[レポート] Tableauデータスタックユーザー会 第5回 Tableauユーザーのためのdbt入門
2025年04月08日(火) Tableauデータスタックユーザー会 第5回のイベント『Tableauユーザーのためのdbt入門』がオンライン(YouTube Live)で開催されました。
個人的にdbt Labs, Inc.社の御二方、dbtに関するセッションが気になったので、動画を参照しながらレポートとメモをまとめておきたいと思います。
dbt Cloudのご紹介

- 登壇者:浅野 翔太氏(dbt Labs, Inc.)
自己紹介
- dbt Labsの日本第一号社員。先日までSnowflakeの社員として、KT氏と共にSnowflakeを日本に広める活動をしていた。
- dbtは現在どんどん普及しており、Tableauユーザーの皆様にもぜひdbtの良さを広めたい。dbt Cloudの良さを広めたい。
- 来週開催されるTableau Conference、dbt Labsもブース出展します。現地参加の方々いましたら是非お立ち寄りください。(ブース #202)
データの信頼度低下はAI時代におけるCIOの悩み
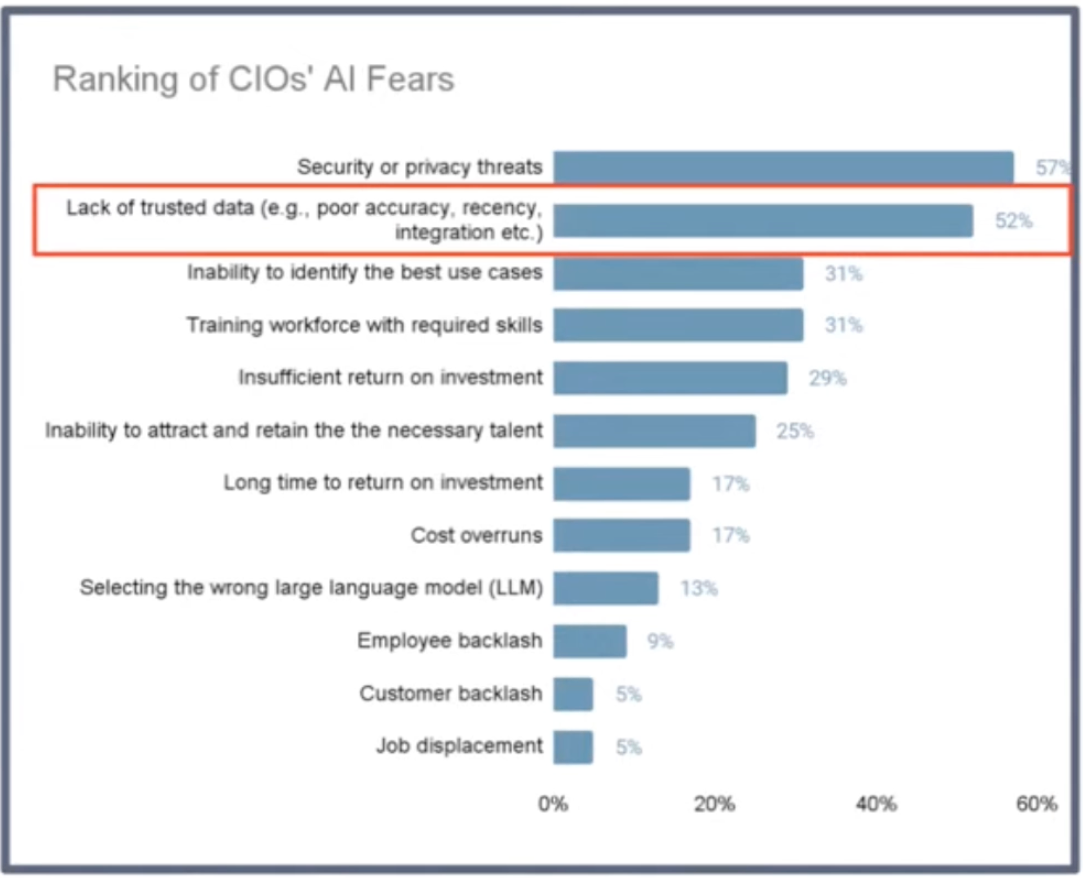
(※CIOの懸念事項のランキング)
- 現在米国でも起きている問題。昨今、AI/LLMを聞かない日はない。社内外でAI活用の話は絶えない。
- ただ、一番の問題は「社内のデータの信頼度が、AIを活用しても低いままで悩んでいる」というところ。せっかく強力な生成AIサービスがあっても、社内のデータが汚いままだと正しくない答えが返ってきてしまう。
- 「データの整備」が一番悩ましいポイント。ここはAIを使ってもどうにもならない、地味で泥臭い世界。
AIは人々の期待を変えている
- 社内を取り巻くAIの環境は毎月、毎週のように変化している。
- 社内で使っているデータ基盤をAIでいい感じに出来ないかな?と試行錯誤されているのがここ最近のムーブかと思う。おそらくこのあたり、来週(2025年04月15日〜17日,米国サンディエゴにて)開催されるTableau Conferenceでもメインテーマとなるのでは。
- Tableauユーザーにおいても、分析を取り巻く環境は進化を続けてきた。過去20年を振り返ってみる
- レガシーなレポーティングシステムを活用する時代を経て、Tableauが生まれることによって2004年頃からかなり革新的に便利なアナリティクスが出来るようになってきた。
- そして去年(2024年)くらいから、徐々にAIにシフトしていく形になっている。今年来年くらいになるとTableau/AI/Salesforceというところを活用することによってデータが飛躍的に使いやすくなる、そんなところが現在MDS(Modern Data Stack)を取り巻く環境。
dbtのモデルとメトリックスが分析を支える〜信頼されたデータで分析を実現〜

