[レポート] Data Engineering Study #25 データカタログの現在地 #DataEngineeringStudy



しんやです。
このたび、Zennでもブログを書いてみることにしました。
データ周りやあまり仕事とかで触ったり携わったりすることが無さそうなテーマや分野の内容について、趣味的に色々と書き連ねて行こうかなと思っています。

当エントリでは 2024年08月28日(水)に開催された『Data Engineering Study #25 データカタログの現在地』のイベントセッションレポートをお届けします。
当日のX投稿もまとめましたので合わせてご参照ください。
イベント概要
前述Connpassのイベントページに記載のセッション概要は以下の通り。
プログラム第25回「データカタログの現在地」
データ量が増加し続ける中、企業におけるデータ管理の重要性が一層高まっています。そのような動きに合わせて、組織全体のデータ資産を管理して、データの発見・理解を促進するデータカタログの需要も高まりつつあります。
今回は、データカタログとは何か、またOSSである「OpenMetadata」に関するご紹介やCommiterとしての活動をOpenMetadataのCommiterであるDATUM STUDIO 川口氏にお話しいただきます。その後、GENDA 山口氏、サミーネットワークス 森氏から実際に各社がデータカタログをどのように活用されているか、事例をご紹介いただきます。
セッションレポート
ここからはセッションレポートを紹介します。アーカイブ動画は以下から。
基調講演「データカタログに求められる機能とOpenMetadataでどのように実現されているかのご紹介」

-
登壇者:川口 氏 (DATUM STUDIO株式会社 データエンジニア部)
-
自己紹介
- 最近は主にデータ分析基盤構築のプロジェクトに関わっている
-
会社紹介
-
DATUM STUDIO株式会社
- データと先端テクノロジーで経営課題を解決するデータ分析コンサルティング・ソフトウェア開発企業
- 様々な企業にデータプラットフォームの導入支援を行っている
-
DATUM STUDIO株式会社
データカタログの概要
-
データカタログとは?
- メタデータを使用して組織がデータを管理出来るようにするもの
- いわば「図書館の蔵書検索」みたいなもの。
- データの所在が分かることで、データを活用出来るようになる(データを検索し、利用へのステップへと進むことが出来る)
- 図書館における「貸出禁止」のように、データに於いても利用制限を管理
-
メタデータとは?
- データカタログの文脈に於いて、メタデータは以下の3種類に分類出来る
- テクニカルメタデータ(ソースシステムにおける技術的な情報)
- ビジネスメタデータ(データの内容や業務に関する情報)
- 必ずしもソースシステムから入手可能とは限らない。その場合は人による整備も求められる
- オペレーショナルメタデータ(データの処理に関する情報)

- データカタログの文脈に於いて、メタデータは以下の3種類に分類出来る
-
メタデータ管理における主な登場人物
- データスチュワード:
- 組織にとって最善の利益のためにデータ資産を管理
- 組織のステークホルダーの利益を代弁し企業のデータを高品質で効果的に利用出来るようにするための全体的な視点を持つ
- データオーナー:
- 担当分野のデータに関する意思決定の承認権限を持つ
- データコンシューマー:
- 日々の業務で様々なデータ資産を使用
- データスチュワード:
-
データカタログの「概観」
- 組織の色々なシステムからメタデータを抽出し、(出どころはそれぞれ別れていたとしても)データカタログ内ではそれらの情報を一箇所で管理
- それぞれのデータにはデータオーナーが存在
- データカタログ内のデータについてはデータスチュワードが責任を持って管理
-
管理されたメタデータで可能になること

-
データカタログの主要機能
-
ディスカバリー
- メタデータの一元管理
- API等を介して収集したメタデータを利用
-
データガバナンス
- 個人情報データ識別、データ保持ポリシーの共有
- ビジネス用語集(Glossary)による「データに対する共通理解」の促進
-
データリネージ
- データの流れを追跡
-
データクオリティ
- データ品質を測定し、データの信頼性を保証
-
ディスカバリー
OpenMetadataの紹介

