【Synapse Pipeline】ローコードでExcel複数シートの内容をSynapseの専用SQLPoolに取り込む方法

この記事の対象者は、Azure Synapse Analyticsで専用sqlプールを作成し、何かしらのクエリ文を実行したことがある方 or Synapse Pipeline(Azure DataFactory)を使ったことがある方を対象としております。そうでいない方は、以下の記事をご参考ください。
- Azure Synapse Analyticsの概要・開発ポータル(Azure Synapse Studio)についての説明はMSLearnのこちらにて記載されております。
- Azure Synapse Analyticsのクイックスタートについてこちらを参照してください。
- Azure DataFactoryのクイックスタートについてこちらを参照ください。
- Azure DataFactoryとSynapse Pipelineは、ほぼ近しいサービスであるが、違いについて知りたい方は以下のサイトを参照ください。
- Azure Synapse Analyticsの概要について約30分ほどの動画で理解したい方は、こちらを参照ください。
- Azure Synapse AnalyticsのSynapse Pipelineについて約30分ほどの動画で理解したい方は、こちらを参照ください。
はじめに
Excelファイルで自社のデータ管理をされている例は2021年の現在でも少なくなく、新しいデータ管理へ移行する手間やコストを考えると.xlsxからsqlデータベースへの移行に関する知見をシェアすることは有益であると思われます。以前まではC#やSSISなど別のツールを利用して、このようなデータ取り込みのオーケストレーション処理を実行していたが、近年はAzure Data FactoryやSynapse Pipeline用のExcelコネクタが存在しており、GUI操作を中心とし比較的容易にデータを移行することができるようになりました。本記事では、特に複数のシートによってデータが分散しているExcelファイルを対象に、Azure Synapseの専用SQLプールにデータを取り込む方法をローコードで示します。
Pythonの扱いに慣れており、追加パッケージやAzure Functionsを活用して、動的にシート名を取得したい方は、こちらの記事を参考にされると良いかもしれません。
本記事に関するGithub Repo
Synapse Studioでのソース管理機能に基づいて、リポジトリが構成されております。
前提準備
1. Excelファイルのダミーデータの作成
まずは、Azure Data Lake Storage Gen2に格納するためのxlsxファイルを用意します。ここで作成するエクセルデータはこちらのGithubのリポジトリよりダウンロードすることも可能です。
ここでは、mockarooというダミーデータ生成用のサイトでダミーデータを作成します。
※mockaroo では 1000 件 / 回のダミーデータを無料で作成することができます
▽ダミーデータ生成サイト「mockaroo」
このようにweb上でField NameとTypeを指定することで、ダミーデータを簡単に作成することができます。


続いて、年次ごとにシートを作成するため、上記の内容にyearの項目を追加します。そして、まずは2020年の値をもつシートを生成したいため、Fieldの横にあるΣのアイコンをクリックします。そして、次のように記述します。
this = '2020'

本記事では、ファイルフォーマットをExcelとして書き出します(データのRowsは20程度)。
同様に2021のデータも書き出します。そして、次の画像に示すような、2つのエクセルファイルからシートを合成し、マルチシートを持つエクセルファイルを作成します(もっと頭の良さそうなファイルの準備の方法はありそうですが・・・w)。

Fin.
2. Azure Synapse Analyticsのリソースの作成
Azure Portalにアクセスして、Azure Synapse Analyticsのリソースを作成します。ADLS(Azure Data Lake Storage Gen2)もこの画面で同時にリソースが作成されます。個人的にリソースの名前付けはこちらの公式ドキュメントを参考に名前を付けています。Azureのリソースの種類を明示的にリソース名に記しておくことで視覚的に認識しやすくなります。たまにUIが悪くて示しているリソースがどれか分からないことがごくまれにありますので、運用でカバーするのをおすすめします。

デプロイは大体3分半程で完了します。
完了したらAzure Synapse Analyticsのリソースにアクセスして、Synapse Studioを起動しましょう。
Fin.
3. Linked Serviceの作成
Synapse StudioからStorageにアクセスしてデータを活用するためにLinkedServiceを作成します。次に、手順を示します。
まず、左側の「管理」ハブを選択し、リンクサービスの画面から新規を選択します。すると、新しく作成するリンクサービスの種類を選ぶことができるため、「Azure Data Lake Storage Gen2」を選択します。