- データをレイヤー毎に分けていったときに、一番下のレイヤーにはデータウェアハウスが存在。
- TableauなどのBIについては上の方にあるアナリティクスレイヤーが該当。
- dbtは下から2つめにある「データモデリングレイヤー」に位置する。一番下のデータレイヤーとアナリティクスレイヤーを繋ぐようなプロダクト。
dbtとは
-
dbtはクラウドデータプラットフォーム上に位置し、組織がSQLとソフトウェアエンジニアリングのベストプラクティスを使用し、ELT型のデータモデリングを強力に推進するプロダクト。
-
データウェアハウスに入ったデータはそのままに、そこに被せるような形でデータを使いやすく変換したり、Tableauに渡すような存在。
-
データウェアハウスのデータを安く早く加工することで、Tableauでデータを見ても正確かつ新しいデータを見られるようになる。そういう世界観を目指している。
-
データ開発業における一貫性のないプロセスはデータ品質と信頼性の低下に繋がる
- オンプレのデータをModern Data Stackに移行したとしても、データがぐちゃぐちゃのままで上手く分析出来てない...というケースも多い。
- サイロ化
- トラブルシューティングが大変
- データの信頼性が低い
- オンプレのデータをModern Data Stackに移行したとしても、データがぐちゃぐちゃのままで上手く分析出来てない...というケースも多い。
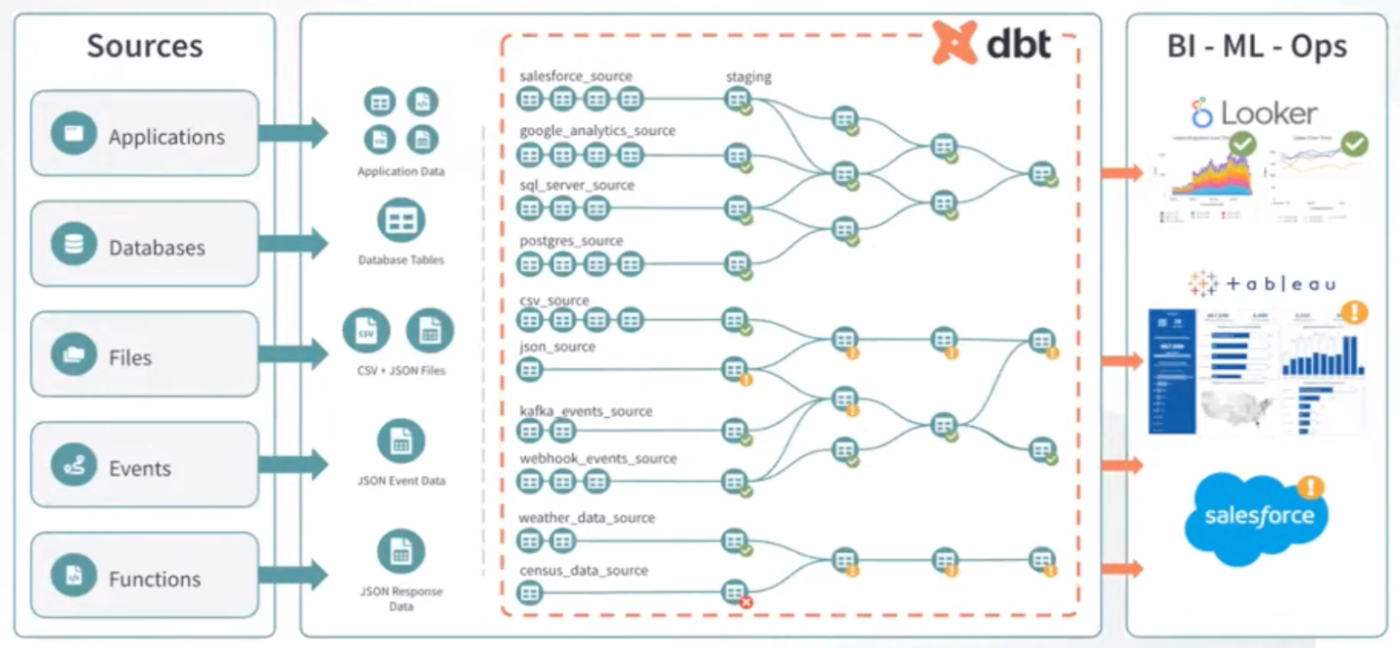
-
dbtはデータ開発のプロセスを標準化し、関係者全員がテスト、リリース、文書化出来るようにサポート
- dbtを導入することで...
- ぐちゃぐちゃなデータを綺麗に整備する事ができる。
- データ基盤のメンバーとアナリティクスのメンバーが同じ設計図を見ながらデータを活用することが出来るようになる。
- より透明性を持ってBIツールを使うことが出来るようになる。
- 結果としてより高速かつ、エンジニアリングリソースも少ない状態、少ない人数でデータ基盤全体を維持運営出来るようになる。コストの最適化にも繋がる。
- ユーザ間の関係性を踏まえて分かりやすく図示したものが以下。
- dbtを導入することで...
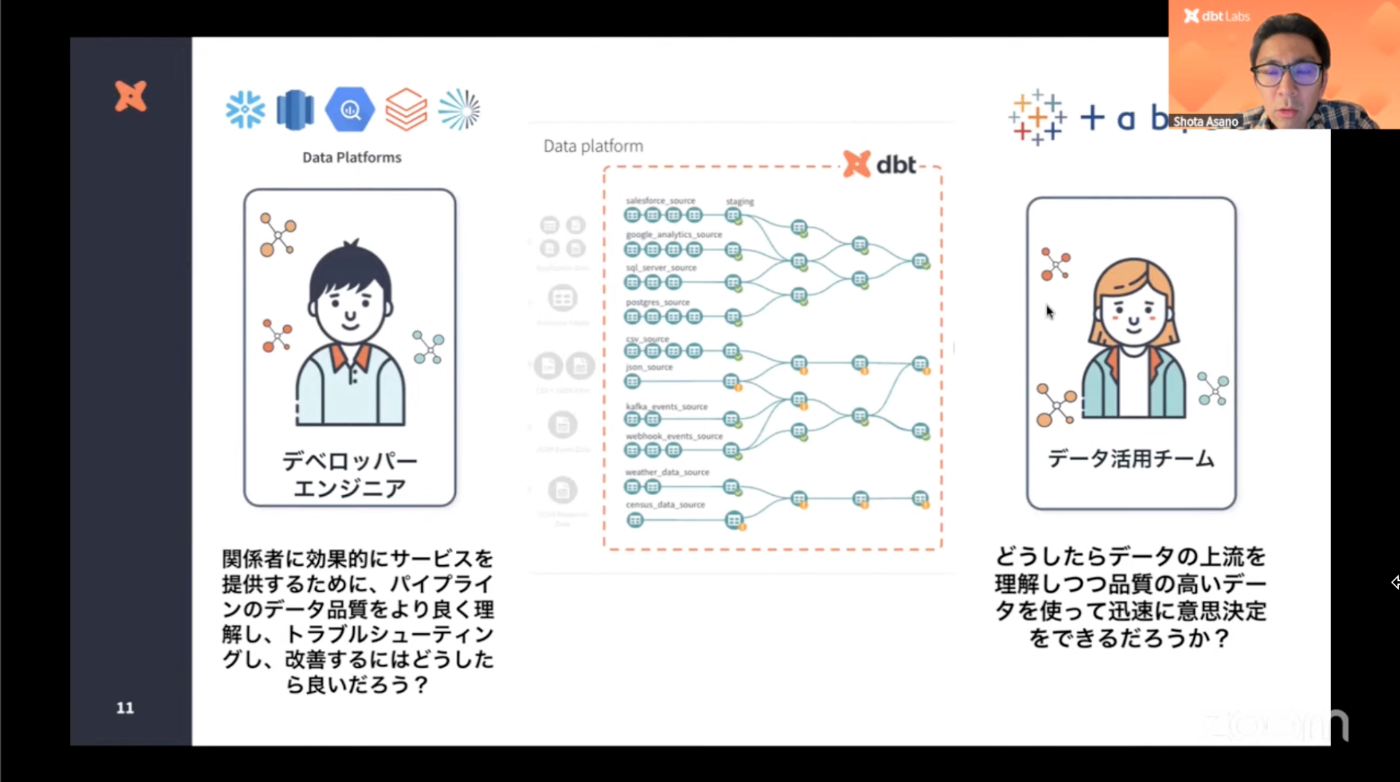
- 後述する「dbt Explorer」というGUI/機能を使うとこのあたりのエンジニア間連携がとてもスムーズになる。dbt(dbt Explorer)は社内のデベロッパーチームとデータ活用チームの架け橋となることが出来る。
- デベロッパーエンジニア:トラブルや改善点を理解
- データ活用チーム:信頼・データ活用、意思決定
分析開発のワークフロー(ADLC)とは
- ADLC = The Analytics Development Lifecycle
- dbt Labs社が最近提唱しているもの。(左側の)データ基盤チームと(右側の)オペレーションチームが手を取り合い、8の字を描くように計画、開発サイクルを回し、フィードバックを得ながら進めていく。
- dbt Cloudでは、以下のように各フェーズにおいてサポートする機能がある。

