uv環境でESPnetの推論スクリプトを実行
uvのインストールはこちら
tts.py
import soundfile
from espnet2.bin.tts_inference import Text2Speech
text2speech = Text2Speech.from_pretrained("kan-bayashi/ljspeech_vits")
text = "Hello, this is a text-to-speech test using ESPnet. Does my speech sound good?"
speech = text2speech(text)["wav"]
soundfile.write("output.wav", speech.numpy(), text2speech.fs, "PCM_16")
uv run --with espnet --with soundfile tts.py

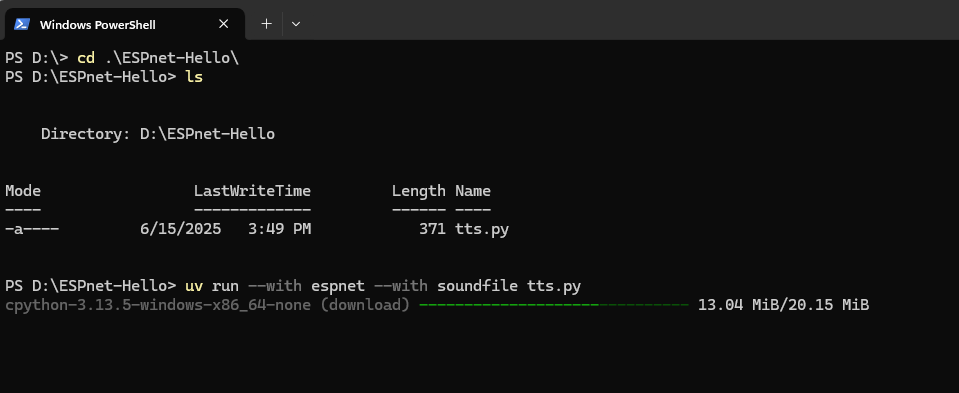
x Failed to build `ctc-segmentation==1.7.4`
|-> The build backend returned an error
`-> Call to `setuptools.build_meta:__legacy__.build_wheel` failed (exit code: 1)
[stdout]
running bdist_wheel
running build
running build_py
creating build\lib.win-amd64-cpython-313\ctc_segmentation
copying ctc_segmentation\ctc_segmentation.py -> build\lib.win-amd64-cpython-313\ctc_segmentation
copying ctc_segmentation\partitioning.py -> build\lib.win-amd64-cpython-313\ctc_segmentation
copying ctc_segmentation\__init__.py -> build\lib.win-amd64-cpython-313\ctc_segmentation
running build_ext
building 'ctc_segmentation.ctc_segmentation_dyn' extension
[stderr]
C:\Users\zzxia\AppData\Local\uv\cache\builds-v0\.tmpodXSzV\Lib\site-packages\setuptools\_distutils\dist.py:289: UserWarning: Unknown
distribution option: 'tests_require'
warnings.warn(msg)
error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools":
https://visualstudio.microsoft.com/visual-cpp-build-tools/
hint: This usually indicates a problem with the package or the build environment.
help: `ctc-segmentation` (v1.7.4) was included because `espnet` (v202412) depends on `ctc-segmentation`
パッケージをインストールする前に、先にPythonをインストールする必要です。
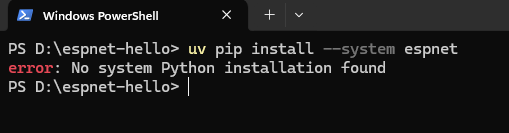
Python 3.10の仮想環境を作成します。
uv venv -p 3.10


ESPnetとsoundfileをインストールします。
uv pip install espnet soundfile

同じエラーが出ました。

Perplexity.aiに聞いてみました。
Visual C++ 14.0以上が入っていなくてctc-segmentationがビルドできなかったようです。
error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/
上記のリンクを踏んでインストールすればよさそうです。
Visual Studio Build Tools 2022をインストールしました。


