RAGにおけるRerankモデルの役割と最新の動向
はじめに
近年、Retrieval Augmented Generation (RAG) が注目されています。RAGは、大規模言語モデル (LLM) の生成能力と情報検索技術を組み合わせることで、LLM単体よりも正確で信頼性の高いテキスト生成を可能にする技術です。RAGでは、質問に対して関連する文書をデータベースなどから検索し、その情報をLLMへの入力として利用して回答を生成します。
ただし、この検索の段階では、キーワードの一致や単純なベクトル類似度で文書が選ばれるため、質問との関連度が必ずしも高くない情報が選ばれることもあります。また、LLMは入力された情報を基に回答を生成しますが、関連性の低い文書が含まれていると、不正確な情報を生成する可能性があります。
こうした課題を解決するために、rerankモデルが役立ちます。rerankモデルは、初期検索で得られた文書群の関連度を再評価し、LLMへの入力として適切な情報を選ぶことで、より質の高い回答生成をサポートします。
RAGの基本フローとRerankの位置づけ
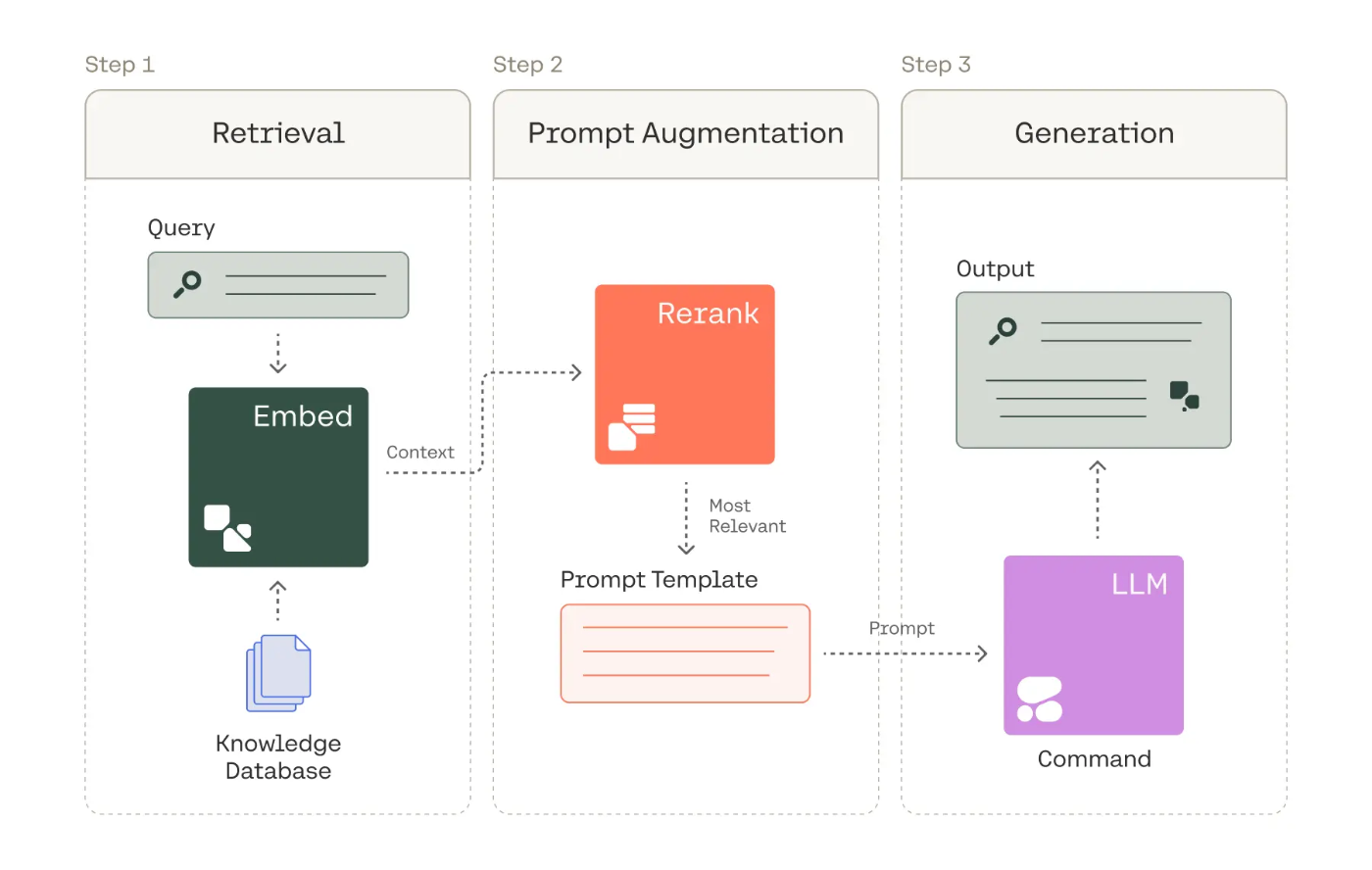
RAGのプロセスは一般的に次のようなステップで構成されています:
-
Retrieval(検索): ユーザークエリに基づいて、大規模なドキュメント集合から初期候補となる関連文書を取得します。これは通常、BM25やベクトル検索などの比較的シンプルで高速な方法で行われます。
-
Rerank: 最初の検索で得られた候補文書を、より精密な方法で再評価します。単なるキーワード一致やベクトル類似性を超えて、セマンティックな関連性を評価します。
-
Generation(生成): rerankされた文書を参照情報として使用し、LLM(大規模言語モデル)がユーザークエリに対する回答を生成します。
Introducing Rerank 3.5: Precise AI Search
RAGにおけるRerankモデルの役割と重要性
rerankモデルがRAGシステムに不可欠である主な理由は以下の通りです:
-
検索精度の向上: 初期検索では、キーワードの一致や単純なベクトル類似度に基づいて文書が検索されるため、文脈や意味を十分に考慮できない場合があります。rerankモデルは、より高度な意味理解能力を用いることで、質問との関連度をより正確に評価し、検索精度を向上させます。
-
効率とコスト: 全文書に対して高度な関連性判定を行うと計算コストが高すぎるため、まず簡易検索で候補を絞り込み、そこから重要な文書だけを選択することで効率化します。
-
ハルシネーションの抑制: LLMは、入力された情報に基づいて回答を生成しますが、入力情報に関連性の低い文書が含まれている場合、事実とは異なる情報や誤った情報を生成する可能性があります。rerankモデルは、関連性の低い文書を排除することで、ハルシネーションの発生を抑制します。
-
文脈理解: rerankモデルは単語の一致だけでなく、クエリと文書の間の意味的な関連性を捉えることができます。
-
LLMの効率的な利用: LLMは、入力される情報の量が多いほど計算コストが高くなります。rerankモデルは、LLMへの入力となる文書を厳選することで、LLMの計算コストを削減し、効率的な利用を促進します。
Rerankモデルのアーキテクチャと代表的手法
Cross-encoder vs. Bi-encoder
rerankモデルを理解する前に、テキストの類似度を計算するための2つの主要なアプローチであるCross-encoderとBi-encoderの違いを理解することが重要です。