- Plan(計画):
- Develop(開発):
- Test(テスト):
- Deploy(デプロイ):
- Operate(操作):
- Observe(観察):
- Discover(探索/発見):
- Analyze(分析):
まとめ

dbt Cloudは、ユーザー(データ開発者、データアナリスト、またはそのビジネス関係者)がADLCの様々な段階で分析製品を構築、展開、活用するのを支援する"データコントロールプレーン"である。
dbt Cloud: LIVEデモ
- 登壇者:伊藤 俊廷氏(Solutions Architect/dbt Labs, Inc.)
続いての伊藤氏によるセッションは、実際にdbt Cloudの画面を見ながら/操作しながら諸機能の紹介をするという内容でした。
ちょっとおさらい
- データ利用チームから見た「よくある課題」:
- データモデルの透明性の欠如
- モデルへの関与の難しさ
- アナリスト、ビジネスユーザーからすると、データパイプラインの更新状況や品質がわからない
- データパイプラインのモデルの一部を修正したいが、修正の仕方がわからない/失敗して本番データを壊したら怖い
デモ実演:dbt Explorer
まずは「データパイプラインの更新状況や品質がわからない」課題に対するソリューションをデモで紹介。まずはTableauのダッシュボードからdbt Cloudの機能「dbt Explorer」を使った実演を行っていました。
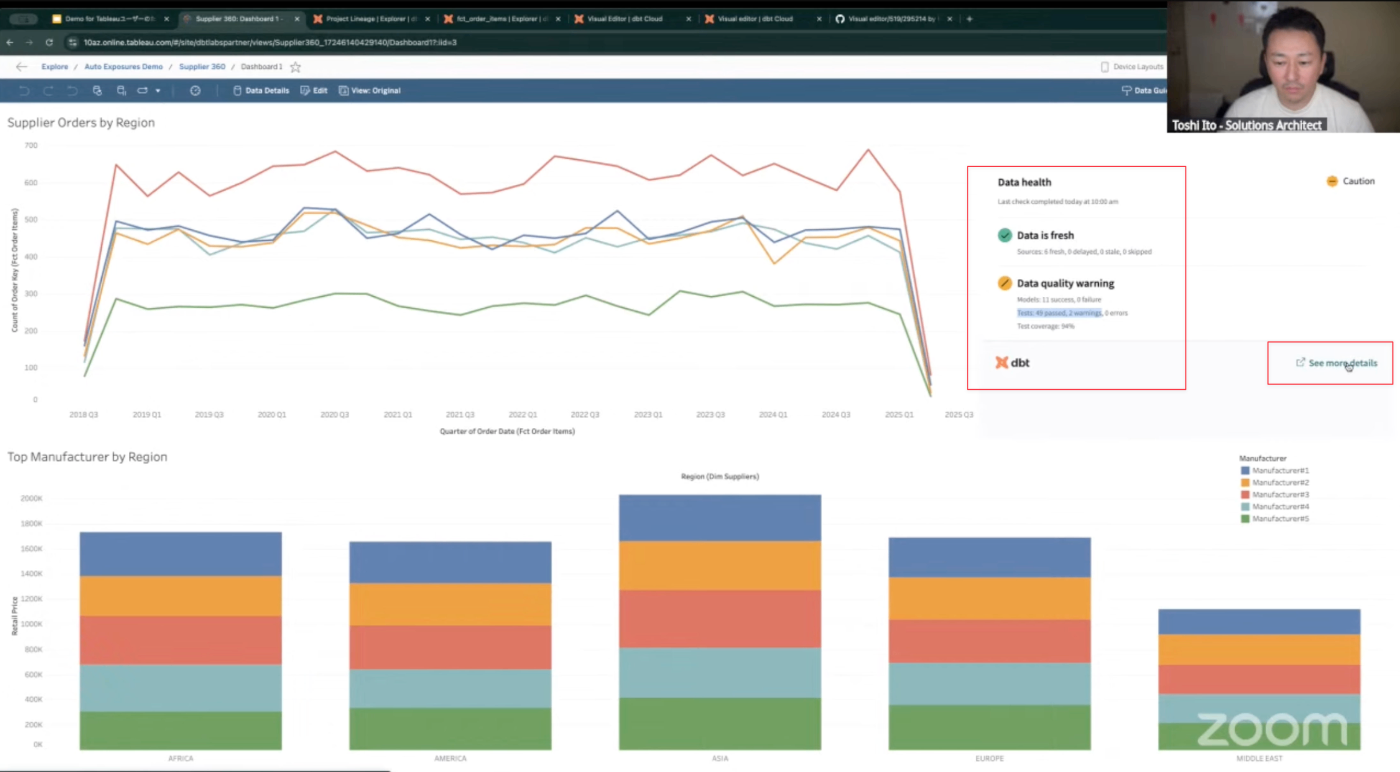
- こちらの画面、実はdbtの情報が付与されている。(画面右上)
- ダッシュボードが参照しているテーブルの状態がfreshである(Data is fresh)ということが分かるようになっている。情報の鮮度に関しては問題なさそう。
- 一方、データ品質に関してはアラートが表示されている(Data quality warining)。テスト実行件数のうち数件がアラートになっていることからこの表示となっている模様。こちらの情報を以て、場合によってはモデル開発者、担当者に確認をいれることが出来る。
- モデルの情報、モデルの定義を見ていきたい!という場合は画面右側、[See more details]のリンクを押下することによって詳細画面に遷移出来る。

