'], label='training loss')
plt.plot(history_df['val_loss'], label='validation loss')
plt.title('Model Loss Function')
plt.legend()
plt.subplot(1,2,2)
plt.plot(history_df['accuracy'], label='training accuracy')
plt.plot(history_df['val_accuracy'], label='validation accuracy')
plt.title('Model Accuracy')
plt.legend();
NvidiaのCNNモデルの論文はこちら↓
3. Raspberry Piのコントロール
def preprocess_image()ではモデルの要件に合わせてモデルの予測前に画像を加工します。cap.set(cv2.CAP_PROP_FPS, 20)で1秒間に20枚の画像を取得します。本来、モデルによる方向の予測はフレームごとに行うことつまりFPS20ならば20回予想を1秒間に行うことが望ましいです。しかし、今回使用するRaspberry Piは1秒間に20回の予想をするにはあまりにも非力すぎるので4の倍数のときだけつまり20フレーム中6回予想するように制限をしています。6回では少なすぎる20フレームすべてに予測を行いたいとなると、GPUを搭載するかより高性能なPCにUDPを通してフレームを送信する手法が有効かもしれません。Google ColabとRaspberry PiをUDPで接続する方法もいいかもしれないですね。
おわりに
本記事では、自動運転モジュールの一環であるPiRacer Standard(Raspberry Pi 4B) + CNNを使用して自動運転を実装するという課題についてどのように実装したのかをお話ししました。
私が参加しているSEA:MEプログラムは、自動車のソフトウェアエンジニアリングについて学ぶことができるプログラムです。SEA:ME / 42に興味がある方は、ぜひお気軽にメッセージください。
Discussion