ivy が面白い
ivyとはなにか
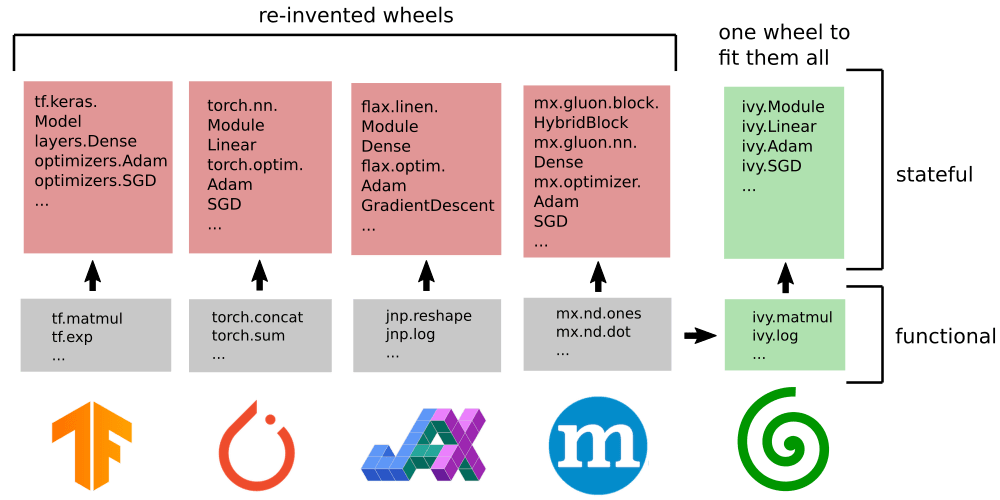
機械学習の統一を目指すフレームワークです。現在、JAX, TensorFlow, PyTorch, Numpy をサポートしています。JAXはNumpy互換なので、実質的に Tensorflow&Pytorch の共通APIのフレームワーク(かなり乱暴なまとめ方)です。
研究のペーパーでよく見るのはPytorchですが、産業ではTensorflowがよく使われるようです。
下の表にもありますが、開発者の設計思想を読むと「書き換えの手間」が想像以上に労力を必要とする文面が多く見受けられます。
余談で手元にTensorflowとPytorchの本が2冊あるのですが、実装に互換性があればそういう悩みが減って深層学習の学習が身近になるかもしれないですね。
特に初学者は「最初にどの山に登るのがいいのか」で迷うと思うので。
ivy登場以前から、学習済みモデルを異なるプラットフォームで共有する仕組みはありました。
ONNXであったり、Apple限定ですが変換ツールのCoreMLToolもその範疇かと思います。
CPU&GPU互換のための環境構築の Anaconda も重要です。
| 環境 | API | モデル |
|---|---|---|
| Conda | ivy | ONNX |
書き換えの手間+車輪の再発明の抑止をivyがAPIの面で担うことが出来れば、Unifyingな学習を実現できます。性能は当然ですが、エコシステムの広がりがAIに限らず使い続ける上で重要な観点だと思います。
何故書くに至ったかですが、ゲームやVFXで使われるゲームエンジンや3DCGのPythonスクリプトにおいて、同様の問題に直面したことがあります。国や業界が異なっていても、同様のことを考えている人がいるのだなと少し感動したのがきっかけです。
前職の異なる部門にMLのエキスパートが数名いたのは知ってますが、機械学習の業務経験はない私に何故、紹介メールが来たのかはわからない...そういう状態で書くので、中身や認識に間違いあればご指摘ください。
ivy を掘り下げる
2つの異なる目的を果たすことができます。
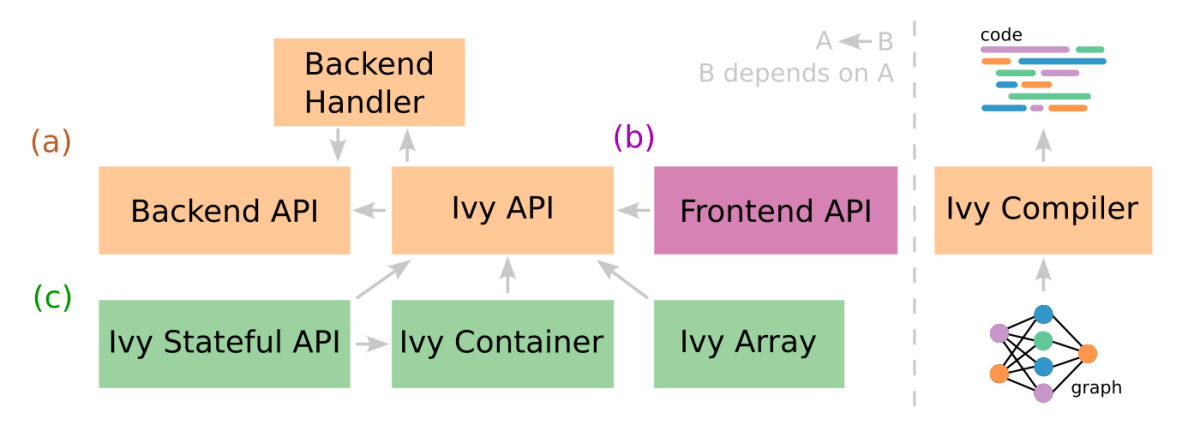
- フレームワーク間のトランスパイラとして機能する。
- 複数のフレームワークをサポートする新しいMLフレームワークとして機能する.
