強化学習の基礎的な手法で簡単なRPG風ゲームを攻略してみた
強化学習を勉強したい!
そう思っていろいろな資料を読み漁るなどして、勉強に励んできました。
が、数式や最適化手法をいろいろ追いかけるよりも、実際に使ってみたほうが頭に入りそう。
というわけで、簡単なゲームを設定して強化学習の基礎的な手法を適用してみました。
強化学習について
強化学習の基本的な知識については、他の方々の素晴らしい記事がございますので、そちらを参照いただければと。
以下の動画が非常に分かりやすく、大いに参考にさせていただきました。おすすめです。
ゲームの設定
以下のようなゲームを設定しました。
ルール
- 初期状態に、health (今回は 12) が与えられ、行動を選択してgoldを最大化することが目的。
- round(行動回数)は5。
- 行動によってhealthを消費し、healthが0になった場合は、goldが自動的に0になる。(死亡)
- 行動は以下の3つから選択でき、効果は以下の通り。
- adventure: healthを1,2,3,4,5からランダムで消費し、10倍のgoldを得る。
- investment: 体力を3減らして金額を1.5倍にする。
- save: healthを1減らす。
あるエピソードの例
Round(1) : State(h=12, g=0) -> Action=adventure
Round(2) : State(h=9, g=30) -> Action=adventure
Round(3) : State(h=6, g=60) -> Action=investment
Round(4) : State(h=3, g=90) -> Action=save
Round(5) : State(h=2, g=90) -> Action=save
Final: h=1, g=90
強化学習の文脈では、プレイ開始から終了までの1回のゲームプレイをエピソードと呼ぶそうです。
期待される戦略
このゲームを攻略するために、おおよそ以下のような戦略が適切だと考えられます。
- とりあえず最初は adventure がいい。
- 死にかけ (例:3ターン目行動選択時点で残りhealthが4) の時はひたすらsaveするのが最適。
- goldが60より大きい時はinvestmentの方が良い行動
(期待値を考えた場合。最高記録を狙うとかの場合は話が変わってくる。)