| アプローチ | 利点 | 欠点 |
|---|---|---|
| Cross-encoder | 高精度: 2つのテキストを同時にエンコードし、テキスト間の相互作用を直接モデル化 | 計算コストが高い: 各ペアを個別に処理する必要がある。 クエリごとに全文書との組み合わせを再計算するため、大規模データセットでは処理時間が増大 |
| Bi-encoder | 計算効率: 各テキストを独立してエンコードし、以下の利点がある: - 文書を事前にエンコードして保存可能なため、クエリ時の計算量を大幅に削減 - ベクトルデータベースと連携し、近似最近傍探索(ANN)などの高速アルゴリズムが利用可能 - 数百万〜数十億の文書に対してもスケーラブルに検索可能 - クエリのエンコードだけで類似度計算ができるため応答時間が短い |
精度が低い: テキスト間の相互作用を十分に捉えられず、微妙な意味の違いや文脈依存の関連性を見逃すことがある |
Bi-encoderの最大の強みは、検索対象となる文書を事前にエンコードしてベクトルデータベースに保存できる点にあります。検索時には、クエリのみをエンコードし、保存済みの文書ベクトルとの類似度計算を行うため、リアルタイム処理の計算コストが大幅に削減されます。例えば、1,000万件の文書に対する検索であっても、事前にインデックス化されていれば数ミリ秒で結果を返すことが可能です。また、FAISS、Annoy、SCaNNなどの近似最近傍検索ライブラリとの組み合わせにより、精度をほとんど犠牲にせずに検索速度をさらに向上させることができます。

Bi-Encoder (左) と Cross-Encoder (右)
RAGでは、一般的にBi-encoderを用いて初期検索を行い、Cross-encoderを用いてre-rankを行うことで、精度と効率のバランスをとっています。
より詳細を知りたい場合は以下の記事をご確認ください。
従来のLearning-to-Rank (LTR) モデル
従来のLTRモデルは、教師あり学習を用いて検索結果を並べ替えるための機械学習モデルです。用語頻度、逆文書頻度、意味的類似度などの特徴に基づいて訓練されます。LTRモデルは主に以下の3つのタイプに分類されます。
- Pointwiseモデル: 各文書を独立してスコアリング(線形回帰やニューラルネットワークなど)
- Pairwiseモデル: 文書のペアを比較して順序を学習(RankNetなど)
- Listwiseモデル: リスト全体を考慮してランキングを最適化(LambdaMARTなど)
BERT
BERT (Bidirectional Encoder Representations from Transformers) は、Googleが開発した自然言語処理モデルです。rerankモデルとして利用する場合、質問と文書のペアを入力として受け取り、関連度をスコアとして出力します。
- 双方向性: 前後の文脈を考慮した単語表現により深い理解が可能
- ファインチューニング: 特定タスク向けに調整可能
Sentence-BERT
Sentence-BERTは、BERTをベースに文全体の表現を獲得するよう改良されたモデルです。質問と文書をそれぞれベクトル化し、その類似度を計算します。
- 効率性: 文全体を1つのベクトルで表現するため計算効率が高い
- 事前学習の活用: 少ないデータでも高精度なモデル構築が可能
Cross-encoder
Cross-encoderは、質問と文書のペアを同時にエンコードし、関連度を直接予測するモデルです。相互作用を直接モデル化するため高精度ですが、ペアごとにエンコードが必要なため計算コストが高くなります。
LLMベースのreranker
