Claudeの拡張思考機能:AIの思考プロセスを可視化する新技術
はじめに
Claude 3.7 Sonnetがリリースされ話題になりました。
本記事ではその中でも拡張思考機能(extended thinking)について紹介されている記事についてまとめました。
Claude 3.7 Sonnetについては以下の記事で詳細を紹介しています。
サマリ
Anthropicは2025年2月に、Claude 3.7 Sonnetに「拡張思考モード」を導入しました。この革新的な機能により、AIは複雑な問題に対してより多くの時間と計算リソースを費やして考えることができるようになり、その思考プロセスをユーザーが観察できるようになりました。この透明性はAIへの信頼性を高める一方で、思考プロセスの忠実性や安全性に関する課題も生じています。
拡張思考機能により、Claude 3.7 Sonnetは標準的な評価テストだけでなく、ゲームプレイやコンピュータ操作といった複雑なタスクでも顕著な性能向上を示しています。同時に、Anthropicはモデルの能力向上に伴い、可視思考プロセスの管理や「プロンプトインジェクション」攻撃への対策など、安全対策も強化しています。この新機能は、AIとユーザー間のコミュニケーションに新たな次元をもたらし、より深い協力関係を可能にする重要な進歩です。
拡張思考モードとは
人間の思考には様々な特性があります。「今日は何曜日?」のような質問には瞬時に答えられますが、複雑な暗号クロスワードを解いたり、複雑なコードのデバッグをしたりする場合には、より多くの精神的な体力が必要になります。私たちは目の前のタスクに応じて、より多くまたは少ない認知的努力を適用することを選択できます。
新しいClaude 3.7 Sonnetでは、このような柔軟性がAIにも実装されました。ユーザーは「拡張思考モード」をオンまたはオフに切り替えることができ、より複雑な質問に対してモデルがより深く考えるよう指示することができます。開発者は「思考予算」を設定して、Claudeが問題に費やす時間を正確に制御することも可能です。
拡張思考モードは異なるモデルに切り替えるオプションではありません。同じモデルがより多くの時間をかけ、答えに到達するためにより多くの努力を費やすことを可能にするものです。
思考プロセスの可視化
Claudeに長時間の思考とより困難な質問への回答能力を与えるだけでなく、その思考プロセスを生の形で可視化することにしました。これには以下のような利点があります:
- 信頼性: Claudeがどのように考えるかを観察できることで、その回答を理解し確認しやすくなり、ユーザーはより良い出力を得られる可能性があります。
- アライメント: 以前のアライメントサイエンス研究では、モデルが内部で考えていることと外部で言うことの間の矛盾を使用して、欺瞞などの懸念される行動に関与している可能性を特定しました。