-
2021年に開発が開始された後発のOSSデータカタログツール
- アーキテクチャのシンプルさに重点を置いているが、豊富な機能を有する
- メタデータリポジトリに様々なソースのメタデータを取り込み、ユーザーにUIやAPIを通してメタデータを提供
- Uber社でのデータカタログ構築経験を元に開発されている
- 開発が活発
- UI表示の日本語変更が可能
-
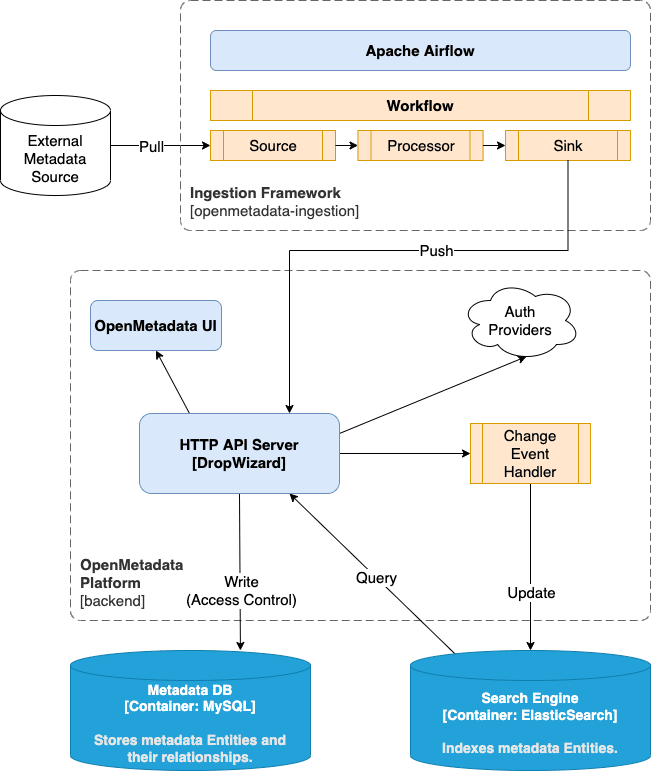
アーキテクチャ:4つのコンポーネントから成る
- OpenMetadata platform
- Airflow
- MySQL
- ElasticSearch
- 参考:Architecture
-
OpenMetadataの主要機能紹介
-
ディスカバリー
- サービスを8つのカテゴリに分類し、カテゴリ毎に共通のメタデータスキーマを定めている
- Database/DataWarehouse
- Dashboard
- Messaging
- Pipeline
- ML Model
- Storage
- Metadata
- Search
- (登壇者注)コネクタの数は豊富だが、コネクタによって抽出対象のメタデータは異なる(対象となるメタデータが対象システムに存在しない場合も)。その場合はカスタムプロパティで対応
- 各サービスからメタデータを抽出するには
- OpenMetadata UIからのメタデータ取り込み(Ingestion)実行
- 外部からのメタデータ取り込み(Ingestion)実行
- サービス・データアセットを横断してのキーワード検索が可能
- 検索対象フィールドやand/or条件指定の検索も可能
- サービスを8つのカテゴリに分類し、カテゴリ毎に共通のメタデータスキーマを定めている
-
データガバナンス
- テクニカルメタデータにビジネスメタデータを付与することでデータの共通理解を深め、ガバナンスを強化可能
- データオーナーは他ユーザーに対して 「データに関して誰に問い合わせをすればよいのか」を明確に示すことが出来るようになる
- タグをデータアセットやカラムに付与可能。これによりデータ保護やセキュリティの観点でデータの適切な管理が行えるようになる
- 「組織で用いる共通の用語に関する理解を深めるための」ビジネス用語集として使えるようになる
- タグや用語集はチーム・ユーザーを指定してレビューのタスクを設定することが可能
- テクニカルメタデータにビジネスメタデータを付与することでデータの共通理解を深め、ガバナンスを強化可能
-
データリネージ
- サービスを横断してデータリネージを作成することが可能

