Streamlit in Snowflakeでデータウェアハウスの情報を一元化するアプリを作ってみた
今回は、Streamlit in Snowflake を活用し、データウェアハウスの情報を一元化し、社内ユーザーに共有するアプリを作成してみました。
この記事では、具体的な設計やコードを交えながら、その内容をご紹介します。
誰向けのもの?
- Snowflake を日常的に利用している方
- Streamlit in Snowflake に興味がある方
- 社内でデータウェアハウスの管理を担当している方
はじめに
Streamlit in Snowflake は、Snowflake のデータクラウド上で 「Streamlit アプリを安全に構築、展開、共有する」[1] ことを可能にする、Snowflake 提供のフルマネージド型アプリケーションです。この機能を活用することで、Snowflake 環境内で簡易なデータ可視化や時系列予測などのアプリケーションを作成できるほか、Snowflake Cortex[2] を利用した大規模言語モデル(LLM)との連携もシームレスに実現します。
今回、このStreamlit in Snowflake を活用して、テーブル情報にアクセスし、テーブルのカラム詳細やテーブル間の関係性、データのプレビューなど、データウェアハウスの理解に必要な情報をユーザー向けに共有するためのアプリケーションを作成できるのでは、と思い実装を行いました。
プロジェクトの背景
社内でデータウェアハウスを管理する中で、次のような課題がある方も多いのではないでしょうか。
- 利用者がデータ構造を把握しにくい
- テーブルやカラムの詳細を確認する手間が多い
- ドキュメントの更新が手間
これらの課題を解決するため、データウェアハウスの"README"的なものを可視化・公開できるツールを Streamlit in Snowflake を使って構築することにしました。
使用したデータセットと目的
題材として、架空の自転車メーカー「Adventure Works Cycles」の購買システムデータが格納されている Adventure Works [3] サンプルデータを使用し、売上データを FACT としたスタースキーマを "WAREHOUSE" スキーマとして用意しました。
今回作成したスタースキーマテーブルの詳細
-
FACT_ORDER
売上や数量などの販売注文に関する詳細なトランザクションデータを保持するファクトテーブル -
DIM_CHANNEL
注文チャネル(例: オンライン、店舗など)に関する情報を格納するディメンジョンテーブル -
DIM_CUSTOMER
顧客の属性(例: 名前、地域、年齢層など)を格納するディメンジョンテーブル -
DIM_PRODUCT
製品の詳細(例: 製品名、カテゴリ、価格など)を格納するディメンジョンテーブル -
DIM_CALENDAR
日付や曜日、四半期など、時間に関連する情報を格納するディメンジョンテーブル
※スタースキーマについて知りたい方は、下記の記事をご参照ください。
実際の活用例として、"WAREHOUSE"スキーマ内のテーブルを利用し、日毎の製品別売上を分析するためのマートテーブル「DAILY_PRODUCT_SALES」を作成し、それを分析に活用するなどが考えられます。

Snowflakeで"MART"スキーマにテーブル「DAILY_PRODUCT_SALES」を作成した例
このようにスタースキーマの構造はマートテーブルの作成に有用ですが、Snowflake環境でマート設計を完結するには、必要な情報をアプリ内で操作したり、クエリを実行して取得する必要があります。
そこで本アプリでは、利用者がスタースキーマテーブルについて理解を深められるように、以下の情報を可視化することを目指しました。
- データウェアハウスに関する基本情報
- テーブルの詳細情報
- テーブル間の相関図
- 実データのプレビュー
実装手順
1. Streamlitアプリの作成
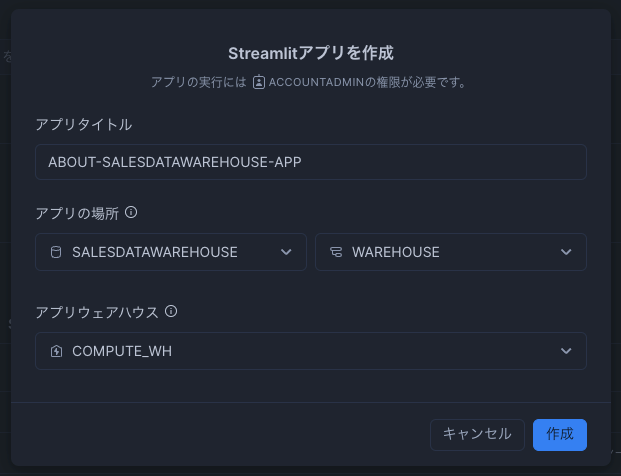
まず、サイドバーの「作成」→「Streamlitアプリ」から、Streamlitアプリを作成します。
今回は、画像のような形でアプリタイトルとアプリの場所、アプリウェアハウス(使用するコンピューティングリソース)を設定しました。
2. ライブラリのインポートとタブ構成の設定
必要なライブラリをインポートし、タブ構成を記述します。
python
import streamlit as st
from snowflake.snowpark.context import get_active_session
import pandas as pd
import networkx as nx
import plotly.graph_objects as go
import numpy as np
# Snowflakeセッションの取得
session = get_active_session()
# タブ構成
overview_tab, tab1, tab2, tab3 = st.tabs(["概要", "テーブル詳細", "相関図", "データプレビュー"])
なお、今回の実装に用いた各ライブラリのバージョンは以下のとおりです。
| ライブラリ名 | バージョン |
|---|---|
networkx |
3.1 |
numpy |
1.24.3 |
plotly |
5.24.1 |
python |
3.8.* |
snowflake-snowpark-python |
最新 (1.24.0) |
streamlit |