もう一度espnetとsoundfileをインストールしてみます。
さっき失敗したところから再開しました。

インストールが成功しました。
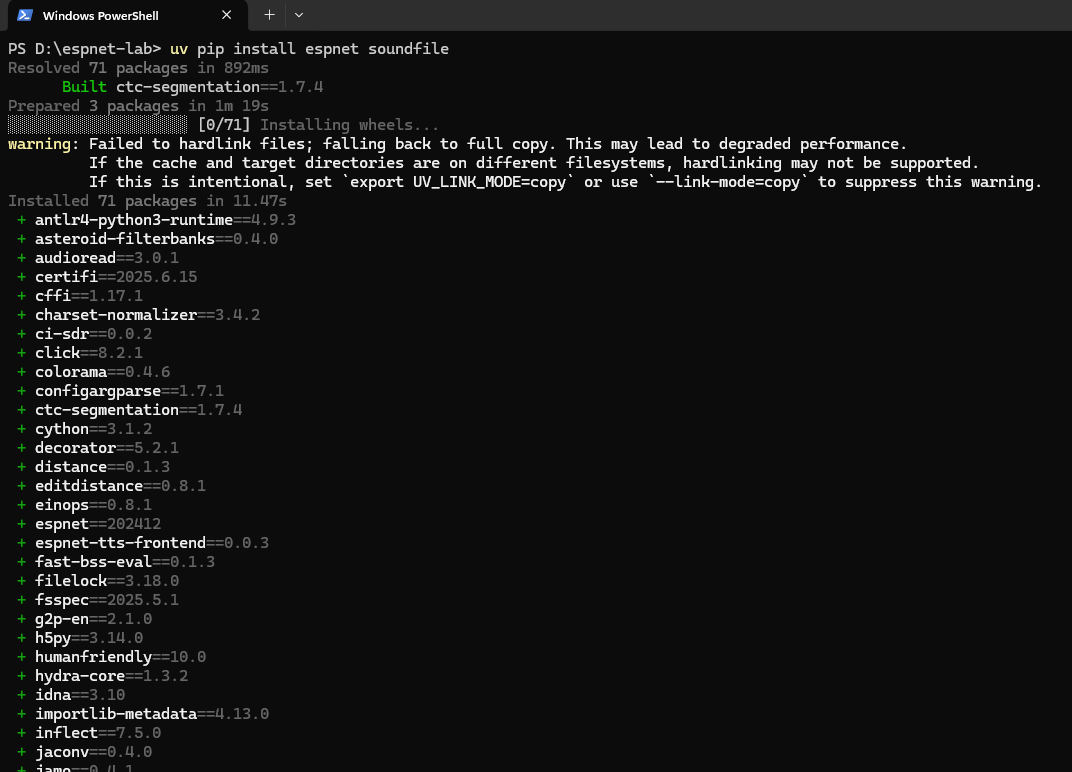
.venvが生成されました。
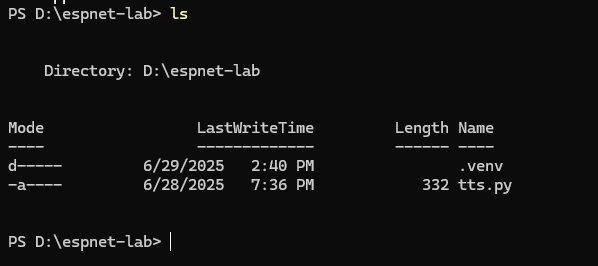
なんと1.5GBが取られました。
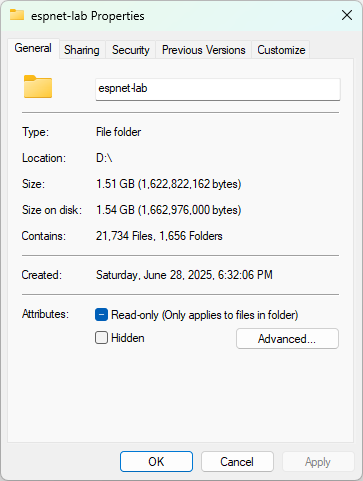
uv pip installの時に以下の警告メッセージが出ました。
warning: Failed to hardlink files; falling back to full copy. This may lead to degraded performance.
If the cache and target directories are on different filesystems, hardlinking may not be supported.
If this is intentional, set `export UV_LINK_MODE=copy` or use `--link-mode=copy` to suppress this warning.
キャッシュフォルダと仮想環境フォルダが別々のファイルシステム(ディスク)にあるのは原因のようです。
uv cache dir