-
データクオリティ
- データプロファイラ機能としてテーブルの行数やカラムのNULL率・ユニーク率等を簡単にチェック可能
- メタデータ抽出と同様にスケジュール実行が可能
- テーブルやカラムに対して任意のテストを設定し、データ品質を継続して監視可能
- こちらもメタデータ抽出と同様にスケジュール実行が可能
- テストが失敗した場合、ユーザーをアサインしてタスクとして対応状況を管理可能
- データプロファイラ機能としてテーブルの行数やカラムのNULL率・ユニーク率等を簡単にチェック可能
-
メタデータの収集や整備は自動化が難しく、停滞しやすいという課題
- 充足率を上げるためのデータカタログの機能方針
- (1).生成AI等を使用して出来るだけ自動化
- 例)descriptionを生成する機能。有償製品では用いられることが多く、OpenMetadataのSaaS版でも機能として存在している
- (2).ビジネスメタデータを入力しやすいような仕組みや機能を導入
-
OpenMetadataはこちらの方針が強く、コラボレーション機能が豊富。 OpenMetadata上でユーザーのコミュニケーションが取りやすいため、メタデータの追加・更新の依頼が容易に。使用感としてはSlackが近い
- タスク
- 会話スレッド
- データセットにメタデータの変更履歴や会話スレッドが紐付き、データアセットについて他ユーザーと共有する機能がある。情報のサイロ化を防ぎ、組織を横断してメタデータと付加情報の共有が可能
- アクティビティフィード
- アナウンス
- データアセットのdescriptionやオーナーの充足度推移を監視したり、いつまでに何%達成か、等のKPIを設定可能
-
OpenMetadataはこちらの方針が強く、コラボレーション機能が豊富。 OpenMetadata上でユーザーのコミュニケーションが取りやすいため、メタデータの追加・更新の依頼が容易に。使用感としてはSlackが近い
- (1).生成AI等を使用して出来るだけ自動化
- 充足率を上げるためのデータカタログの機能方針
-
OpenMetadataとDataHubとの比較
- 両者共にOSSデータカタログ製品であり、機能の重複も多い

データカタログ(OpenMetadata)の活用方法例
- 活用例(1). サービスを横断したデータリネージ
- サービスを横断してデータソースまでのリネージを確認出来るようになると以下のような活用が可能に
- ダッシュボードの値がおかしいので原因を調査したい
- パイプラインの一部を変更する場合、テーブルやダッシュボードにどの範囲で影響があるかを把握したい
- サービスを横断してデータソースまでのリネージを確認出来るようになると以下のような活用が可能に
- 活用例(2). インタフェース・関連システムの把握
- データ基盤の構築前に関連システムのメタデータを収集し、組織のデータ全体感を把握
- 設計や開発で必要な情報も把握しやすくなる。特にインタフェース部分
- 活用例(3). マイグレーション
- データ基盤やデータパイプラインのマイグレーション時に、関連システムの把握や新旧データ基盤のスキーマが一致するかのチェックなどを行う
- OpenMetadataの最新バージョンに於いてはテーブル間差分チェックのテストも行われており、マイグレーションのクオリティチェックも行いやすい。
OpemMetadataのデモ
- ここまでの内容を踏まえたOpenMetadataのデモ実演を実施。(47:07〜48:28まで)
OSS活動
- OpenMetadataの開発に貢献し、導入の機会を増やしたい
- バグの報告や改善要望Issueの作成、ドキュメント修正のPR等も対応
- 活動を行う中でOpenMetadataのアーキテクチャや実装内容についてのより深い理解が得られた
- 今後も継続的に開発に貢献し、OpenMetadataを活用していきたい
まとめ

質疑応答
川口 氏の登壇内容に関して、当日展開されたSlidoに寄せられた主な質問は以下の通り。質問パートは53:30辺りから。
- OpenMetadataをクラウド上にホスティングする際の一般的なプラクティスがあれば教えてください。メタデータをためるDBはAWSであればRDSなど専用のサービスを使うのか、それともECS、EKSなどでDBやElasticSearchのコンテナを立ててしまって賄うのか、など
- (図書館の話のように)データカタログって、コンセプトとしては万人にデータを解放する印象があるのに、実際は専らデータエンジニアの業務効率化のために使われるイメージがあります。例えばビジネス職がユーザーの場合でも(SQLは書ける)、OpenMetadataのようなデータカタログ提供がデータ利活用促進に繋がると思いますか?
- OpenMetadataでDWHに対してデータの収集、テストを行うと、DWHのコストを消費すると思いますが、コスト削減出来る運用方法があれば教えて欲しいです
- テーブルの差分チェック機能が気になったのですが、具体的にどのようなテストがなされて、どういった結果が表示されるようになっているのでしょうか?
- OpenMetadataはSaaS版があると思うのですが、OSS版との使い分けはどのようにされていますか?(こういう要件があればSaaS使うなど)
- リネージのお話でSQL実行結果から自動で生成されるようなお話がありましたが、OpenMetadataでクエリエディタがありSQLが実行出来るイメージであってますでしょうか
- 検索結果として、Column一覧が取得したいケースもあると思うのですが、そのようなデータカタログを見つけれてないです。OpenMetadataでもできない認識なのですが、何か世の中に存在したりするのでしょうか?
事例講演①「Streamlitのデータカタログが社内にもたらした変化」