表にもあるように中間形式のサポートによって、将来異なるフレームワークが登場してもそこに対応できる形式にするようです。Background で読むことのできる翻訳を引用します。他業種にも応用の利く普遍的な動機だなと感じます。
長いので英語読める方はリンク先推奨です。
近年、オープンソースのMLプロジェクトはかなり増えてきており、特にDeep Learningは、時間の経過とともに「Deep Learning」という言葉を含むGitHubレポが急速に増えていることからわかるように、その数は増えてきています。これらのプロジェクトは、様々なフレームワークで書かれています。
これは研究者や開発者にとっては素晴らしいことですが、フレームワークの進化のスピードも考慮すると、コードの共有が著しく妨げられ、最新のフレームワークや、最新のフレームワークのバージョンに対して厳格にメンテナンスしないと、プロジェクトやライブラリが数ヶ月で時代遅れになってしまうのです。
迅速なプロトタイピングとコラボレーションが重要なソフトウェア開発パイプラインにとって、これは大きなボトルネックとなります。新しいフレームワークが利用可能になると、バックエンド固有のコードはすぐに時代遅れになってしまい、これらのフレームワークのユーザーは常に車輪の再発明をすることになります。
もし、現代のすべてのフレームワークを同時に、シンプルかつスケーラブルにサポートする新しいフレームワークを提供することを望むのであれば、それらの共通項を正確に見極める必要があるのです。
既存のフレームワークの共通点を見つけることは、シンプルでスケーラブルな普遍的抽象化を設計するために必要不可欠です。
共通項を探すために、まず言語を考えてみると、Pythonが明らかにフロントランナーになっていることがわかります。これらのPythonフレームワークをもう少し深く見てみると、これらすべてが同じ動作原理に従っており、ほとんど同じコア機能APIを公開していますが、ユニークな構文と引数を持っていることがわかります。テンソルを操作する方法は限られており、当然のことながら、これらの基本的なテンソル操作はフレームワーク間で一貫している。各フレームワークによって公開される関数は、2006年に初めて導入されたNumpyの関数と非常によく似た規約に従っている。
したがって、シンプルでスケーラブルな抽象化レイヤーを提供することができます。既存のすべてのMLフレームワークの関数APIは、同じ布から切り出され、類似の関数群に準拠していますが、異なるシンタックスとセマンティクスを持っています。
"すべてのMLフレームワークを統一して何の意味があるのか "と思われるかもしれません。
あなたは現在使っているフレームワークに完全に満足しているかもしれませんし、それはそれで素晴らしいことです。私たちは、素晴らしいMLツールが豊富にある時代に生きているのです。
Ivy はその素晴らしいものをさらに良くするものです...