それぞれ同じコピーのパッケージがインストールされています。スペースがもったいないです。

uvのキャッシュについての公式資料は以下を参照
UV_CACHE_DIR環境変数を定義しました。

もう一度uv venv -p 3.10から環境を作り直します。
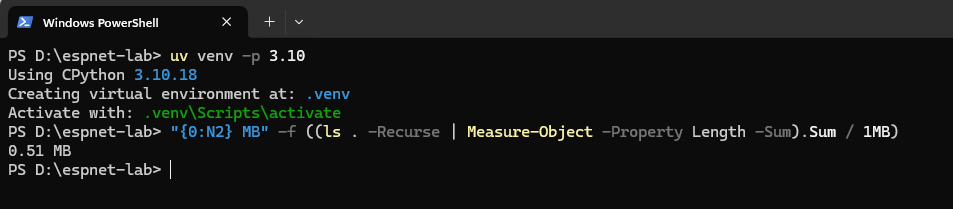
警告メッセージが消えました。
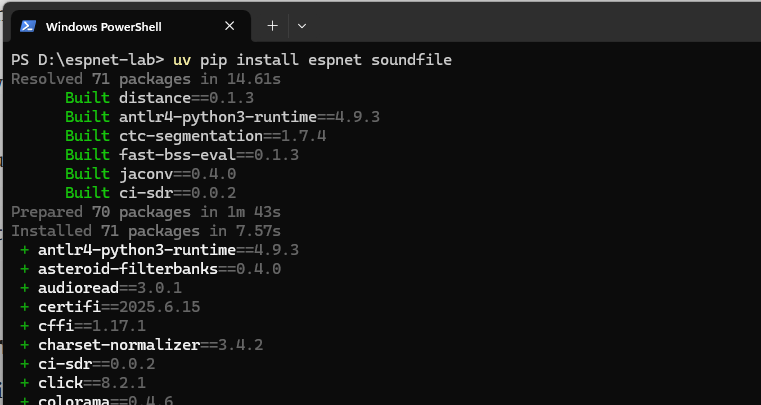
uv run tts.py
touchaudioもインストールする必要です。