- 登壇者:山口 歩夢 氏 (株式会社GENDA IT戦略部・データエンジニア)
はじめに
- 自己紹介
- 元々は営業職、データエンジニアにジョブチェンジ
- 著書に「Streamlit データ可視化入門」
- 情報発信を評価され、Snowflake Squadにも選ばれた
- 本日のお題は「Streamlitのデータカタログが社内にもたらした変化」について話します
- 会社紹介
- 株式会社GENDA
- グループを横断したデータ活用で利益の向上を目指している
- グループが提供するサービスの相互創客を目的とした機能「GENDA ID」を導入し、IDとプロダクトの紐付けを行っている
- 「グループ横断でデータ利活用ができるデータ基盤を構築・運用すること」がGENDAデータチームの目的。CTOもデータの重要性について明言しており、多種多様な事業・データが存在する中でデータマネジメントを進めていきたい。そのためにもデータカタログが必要
データカタログ導入まで
- 多種多様な事業・データを横断的に活用するために以下の状態を目指したい
- データの関連性を把握できる
- データ利活用が活発である
- データの品質を管理できる
- データマートの作成者が把握できる
- データカタログを導入したいが、重要性の理解が社内で広まっていなかった。なのでまずはStreamlitで自作するところから始めてみた
- 自作するまでの経緯
- 社内でデータカタログの有用性を知ってもらう必要がある
- 既存データカタログを調査したが高額。参入障壁が高いと感じる
- Streamlitなら無料且つ比較的簡単に開発出来そう?
- チーム内で提案した結果「やってみよう!」という流れに
- 自作するまでの経緯
Streamlitで開発したデータカタログ

- 特徴
- ドロップダウンでDB、スキーマ、テーブルを選択し、内容を表示可能
- テーブル概要を検索可能
- システム設計

- この部分はStreamlit in Snowflakeを使うことでシンプルなインフラにすることも可能
- メタデータ定義フロー
- yamlで管理。GitHubにPushし、mainブランチにmergeする事でGitHub Actionが走り最終的にメタデータ更新がされる流れを作る
導入結果
- 非常に好評!社内に於いてデータカタログとメタデータの重要性を理解してもらえた
- データカタログに必要な新たな機能を把握出来た
- 更に直感的にメタデータを素早く見付けられるUI
- データリネージ機能
- データの品質把握
- 更に詳細なメタデータ検索
- Streamlitの知見を得られた
- 結果、データマネジメントが捗るようになった
今後の展望
- 理想的なデータマネジメントに向けて更に進んでいきたい
- Streamlitが有用な技術だと分かった。特にDX観点で事業に貢献出来そうだと分かったので各種ツールを自作して貢献していきたい
- DX観点で実際に開発したアプリケーションを幾つか紹介。実店舗運営の方々に直接ヒアリングしながら「あると便利」な機能を考えて提案しながら開発出来るところが大変でもあり楽しいところ。
- 景品毎の公開ステータスを可視化するアプリケーション
- 景品の売上や売上見込を可視化するアプリケーション
- 景品の売上数値などを様々な角度から可視化するアプリケーション
まとめ
- 会社方針実現のためにデータカタログが必要だった
- Streamlitを使いデータカタログを自作したことでデータマネジメントを促進できた
- StreamlitがDXに貢献できることが分かったので今後も更に便利なアプリを開発出来そう
質疑応答
山口氏の登壇内容に関して、当日展開されたSlidoに寄せられた主な質問は以下の通り。質問パートは1:28:50辺りから。
- データカタログの立ち上げ期において、スクラッチのデータカタログで組織に価値を認めて頂けたのは
素晴らしいと思います。その一方で、OpenMetadata等を純粋に追いかけていくと大変かと思いますが、
今後もこのデータカタログを使い続けるのか、今後はOSS・SaaS等に乗り換えるのかなどの中長期ビジョンはありますか? - データマネジメントが必要→データカタログツール導入となった思考(検討)のプロセスをもう少し教えていただけないでしょうか?
- データアプリの開発やデータカタログ作成などを通じて社内のデータ活用を促進する際に、何かモニタリングされていた指標があれば教えて頂けないでしょうか?
- メタデータの更新をどう仕組み化していくのかがとても難しい部分かと思っていますが、何か工夫された点や取り組んでいることはありますか?
- このデータカタログの初期リリースまでにはどれくらいの開発期間を要したのでしょうか?
共催LT2「COMETA開発の裏側をご紹介」
- 登壇者:中村 愛美 氏 (株式会社primeNumber COMETAチーム Senior Manager)