続いて、このように作成するリンクサービスの情報の記入が求められるため、「名前」と「認
証方法」を入力し、「テスト接続」を選択し、行います。個人的には、リンクサービスの名前は頭文字に「Linked」を付け、明示的にリソースの種類が分かるようにすることをおすすめします。

接続成功で表示されたら、作成ボタンを選択し、リンクサービスの作成を行います。
Fin.
4. ADLS(Azure Data Lake Storage Gen2)へのアップロード
Synapse Studioからダミーファイルをアップロードする手順を示します。
まず、左側の「データ」ハブを選択します。続いて、リンク済み->Azure DataLake Gen2のプルダウンを開きます。すると、ファイルシステム名が現われるので作成したファイルシステムを選択し、アップロードをクリックすることで先程準備したdummyのExcelファイルをアップロードします(本記事では、dummyのエクセルファイル名は「dummydata.xlsx」としています)
こちらの画面では、windowsのエクスプローラー同様に階層構造になっており、フォルダの作成やアップロード・ダウンロード、名前の変更などが行えるようになっております。(本記事では特に説明しませんが、Azure Portalから直接Storageアカウントへアクセスする方法やStorage Explorerにて行う方法で同様の操作を行うことができます)。

Fin.
5. 専用SQLプールの作成
Synapse Studioから専用SQLプールをアップロードする手順を示します。
まず、左側の「管理」ハブを選択します。続いて、SQLプール->新規を選択します。すると、専用SQLプールを新規作成する際に入力する情報が求められるため入力します。「専用SQLプール名」と「パフォーマンスレベル」を決める必要があります。名前に関しては先頭に「d_」を付けると分かりやすいかと思います。「d_」はdedicatedの略で「専用」という意味になります。パフォーマンスレベルに関しては最小値のDW100cを選択するとお財布に優しいかと思います。すべての記入が完了したら、「確認および作成」を選択して、「作成」をクリックし、作成しましょう。大体2分かからない程でデプロイが完了します。

Fin.
方法
本記事では、以下の3つのパターンに対して、手順を示します。
▼ パターン1の全体構成図

パターン1:Excelの1つのシートを1つの専用SQLプールのテーブルに読み込む方法
本記事のメインは複数シートの取り込みであるが、まずは1つのシートのみの読み込み方法についても記載しておきます。既知の方は読み飛ばしてください。
1. コピー先のテーブルの作成
まずは、コピー先のテーブルを作成します。
「開発」ハブ->「+」-> SQLスクリプトで新規作成して以下のスクリプトを実行しましょう。
※実行の際に、接続先をサーバーレスSQLから専用SQLである「d_sql(作成した専用SQLプール名)」への変更忘れを注意しましょう。変更していない状態で実行すると次のようなエラーが発生します。
Incorrect syntax near 'DISTRIBUTION'.
※Create Table文で指定するデータサイズ(文字数)が短いとエラーになりますので注意(このままコピペでOK!)
CREATE TABLE [dbo].[SingleTable]
(
id nvarchar(10),
first_name nvarchar(20),
last_name nvarchar(20),
email nvarchar(30),
gender nvarchar(20),
ip_address nvarchar(20),
year nvarchar(4)
)
WITH
(
DISTRIBUTION = ROUND_ROBIN,
CLUSTERED COLUMNSTORE INDEX
)
GO
実行したら、小まめに「発行」をクリックし、保存しましょう。
テーブルが作成されたの確認をするために、「データ」ハブ-> 「ワークスペース」-> 「SQLデータベース」-> 「d_sql(SQL)(作成した専用SQLプール名)」の下に「dbo.SingleTable」が存在していることが確認出来たら作成成功です。
※「データ」ハブ->「ワークスペース」に移動して、何も表示されていない場合は、Synapse Studio上の右上(青い帯の下)に存在するリロードのアイコンをクリックして再読み込みをおこなってください。