Let's 強化学習
さっそく強化学習でこのゲームを解いていきます。
ゲームについて強化学習の文脈で整理する
まず、強化学習で用いられる変数や関数を、このゲームに合わせて整理します。
s
ゲームとしてどんな状況にあるか。このゲームの場合は、round数、残りhealth、goldが決まることによって、一意に決まります。
a
プレイヤーの行動。このゲームの場合、"adventure","investment","save" のうちどれかを選ぶことです。
r
ゲームスコアのこと。今回のゲームの場合はゲーム終了後に得られるgoldのことであり、これを最大化するように学習が行われます。
Q_{\text{new}}(s,a), Q(s,a)
強化学習では、実際にゲームをプレイしてみて、その結果をこの行動価値関数に反映していくことによって、報酬を最大化する行動が何か探索していきます。
最適化手法について
価値関数の最適化手法は、モンテカルロ法、Q学習を使用しました。
モンテカルロ法
(
ここで、

更新式については、下の図のように、

コードは以下の通り。episode_state_actionはゲームプレイ1回分の履歴が入っています。final_rewardを確認して、再度for文を回して、通ってきた
for sc in range(step_count+1):
t_s, h_s, g_s, a_s = episode_states_actions[sc]
Q[t_s, h_s, g_s, a_s] += alpha * (final_reward*(gamma**(step_count-t_s)) - Q[t_s, h_s, g_s, a_s])
Q学習
以下のような関数で学習します。
(
先ほどと同じような解釈で更新式をグラフ化してみると以下のようになります。
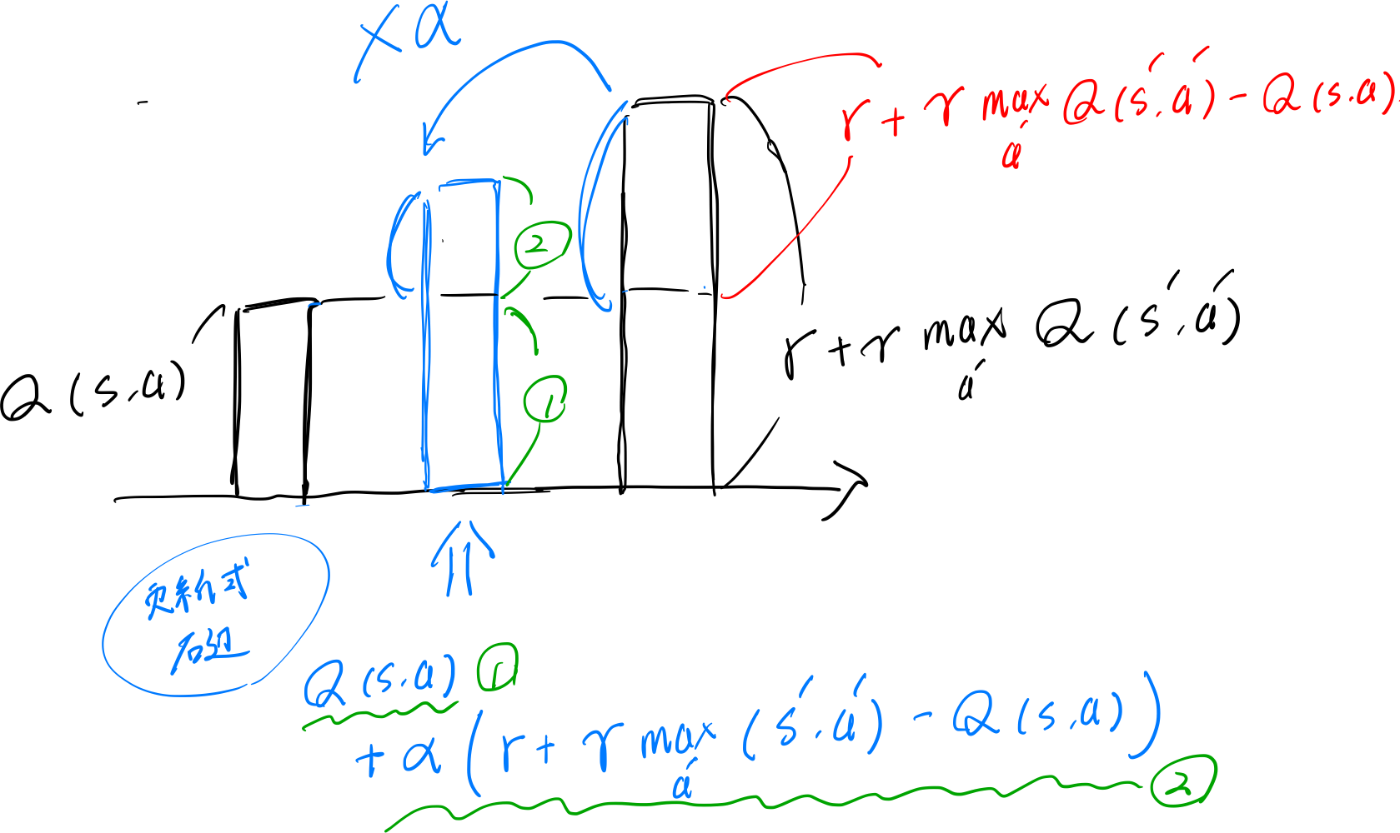
実装
いくつかパラメータを設定して実験ができるように設計したコードが以下になります。
Colabで開く
EPSILONS・DECAY_RATESについて
コードを見ていただけると分かりますが、最初に"とりあえずプレイしてみる"という処理が入ります。
この際に、一定の確率でランダムな選択を行い、それ以外の場合は現状で最適な行動をとる戦略をとっています。