事例講演セッションの合間に発表された共催LT2つめはprimeNumber社が展開しているデータカタログ製品「COMETA」に関する内容でしたので当エントリでも採り上げたいと思います。
COMETAの概要
- データの発見・理解を促進するデータカタログSaaS
- 散らばったデータを管理し、安全かつ効率的にデータを利用可能に
- 主な機能
- メタデータ検索
- カラムリネージ
- クエリエディタ
- ER図
- JOIN分析
- 用語集
- 構成要素
- メタデータ閲覧・検索UI
- メタデータ取り込みバッチ
- DWHのメタデータ取り込み
- TROCCOで転送しているメタデータの自動生成
- 検索インデックス生成
- リネージ生成
エンジニア視点でご紹介するCOMETAの特色
-
(1).カラムレベルリネージ
- BigQuery, Snowflake共にSQLパーサライブラリを拡張して実装
- AST(Abstract Syntax Tree:抽象構文木、SQL言語のコードの構造をツリーとして表現したもの)を読み解く地道な作業の上に実現されている機能
- 現在はTROCCOデータマート機能を利用する場合のみ対応
- 今後はビューのリネージやdbtビルドの結果のSQLを用いたカラムレベルリネージも拡充予定
-
(2).ER図とJOIN分析
- ER図
- リレーションを定義する事でER図をリアルタイム表示。
- 論理的なテーブル同士の俯瞰を把握、分析者がテーブルの詳細画面から関連する情報を探すことが出来るように
- リレーション作成方法は現在3種類の方式に対応
- 手動でカラム同士の関連を登録
- 転送元の外部キー情報を利用して自動生成(TROCCOを利用している場合)
- カラム同士の関連を記載したCSVをインポート
- JOIN分析
- ER図のノード同士を繋げることでキーでJOINした結果が視覚的に分析出来るように
- データの適切な結合方法をデータを見ながら確認可能に
- ER図
-
(3).日本語検索対応
- 日本企業がメタデータ管理するにあたって肝になる機能。
- Elastic Searchプラグインで日本語検索を実現
直近のリリースと今後について
-
直近リリース

-
今後について
- Tableau連携、dbt連携、DWHから取得するメタデータの強化などを予定。
-
皆様の「こんな機能があったら良いな」の声をお待ちしています!
事例講演②「COMETAを用いたデータ品質管理と業務標準化への取り組み」