LLMをrerankerとして利用する手法が注目されています。質問と文書群をプロンプトとしてLLMに入力し、関連度に基づいて並べ替えを行います。
例えば、RankGPTでは、LLMが関連度の高い順に文書IDを出力することでrerankを行います。高精度が期待できる一方、LLMの利用コストが高いという課題があります。
Private API
近年では、CohereやJina AI、OpenAI、Anthropicなどの企業が、高性能なrerankモデルをAPIとして提供しています。これらのAPIは、高精度なrerankモデルを簡単に利用できるというメリットがあります。
- Cohere Rerank: 質問と文書の関連性を0〜1のスコアで評価し、最新のRerank 3.5モデルは汎用性が高く多言語に対応しています。構造化データ(YAML形式など)のrerankにも対応している点が特徴です。
- Jina AI: オープンソースの基盤に基づくAPIで、異なるサイズのモデルを提供し、用途に応じて精度と速度のバランスを選択できます。
- OpenAI Embeddings: テキストを高次元ベクトル空間に埋め込み、セマンティック検索の基盤として利用可能です。最新のtext-embedding-3モデルは、多様な検索タスクで高い性能を示しています。
- Claude/GPT API: LLMそのものをrerankerとして利用する方法も増えています。専用のプロンプトを用いることで、文書の関連性評価タスクに対応させることが可能です。
これらのAPIサービスを利用する主なメリットは、インフラストラクチャの構築や複雑なモデルのトレーニングなしに、最先端のrerankモデルを即座に利用できることです。一方で、APIコストやデータプライバシーの懸念がデメリットとして挙げられます。
各手法の性能比較
以下の表は、主要なrerankモデルの性能比較を示しています。選択する際は、精度と計算コストのトレードオフを考慮する必要があります。
| 手法タイプ | 精度 | 計算コスト | 例 |
|---|---|---|---|
| Cross-encoder | 高 | 中 | BGE, sentence transformers, Mixedbread |
| Multi-vector | 良 | 低 | ColBERT |
| LLM オープンソース | 高 | 高 | RankZephyr, RankT5 |
| LLM API | 最高 | 非常に高 | GPT, Claude |
| Rerank API | 高 | 中 | Cohere, Mixedbread, Jina |
例えば、ある実験では、多数のクエリに対するrerankerの評価が行われ、Cohere (Cross-encoderの一種) が高い精度を示しました[1]。別の実験では、ColBERT (Multi-vector rerankerの一種) が、BEIRベンチマーク(Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models)[2]の複数のデータセットにおいて、最先端のlate interactionモデルとほぼ同等のzero-shot性能を示しました[3]。
具体例
以下の例は、rerankモデルがどのように機能するかを具体的に示しています。
例えば、「東京の桜の見頃はいつですか?」というクエリに対して:
-
初期検索: ベクトル検索で「東京」「桜」「見頃」などのキーワードを含む文書を10件取得します。
- 東京の桜についての記事
- 日本全国の桜の開花予想
- 東京の観光スポット
- 桜の種類についての解説
- など...