2. パイプラインの作成
次に、Pipelineの作成を行います。「統合」ハブ->「+」->「パイプライン」を選択し、「データのコピー」アクティビティを配置します。アクティビティ名をSingleSheetCopyとし、パイプライン名をpipeline_singlesheetとしてます。
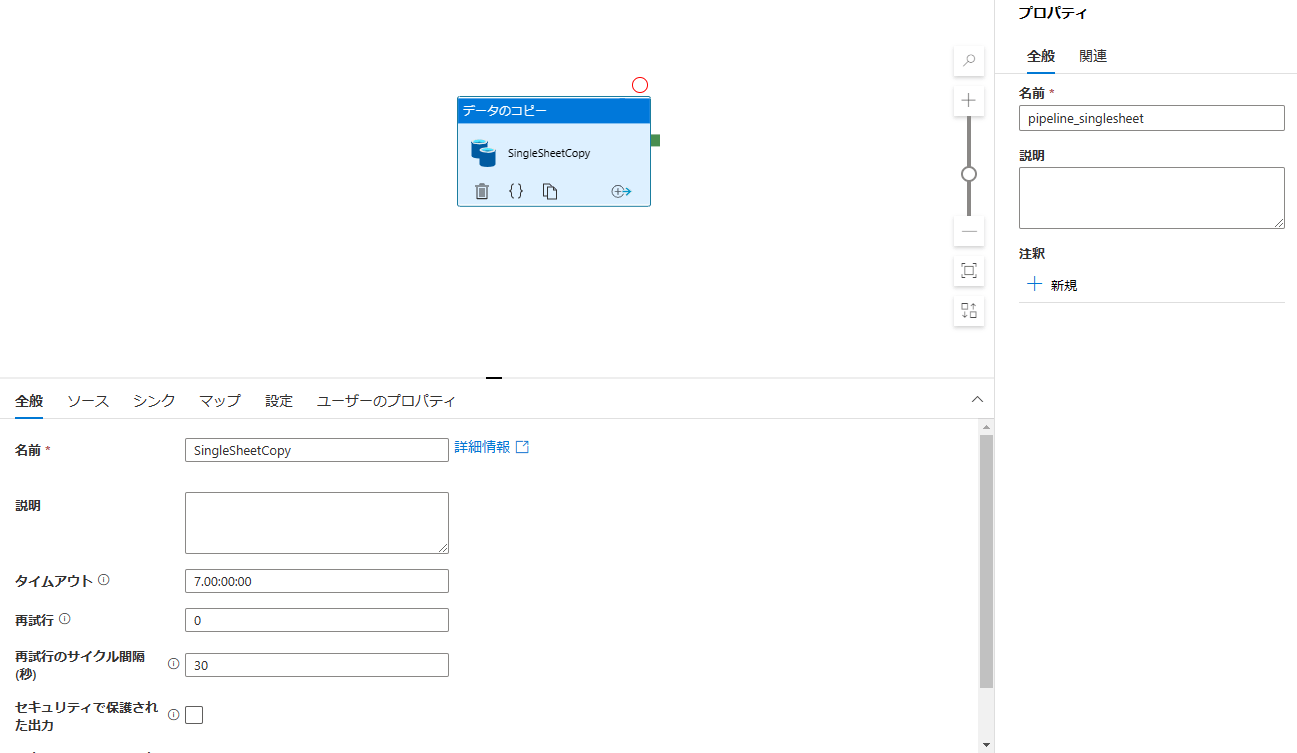
2.1 ソースの設定
続いて、「データのコピー」アクティビティのプロパティ情報を入力します。そして、「ソース」->「ソースデータセット」で「+新規」を選択します。ここでは、コピー元となるExcelのデータセットを作成します。そのため、「Azure Data Lake Storage Gen2」-> 「Excel」を選択します。すると、次の画像の画面が表示されるかと思います。
ここでは、「名前」、「リンクサービス」、「ファイルパス」、「シート名」を指定します。
※設定内容は以下のテーブルにまとめておりますので参照ください。
名前はリソースの種類が分かりやすくするために、先頭に「Dataset」と付けております。リンクサービスは、先程、自作したものを選択します。ファイルパスはダミーファイルを指定します。シート名はまずは、年次が若い「2020」を指定します。また、「先頭行をヘッダーとして」のチェックボックスにチェックを付けます。設定が完了したら「OK」を選択し、作成します。
| 項目名 | 設定内容 |
|---|---|
| 名前 | DatasetSingleDummyData |
| リンクサービス | LinkedADLS |
| ファイルパス | fs-ac/ディレクトリ名(作成していれば)/dummydata.xlsx |
| シート名 | 2020 |
| 先頭行をヘッダーとして | チェックあり |
作成が完了したら、データセットの中身を確認しましょう。「ソース」-> 「ソースデータセット」-> 「開く」を選択します。
次の画面が表示され、「シート名」が「2020」であることを確認し、問題がなければ、データセットの作成と設定は完了です。