- ダッシュボードに対応する詳細な情報が表示。
- [Data Health]の部分は上述画面で表示されていた内容と対応。
- 下の方にはデータモデルの依存関係を示す「リネージ」が表示されている。[supplier_360]のダッシュボードが、2つのモデル(dim_suppliers,fct_order_items)を参照していることが分かる。
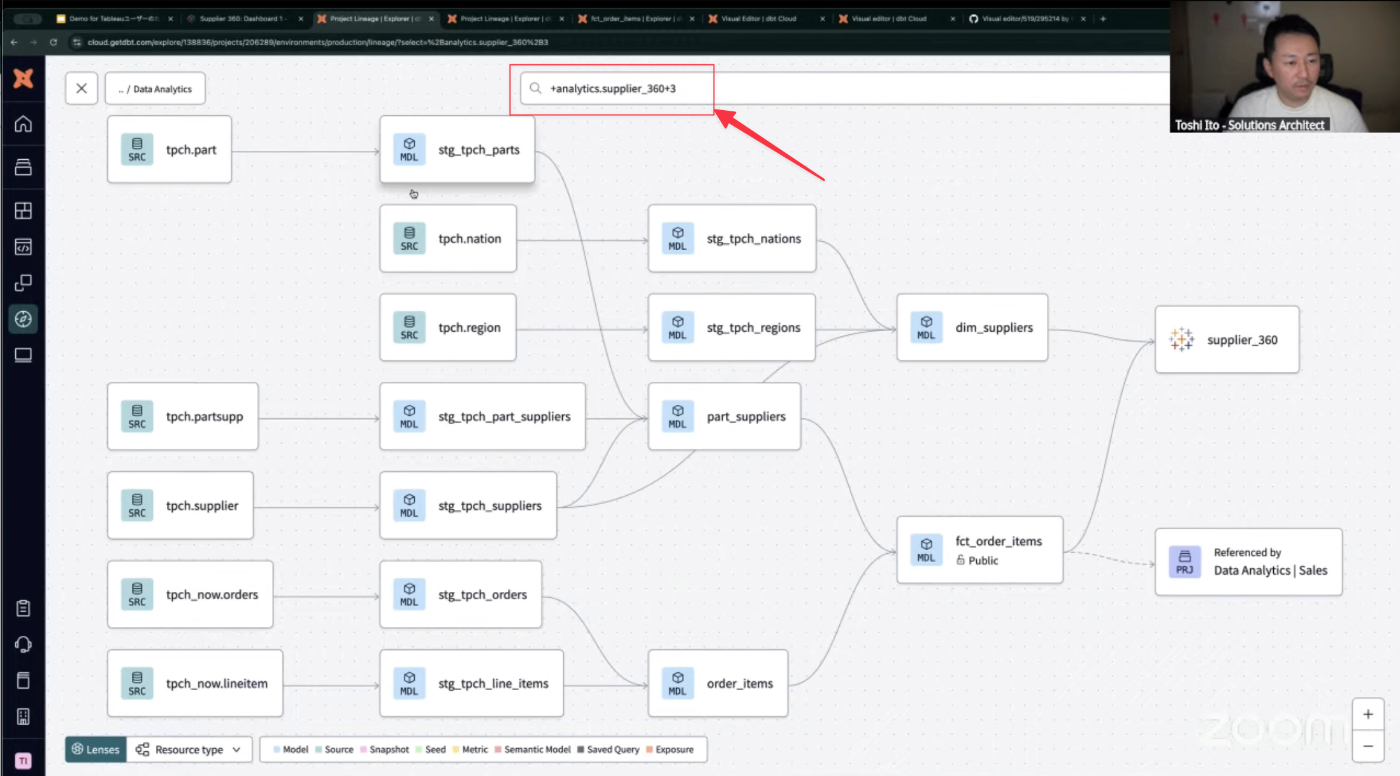
- リネージは必要に応じて全体表示も可能。また、画面上部の検索窓に所定のキーワードを入れることによって表示範囲を制御することも出来る。この画面では、Tableauダッシュボードが参照している「大元の情報、データ」がどういうものなのかを辿ることが出来ている。(画面左側のtpch.xxxxxテーブル郡が該当)

- Tableauダッシュボードが参照しているファクトテーブル:[fct_order_items]の詳細を見てみる。
- 「Latest Status」の箇所で、モデルに対するテストの内容が確認出来る。3つのテストが実行され、いずれも成功している。
- また、データリネージについては対象となっているファクトテーブルを中心とした範囲の表示がなされていることが分かる。

- ページを下に遷移していくと、テーブルのコメント(Description)やその他詳細情報を確認することも出来る。テスト結果のサマリ、テーブル属性、タグ情報、テーブルの所有者など様々な情報が確認可能。
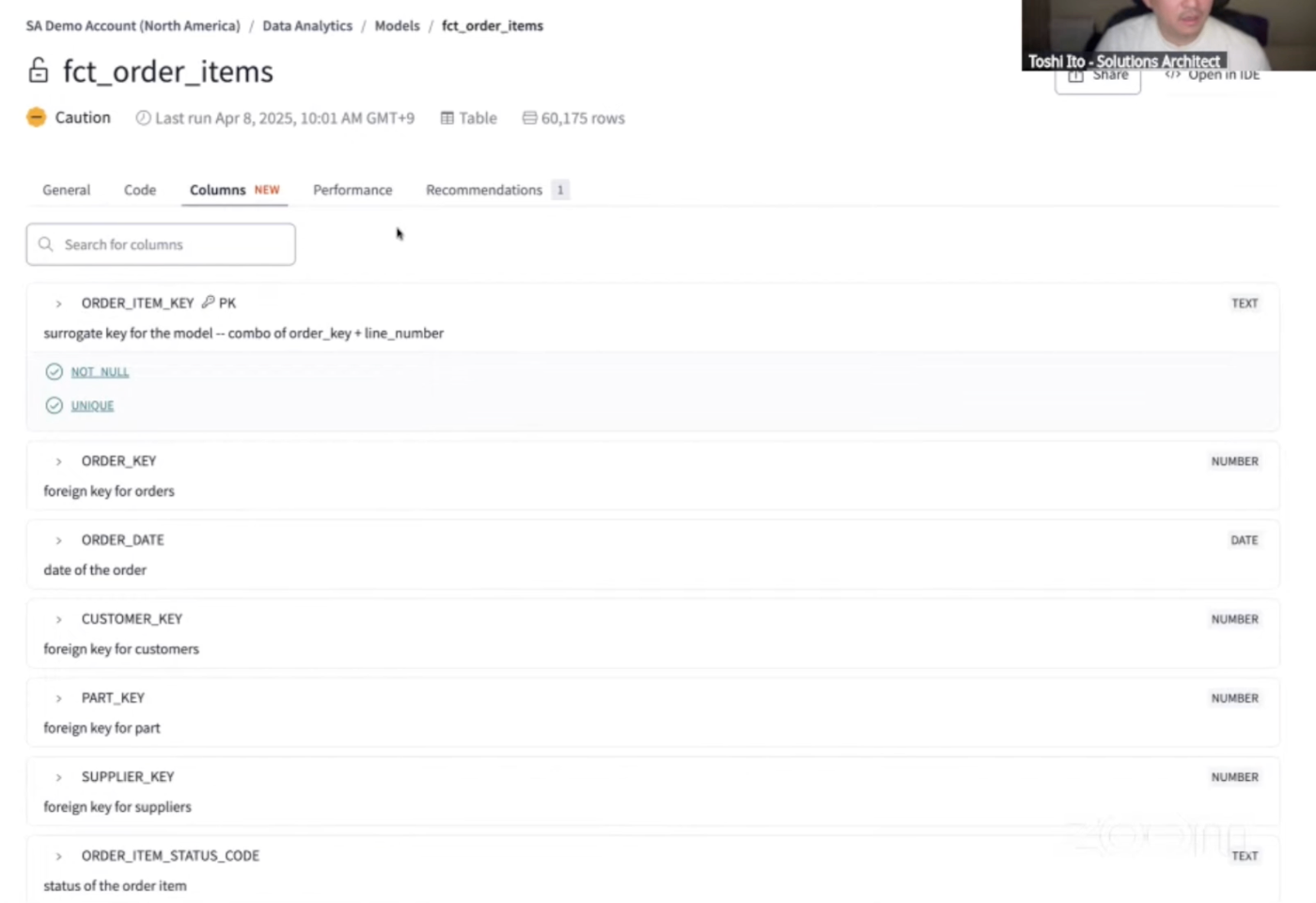
- [Columns]タブではテーブル定義の詳細な情報を見ることも出来る。