uv pip install torchaudio

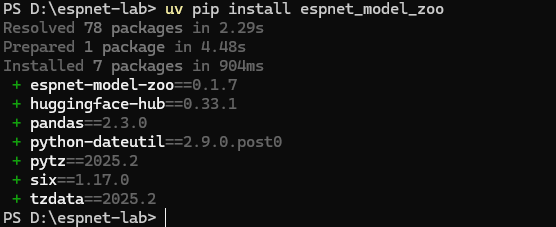
espnet_model_zooも必要です。

flash_attnもインストールしたほうがよさそうです。
flash_attnをインストールする時にtorchが見つからなくて怒られました。
でもespnetをインストールするときにtorchはインストールされたはずです。
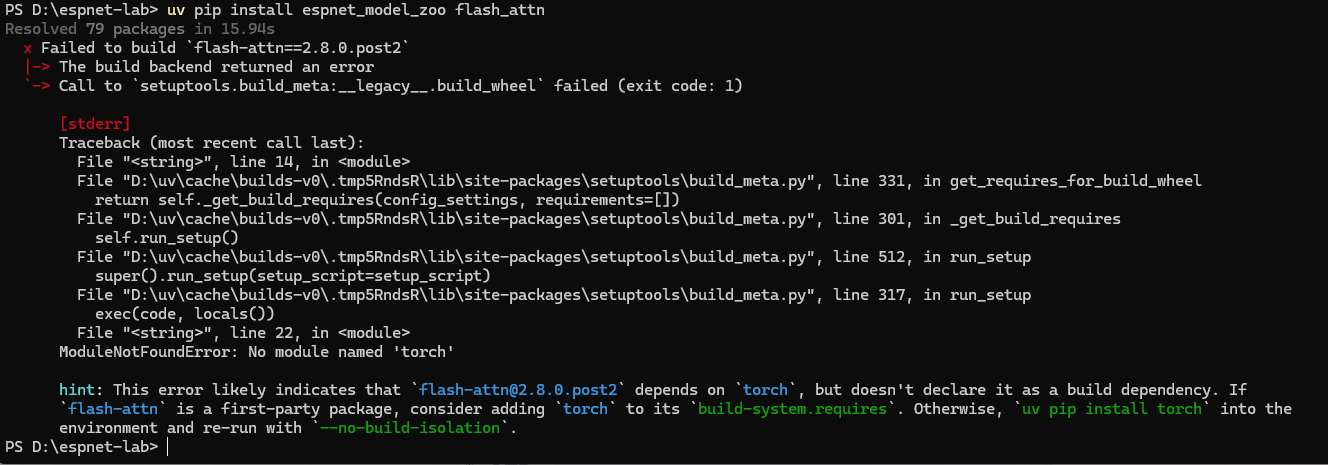
torchのバージョンが高すぎるかもしれません。

torch 2.6.0をインストールしてもダメです。
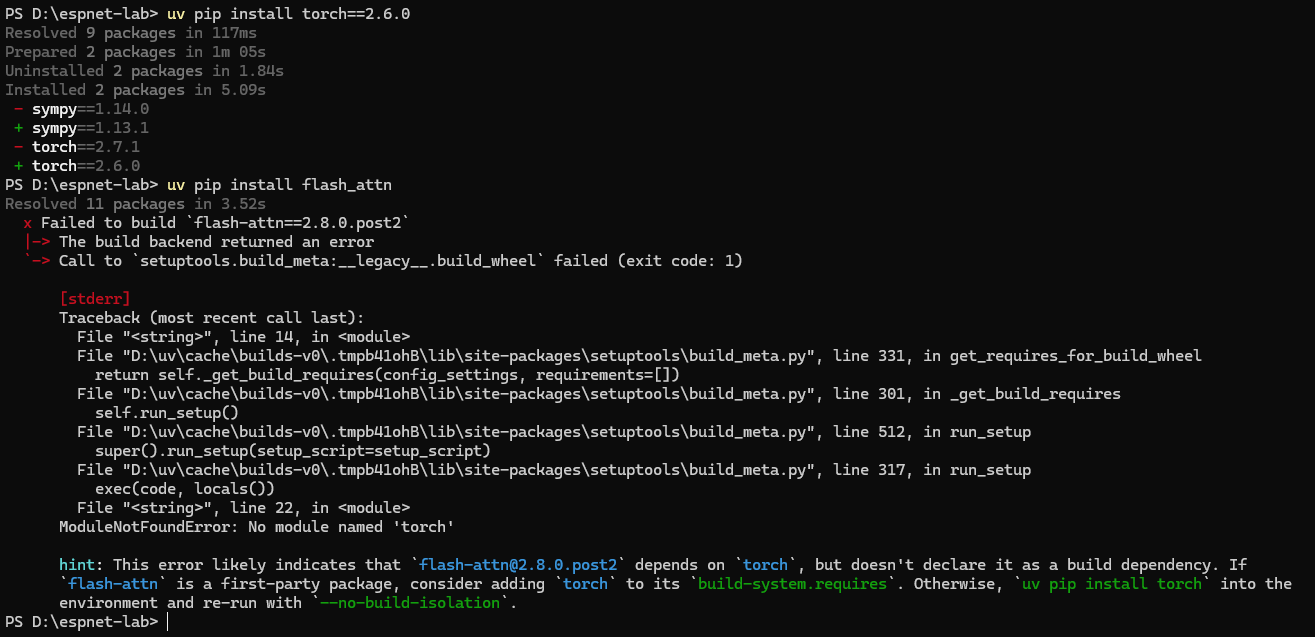
原因はこちらに記載してあります。
flash_attnをなしに実行してみましたが、import Text2Speech2のところにエラーが出ました。
OSError: [WinError 127] The specified procedure could not be found