-
登壇者:森 和也 氏 (株式会社サミーネットワークス マーケティング部)
-
自己紹介
-
会社紹介
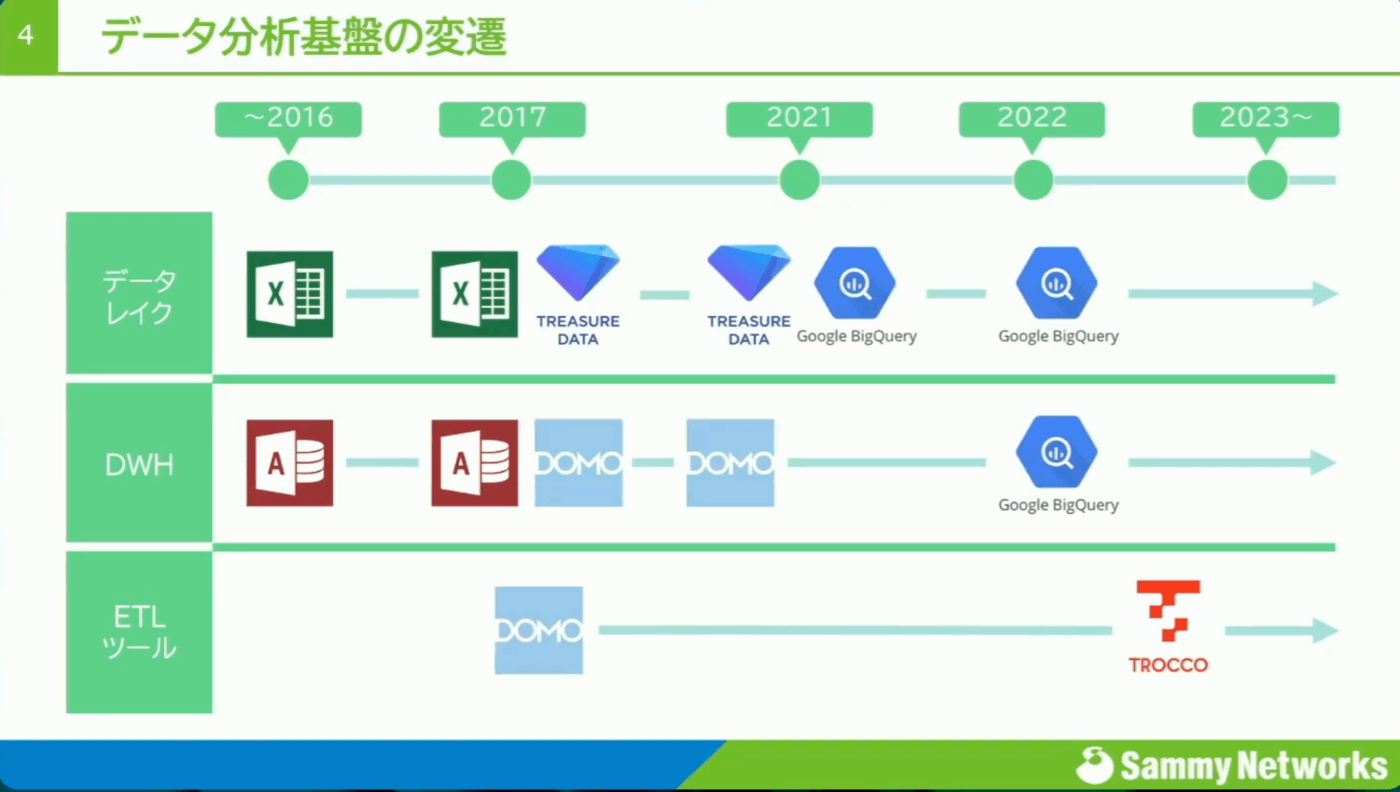
データカタログの変遷
- 経緯
- 元々は各CMSツールからCSVをダウンロードし、ACCESSで処理をしていた
- 2017年からDOMOを導入、データ収集から集計処理までの自動化を図った
- 2020年にデータ分析環境を刷新、BigQueryに切り替える
- 2021年からETLツールとしてTROCCOの利用を開始、今に至る
- 変遷の背景:下記背景理由により、自部署でデータ基盤を再構築すべくプロジェクト化へ
- データ分析によって課題解決や意思決定を支援する組織として誕生
- BIツールの導入と共にデータ基盤をクラウド化
- データ収集はインフラチームに大きく依存
- 課題の解決
- スケーラビリティの不足:BigQueryを自部署で導入することで対応
- 適時性の低さ:各サービスのDBからBigQueryにログを直接送信
- 複雑化したデータフロー:集計処理をBigQuery上に統一
- ユーザビリティの低さ&データ品質保証が未確立:ここはそもそも、当時は課題であることに気付けていなかった
-
新たに生まれた課題:これらの問題を解決するためにTROCCOを導入。
- データフローの追跡が困難
- サービス側DB以外からのデータ取得がボトルネックに
- シンプルに『時間が足りない』
データカタログ(COMETA)導入に至った理由
- 現在のデータ分析基盤