最新 (1.35.0) |
3. 概要タブの実装
概要タブでは、データウェアハウスの背景や問い合わせ先など基本情報を記載しています。

概要タブの画面
python
with overview_tab:
st.header("概要")
st.markdown("""
## プロジェクトの背景
SALESDATAWAREHOUSEは、Adventure Worksデータベースを基に、販売データの分析およびビジネスインテリジェンス(BI)ツールでの可視化を目的として構築されました。
このアプリでは、スタースキーマのテーブル詳細やテーブルの相関図、データプレビューを通してデータへの理解を深め、データマートの設計に役立てることができます。
## スタースキーマの概要
### 主要なテーブル
- **FACT_ORDER**: 販売注文に関する詳細なトランザクションデータを保持。
- **DIM_CHANNEL**: 注文チャネル(オンライン、店舗など)の情報。
- **DIM_CUSTOMER**: 顧客に関する情報。
- **DIM_PRODUCT**: 製品に関する情報。
- **DIM_CALENDAR**: 日付に関する情報。
### データ粒度
- **FACT_ORDER**: 1行が1つの販売注文詳細(SalesOrderDetail)を表します。
- **データの更新頻度**: データは1時間に1度更新されます。
## お問い合わせ先
データウェアハウスに関する質問や要望は、以下の連絡先までご連絡ください。
- **担当者**: 山田 太郎
- **メールアドレス**: [yamada.taro@example.com](mailto:yamada.taro@example.com)
- **Slackチャンネル**: `#data-warehouse-support`
""")
4. テーブル詳細タブの実装
このタブでは、各テーブルのカラムやデータ型などの詳細を一覧表示します。レコード数やサイズなど、リアルタイム性の高い情報も取得できます。

テーブル詳細タブの画面
python
# タブ1: テーブル詳細
with tab1:
st.header("テーブル詳細")
st.write("データ型、レコード数、サイズなど、テーブル詳細を確認できます。")
# テーブル情報を取得するクエリ
query = """
SELECT TABLE_SCHEMA, TABLE_NAME, COLUMN_NAME, DATA_TYPE, IS_NULLABLE
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = 'WAREHOUSE'
ORDER BY TABLE_NAME, COLUMN_NAME;
"""
df_table_details = session.sql(query).to_pandas()
# テーブルサイズとレコード数を取得するクエリ
size_query = """
SELECT TABLE_SCHEMA, TABLE_NAME, ROW_COUNT, BYTES
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'WAREHOUSE';
"""
df_table_sizes = session.sql(size_query).to_pandas()
# テーブル詳細とサイズ情報をマージ
df_table_details = pd.merge(
df_table_details,
df_table_sizes[['TABLE_NAME', 'ROW_COUNT', 'BYTES']],
on='TABLE_NAME',
how='left'
)
# テーブルごとに表示
for table_name in df_table_details["TABLE_NAME"].unique():
st.subheader(f"テーブル: {table_name}")
# レコード数とサイズの取得
row_count = df_table_details[df_table_details["TABLE_NAME"] == table_name]["ROW_COUNT"].values
table_bytes = df_table_details[df_table_details["TABLE_NAME"] == table_name]["BYTES"].values
# サイズのフォーマット
if len(table_bytes) > 0 and table_bytes[0] is not None:
if table_bytes[0] < 1024 ** 2: # サイズが1MB未満の場合
size_formatted = f"{table_bytes[0] / 1024:.2f} KB"
else: # サイズが1MB以上の場合
size_formatted = f"{table_bytes[0] / (1024 ** 2):.2f} MB"
else:
size_formatted = "不明"
# レコード数とサイズを1行で表示
if len(row_count) > 0 and row_count[0] is not None:
st.write(f"**レコード数**: {row_count[0]:,} | **サイズ**: {size_formatted}")
else:
st.write(f"**レコード数**: 不明 | **サイズ**: {size_formatted}")