torchのバージョンを戻します。

別のエラーが出ました。nltk_dataが見つからなかったです。
PS D:\espnet-lab> uv run .\tts.py
Failed to import Flash Attention, using ESPnet default: No module named 'flash_attn'
https://zenodo.org/record/5443814/files/tts_train_vits_raw_phn_tacotron_g2p_en_no_space_train.total_count.ave.zip?download=1: 100%|█| 356M/356M [02:5
D:\espnet-lab\.venv\lib\site-packages\espnet_model_zoo\downloader.py:364: UserWarning: Not validating checksum
warnings.warn("Not validating checksum")
D:\espnet-lab\.venv\lib\site-packages\torch\nn\utils\weight_norm.py:143: FutureWarning: `torch.nn.utils.weight_norm` is deprecated in favor of `torch.nn.utils.parametrizations.weight_norm`.
WeightNorm.apply(module, name, dim)
D:\espnet-lab\.venv\lib\site-packages\espnet2\gan_tts\vits\monotonic_align\__init__.py:19: UserWarning: Cython version is not available. Fallback to 'EXPERIMETAL' numba version. If you want to use the cython version, please build it as follows: `cd espnet2/gan_tts/vits/monotonic_align; python setup.py build_ext --inplace`
warnings.warn(
WARNING:root:It seems weight norm is not applied in the pretrained model but the current model uses it. To keep the compatibility, we remove the norm from the current model. This may cause unexpected behavior due to the parameter mismatch in finetuning. To avoid this issue, please change the following parameters in config to false:
- discriminator_params.follow_official_norm
- discriminator_params.scale_discriminator_params.use_weight_norm
- discriminator_params.scale_discriminator_params.use_spectral_norm
See also:
- https://github.com/espnet/espnet/pull/5240
- https://github.com/espnet/espnet/pull/5249
Traceback (most recent call last):
File "D:\espnet-lab\tts.py", line 5, in <module>
speech = text2speech(text)["wav"]
File "D:\espnet-lab\.venv\lib\site-packages\torch\utils\_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
File "D:\espnet-lab\.venv\lib\site-packages\espnet2\bin\tts_inference.py", line 173, in __call__
text = self.preprocess_fn("<dummy>", dict(text=text))["text"]
File "D:\espnet-lab\.venv\lib\site-packages\espnet2\train\preprocessor.py", line 548, in __call__
data = self._text_process(data)
File "D:\espnet-lab\.venv\lib\site-packages\espnet2\train\preprocessor.py", line 483, in _text_process
tokens = self.tokenizer.text2tokens(text)
File "D:\espnet-lab\.venv\lib\site-packages\espnet2\text\phoneme_tokenizer.py", line 623, in text2tokens
tokens = self.g2p(line)
File "D:\espnet-lab\.venv\lib\site-packages\espnet2\text\phoneme_tokenizer.py", line 260, in __call__
phones = self.g2p(text)
File "D:\espnet-lab\.venv\lib\site-packages\g2p_en\g2p.py", line 162, in __call__
tokens = pos_tag(words) # tuples of (word, tag)
File "D:\espnet-lab\.venv\lib\site-packages\nltk\tag\__init__.py", line 168, in pos_tag
tagger = _get_tagger(lang)
File "D:\espnet-lab\.venv\lib\site-packages\nltk\tag\__init__.py", line 110, in _get_tagger
tagger = PerceptronTagger()
File "D:\espnet-lab\.venv\lib\site-packages\nltk\tag\perceptron.py", line 183, in __init__
self.load_from_json(lang)
File "D:\espnet-lab\.venv\lib\site-packages\nltk\tag\perceptron.py", line 273, in load_from_json