- そしてdbt Cloudでは「カラムのリネージ」もこのような形で参照可能。対象のカラムが、上流ではどのような内容、名称だったのかを辿ることが出来る。
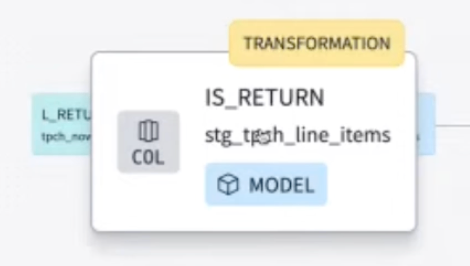
- カラムに表示されている[TRANSFORMATION]は、何らかの加工処理が施されていることを意味する。
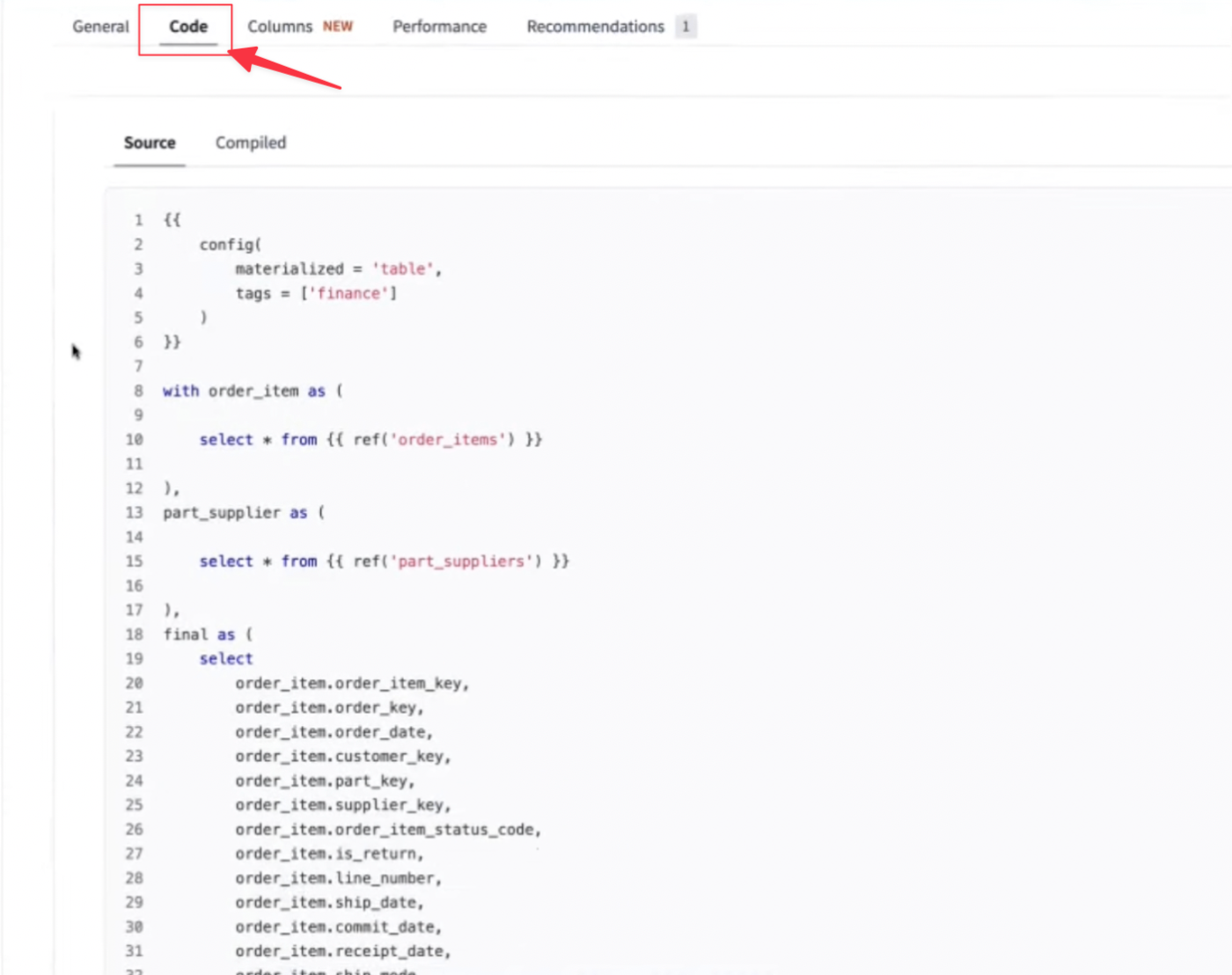
- モデルをより深く理解したい、という場合は[Code]タブで、モデルを構成しているSQLソースコードを確認することが出来る。
- SQLは幾らでも複雑に書くこと出来るが、dbtを使うことのメリットは、SQLをブロックで記述、構成してくれる(推奨している)ところ。基本的には複雑度がそんなに高くならないような記載に落ち着かせることが出来る。
デモ実演:dbt Cloud IDE(統合開発環境)
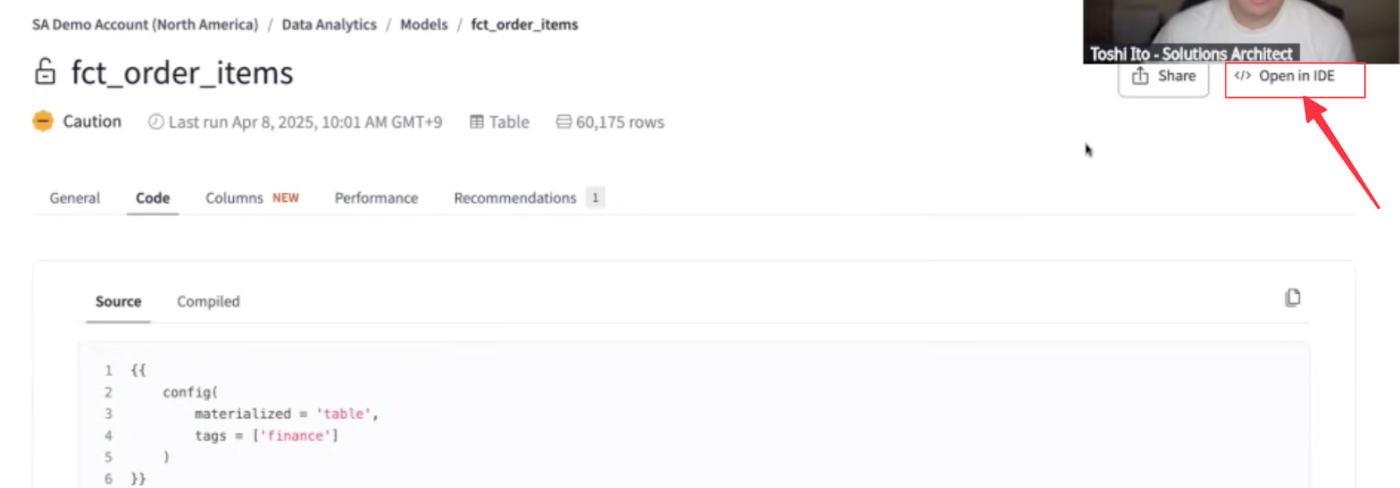
- 上述のモデル、エンジニアであれば画面右側の[Open in IDE]からdbt Cloud IDE(統合開発環境)の対象モデル編集画面に遷移する事ができる。