-
rerank: これらの文書をrerankモデルで評価します。モデルは「見頃」という時期に関する質問の意図を理解し、単に「東京」と「桜」を含むだけでなく、時期に関する情報を含む文書を優先的に評価します。
- 「東京都内の桜の見頃は例年3月下旬から4月上旬です」(関連性高)
- 「新宿御苑では例年3月25日頃から桜が咲き始めます」(関連性高)
- 「日本には山桜、ソメイヨシノなど様々な桜の種類があります」(関連性低)
-
生成: 関連性の高い上位の文書を基に、LLMが適切な回答を生成します。
より実用的な例として、企業の社内知識ベースでの利用を考えてみましょう:
クエリ:「新入社員向けの研修資料はどこにありますか?」
-
初期検索:「新入社員」「研修」「資料」などのキーワードに基づいて文書を検索
- 「2023年度新入社員研修スケジュール.pdf」
- 「社員向け研修制度に関する説明.docx」
- 「研修資料作成ガイドライン.pptx」
- 「新入社員メンター制度について.txt」
-
rerank:rerankモデルがクエリの意図(研修資料の場所を知りたい)を理解し、最適な文書を選択
- 「新入社員研修資料は社内ポータルの人事ページからアクセスできます」(関連性最高)
- 「2023年度新入社員研修スケジュールと資料はSharePointの以下のフォルダに保存されています...」(関連性高)
-
生成:LLMが関連性の高い情報を基に、具体的なアクセス方法まで含めた回答を生成
Rerankモデルの適用事例
Rerankモデルは、様々な分野でRAGの性能向上に貢献しています。
-
社内検索: 多くの企業が、rerankモデルを用いて社内検索の精度を向上させています。rerankモデルを導入することで、従業員はサイロ化された知識ベースから関連する文書をより簡単に見つけることができます。
-
チャットボット: rerankモデルは、チャットボットの応答精度を向上させるためにも利用されています。rerankモデルを用いることで、チャットボットはより適切な知識を検索し、より的確な応答を生成することができます。
Rerankモデルの課題と今後の展望
Rerankモデルは、RAGの性能向上に大きく貢献する一方、いくつかの課題も抱えています:
-
計算コスト: 特にCross-encoderベースのrerankモデルは、文書とクエリのペアを個別に処理する必要があり、計算コストが高くなります。今後は、効率性を向上させつつ精度を維持するアプローチが求められます。
-
バイアス: rerankモデルは学習データのバイアスを継承する可能性があります。これにより、特定のトピックや表現に対して偏ったランキングが生じる可能性があります。バイアスの検出と軽減のための技術開発が重要です。
-
説明可能性: 多くのrerankモデルは、なぜ特定の文書が高いランクを与えられたのかを説明することが難しいブラックボックスです。説明可能なrerankモデルの開発が、特に企業や規制の厳しい環境では求められています。
-
ドメイン適応: 一般的なrerankモデルは特定のドメインで性能が低下する場合があります。特に専門用語や特殊な表現が多いドメインでは、ドメイン固有のファインチューニングが必要になることがあります。
-
多言語対応: 多くのrerankモデルは英語に最適化されており、他の言語での性能が低い場合があります。多言語をサポートするrerankモデルの開発が進んでいますが、さらなる改善が期待されます。
Rerankモデルの最新の動向
新しいアーキテクチャの発展
最近のrerankモデルでは、高性能なアーキテクチャが複数登場しています。Elasticが開発したDeBERTa v3ベースの「Elastic Rerank」は、既存検索パイプラインへの容易な統合と再インデックス不要という利点を持ち、一般的な検索タスクで40%の性能向上を実現しています[4]。また、Alibaba NLPの「gte-multilingual-reranker-base」は70以上の言語に対応し、8192トークンまでの長文処理が可能です[5]。
LLMの活用とAPI提供サービス
LLMの発展により、Orion Wellerらが開発したRank1のようなテスト時の計算を活用するrerankモデルが研究論文で発表されています。これはOpenAIのo1やDeepseekのR1などの推論言語モデルを蒸留して小型モデルの性能を向上させる手法です[6]。
API提供サービスも充実し、Cohere Rerank 3.5[7]やPineconeの「pinecone-rerank-v0」[8]など、自前でモデルを構築せずに高性能なrerankを利用できるようになっています。NVIDIAのNeMo Retriever rerankingを使用することで、検索精度を向上させながらLLMの実行コストを21.54%削減できることも報告されています[9]。
効率化と実用性の向上