- 興味深さ: Claudeの思考を観察することは魅力的です。数学や物理学のバックグラウンドを持つ研究者の中には、複雑な問題を推論する際のClaudeの思考プロセスが、多くの異なる角度や推論の枝を探索し、結果を二重三重にチェックするなど、自分たちの推論方法と非常に似ていることに気づいた人もいます。
しかし、思考プロセスを可視化することには、いくつかのデメリットもあります:
- ユーザーは、開示された思考がClaudeのデフォルト出力よりも客観的で個人的でない印象を受ける可能性があります。これは、モデルの思考プロセスに標準的な「キャラクター」トレーニングを行わなかったためです。
- 「忠実性(faithfulness)」の問題があります。思考プロセスに表示されるものが本当にモデルの心の中で起きていることを表しているかどうかは確実ではありません。
- いくつかの安全性とセキュリティの懸念があります。悪意のある行為者が、可視化された思考プロセスを使用してClaudeをジェイルブレイク(制約を回避)するためのより良い戦略を構築する可能性があります。
これらの懸念は、将来のより高性能なバージョンのClaudeでは特に重要になるでしょう。現時点では、Claude 3.7 Sonnetの可視思考プロセスは研究プレビューとして考えられるべきです。
Claudeの思考能力に関する新しいテスト
エージェントとしてのClaude
Claude 3.7 Sonnetは「アクションスケーリング」と呼べる改善された能力から恩恵を受けています。これにより、関数を反復的に呼び出し、環境の変化に応答し、オープンエンドのタスクが完了するまで継続することができます。コンピュータの使用はこのようなタスクの一例です:Claudeはユーザーに代わってタスクを解決するために、仮想的なマウスクリックやキーボード入力を発行できます。
前モデルと比較して、Claude 3.7 Sonnetはコンピュータ使用タスクにより多くのターン(およびより多くの時間と計算能力)を割り当てることができ、その結果は多くの場合より優れています。
これはOSWorldという評価で見ることができます。OSWorldはマルチモーダルAIエージェントの能力を測定するものです。Claude 3.7 Sonnetは最初からやや優れていますが、モデルが仮想コンピュータとの対話を続けるにつれて、パフォーマンスの差が拡大します。

Claudeの拡張思考とエージェントトレーニングにより、OSWorldのような標準的な評価で良好な結果が得られるだけでなく、他の予期せぬタスクでも大幅な向上が見られます。
例えば、ポケモン(特にGame Boy用のポケモン赤)をプレイすることもそのようなタスクの一つです。Claudeに基本的なメモリ、画面ピクセル入力、ボタンを押したり画面上を移動したりするための関数呼び出しを装備させることで、通常のコンテキスト制限を超えて継続的にポケモンをプレイさせることができ、数万回の相互作用を通じてゲームプレイを維持することができます。