- この画面ではモデルの作成、テスト、リネージの参照など様々な操作が行える。dbt Cloud IDEで出来ることの詳細は下記参照。
デモ実演:Visual Editor(ビジュアル・エディター)
ここで浅野氏の前セッションで紹介のあった「Visual Editor(ビジュアルエディター)」の実演に移りました。
これは2025年04月現在、Beta版の機能。SQLが苦手なユーザーでも、dbtのモデル作成をGUIベースで実施可能となります。前セッションで浅野氏から機能概要紹介がありましたのでこちらに該当スライド部分を表示しておきます。

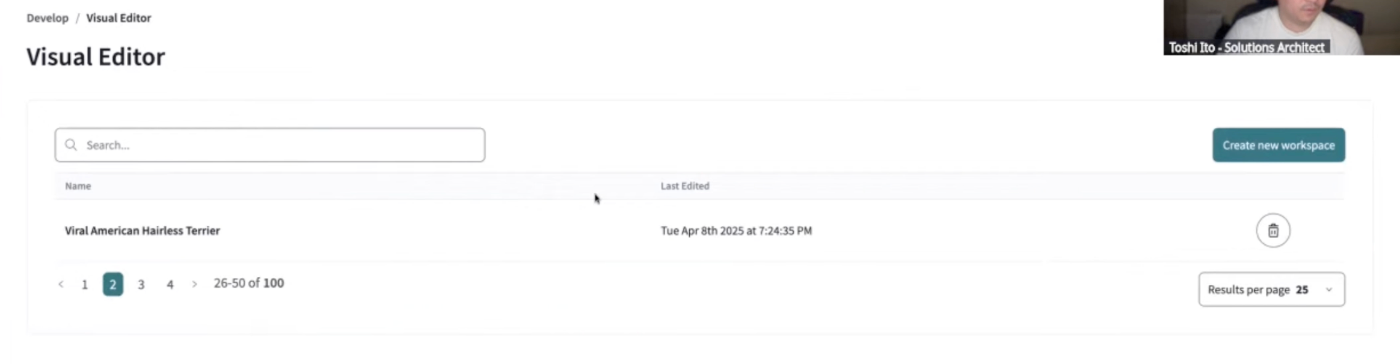
- Visual Editorの画面からワークスペースを作成。(画面右上の[Create new workspace])

- まずは「既存のモデルを修正」するケースの実演から。作成したワークスペースから[Edit existing model]を選択。
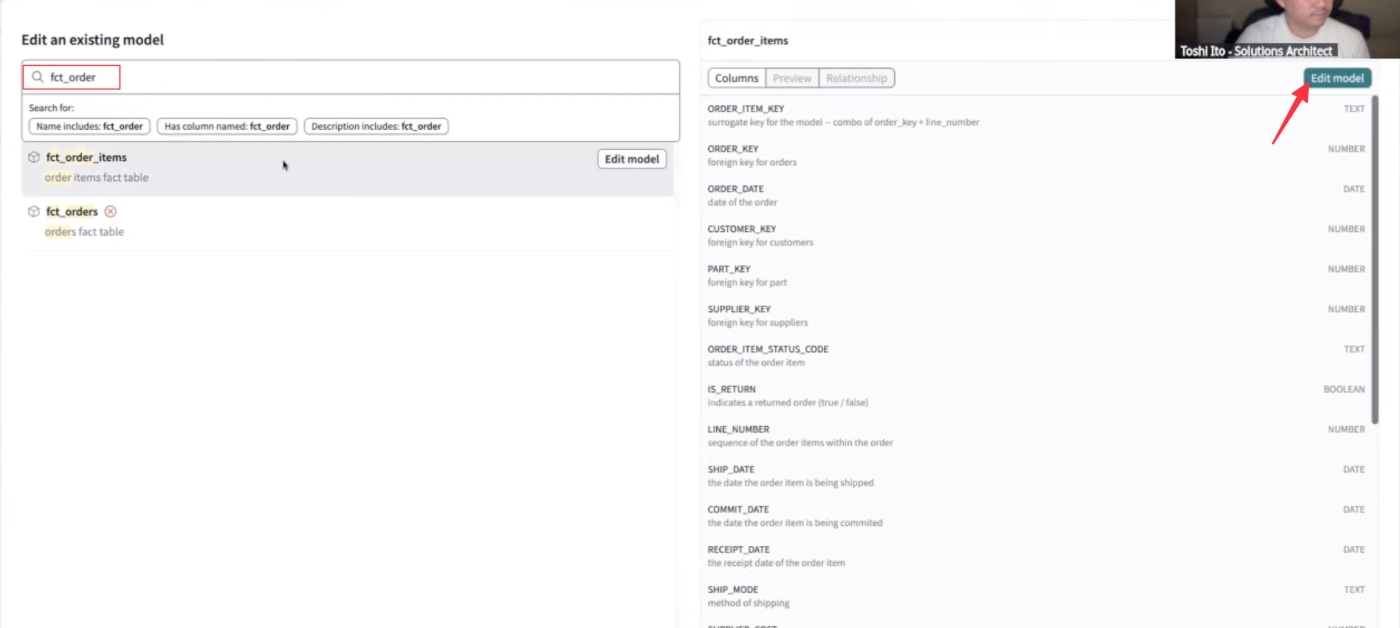
- 対象のモデルを指定[モデルは絞り込み検索可能]し、モデルを編集([Edit model])。

- モデルの編集画面に遷移。fct_orders_itemsは基本的には1行1行が注文項目を示すファクトテーブルとなっている。2つのソーステーブルをジョインしたうえで何らの変換処理と並べ替えを行い、最終的に項目を列挙したテーブルの形にしていることがグラフから読み取れる。

