
Dataiku は、企業のデータ活用を推進するための統合型データ分析プラットフォームです。
プログラミング不要の直感的なGUIと、高度なカスタマイズが可能なコードベースの機能を両立し、データ準備、分析、機械学習モデル構築から運用までをワンストップで提供します。チームでのコラボレーションやプロジェクト管理も強力にサポートし、エンジニアだけでなく、ビジネス部門のユーザーも含めた全社的なデータ利活用を実現します。
同じ位置付けの著名なサービスとしては他に Alteryx が挙げられますが、Alteryxでのデータ加工や分析に慣れている方にとって、Dataikuはより包括的で柔軟なデータ分析基盤として存在しています。Dataikuは、ノーコードから本格的なプログラミング分析まで幅広く対応できるため、複雑なワークフローやチームでの協働プロジェクトに最適なサービスです。
当エントリでは、Alteryxユーザーの視点から見たDataikuの特徴や違いを観点・テーマ毎に見ていきます。(違いや特性を把握した上で「AlteryxからDataikuへのワークフロー移行」を見据えて行ければ...という感じです)
はじめに
当エントリではDataikuのアカウントは(まだ)用意せずに、インターネット経由で参照・アクセスできるDataikuギャラリーの内容を観ていくことで進めていきます。Dataikuギャラリーは公開された読み取り専用Dataikuインスタンスです。そのため、通常のインスタンスと比べて一部制限がありますが、開始するために必要なほとんどの機能は備わっていますし、「Dataikuでどんなことが出来るのか」「DataikuのUI・操作感を把握する」のに十分事足ります。
Dataikuギャラリーは下記URLからアクセス可能です。
当エントリではこのギャラリーの中から「Fake Job Postings Quick Start」というDataikuプロジェクトを観ていきながら進めていきます。検索窓から検索してアクセスするか、下記URLから直接アクセスしてください。

DataikuとAlteryxのデータパイプラン
ここからはトピックやテーマ毎に「Dataikuではどういうことが出来るのか」「DataikuとAlteryxではどう考え方やコンセプトが異なるのか」といった部分を見ていきます。
データリネージ
Dataikuのフローは、Alteryxのワークフローと似ている部分があります。
- 左側にデータソースを入力として開始
- 入力データを保持したまま、両プラットフォームはデータ変換のリネージを視覚的に理解する手段を提供
- 最終的に右側に最終出力(アウトプット)を生成
加えて、Dataikuでは独自のビジュアル言語も導入しています。
| 形状 | 項目 | 説明 |
|---|---|---|
| データセット(Dataset) | データセットの保存場所。 例)Amazon S3、Snowflake、PostgreSQLなど |
|
| レシピ(Recipe) | データ変換の種類。 例)Prepareレシピ(ほうきのアイコン)、 Python レシピ(巻き蛇のアイコン)など |
|
| モデルまたはエージェント (Model or Agent) |
モデリングタスクの種類 (予測、クラスタリング、時系列予測など) または エージェントの種類 (視覚的またはコードなど)。 |
上記形状の他にもDataikuのアイコンは"色"にも意味があります。
- データセットについて
- 基本的にはデータセットは青色
- 他のプロジェクトから共有されたものは黒色
- レシピについて
- ビジュアルレシピは黄色
- コードレシピはオレンジ色
- プラグインレシピは赤色
- 機械学習の要素は緑色
- 生成AIの要素はピンク色
前述指定したプロジェクトのフローを全体像で確認してみます。フローの表示は画面上部メニューバーの一番左側にあるアイコン→[Flow]から。

一連の処理が線で結ばれてワークフローを構成し、それぞれの要素の形状や色は意味を成しています。
- 四角形のデータセット(例:job_postings_prepared_joined)が、1つのフローゾーン(データ準備)の終わりと、別のゾーン(機械学習)の始まりに位置している。
- 円の色の違いがレシピの種類(ビジュアル、コード、ML、LLM)を示している
- ダイヤモンドがML(緑)とLLM(ピンク)のモデルを表している
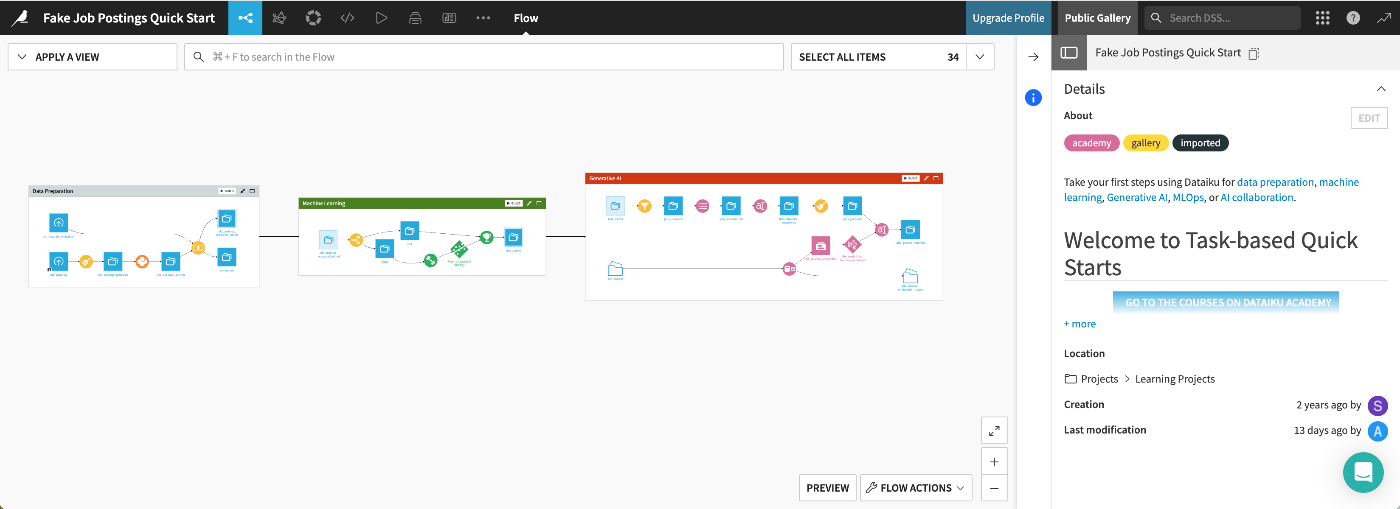
パイプラインナビゲーション
Dataikuの操作は画面要素をクリックすることで進めることができますが、キーボードショートカットにも対応しています。
また、Dataikuのインターフェースに慣れるために下記ドキュメントも合わせてご参照ください。
- Reference | Navigation bar - Dataiku Knowledge Base
- Reference | Right panel navigation - Dataiku Knowledge Base
パイプラインの構成
パイプライン作成の操作については以下のような違いがあります。パイプラインが長くなるにつれて「要素の配置」は大きな負担になる可能性があるのでその点ではDataikuを使うことでその辺りの手間から解放されるメリットはあるでしょう。
- [Alteryx] オブジェクトをキャンバスにドラッグアンドドロップして個人用のパイプラインを作成
- [Dataiku] オブジェクトの配置はFlow内で自動的に決定される
Alteryxでは、ツールをワークフロー内で整理するためにツールコンテナを使用しますが、Dataikuでは、フローを複数のフローゾーンに分割することでフローを整理できます。
デフォルトでは、フローゾーンの位置は自動的に設定されますが手動でのフローゾーンの位置設定を有効化すると、必要に応じてゾーンをドラッグして移動できます。(※ギャラリーの閲覧者としては、この設定を確認することはできません)
今回観ていくワークフローはプロジェクトの主要な段階に対応する3つのゾーン(データ準備、機械学習、生成AI)で構成されており、それぞれに対応する「クイックスタート」で構築されています。