- BIツールはこのタイミングでTableauに切り替えている。新しいデータ分析需要が生まれ、サービス間を横断した集計や分析が増えた
- 未解決の問題に気付く → 業務効率化と属人化解消のためにメタデータの整備が必要、データカタログの導入を検討へ。
- 担当していないサービスのデータが分からない
- 他部署とのコミュニケーションが増加
- データカタログの導入:データカタログに求めたもの
- メタデータをGUI上で入力出来る
- 利用するのは非データエンジニア
- ER図やデータリネージが自動で作成される
- データ相関図やカラムの関係性を可視化するのは大変
- メタデータをGUI上で入力出来る
- 上記ポイントから、TROCCOからシームレスで利用できるCOMETANO利用を開始。
- ちなみに利用開始時点では『あったほうが良いよな』くらいの認識だった
メタデータの整備をどのように進めたか
- データカタログ活用への道筋
- まずは自分から
- 整備ルールを決める
- 〆切を設定、都度の進捗確認
- 実例紹介:メタデータ管理ダッシュボード
- データカタログ活用への道筋
- メタデータ整備の過程でデータの棚卸、品質管理の重要性に気付く
- 潜在していたリスクを発見する事ができた
- データ品質管理プロセスを定めなくてはいけない

COMETAを導入した結果データ品質と業務標準化にどう寄与したのか
- COMETA導入による効果
- 未着手の課題について
- ユーザビリティの低さ:データカタログの導入で解消
- データ品質保証が未確立:ここはこれから取り組んでいく課題
- 良かった点
- 業務標準化を進めることが出来た
- データ品質管理の必要性に気付けた
- サービス側DBの変更による分析DBへの影響がひと目で分かるようになった
- 未着手の課題について
- 今後の課題
- データ品質管理プロセスの構築
- メタデータ整備の継続
- データモデリングの改善
おわりに
- データカタログは重要性を理解していない時こそ導入するべきかもしれない
- 最短経路ではないけれど少しずつデータ基盤を進歩させられている
質疑応答
森氏の登壇内容に関して、当日展開されたSlidoに寄せられた主な質問は以下の通り。質問パートは2:12:10辺りから。
- メタデータが入力され拡充され、メンバーにとって価値があるものだと認められるまでのギャップを越えるまでが大変かと思います。御社でそこをどう乗り越えたか、乗り越えるまでの工夫があれば教えてください。
- ビジネスメタデータ拡充を行うにあたって、コラボレーション機能とAIによるサポート等のお話が川口さんの発表の中にあったかと思いますが、どのような方向性の機能があると良いと感じますか?
- ビジネスメタデータはアプリケーション開発側のメンバーにも入力いただけたのでしょうか?それともメタデータ管理の業務フローができるまではデータ活用部署で入力したのでしょうか?
- 先日の川口さんの発表を踏まえて、OpenMetadataとCOMETAを比べてメリットデメリットなど、どう感じられていますか?
ゆずたそ(@yuzutas0)さんからの質問
- イベントの質疑応答タイミングでは、風音屋のゆずたそ(@yuzutas0)さんもそれぞれのパートで参加し、Slidoでの質問とは別に鋭い視点、切り口でディスカッションされていました。動画登場時間は各セッションの「質疑応答」セクション記載リンクからご参照ください。
まとめ
セッションレポートは以上です。想定以上に長くなっちゃった!
- 基調講演OpenMetadataセッションは機能概要が俯瞰できてとても参考になりました。
- Streamlit便利ですよねぇ。何より無料だし『まずはじめてみる』ステップで試しに(データカタログ機能を)実装してみる、というのは効果的なチャレンジだな、というのは思った次第。
- COMETA、手始めにデータカタログ触ってみようかな...ってなった時に取っ掛かりやすそうなサービスだな、という印象。トライアルって出来るのかな? → COMETAについてを見る感じだと要問い合わせな模様。
その他個人的に幾つか気になったものをX投稿から。
↓
LT登壇者の方から直々に返答頂きました。ありがとうございます!
↓
日本語的には「スライド」っぽい?
Discussion