2.2 シンクの設定
次は、書き込み先のシンクの設定を行います。「シンク」->「シンクデータセット」で「+新規」を選択します。ここでは、コピー先となる専用SQLプールを設定します。そのため、「Azure Synapseの専用SQLプール」を選択します。すると、次の画像の画面が表示されるかと思います。
ここでは、「名前」、「SQLプール」を指定します。テーブル名は現状作成していなため、「なし」と指定されていることを確認してください。
※設定内容は次のテーブルの通りです。
| 項目名 | 設定内容 |
|---|---|
| 名前 | SingleSqlPoolTable |
| SQLプール | d_sql |
| テーブル名 | dbo.SingleTable |
 |
|
| 作成が完了したら、データセットの中身を確認しましょう。 | |
| 先程の設定どおりに設定されていたら成功です。 | |
 |
続いて、「データのコピー」アクティビティの画面に戻ります。「シンク」-> 「Copyメソッド」で「一括挿入」を選択します。
この時点で次のように設定ができていれば、シンクの設定は完了です。
| 項目名 | 設定内容 |
|---|---|
| シンクデータセット | SingleSqlPoolTable |
| Copyメソッド | 一括挿入 |
| 一括挿入テーブルロック | いいえ |
| テーブルオプション | なし |
 |
ここで一度、作成したデータ・設定を保存するために、Synapse Studioの上に位置する「すべて発行」を選択して保存しましょう。

後は、実行するだけです。「検証」して問題がなければ「デバッグ」を押しましょう。
成功すれば次のように「状態」に成功と表示されます。

実際に、テーブルにExcelデータが書き込まれているか確認しましょう。
次のスクリプトを実行する or データハブからテーブル名->「新しいSQLスクリプト」-> 「上位100行を選択」を選択し、スクリプトを実行しましょう(どちらも同じスクリプトです)。
SELECT TOP (100)
[id],
[first_name],
[last_name],
[email],
[gender],
[ip_address],
[year]
FROM [dbo].[SingleTable]
このようにテーブルの中身が確認できたら、Excelの1つのシートを1つの専用SQLプールのテーブルに読み込むことができたため、パターン1は成功です。

Fin.
▼ パターン2の全体構成図

パターン2:専用SQLプールの複数のテーブルに対し、Excelの複数のシートをそれぞれ取り込む方法
こちらのセクションでは、Excelのシート情報を参照するためにLookUpTableを作成し(参照アクティビティを使用)、ForEachアクティビティで随時参照することで取り込んでいきます。
1. 各テーブルの準備とデータの挿入
まずは、シート情報が書かれたTableを次のSQLスクリプトを実行し、作成します。
CREATE TABLE [dbo].[SheetLUT](
[SheetName] [nvarchar](10),
[TableName] [nvarchar](20)
)
次に、シンク先のテーブルを用意します。本記事では、シートは2つしかないため、2つのテーブルを用意します。次のSQLスクリプトを実行し、作成します。
CREATE TABLE [dbo].[SinkTable2020]
(
id nvarchar(10),
first_name nvarchar(20),
last_name nvarchar(20),
email nvarchar(30),
gender nvarchar(20),
ip_address nvarchar(20),
year nvarchar(4)
)
WITH
(
DISTRIBUTION = ROUND_ROBIN,
CLUSTERED COLUMNSTORE INDEX
)
GO
CREATE TABLE [dbo].[SinkTable2021]
(
id nvarchar(10),
first_name nvarchar(20),
last_name nvarchar(20),
email nvarchar(30),
gender nvarchar(20),
ip_address nvarchar(20),
year nvarchar(4)
)
WITH
(
DISTRIBUTION = ROUND_ROBIN,
CLUSTERED COLUMNSTORE INDEX
)
GO
そして、SheetLUTにシート名とシンク先のテーブル名をInsert文で挿入します。
※何回も実行するとその分、挿入されるので注意。複数実行してしまったら、SheetLUTをDrop文で削除し、もう一度2-1_createLUT.sqlを実行しましょう。
INSERT INTO [dbo].[SheetLUT] VALUES ('2020','SinkTable2020');
INSERT INTO [dbo].[SheetLUT] VALUES ('2021','SinkTable2021');
2. パイプラインの作成
次に、Pipelineの作成を行います。「統合」ハブ->「+」->「パイプライン」を選択し、「参照」アクティビティを配置します。アクティビティ名をSheetLookUpとし、パイプライン名をpipeline_multisheet_eachとしてます。