- ここでは新しくカラムを追加してみる。テーブル編集を行い、そのテーブルにどういう項目があるかを確認することもUIとして可能。

- ジョインした後のカラムの状態を確認することも出来る。

- ジョインした後の項目一覧の中で、[order_status_code]は現状非表示となっている。これを表示させる。表示させる(項目として利用する)場合は、カラムの右にある[+]をクリックすることで対応出来る。追加した項目は後続のテーブルで参照出来るようになる。

- 最終的にファクトテーブルにおいて[order_status_code]が選択出来ている。

- 注文(order)に関する利益率も出してみる。上記のように、エディタ上で項目補完をしながら計算式を作成。
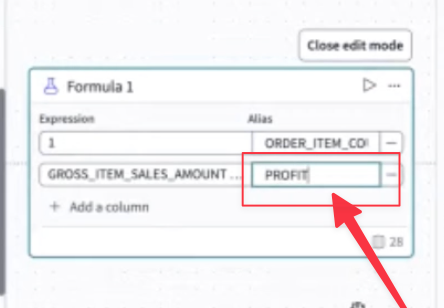
- 作成した項目は[Alias]として任意の名前を指定可能。
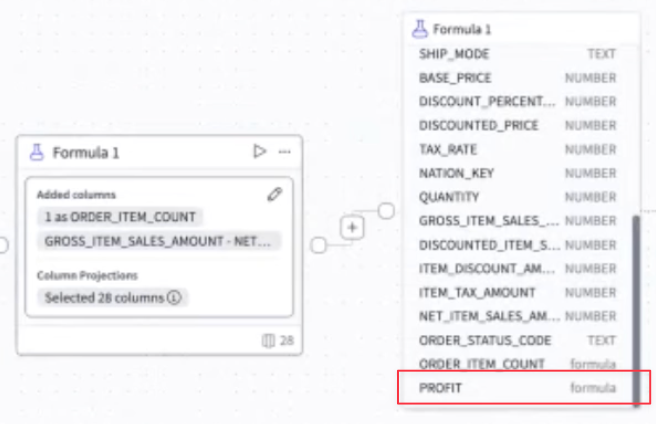
- 作成した項目が後続でも参照出来るようになりました。

- ここまでの内容(カラムを2つ追加)をプレビューで確認してみる。このようにデータとしても取得出来ていることが確認出来た。
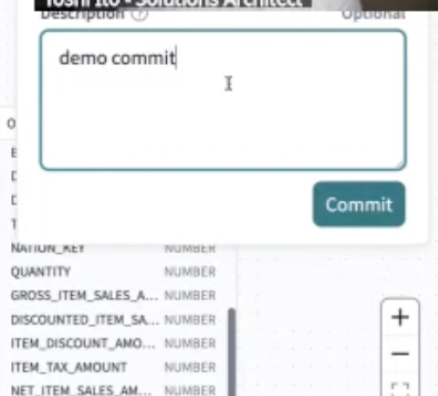
- ここまでの内容をソースコードに反映していく。メニューからCommit(コミット)を実行。コミットメッセージを入力し、[Commit]を押下。

- GitHubの画面に遷移。ソースコードのコミットをリポジトリへ反映させていく。

- SQLコードの内容をレビュー。ここは最終的に人が判断する。コードについてはここまでの操作でdbt Cloudの機能として良い感じに記載してくれている。

- 続いて、新しくカラムを追加する手順を試してみる。2つのテーブルを結合させたデータを作成。GUIにて参照させたいテーブル/モデルを指定していく。
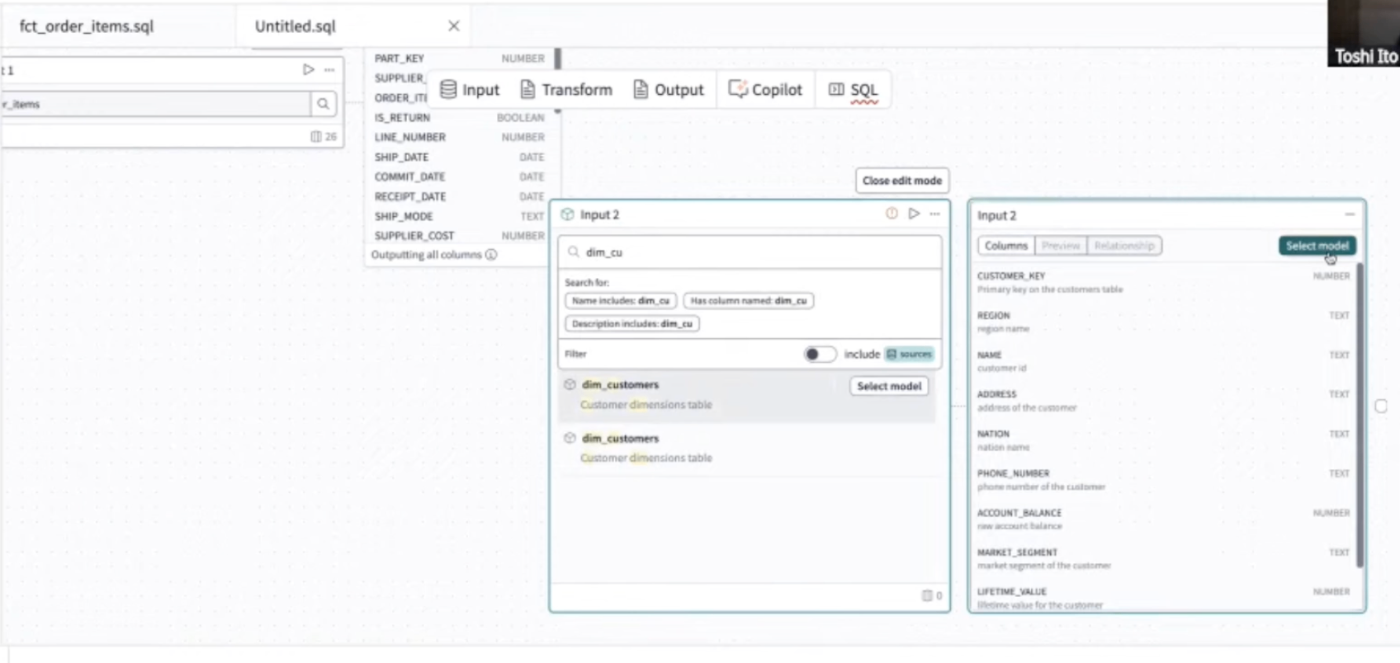
- モデル指定はGUIで絞り込みの上指定していくことが出来る。
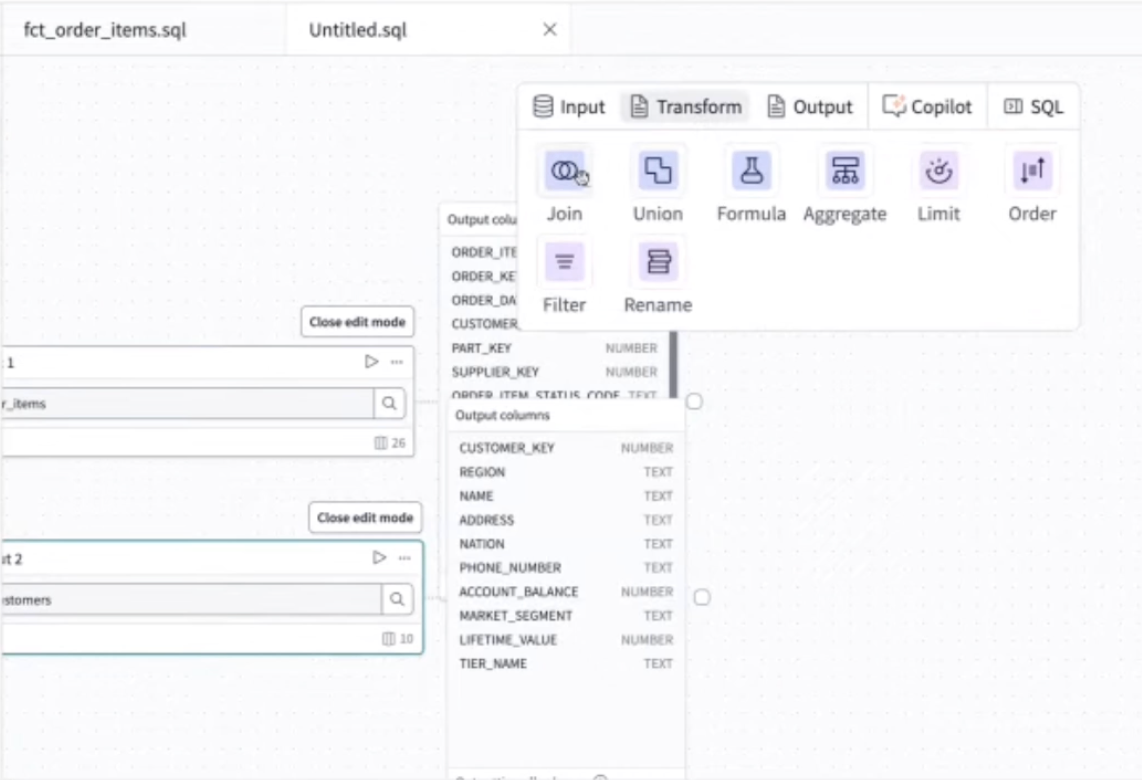
- 変換処理はあらかじめ用意されている処理を選択することで作っていくことが出来る。