loc = find(f"taggers/averaged_perceptron_tagger_{lang}/")
File "D:\espnet-lab\.venv\lib\site-packages\nltk\data.py", line 579, in find
raise LookupError(resource_not_found)
LookupError:
**********************************************************************
Resource averaged_perceptron_tagger_eng not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('averaged_perceptron_tagger_eng')
For more information see: https://www.nltk.org/data.html
Attempted to load taggers/averaged_perceptron_tagger_eng/
Searched in:
- 'C:\\Users\\zzxia/nltk_data'
- 'D:\\espnet-lab\\.venv\\nltk_data'
- 'D:\\espnet-lab\\.venv\\share\\nltk_data'
- 'D:\\espnet-lab\\.venv\\lib\\nltk_data'
- 'C:\\Users\\zzxia\\AppData\\Roaming\\nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
**********************************************************************
PS D:\espnet-lab>
D:\espnet-labフォルダに、以下のPythonスクリプトを作成し実行します。
import nltk
nltk.download('averaged_perceptron_tagger_eng')
またCドライブにダウンロードされました。
PS D:\espnet-lab> & D:/espnet-lab/.venv/Scripts/python.exe d:/espnet-lab/download_nltk_data.py
[nltk_data] Downloading package averaged_perceptron_tagger_eng to
[nltk_data] C:\Users\zzxia\AppData\Roaming\nltk_data...
[nltk_data] Unzipping taggers\averaged_perceptron_tagger_eng.zip.
PS D:\espnet-lab>
Dドライブの仮想環境に移動します。
mv C:\Users\zzxia\AppData\Roaming\nltk_data .\.venv\
確認
PS D:\espnet-lab> ls .\.venv\ | select-string nltk
nltk_data
PS D:\espnet-lab>
やっとtts.pyを実行できました。
PS D:\espnet-lab> uv run .\tts.py
Failed to import Flash Attention, using ESPnet default: No module named 'flash_attn'
D:\espnet-lab\.venv\lib\site-packages\torch\nn\utils\weight_norm.py:143: FutureWarning: `torch.nn.utils.weight_norm` is deprecated in favor of `torch.nn.utils.parametrizations.weight_norm`.
WeightNorm.apply(module, name, dim)
D:\espnet-lab\.venv\lib\site-packages\espnet2\gan_tts\vits\monotonic_align\__init__.py:19: UserWarning: Cython version is not available. Fallback to 'EXPERIMETAL' numba version. If you want to use the cython version, please build it as follows: `cd espnet2/gan_tts/vits/monotonic_align; python setup.py build_ext --inplace`
warnings.warn(
WARNING:root:It seems weight norm is not applied in the pretrained model but the current model uses it. To keep the compatibility, we remove the norm from the current model. This may cause unexpected behavior due to the parameter mismatch in finetuning. To avoid this issue, please change the following parameters in config to false:
- discriminator_params.follow_official_norm
- discriminator_params.scale_discriminator_params.use_weight_norm
- discriminator_params.scale_discriminator_params.use_spectral_norm
See also:
- https://github.com/espnet/espnet/pull/5240
- https://github.com/espnet/espnet/pull/5249
PS D:\espnet-lab> ls
Directory: D:\espnet-lab
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 6/29/2025 4:06 PM .venv
-a---- 6/29/2025 4:03 PM 60 download_nltk_data.py
-a---- 6/29/2025 4:08 PM 255532 output.wav
-a---- 6/28/2025 7:36 PM 332 tts.py
PS D:\espnet-lab>
uv pip installよりuv addがいいかもしれません。
uv addを使うにはpyproject.tomlが必要です。