2.1 「参照」アクティビティの設定
参照アクティビティの設定を行います。「設定」-> 「ソースデータセット」-> 「+新規」-> 「Azure Synapseの専用SQLプール」を選択してください。ここでは、プロパティの設定として、次の情報を入力します。問題がなければ「OK」を選択し、データセットの作成を完了させましょう。
| 項目名 | 設定内容 |
|---|---|
| 名前 | Dataset_sheetLUT |
| SQLプール | d_sql |
| テーブル名 | dbo.SheetLUT |
そして、「参照」アクティビティの「設定」の「クエリの使用」の項目を「クエリ」にします。すると、実際に実行するクエリ文を入力する欄がでてくるため次のように入力します。
select [sheetName],[TableName]
From [dbo].[SheetLUT]
こちらのSQL文により、参照が行われます。
2.2 「ForEach」アクティビティの設定
続いて、LUTを探索するために、「ForEach」アクティビティを配置します(繰り返しと条件付きの項目にあります)。ここでは、名前を「FE_excelsheet2dsql」とします。
次にアクティビティ同士のデータの連携をするために、ドラッグ&ドロップで線を繋ぎます。
そして、ForEachアクティビティの「設定」-> 「項目」の下にある「動的なコンテンツの追加[Alt+Shift+D]」を選択します。すると、次の画像の通りに入力の詳細がでてくるため、このように記入します。
@activity('SheetLookUp').output.value
こちらのCodeは、SheetLookUpという名前のアクティビティの出力の値を渡すという意味です。Azure Data FactoryやSynapse Pipelineに関する式と関数についてはこちらの公式ドキュメントを参照ください。

ForEachの設定が完了したら、内部でループさせる処理に移ります。ForEachアクティビティをダブルクリックすると、配置画面が新しく表示されるため、そこに「データのコピー」アクティビティを配置します。名前を「CopyExcelSheet」とします。

2.3 「データのコピー」アクティビティのソースの設定
続いて、「データのコピー」アクティビティのプロパティ情報を入力します。そして、「ソース」->「ソースデータセット」で「+新規」を選択します。ここでは、コピー元となるExcelのデータセットを作成します。そのため、「Azure Data Lake Storage Gen2」-> 「Excel」を選択します。すると、次の画像の画面が表示されるかと思います。ここも前回のデータセットの作成と同様に以下のように一旦入力し、「OK」を選択します。「シート名」に関しては別画面で動的に参照できるように変更予定です。

| 項目名 | 設定内容 |
|---|---|
| 名前 | DatasetMultisheet |
| リンクサービス | LinkedADLS |
| ファイルパス | fs-ac/ディレクトリ名(作成していれば)/dummydata.xlsx |
| シート名 | 2020(変更予定) |
| 先頭行をヘッダーとして | チェックあり |
データセットの作成が完了したら、中身を確認するために開きましょう(「データのコピー」アクティビティの 「ソースデータセット」->「開く」を選択)。シート名を動的に参照できるように変更する必要があります。まずは、「パラメーター」のタブを選択し、次のようにパラメーターを新規作成します。
| 項目名 | 設定内容 |
|---|---|
| 名前 | SheetName |
| 種類 | 文字列 |
| 既定値 | 入力の必要なし |