# テーブルのカラム詳細を表示
df_table = df_table_details[df_table_details["TABLE_NAME"] == table_name][["COLUMN_NAME", "DATA_TYPE", "IS_NULLABLE"]]
st.dataframe(df_table)
5. 相関図タブの実装
相関図タブでは、テーブル間の関係を視覚化します。
今回は処理をシンプルにするために、FACTとDIMに共通しているカラム(ID列など)を外部キーとして認識し、それに基づいて関係性を描写する実装を行なっています。

相関図タブの画面
また、plotlyを活用して、カーソルを当てるとツールヒントが表示され、そのテーブルのカラム一覧が見れるようにしています。
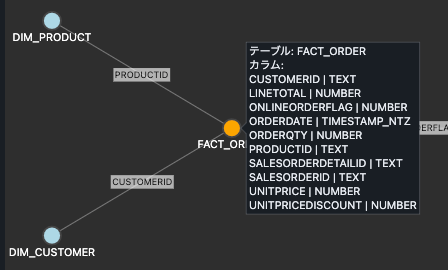
FACT_ORDERにカーソルを当てるとツールヒントにカラム一覧が表示される
python
# タブ2: 相関図
with tab2:
st.header("相関図")
st.markdown("""
スタースキーマに基づいたテーブル間の関係性を視覚化しています。
テーブル名にカーソルを当てるとカラム一覧が確認できます。
""")
# スタースキーマにおけるファクトテーブルとディメンジョンテーブルの識別
df_tables = df_table_details["TABLE_NAME"].unique()
fact_tables = [table for table in df_tables if "FACT" in table.upper()]
dimension_tables = [table for table in df_tables if table not in fact_tables]
if not fact_tables:
st.error("ファクトテーブルが見つかりません。テーブル名に 'FACT' が含まれていることを確認してください。")
else:
# ファクトテーブルとディメンジョンテーブルの関係を共通カラム名で抽出
relationships = []
for fact in fact_tables:
fact_columns = set(df_table_details[df_table_details["TABLE_NAME"] == fact]["COLUMN_NAME"])
for dim in dimension_tables:
dim_columns = set(df_table_details[df_table_details["TABLE_NAME"] == dim]["COLUMN_NAME"])
common_columns = fact_columns.intersection(dim_columns)
for col in common_columns:
relationships.append((fact, dim, col))
if not relationships:
st.warning("ファクトテーブルとディメンジョンテーブル間で共通するカラムが見つかりません。")
else:
# グラフの構築
G = nx.Graph()
# ノードの追加
for fact in fact_tables:
G.add_node(fact, type='fact')
for dim in dimension_tables:
G.add_node(dim, type='dimension')
# エッジの追加
for fact, dim, col in relationships:
G.add_edge(fact, dim, label=col)
# 紐づいているディメンジョンテーブルと紐づいていないものを分ける
linked_dim_tables = set()
for fact, dim, col in relationships:
linked_dim_tables.add(dim)
unlinked_dim_tables = set(dimension_tables) - linked_dim_tables
# レイアウトの設定
pos = {}
num_facts = len(fact_tables)
num_linked_dims = len(linked_dim_tables)
num_unlinked_dims = len(unlinked_dim_tables)
# ファクトテーブルを中心に配置(複数の場合は円周上に配置)
if num_facts == 1:
pos[fact_tables[0]] = (0, 0)
else:
radius_fact = 10
for i, fact in enumerate(fact_tables):
angle = (2 * np.pi / num_facts) * i
pos[fact] = (radius_fact * np.cos(angle), radius_fact * np.sin(angle))
# 紐づいているディメンジョンテーブルを円周上に配置
radius_dim = 20
if num_linked_dims > 0:
angle_gap = 2 * np.pi / num_linked_dims
for i, dim in enumerate(linked_dim_tables):
angle = angle_gap * i
pos[dim] = (radius_dim * np.cos(angle), radius_dim * np.sin(angle))
# 紐づいていないディメンジョンテーブルを下部に配置
if num_unlinked_dims > 0:
# グラフの下部に均等に配置
x_start = - (num_unlinked_dims - 1) / 2
y_position = -radius_dim - 10 # 下部に配置
for i, dim in enumerate(sorted(unlinked_dim_tables)):
pos[dim] = (x_start + i, y_position)
# ノードごとのカラム情報をテキスト形式でまとめる(区切り文字を使用)
table_columns = {}
for table in G.nodes():
columns = df_table_details[df_table_details["TABLE_NAME"] == table][["COLUMN_NAME", "DATA_TYPE"]]
# 各カラムを区切り文字で分けて表示
columns_info = "<br>".join([f"{row['COLUMN_NAME']} | {row['DATA_TYPE']}" for _, row in columns.iterrows()])
table_columns[table] = f"テーブル: {table}<br>カラム:<br>{columns_info}"
# エッジトレースの作成
edge_trace = go.Scatter(
x=[],
y=[],
line=dict(width=1, color='gray'),
hoverinfo='text',
mode='lines',
text=[f"カラム: {data['label']}" for _, _, data in G.edges(data=True)]
)
for u, v, data in G.edges(data=True):
x0, y0 = pos[u]
x1, y1 = pos[v]
edge_trace['x'] += (x0, x1, None)
edge_trace['y'] += (y0, y1, None)
# ノードカラーの設定
node_colors = [
'orange' if G.nodes[node]['type'] == 'fact' else 'lightblue'
for node in G.nodes()
]
# ノードトレースの作成
node_trace = go.Scatter(
x=[],
y=[],
text=[],
mode='markers+text',
hoverinfo='text',
marker=dict(
showscale=False,
color=node_colors,
size=20,
line_width=2
),
textposition="bottom center",
textfont=dict(
size=12,
color='white'
)
)
for node in G.nodes():
x, y = pos[node]
node_trace['x'] += (x,)
node_trace['y'] += (y,)
node_trace['text'] += (node,)
# ノードのツールチップを設定(区切り文字を使用)
node_trace['hovertext'] = [table_columns[node] for node in G.nodes()]
node_trace['hoverinfo'] = 'text'
# Plotlyのレイアウト設定(タイトルを削除)
fig = go.Figure(data=[edge_trace, node_trace],
layout=go.Layout(
showlegend=False,
hovermode='closest',
margin=dict(b=20, l=5, r=5, t=40),
annotations=[],
xaxis=dict(showgrid=False, zeroline=False, showticklabels=False),
yaxis=dict(showgrid=False, zeroline=False, showticklabels=False),
plot_bgcolor='#2E2E2E',
paper_bgcolor='#2E2E2E'
))
# エッジラベルの描画
for u, v, data in G.edges(data=True):
x0, y0 = pos[u]
x1, y1 = pos[v]
midpoint = ((x0 + x1) / 2, (y0 + y1) / 2)
fig.add_annotation(
x=midpoint[0],
y=midpoint[1],
text=data['label'],
showarrow=False,
font=dict(
color="black",
size=10
),
align="center",
bgcolor="white",
opacity=0.6
)
st.plotly_chart(fig, use_container_width=True)
6. データプレビュータブの実装
ユーザーが選択したテーブルの先頭10行のサンプルデータを表示します。さらに、外部キーで関連するデータも参照できるようにしています。

データプレビュータブの画面
python
# タブ3: データプレビュー
with tab3:
st.header("データプレビュー")
st.write("選択したテーブルの先頭数行を表示します。")
# テーブル一覧の取得
table_query = """
SELECT TABLE_NAME