- ここでは2つの項目を結合(ジョイン)させる処理を組んでいる。ここでは[CUSTOMER_KEY]を結合させる。

- アウトプットを繋げてプレビュー実施。2つのカラムを結合したデータが表示された。

- モデルの作成はCopilotを使っても対応出来る。

- [generate]を押下すると対応する情報を返してくるので内容を確認、[apply]を押下。
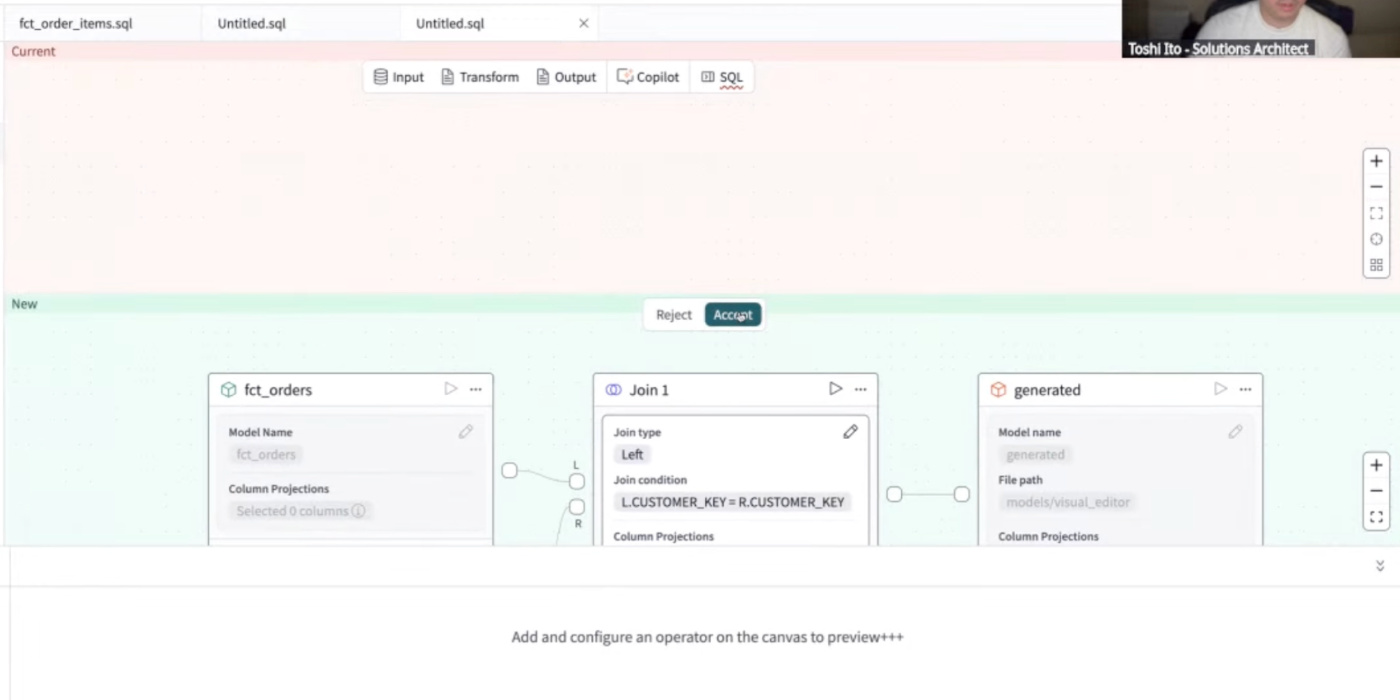
- 差分表示の形でVisual Editorに内容が反映された。[accept]を押下。

- 先程のケースと同様、Visual Editor上に処理が作成された。
機能紹介:Auto-exposures
実演デモという形での紹介は特になかったですが、今回のユースケースで有用と思われる機能の紹介が1つありました。dbtとTableauを密に結合することで、非常に面白いことが出来る「Auto-exposures」という機能です。

その他
上記2つのセッション詳細、及びパネルディスカッション部分については動画アーカイブをご参照ください。
まとめ
という訳で「Tableauデータスタックユーザー会 第5回 Tableauユーザーのためのdbt入門」のdbt Labs社御二方の登壇内容のレポートでした。ADLCの考え方については別途ホワイトペーパーも展開されているようなので別途情報として読み込んでおこうと思います。伊藤氏のdbt Cloud機能デモについてはとても分かり易い説明で操作・利用イメージもスムーズに湧いて来ました。Visual Editorは現在ベータ版機能のステータスなので、一般公開が待ち遠しいですね!
Discussion