計算コスト削減のために、kdb+が紹介しているようなbi-encoderとcross-encoderを組み合わせたハイブリッドアプローチが主流となっています[10]。また、非自己回帰型生成モデル(NAR4Rec)のような効率的な手法も登場し、特に推薦システムでの高速な候補生成を可能にしています[11]。
rerankモデルの評価においても、精度だけでなく多様性や公平性などの複数指標を同時に考慮するLLM4Rerankのようなフレームワークが開発されています[12]。また、実装面ではマイクロサービス化やElasticsearchとの統合、クラウドサービスとの連携が進み、大規模システムへの導入が容易になっています。
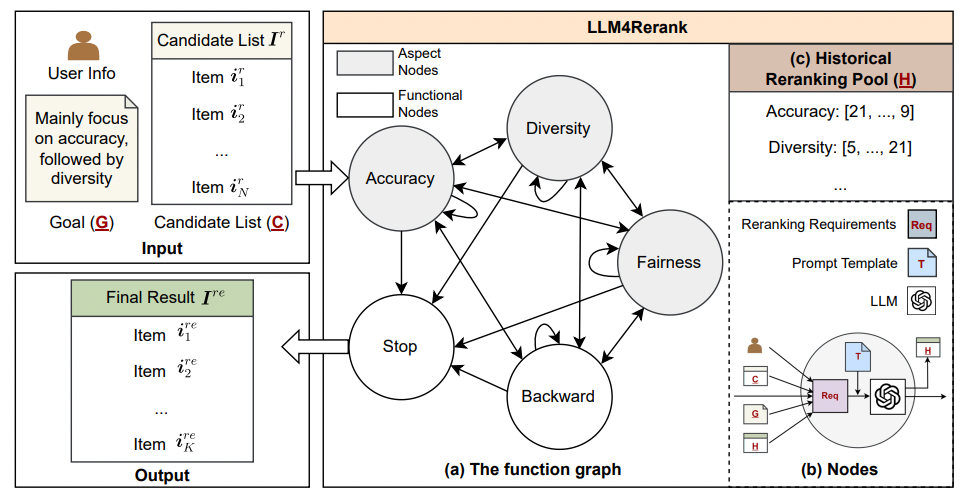
Overall structure of LLM4Rerank. Inputs are first directed to the “Accuracy” node, which initiates an automatic reranking process in (a). Nodes (b) with varying colors represent distinct aspects or functional steps, guiding the LLM in its deliberations with historical information in (c). A complete reranking process is considered finished once LLM reaches the “Stop” node. For simplicity, items in this figure are represented by their IDs, and the detailed descriptions are hidden.
これらの技術革新により、rerankモデルは精度と実用性の両面で大きく進化し、RAGシステムの性能向上に不可欠な要素となっています。
結論
Rerankモデルは、RAGにおいてLLMへの入力となる文書を厳選することで、回答の精度向上、幻覚の抑制、LLMの効率的な利用に貢献します。Cross-encoderとBi-encoderの違いを理解し、適切なrerankモデルを選択することが、RAGシステムの性能を最大化するために重要です。
様々なrerankモデルが提案されており、それぞれに特徴があります。計算コストやバイアス、説明可能性などの課題がありますが、今後の研究開発により、より効率的で公平性が高く、説明可能なモデルが登場することが期待されます。
Rerankモデルの進化は、RAGシステムの性能向上に不可欠です。より洗練されたrerankモデルが登場することで、RAGはより正確で信頼性の高い情報検索システムへと進化し、様々な分野で活用されることが期待されます。
-
Thakur, N., Reimers, N., Rückle, A., Srivastava, A., & Gurevych, I. (2021). BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. arXiv:2104.08663. ↩︎
-
Khattab, O., & Zaharia, M. (2020). ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. SIGIR 2020. arXiv:2004.12832. ↩︎
-
Elastic. "Elastic Announces Elastic Rerank Model to Power Up Semantic Search." ↩︎
-
Weller, O., et al. "Rank1: Test-Time Compute for Reranking in Information Retrieval." arXiv:2502.18418. ↩︎
-
AWS. "Enhancing Search Relevancy with Cohere Rerank 3.5 and Amazon OpenSearch Service." ↩︎
-
NVIDIA. "How Using a Reranking Microservice Can Improve Accuracy and Costs of Information Retrieval." ↩︎
-
"Non-autoregressive Generative Models for Reranking Recommendation." arXiv:2402.06871. ↩︎
-
"LLM4Rerank: LLM-based Auto-Reranking Framework for Recommendations." arXiv:2406.12433. ↩︎
Discussion