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'WAREHOUSE';
"""
df_tables_preview = session.sql(table_query).to_pandas()
table_names_preview = df_tables_preview["TABLE_NAME"].tolist()
# タブ2と同様にファクトテーブルを識別
fact_tables_preview = [table for table in table_names_preview if "FACT" in table.upper()]
# 初期選択をファクトテーブルの最初のテーブルに設定、存在しない場合は最初のテーブルを設定
if fact_tables_preview:
default_table = fact_tables_preview[0]
else:
default_table = table_names_preview[0] if table_names_preview else None
# テーブルを選択してデータをプレビュー
selected_table = st.selectbox(
"テーブルを選択してください",
table_names_preview,
index=table_names_preview.index(default_table) if default_table in table_names_preview else 0
)
if selected_table:
preview_query = f"SELECT * FROM WAREHOUSE.{selected_table} LIMIT 10;"
df_preview = session.sql(preview_query).to_pandas()
st.subheader(f"テーブル: {selected_table}")
st.dataframe(df_preview)
# 外部キーを検索し、関連するテーブルのデータを表示
# ファクトテーブルとディメンジョンテーブル間で共通するカラム名を外部キーとみなす
fk_columns = [
col for col in df_preview.columns if col in df_table_details[
(df_table_details["TABLE_NAME"] != selected_table) &
(df_table_details["COLUMN_NAME"] == col)
]["COLUMN_NAME"].unique()
]
if fk_columns:
st.subheader("関連データ")
for fk_column in fk_columns:
fk_values = df_preview[fk_column].dropna().unique()
if fk_values.size > 0:
# 外部キーから関連テーブルを特定
related_tables = df_table_details[
(df_table_details["COLUMN_NAME"] == fk_column) &
(df_table_details["TABLE_NAME"] != selected_table) # selected_tableを除外
]["TABLE_NAME"].unique()
for related_table in related_tables:
try:
# クエリ内の文字列を適切に引用符で囲む
fk_values_str = ', '.join(
[f"'{val}'" if isinstance(val, str) else str(val) for val in fk_values]
)
related_data_query = (
f"SELECT * FROM WAREHOUSE.{related_table} WHERE {fk_column} IN ({fk_values_str}) LIMIT 10;"
)
df_related = session.sql(related_data_query).to_pandas()
if not df_related.empty:
st.markdown(f"**{related_table}** ({fk_column})")
st.dataframe(df_related)
else:
st.markdown(f"*{related_table} には関連データがありません。*")
except Exception as e:
st.markdown(f"エラー: {related_table} の関連データの取得に失敗しました。")
st.error(e)
else:
st.write("関連する外部キーはありません。")
今後の展望
今回のアプリでは、データ構造の可視化と簡単なプレビューを実装してみました。
今後はSnowflake CortexのLLM機能を使って、以下のような機能を追加できると面白そうだなと思っています。
- リッチなER図の描写: リッチな ER 図の動的な生成
- 分析方針の相談: 対象のスタースキーマテーブルをもとに、分析方針からマートテーブル作成まで相談できるチャット機能
まとめ
Streamlit in Snowflake を活用して、データウェアハウスの README を公開するアプリを作成しました。このようにアプリを使ってマート作成者やユーザーにデータ構造や利用シナリオに関する直感的な情報を提供することで、より効率的かつ実践的なデータ活用が実現できるかもしれません。
最後までお読みいただきありがとうございました!