シート名の項目の下にある「編集」のチェックボックスをオンにし、シート名の項目をクリックすると「動的なコンテンツの追加[Alt+Shift+D]」の文字が現れるのが分かります。そちらをクリックし、次のように入力します。
@dataset().SheetName
そちらのCodeにより、動的にシート名を指定できるようになります。
「接続」タブに移り、シート名の編集チェックボックスにチェックを付け、次のように変更します。
| 項目名 | 設定内容 |
|---|---|
| シート名 | @dataset().SheetName |
 |
再び、「データのコピー」アクティビティの設定に戻ります。「ソース」-> 「ソースデータセット」のデータセットのプロパティの値を次のように設定してください。
@item().SheetName

Fin.
2.4 「データのコピー」アクティビティのシンクの設定
続いて、「データのコピー」アクティビティのシンクの設定を行います。「シンク」->「シンクデータセット」で「+新規」を選択します。ここでは、シンク先となるテーブルのデータセットを作成します。そのため、「Azure Synapseの専用SQLプール」を選択します。ここでは以下のように設定し、「OK」を選択します。
| 項目名 | 設定内容 |
|---|---|
| 名前 | MultiSqlPoolTable |
| SQLプール | d_sql |
| テーブル名 | なし(後で変更予定) |

作成したデータセットを開き、まずは、「パラメータ」タブの内容を次のように設定します。
| 項目名 | 設定内容 |
|---|---|
| 名前 | TableName |
| 種類 | 文字列 |
| 既定値 | 適当な文字列(動的に取得して上書きされるため) |

そして、「接続」タブに移り、次の通りにテーブル名を変更します。

| 項目名 | 設定内容 |
|---|---|
| 名前 | MultiSqlPoolTable |
| SQLプール | d_sql |
| テーブル | dbo.@dataset().TableName |
ここまで、設定出来たら、一旦、「データのコピー」アクティビティのシンクの画面に戻ります。
こちらで、「シンクデータセット」->「データセットのプロパティ」を次のように編集します。
| 項目名 | 設定内容 |
|---|---|
| 名前 | TableName |
| 値 | @item().TableName |
| その下のCopyメソッドの設定も「一括挿入」にチェックを入れ、変更します。 |

ここまで設定すると、「すべて発行」ボタンをクリックしてもエラーが出力されないかと思います。発行できるときに発行しておくことをおすすめします(パイプライン作り直しになると少し大変です)。
実行に成功すると、このようにForEachが回り、「データのコピー」のログがループ数分表示されるのが分かります。

このように各テーブルの中身(dbo.SinkTable2020, dbo.SinkTable2021)が確認できたら、Excelの複数シートを専用SQLプールのテーブルに対してそれぞれ読み込むことができたため、パターン2は成功です。


▼ パターン3の全体構成図

パターン3:Excelの複数のシートを専用SQLプールの1つのテーブルに読み込む方法
こちらのセクションでは、複数持つExcelのシートの中身をForEachアクティビティで随時参照し、専用SQLプールの1つのテーブルに取り込んでいきます。
1. コピー先のテーブルの作成
まずは、コピー先のテーブルを作成します。
「開発」ハブ->「+」-> SQLスクリプトで新規作成して以下のスクリプトを実行しましょう。
※実行の際に、接続先をサーバーレスSQLから専用SQLである「d_sql(作成した専用SQLプール名)」への変更忘れを注意しましょう。変更していない状態で実行すると次のようなエラーが発生します。
Incorrect syntax near 'DISTRIBUTION'.
※Create Table文で指定するデータサイズ(文字数)が短いとエラーになりますので注意(このままコピペでOK!)
CREATE TABLE [dbo].[SinkMergeTable]
(
id nvarchar(10),
first_name nvarchar(20),
last_name nvarchar(20),
email nvarchar(30),
gender nvarchar(20),
ip_address nvarchar(20),
year nvarchar(4)
)
WITH
(
DISTRIBUTION = ROUND_ROBIN,
CLUSTERED COLUMNSTORE INDEX
)
GO
実行したら、小まめに「発行」をクリックし、保存しましょう。
2. パイプラインの作成
次に、Pipelineの作成を行います。「統合」ハブ->「+」->「パイプライン」を選択し、「ForEach」アクティビティを配置します(繰り返しと条件付きの項目にあります)。ここでは、名前を「FE_excelsheet2dsql」とします。アクティビティ名をFE_merge_excelsheet2dsqlとし、パイプライン名をpipeline_multisheet_mergeとしてます。