以下のグラフでは、Claude 3.7 Sonnetのポケモン進行状況を、拡張思考オプションがなかった以前のバージョンのClaude Sonnetと比較しています。前バージョンはゲームの非常に早い段階で行き詰まり、Claude 3.0 Sonnetはストーリーが始まるマサラタウンの家から出ることさえできませんでした。
しかし、Claude 3.7 Sonnetの改善されたエージェント能力により、はるかに先に進むことができ、3人のポケモンジムリーダー(ゲームのボス)と戦い、バッジを獲得することに成功しました。Claude 3.7 Sonnetは複数の戦略を試し、以前の仮定に疑問を投げかけることが非常に効果的で、それにより進行するにつれて自身の能力を向上させることができます。
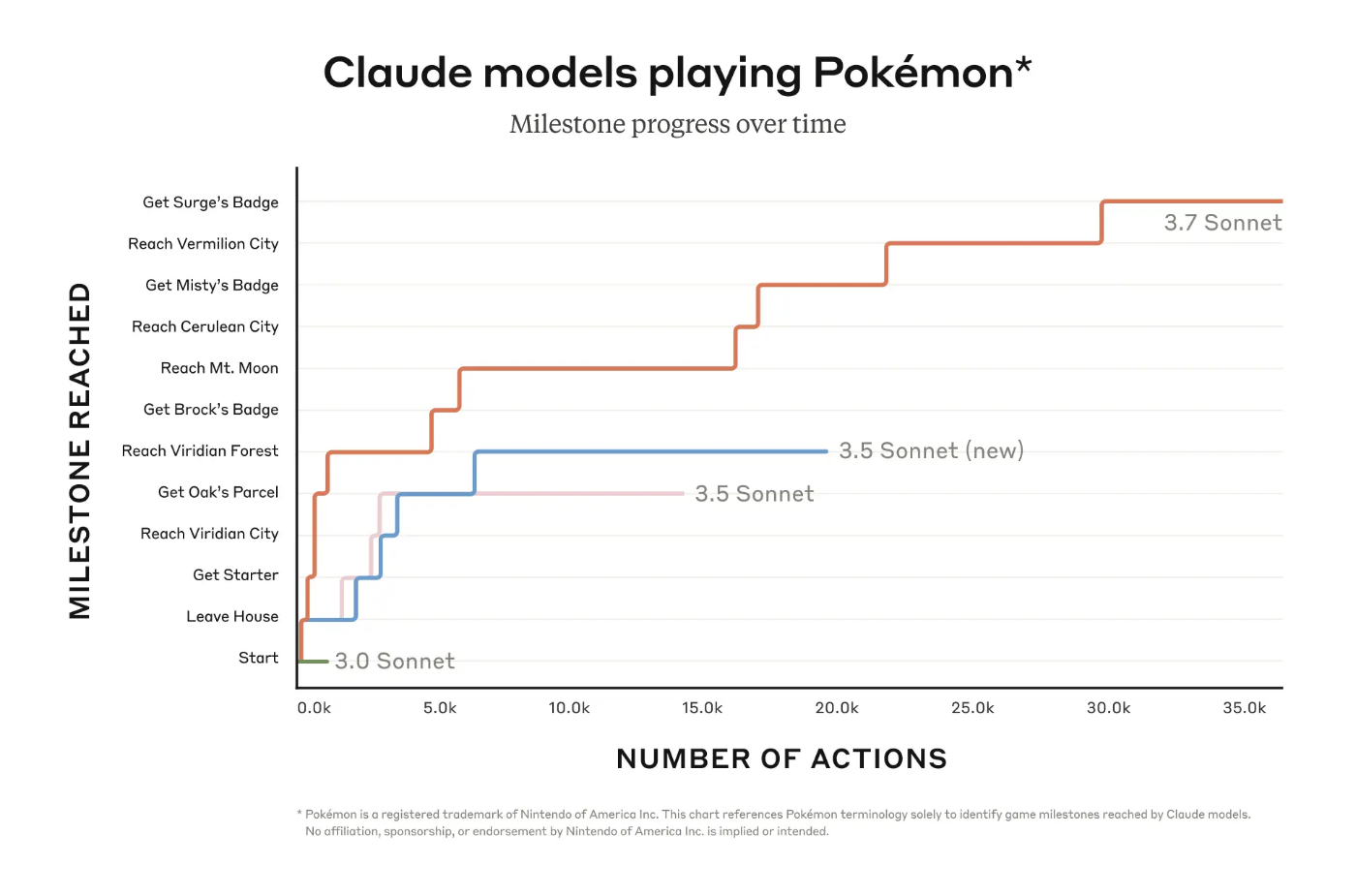
ポケモンはClaude 3.7 Sonnetの能力を評価する楽しい方法ですが、これらの能力はゲームプレイを超えた現実世界への影響を持つことが期待されます。モデルの集中力を維持し、オープンエンドの目標を達成する能力は、開発者が幅広い最先端AIエージェントを構築するのに役立つでしょう。
シリアルおよび並列テスト時計算スケーリング
Claude 3.7 Sonnetが拡張思考機能を使用する場合、「シリアルテスト時計算」の恩恵を受けていると説明できます。つまり、最終出力を生成する前に、複数の連続的な推論ステップを使用し、進行するにつれてより多くの計算リソースを追加します。一般的に、これはパフォーマンスを予測可能な方法で向上させます:例えば、数学の質問に対する精度は、サンプリングが許可される「思考トークン」の数に対して対数的に向上します。

研究者たちは、並列テスト時計算を使用してモデルのパフォーマンスを向上させる実験も行っています。複数の独立した思考プロセスをサンプリングし、事前に真の答えを知ることなく最良のものを選択します。
このような戦略を使用して、GPQA評価(生物学、化学、物理学に関する一般的に使用される難しい質問のセット)で顕著な改善を達成しました。256の独立したサンプルの同等の計算、学習したスコアリングモデル、および最大64kトークンの思考予算を使用して、Claude 3.7 Sonnetは84.8%のGPQAスコア(物理学のサブスコアは96.5%)を達成し、多数決の限界を超えた継続的なスケーリングから恩恵を受けました。
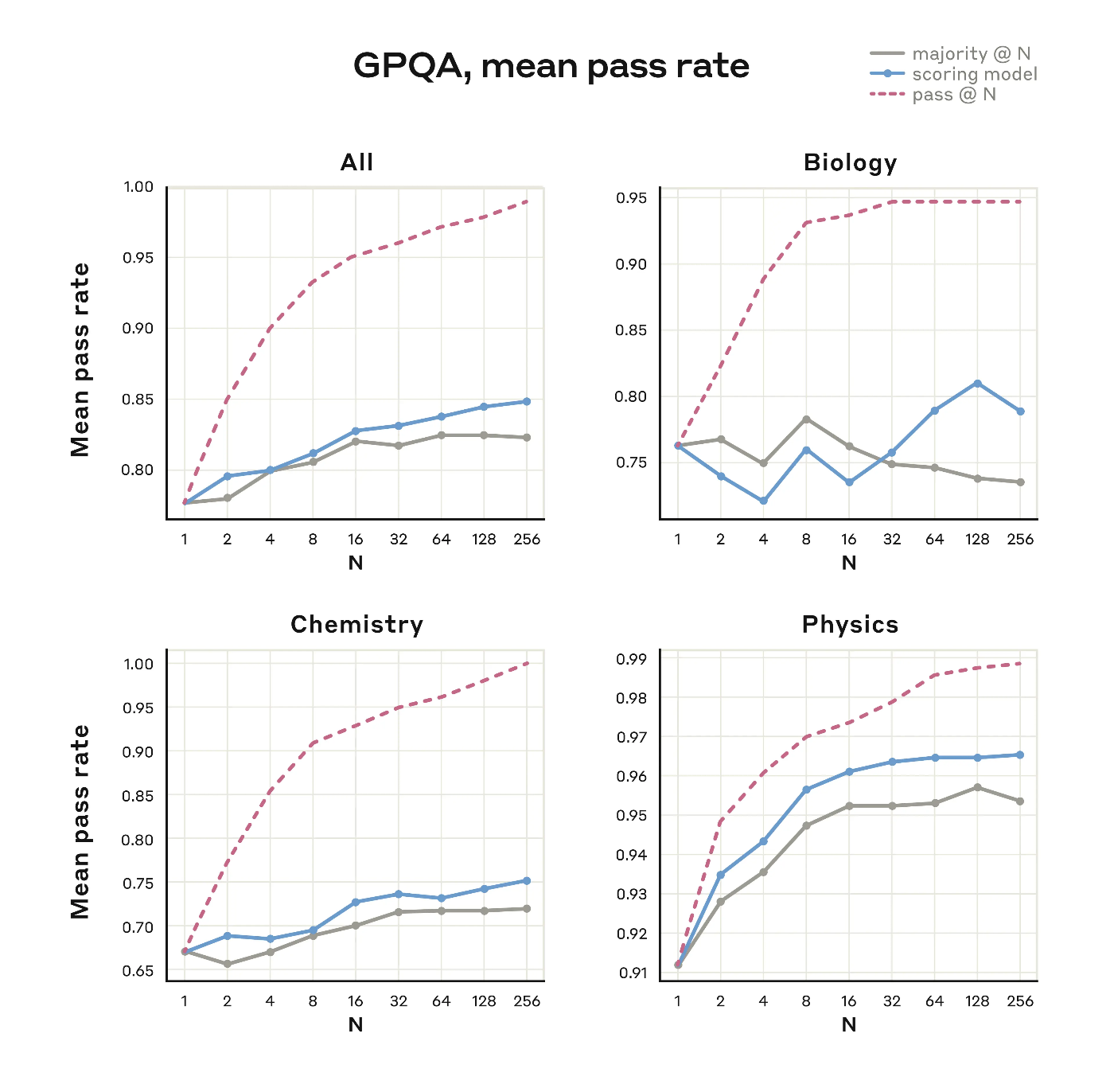
このような方法により、Claudeの回答の質を向上させることができ、通常は思考が終わるのを待つ必要もありません。Claudeは同時に複数の異なる拡張思考プロセスを持つことができ、問題へのより多くのアプローチを検討し、最終的にはより正確に解答することができます。