Ivy がどのように ML のワークフローを合理化し、開発時間を何週間も節約できるのか、2つの明確な例をあげます。
DeepMindがJAXで素晴らしい論文を発表し、あなたが自分の好きなフレームワークを使ってそれを試したいと思っているとしよう。例としてPerceiverIOを使ってみよう。現在、何が起こっているかというと
多くのオープンソースの開発者が、すべてのMLフレームワークでコードを再実装しようと殺到し、多くの異なるバージョン(a、b、c、d、e、f、g)が作られることになります。
これらの実装は必然的にオリジナルから逸脱し、しばしば、誤った学習、収束不良、性能問題などを引き起こします。新しいフレームワークで何とか動作させることで、全く新しい論文が出版されることもあります。
これらのリポジトリは、問題やプルリクエストでいっぱいになり、元の論文やコードベース(a、b、c、d、e、f、g)で期待されたとおりに物事が動いたり動かなかったりする理由についての混乱に陥ります。
それぞれのスピンオフコードベースの開発、コードのテスト、エラーについての議論、そしてエラーに対処するための反復作業に、合計で何百時間も費やされています。これはすべて、1つのプロジェクトを複数のフレームワークで再実装するためのものです。
Ivyを使えば、このプロセスはこうなります。
1 行で、元のコードと同一であることが保証された計算グラフを持つコードを、あなたのフレームワークに直接変換します。
何百時間もかかる4ステップの作業を、数秒の1ステップにしたのです。
さらに言えば、この自動変換ツールを使って、すべてのMLツールを、フレームワークに関係なく、誰にでも開放することができるのです。
一度書いたコードが、フレームワークの開発ラッシュですぐに陳腐化するようなことがなければいいと思いませんか?
ここ数年、多くの開発者がTensorFlowのコードをPyTorchに移植することに多くの時間を費やしてきました。その例として、Lucid、Honk、Improving Language Understandingが挙げられます。
このパターンは変わっておらず、開発者は今、JAXへのコードの移植に多くの時間を費やしています。例えばTorchVision、TensorFlow Graph Nets library、TensorFlow Probability、TensorFlow Sonnetなどです。
数年後にリリースされる次のフレームワークはどうなるのだろうか、すべてを何度も再実装し続けなければならないのだろうか。
Ivyを使えば、一度コードを書けば、あとは変更することなく、将来のすべてのMLフレームワークをサポートすることができます。
使ってみる
思想背景は理解したので使い心地はどうかを検証してみます。Colab の確認が便利なのでお勧めです。
import ivy
class MyModel(ivy.Module):
def __init__(self):
self.linear0 = ivy.Linear(3, 64)
self.linear1 = ivy.Linear(64, 1)
ivy.Module.__init__(self)
def _forward(self, x):
x = ivy.relu(self.linear0(x))
return ivy.sigmoid(self.linear1(x))
ivy.set_backend('torch') # change to any backend!
model = MyModel()
optimizer = ivy.Adam(1e-4)
x_in = ivy.array([1., 2., 3.])
target = ivy.array([0.])
def loss_fn(v):
out = model(x_in, v=v)
return ivy.mean((out - target)**2)
for step in range(100):
loss, grads = ivy.execute_with_gradients(loss_fn, model.v)
model.v = optimizer.step(model.v, grads)
print('step {} loss {}'.format(step, ivy.to_numpy(loss).item()))
print('Finished training!')
AttributeError: module 'ivy' has no attribute 'set_backend'
プロンプト内の以下の文面も動作しません。ivy.\t になります。
To see a list of all Ivy methods, type ivy. into a python command prompt and press tab. You should then see output like the following:
...これだけだと厳しいので、基本に立ち返ってデータ型を確認します。
リストでもndarrayでもtensorでも変換します。タイプは文字列指定が必要です。
import torch, ivy
x_train = torch.tensor(x_train, dtype=torch.float32)
t_train = torch.tensor(t_train, dtype=torch.int64)
x_test = torch.tensor(x_test, dtype=torch.float32)
t_test = torch.tensor(t_test, dtype=torch.int64)
ivy.set_framework('torch')
x_train = ivy.array(x_train, dtype_str="float32")
t_train = ivy.array(t_train, dtype_str="int64")
x_test = ivy.array(x_test, dtype_str="float32")
t_test = ivy.array(t_test, dtype_str="int64")
pytorch実装に併記する形で minist を ivy で実装してみます。[1]
import torch
from torch import nn, optim
from sklearn import datasets
from sklearn.model_selection import train_test_split
import ivy
ivy.set_framework('torch')
DEGIT = 1
# datasets
digits_data = datasets.load_digits()
digits_images = digits_data.data
labels = digits_data.target