2.1 「ForEach」アクティビティの設定
配置した「ForEach」アクティビティの設定を行います。「設定」タブの項目に変数を設定することで、その値を読み取りデータのコピーを行います。現状まだ設定を行っていないため、まずはそちらを設定します。パイプラインの画面のアクティビティではない領域を適当にクリックします。すると、次の画像のように、「変数」タブが現れます。ここで設定する変数は、このパイプラインの内部でもつアクティビティから参照可能です。また、ローコードで複数タブの値をコピーするという本記事の肝になる部分になります。
| 項目名 | 設定内容 |
|---|---|
| 名前 | SheetName |
| 種類 | アレイ |
| 既定値 | ["2020","2021"](シート名をアレイ形式で記述) |
 |
そして、再び、「ForEach」アクティビティに戻ります。「設定」タブの「項目」を次のように設定します。
@variables('SheetName')

2.2 「データのコピー」アクティビティの設定
「ForEach」アクティビティを設定したら、内部でループする処理として「データのコピー」アクティビティを配置します。ForEachアクティビティをダブルクリックすると、配置画面が新しく表示される配置することができます。名前を「CopyExcelSheet」とします。
2.3 「データのコピー」アクティビティのソースの設定
続いて、「データのコピー」アクティビティのプロパティ情報を入力します。そして、「ソース」->「ソースデータセット」で「+新規」を選択します。ここでは、コピー元となるExcelのデータセットを作成します。なお、「パターン2:専用SQLプールの複数のテーブルに対し、Excelの複数のシートをそれぞれ取り込む方法」で作成するDatasetMultisheetを既に作成されている方はそのまま活用することができます。作成されていない方は、パターン2の作成手順を一読ください。
作成または現段階で既存にDatasetMultisheetがある方は、「ソースデータセット」のプルダウンから、DatasetMultisheetを選択します。そいて、データセットのプロパティを次のように指定します。
@item()
| 項目名 | 設定内容 |
|---|---|
| 名前 | SheetName |
| 値 | @item() |
 |
2.4 「データのコピー」アクティビティのシンクの設定
続いて、「データのコピー」アクティビティのシンクの設定を行います。「シンク」->「シンクデータセット」で「+新規」を選択します。ここでは、シンク先となるテーブルのデータセットを作成します。そのため、「Azure Synapseの専用SQLプール」を選択します。ここでは以下のように設定し、「OK」を選択します。
| 項目名 | 設定内容 |
|---|---|
| 名前 | MergeMultiSqlPoolTable |
| SQLプール | d_sql |
| テーブル名 | dbo.SinkMergeTable |
| 「シンク」タブに戻り、「Copyメソッド」の項目を「一括挿入」にします。 | |
| ※Copy コマンドを使用してデータを直接 SQL プール にコピーすることは、このソースの種類ではサポートされていません。 | |
 |
|
これで「検証」を行った後に、「デバッグ」をクリックして実行してみましょう。
|
|
| 実行が完了し、dbo.SinkMergeTableテーブルの中身を見たときに次のように2020年、2021年のデータがどちらもあれば成功でExcelの複数シートを専用SQLプールの1つのテーブルにマージして読み込むことができたため、パターン3は成功です。 | |
| ※idが重なっておりますが、ダミーデータなので出席番号程度に思ってください:pray: | |
 |
|
| Fin. |
最後に
本記事は、主にシート数が少ないExcelデータの扱いに対して、Azure FunctionsやPythonでのデータ処理を用いずに複数シートをSynapseの専用SQLプールのテーブルにコピーすることを目的に執筆しました。これにより、新たに他の知識(言語やサービス)を学習する必要なくなったことや、Functions実行にかかる金銭面でのコストや、コーディング・デバッグにかかる時間のコストを抑えることができます。
読んで頂きましてありがとうございました😊
ご質問やご感想などありましたら、ぜひTwitter (@shisyu_gaku) までお気軽にお問い合わせください。
Discussion