並列テスト時計算スケーリングは新しくデプロイされたモデルでは利用できませんが、将来のためにこれらの方法の研究を継続しています。
Claude 3.7 Sonnetの安全メカニズム
AI安全レベル
Anthropicの責任あるスケーリングポリシーでは、適切な安全性とセキュリティ対策を実施しない限り、モデルをトレーニングまたはデプロイしないことを約束しています。フロンティアレッドチームとアライメントストレステストチームは、Claude 3.7 Sonnetに対して広範なテストを実施し、AI安全レベル(ASL)2標準として知られる前モデルと同じレベルのデプロイメントとセキュリティ対策が必要かどうか、またはより強力な対策が必要かどうかを判断しました。
Claude 3.7 Sonnetの包括的な評価により、現在のASL-2安全基準が適切であることが確認されました。同時に、このモデルはすべての領域でより高度な洗練性と能力を示しました。
将来のモデルの能力によっては、次の段階であるASL-3セーフガードに移行する必要があるかもしれません。ジェイルブレイクを防止するための最近の「Constitutional Classifiers」の取り組みなど、近い将来ASL-3基準の要件を実装する準備が整っています。
可視思考プロセス
ASL-2であっても、Claude 3.7 Sonnetの可視拡張思考機能は新しいものであり、適切な保護対策が必要です。稀なケースでは、Claudeの思考プロセスに子供の安全、サイバー攻撃、危険な武器など、潜在的に有害なコンテンツが含まれる可能性があります。
そのような場合、思考プロセスを暗号化します:これはClaudeが思考プロセスにコンテンツを含めることを妨げるものではなく(これは完全に無害な応答を最終的に生成するために重要である可能性があります)、思考プロセスの関連部分はユーザーに表示されません。代わりに、「このレスポンスの残りの思考プロセスは利用できません」というメッセージが表示されます。
Computer use
最後に、Claudeのコンピュータ使用能力に対する安全対策を強化しました。「プロンプトインジェクション」攻撃に対する防御に大きな進歩がありました。これは、悪意のある第三者がコンピュータを使用中にClaudeが見る可能性のある場所に秘密のメッセージを隠し、ユーザーが意図しなかったアクションを取るよう騙す可能性があるものです。
プロンプトインジェクションに抵抗するための新しいトレーニング、これらの攻撃を無視するよう指示する新しいシステムプロンプト、およびモデルが潜在的なプロンプトインジェクションに遭遇したときに作動する分類器により、現在これらの攻撃を88%の確率で防止しています(緩和策なしの場合の74%から上昇)。
Discussion