x_train, x_test, t_train, t_test = train_test_split(digits_images, labels)
# container
x_train = torch.tensor(x_train, dtype=torch.float32)
t_train = torch.tensor(t_train, dtype=torch.int64)
x_test = torch.tensor(x_test, dtype=torch.float32)
t_test = torch.tensor(t_test, dtype=torch.int64)
x_train = ivy.array(x_train, dtype_str="float32")
t_train = ivy.array(t_train, dtype_str="int64")
x_test = ivy.array(x_test, dtype_str="float32")
t_test = ivy.array(t_test, dtype_str="int64")
# model
class MyModel(nn.Module):
def __init__(self):
super().__init__()
self.fn0 = nn.Linear(64,32)
self.fn1 = nn.Linear(32,16)
self.fn2 = nn.Linear(16,10)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fn0(x))
x = self.relu(self.fn1(x))
x = self.fn2(x)
return x
class IvyModel(ivy.Module):
def __init__(self):
self.linear0 = ivy.Linear(64,32)
self.linear1 = ivy.Linear(32,16)
self.linear2 = ivy.Linear(16,10)
ivy.Module.__init__(self)
def _forward(self, x):
x = ivy.relu(self.linear0(x))
x = ivy.relu(self.linear1(x))
x = self.linear2(x)
return x
is_torch = False
if is_torch:
net = MyModel()
loss_func = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01)
else:
net = IvyModel()
optimizer = ivy.SGD(lr=0.01)
# train
record_loss_train = []
record_loss_test = []
def loss_fn(v):
out = net(v=v)
return ivy.cross_entropy(out)
for i in range(1000):
if is_torch:
optimizer.zero_grad()
else:
# ???
loss_func, grads = ivy.execute_with_gradients(ivy.cross_entropy, net.v)
y_train = net(x_train)
y_test = net(x_test)
loss_train = loss_func(y_train, t_train)
loss_test = loss_func(y_test, t_test)
record_loss_train.append(loss_train.item())
record_loss_test.append(loss_test.item())
if is_torch:
loss_train.backward()
optimizer.step()
else:
# ???
net.v = optimizer.step(net.v, grads)
if i % 100 == 0:
print(f"Epoch:{i} Loss Train:{loss_train.item()} Loss_Test:{loss_test.item()}")
# evaluate
y_test = net(x_test)
count = (y_test.argmax(1) == t_test).sum().item()
print(f"Score:{str(count/len(y_test)*100)}%")
x_pred = digits_images[DEGIT]
image = x_pred.reshape(8, 8)
x_pred = torch.tensor(x_pred, dtype=torch.float32)
x_pred = ivy.array(x_pred, dtype_str="float32")
y_pred = net(x_pred)
print(labels[DEGIT], y_pred.argmax().item())
データ型、アルゴリズム、損失関数 あたりはそのまま互換性があり書き進めるのは容易でした。
pytorch の gradient の取り回しがよくわからず、Sequential 表記は ReLU が引数を要求したりで(torch.nnのReLUクラスではなくtorch.nn.functionalのrelu関数でした)、微妙な差異を把握するのがなかなか難しいです。
デバイス切替は、バックエンドのレイヤーになるので課題も多そうです。モジュールが環境整備されていれば、バックエンドのそれぞれで動作することは確認できました。
ivy.set_framework('torch')ivy.set_framework('tensorflow')
懸念
ソースコードを読みながら確認しているため理解があやふやですが、シェアを二分する2大フレームワークのリリースサイクルに保守メンテナンスを続けていけるのか不安があります。
ラッパーを気にしてフレームワークの開発者が足並みをそろえるようなことはしないでしょうし...
フレームワークの違いは基礎概念を理解した上級者の視点では些細な違い程度なのでしょうが、
トラブルシュートの際に結局のところフレームワークのレイヤーまで下りて問題解決することになるのではないか?という懸念もあります。
私は専門分野外の人なので、フレームワークの違いに悩むことなく身の回りや自らの業務の課題解決にディープラーニングを使える世界が早く来てもらえないかと思います。個人的には同一ジャンルでフレームワークが分かれていてもあまりいいことないと思うので、ivy が取りまとめてくれるとよりプロジェクトに取り入れやすくなる、かもしれませんね。
参考
Discussion