参考文献
- Streamlitアプリケーションの作成方法について参考にしました:
- データカタログの作成に関する事例として参照しました:
- 実際の運用に役立つ視点を提供しています(今回は簡易的な実装のため省略):
付録
コード全文
import streamlit as st
from snowflake.snowpark.context import get_active_session
import pandas as pd
import networkx as nx
import plotly.graph_objects as go
import numpy as np
# Snowflakeセッションの取得
session = get_active_session()
# タブ構成
overview_tab, tab1, tab2, tab3 = st.tabs(["概要", "テーブル詳細", "相関図", "データプレビュー"])
# 概要タブ
with overview_tab:
st.header("概要")
st.markdown("""
## プロジェクトの背景
SALESDATAWAREHOUSEは、Adventure Worksデータベースを基に、販売データの分析およびビジネスインテリジェンス(BI)ツールでの可視化を目的として構築されました。
このアプリでは、スタースキーマのテーブル詳細やテーブルの相関図、データプレビューを通してデータへの理解を深め、データマートの設計に役立てることができます。
## スタースキーマの概要
### 主要なテーブル
- **FACT_ORDER**: 販売注文に関する詳細なトランザクションデータを保持。
- **DIM_CHANNEL**: 注文チャネル(オンライン、店舗など)の情報。
- **DIM_CUSTOMER**: 顧客に関する情報。
- **DIM_PRODUCT**: 製品に関する情報。
- **DIM_CALENDAR**: 日付に関する情報。
### データ粒度
- **FACT_ORDER**: 1行が1つの販売注文詳細(SalesOrderDetail)を表します。
- **データの更新頻度**: データは1時間に1度更新されます。
## お問い合わせ先
データウェアハウスに関する質問や要望は、以下の連絡先までご連絡ください。
- **担当者**: 山田 太郎
- **メールアドレス**: [yamada.taro@example.com](mailto:yamada.taro@example.com)
- **Slackチャンネル**: `#data-warehouse-support`
""")
# タブ1: テーブル詳細
with tab1:
st.header("テーブル詳細")
st.write("データ型、レコード数、サイズなど、テーブル詳細を確認できます。")
# テーブル情報を取得するクエリ
query = """
SELECT TABLE_SCHEMA, TABLE_NAME, COLUMN_NAME, DATA_TYPE, IS_NULLABLE
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = 'WAREHOUSE'
ORDER BY TABLE_NAME, COLUMN_NAME;
"""
df_table_details = session.sql(query).to_pandas()
# テーブルサイズとレコード数を取得するクエリ
size_query = """
SELECT TABLE_SCHEMA, TABLE_NAME, ROW_COUNT, BYTES
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'WAREHOUSE';
"""
df_table_sizes = session.sql(size_query).to_pandas()
# テーブル詳細とサイズ情報をマージ
df_table_details = pd.merge(
df_table_details,
df_table_sizes[['TABLE_NAME', 'ROW_COUNT', 'BYTES']],
on='TABLE_NAME',
how='left'
)
# テーブルごとに表示
for table_name in df_table_details["TABLE_NAME"].unique():
st.subheader(f"テーブル: {table_name}")
# レコード数とサイズの取得
row_count = df_table_details[df_table_details["TABLE_NAME"] == table_name]["ROW_COUNT"].values
table_bytes = df_table_details[df_table_details["TABLE_NAME"] == table_name]["BYTES"].values
# サイズのフォーマット
if len(table_bytes) > 0 and table_bytes[0] is not None:
if table_bytes[0] < 1024 ** 2: # サイズが1MB未満の場合
size_formatted = f"{table_bytes[0] / 1024:.2f} KB"
else: # サイズが1MB以上の場合
size_formatted = f"{table_bytes[0] / (1024 ** 2):.2f} MB"
else:
size_formatted = "不明"
# レコード数とサイズを1行で表示
if len(row_count) > 0 and row_count[0] is not None:
st.write(f"**レコード数**: {row_count[0]:,} | **サイズ**: {size_formatted}")
else:
st.write(f"**レコード数**: 不明 | **サイズ**: {size_formatted}")
# テーブルのカラム詳細を表示
df_table = df_table_details[df_table_details["TABLE_NAME"] == table_name][["COLUMN_NAME", "DATA_TYPE", "IS_NULLABLE"]]
st.dataframe(df_table)
# タブ2: 相関図
with tab2:
st.header("相関図")
st.markdown("""
スタースキーマに基づいたテーブル間の関係性を視覚化しています。
テーブル名にカーソルを当てるとカラム一覧が確認できます。
""")
# スタースキーマにおけるファクトテーブルとディメンジョンテーブルの識別
df_tables = df_table_details["TABLE_NAME"].unique()
fact_tables = [table for table in df_tables if "FACT" in table.upper()]