ランダムな選択を行う確率として、初期値をEPSILON、一回ゲームプレイするごとにDECAY_RATEをかけた値を使います。DECAY_RATEは1未満に設定され、学習が進むごとにランダムな行動の確率を低くしていきます。
最初はランダムな行動を多くして、さまざまなパターンを学習し、だんだん最適な行動がわかってきたら、その行動を多めにする。そんなイメージです。
結果
以下に示すグラフは、横軸が Episode (ゲームプレイを試行した回数) で、縦軸が reward (最終的に獲得した報酬)であり、学習が進むにつれて結果が改善していることが分かります。
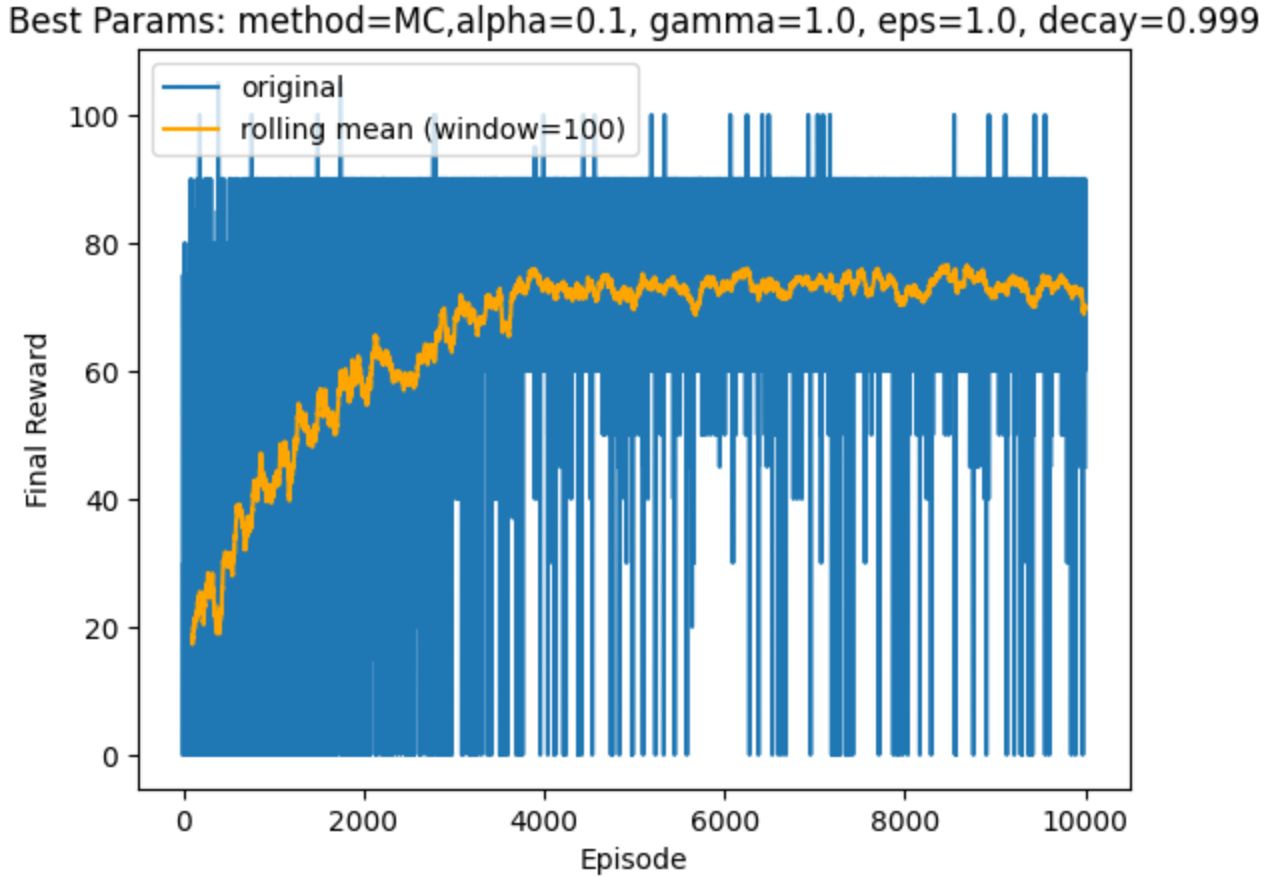
どのくらい賢いか
最後に、この記事の上の方で考えた「期待される戦略」と実際の行動を照らし合わせて、どのくらい賢くなったか確認してみます。
# ゲームプレイの一例
Round(1) : State(h=12, g=0) -> Action=adventure
Round(2) : State(h=11, g=10) -> Action=adventure
Round(3) : State(h=9, g=30) -> Action=save
Round(4) : State(h=8, g=30) -> Action=investment
Round(5) : State(h=5, g=45) -> Action=investment
Final: h=2, g=67
- とりあえず最初は adventure がいい。→⭕️
- 死にかけ (例:3ターン目行動選択時点で残りhealthが4) の時はひたすらsaveするのが最適。→⭕️
- goldが60より大きい時はinvestmentの方が良い行動→❌
上の例だと、Round(3)もしくは(4)はまだ"adventure"を選んだ方がいいのでは?
全体的に、かなり上手にプレイしてくれますが過剰に死亡を避ける傾向があるように見えます。
これについて、パラメータを色々振ってみた時に、DECAY_RATEを低め(あまりランダムに選ばない)の設定にするとほとんど学習が進まなかったという結果が得られました。
今回のケースでは、ちょっと間違えたら死亡してしまうが報酬が高い選択肢をいかに学習するかが肝になっている気がします。
まとめ
まだまだ改善の余地はありますが、強化学習を実行することができました🙌
Discussion