📊
「箱ひげ図」に「ひと味」加えて可視化する(boxen / swarm / violin)
概要
-
kaggleのtitanicのデータ可視化で思ったことのメモです。
- 「乗船した港」毎に「乗客の年齢」分布をうまく可視化したい。
- そういったときに、箱ひげ(seabornで言えばboxplot)を使うのがよくある手段
- 一方で、他の 可視化手段を使うと「ひと味」加える事ができるので、まとめてみました。
- 今回は、seabornの箱ひげ図(boxplot)の代替として下記あたりを検討してみたいと思います。
- 誰かの役に立つと嬉しいですが、あくまでも作業メモ&私見です。
モチベーション
箱ひげ
- タイタニックで、乗船港毎の乗客の年齢はこんな感じ。(まずは、箱ひげ)
- 一応、下記程度は読み取れます。
- どの港から乗ったとしても、年齢の中央値は25~30歳くらい
- 中央値や第1、3分位値にも大きく差はない。(Queenstownがちょっと若め?)
- Southamptonから乗った乗客に、外れ値(高齢の方のデータ)が目立つ

Swarmplotにしてみると
- これをSwarmplotにしてみると、四分位値は見づらくなる代わりに、「ひと味」加わり良い感じ。
- 系列毎のデータの個数を意識できるようになる。(実は、Queenstownは少数)
- 箱やひげの意味を知らない人にも読みやすい
- データの密な部分、疎な部分を読み取りやすい

箱ひげに「ひと味」加える
関数やオプションを変えてみる
- 関数をかえる
- オプションをかえる
- hue、splitの指定
等々やると、「ひと味」加える事ができます
まとめてみると(チートシート)
- boxenplotには、splitオプションがない
- swarmplotとviolinplotでは、splitオプションの意味が、ちょっと違うので注意
| オプション | boxenplot | swarmplot | violinplot |
|---|---|---|---|
| 指定無し |  |
|
 |
| hue="Sex" |  |
 |
 |
| hue="Sex" split=True |
なし |  |
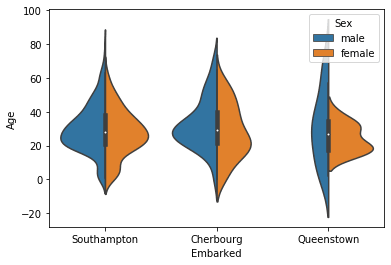 |
「どれ」を「いつ」使うべきか?
- 「この用途では、これ!」と言い切るのは難しいのですが、、
- それぞれ比較してみると特性が見えてきます。
箱ひげ(boxplot) vs boxenplot
- アルファベット的にも2文字(en)しか変わらないのでそこまで差はありません
- 四分位で見せたいか、もっと細かい分位値で見せたいか? 外れ値 を意識させたいか?がポイント
| 箱ひげ(boxplot) | boxenplot | |
|---|---|---|
| 表示 | |
|
| 特徴 |
四分位、最大、最小が分かる 外れ値の状況も見える |
より細かい分位値が見える 外れ値として見えづらい |
箱ひげ(boxplot) vs swarmplot
- 箱ひげに比べて、データの個々を意識し、連続的に捉えるswarmplot
- データの個数、密度、差も見えるようになるが、プロットコストが高く、大量データだと厳しい。
| 箱ひげ(boxplot) | swarmplot | |
|---|---|---|
| 表示 | |
|
| 特徴 | 区間(分位値)として捉える プロットコストが低い |
個々を意識し連続的にデータを捉える データ個数や系列毎の差も理解可 しかし、プロットコストが高い |
swarmplot vs violinplot
- swarmplotのように、連続的にデータを扱い、プロットコストも抑えられるのがviolinplot
- その代わり、データの個数や系列毎の差は意識できなくなる。
| swarmplot | violinplot | |
|---|---|---|
| 表示 | |
|
| 特徴 |
個々を意識し連続的にデータを捉える データ個数や系列毎の差も理解可 しかし、プロットコストが高い |
個々を意識せず、データの個数が見えないが、 全体傾向を連続的に理解可能 プロットコストも抑える事ができる。 |
まとめ
- 一長一短あり、用途に応じて選択すべきですが、まとめると下記といったところでしょうか。
| 区間 vs 連続 | 「ひと味」の加え方 | 選ぶべき可視化手法は? |
|---|---|---|
| データを**区間 (分位)**で扱い、 |
外れ値も意識させたければ、 |
箱ひげ(boxplot)
|
| 四分位より細かい表示では、 |
boxenplot
|
|
| データを連続的に扱い、 | その個数や密度を見せたければ、 |
swarmplot
|
| プロットコストを抑えて 全体傾向を見せたければ、 |
violinplot
|
Discussion