dimension_tables = [table for table in df_tables if table not in fact_tables]
if not fact_tables:
st.error("ファクトテーブルが見つかりません。テーブル名に 'FACT' が含まれていることを確認してください。")
else:
# ファクトテーブルとディメンジョンテーブルの関係を共通カラム名で抽出
relationships = []
for fact in fact_tables:
fact_columns = set(df_table_details[df_table_details["TABLE_NAME"] == fact]["COLUMN_NAME"])
for dim in dimension_tables:
dim_columns = set(df_table_details[df_table_details["TABLE_NAME"] == dim]["COLUMN_NAME"])
common_columns = fact_columns.intersection(dim_columns)
for col in common_columns:
relationships.append((fact, dim, col))
if not relationships:
st.warning("ファクトテーブルとディメンジョンテーブル間で共通するカラムが見つかりません。")
else:
# グラフの構築
G = nx.Graph()
# ノードの追加
for fact in fact_tables:
G.add_node(fact, type='fact')
for dim in dimension_tables:
G.add_node(dim, type='dimension')
# エッジの追加
for fact, dim, col in relationships:
G.add_edge(fact, dim, label=col)
# 紐づいているディメンジョンテーブルと紐づいていないものを分ける
linked_dim_tables = set()
for fact, dim, col in relationships:
linked_dim_tables.add(dim)
unlinked_dim_tables = set(dimension_tables) - linked_dim_tables
# レイアウトの設定
pos = {}
num_facts = len(fact_tables)
num_linked_dims = len(linked_dim_tables)
num_unlinked_dims = len(unlinked_dim_tables)
# ファクトテーブルを中心に配置(複数の場合は円周上に配置)
if num_facts == 1:
pos[fact_tables[0]] = (0, 0)
else:
radius_fact = 10
for i, fact in enumerate(fact_tables):
angle = (2 * np.pi / num_facts) * i
pos[fact] = (radius_fact * np.cos(angle), radius_fact * np.sin(angle))
# 紐づいているディメンジョンテーブルを円周上に配置
radius_dim = 20
if num_linked_dims > 0:
angle_gap = 2 * np.pi / num_linked_dims
for i, dim in enumerate(linked_dim_tables):
angle = angle_gap * i
pos[dim] = (radius_dim * np.cos(angle), radius_dim * np.sin(angle))
# 紐づいていないディメンジョンテーブルを下部に配置
if num_unlinked_dims > 0:
# グラフの下部に均等に配置
x_start = - (num_unlinked_dims - 1) / 2
y_position = -radius_dim - 10 # 下部に配置
for i, dim in enumerate(sorted(unlinked_dim_tables)):
pos[dim] = (x_start + i, y_position)
# ノードごとのカラム情報をテキスト形式でまとめる(区切り文字を使用)
table_columns = {}
for table in G.nodes():
columns = df_table_details[df_table_details["TABLE_NAME"] == table][["COLUMN_NAME", "DATA_TYPE"]]
# 各カラムを区切り文字で分けて表示
columns_info = "<br>".join([f"{row['COLUMN_NAME']} | {row['DATA_TYPE']}" for _, row in columns.iterrows()])
table_columns[table] = f"テーブル: {table}<br>カラム:<br>{columns_info}"
# エッジトレースの作成
edge_trace = go.Scatter(
x=[],
y=[],
line=dict(width=1, color='gray'),
hoverinfo='text',
mode='lines',
text=[f"カラム: {data['label']}" for _, _, data in G.edges(data=True)]
)
for u, v, data in G.edges(data=True):
x0, y0 = pos[u]
x1, y1 = pos[v]
edge_trace['x'] += (x0, x1, None)
edge_trace['y'] += (y0, y1, None)
# ノードカラーの設定
node_colors = [
'orange' if G.nodes[node]['type'] == 'fact' else 'lightblue'
for node in G.nodes()
]
# ノードトレースの作成
node_trace = go.Scatter(
x=[],
y=[],
text=[],
mode='markers+text',
hoverinfo='text',
marker=dict(
showscale=False,
color=node_colors,
size=20,
line_width=2
),
textposition="bottom center",
textfont=dict(
size=12,
color='white'
)
)
for node in G.nodes():
x, y = pos[node]
node_trace['x'] += (x,)
node_trace['y'] += (y,)
node_trace['text'] += (node,)
# ノードのツールチップを設定(区切り文字を使用)
node_trace['hovertext'] = [table_columns[node] for node in G.nodes()]
node_trace['hoverinfo'] = 'text'
# Plotlyのレイアウト設定(タイトルを削除)
fig = go.Figure(data=[edge_trace, node_trace],
layout=go.Layout(
showlegend=False,
hovermode='closest',
margin=dict(b=20, l=5, r=5, t=40),
annotations=[],
xaxis=dict(showgrid=False, zeroline=False, showticklabels=False),
yaxis=dict(showgrid=False, zeroline=False, showticklabels=False),
plot_bgcolor='#2E2E2E',
paper_bgcolor='#2E2E2E'
))
# エッジラベルの描画
for u, v, data in G.edges(data=True):
x0, y0 = pos[u]
x1, y1 = pos[v]
midpoint = ((x0 + x1) / 2, (y0 + y1) / 2)
fig.add_annotation(
x=midpoint[0],
y=midpoint[1],
text=data['label'],
showarrow=False,
font=dict(
color="black",
size=10
),
align="center",
bgcolor="white",
opacity=0.6
)
st.plotly_chart(fig, use_container_width=True)
# タブ3: データプレビュー
with tab3:
st.header("データプレビュー")
st.write("選択したテーブルの先頭数行を表示します。")
# テーブル一覧の取得
table_query = """
SELECT TABLE_NAME
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'WAREHOUSE';
"""
df_tables_preview = session.sql(table_query).to_pandas()
table_names_preview = df_tables_preview["TABLE_NAME"].tolist()
# タブ2と同様にファクトテーブルを識別
fact_tables_preview = [table for table in table_names_preview if "FACT" in table.upper()]
# 初期選択をファクトテーブルの最初のテーブルに設定、存在しない場合は最初のテーブルを設定
if fact_tables_preview:
default_table = fact_tables_preview[0]
else:
default_table = table_names_preview[0] if table_names_preview else None
# テーブルを選択してデータをプレビュー
selected_table = st.selectbox(
"テーブルを選択してください",
table_names_preview,
index=table_names_preview.index(default_table) if default_table in table_names_preview else 0
)
if selected_table:
preview_query = f"SELECT * FROM WAREHOUSE.{selected_table} LIMIT 10;"
df_preview = session.sql(preview_query).to_pandas()
st.subheader(f"テーブル: {selected_table}")
st.dataframe(df_preview)
# 外部キーを検索し、関連するテーブルのデータを表示
# ファクトテーブルとディメンジョンテーブル間で共通するカラム名を外部キーとみなす
fk_columns = [
col for col in df_preview.columns if col in df_table_details[
(df_table_details["TABLE_NAME"] != selected_table) &
(df_table_details["COLUMN_NAME"] == col)
]["COLUMN_NAME"].unique()
]
if fk_columns:
st.subheader("関連データ")
for fk_column in fk_columns:
fk_values = df_preview[fk_column].dropna().unique()
if fk_values.size > 0:
# 外部キーから関連テーブルを特定
related_tables = df_table_details[
(df_table_details["COLUMN_NAME"] == fk_column) &
(df_table_details["TABLE_NAME"] != selected_table) # selected_tableを除外
]["TABLE_NAME"].unique()
for related_table in related_tables:
try:
# クエリ内の文字列を適切に引用符で囲む
fk_values_str = ', '.join(
[f"'{val}'" if isinstance(val, str) else str(val) for val in fk_values]
)
related_data_query = (
f"SELECT * FROM WAREHOUSE.{related_table} WHERE {fk_column} IN ({fk_values_str}) LIMIT 10;"
)
df_related = session.sql(related_data_query).to_pandas()
if not df_related.empty:
st.markdown(f"**{related_table}** ({fk_column})")
st.dataframe(df_related)
else:
st.markdown(f"*{related_table} には関連データがありません。*")
except Exception as e:
st.markdown(f"エラー: {related_table} の関連データの取得に失敗しました。")
st.error(e)
else:
st.write("関連する外部キーはありません。")
Discussion