Data Preparationパート

Machine Learningパート
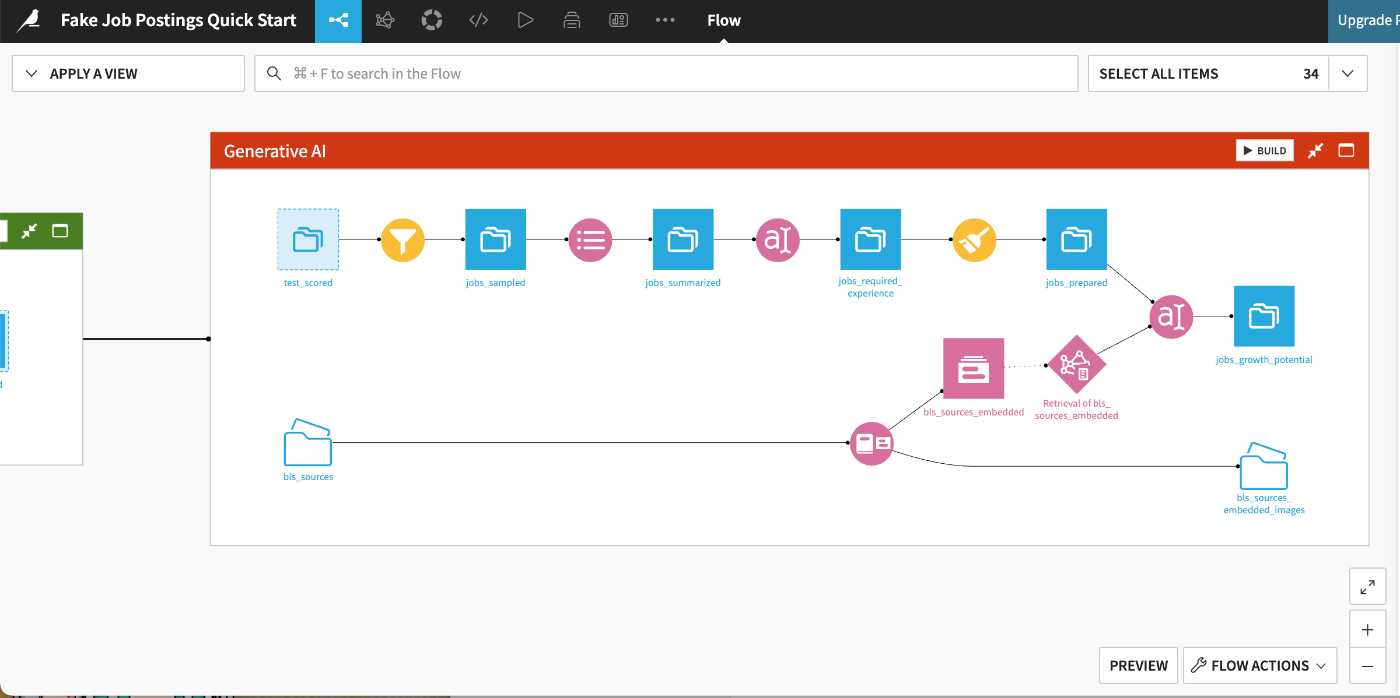
Generative AIパート
データセットの詳細
Dataikuでは特定のデータセットに関する基本情報やメタデータを追跡することができます。この機能はすべてのデータセットに標準で組み込まれています。
データセットを選択し右側のパネルでDetailsアイコンをクリック→説明、タグ、ステータスなどの関連メタデータを確認:

Apply a View メニューを開き、Record Count を選択することで:
各データセットのレコード数が色分け表示される:
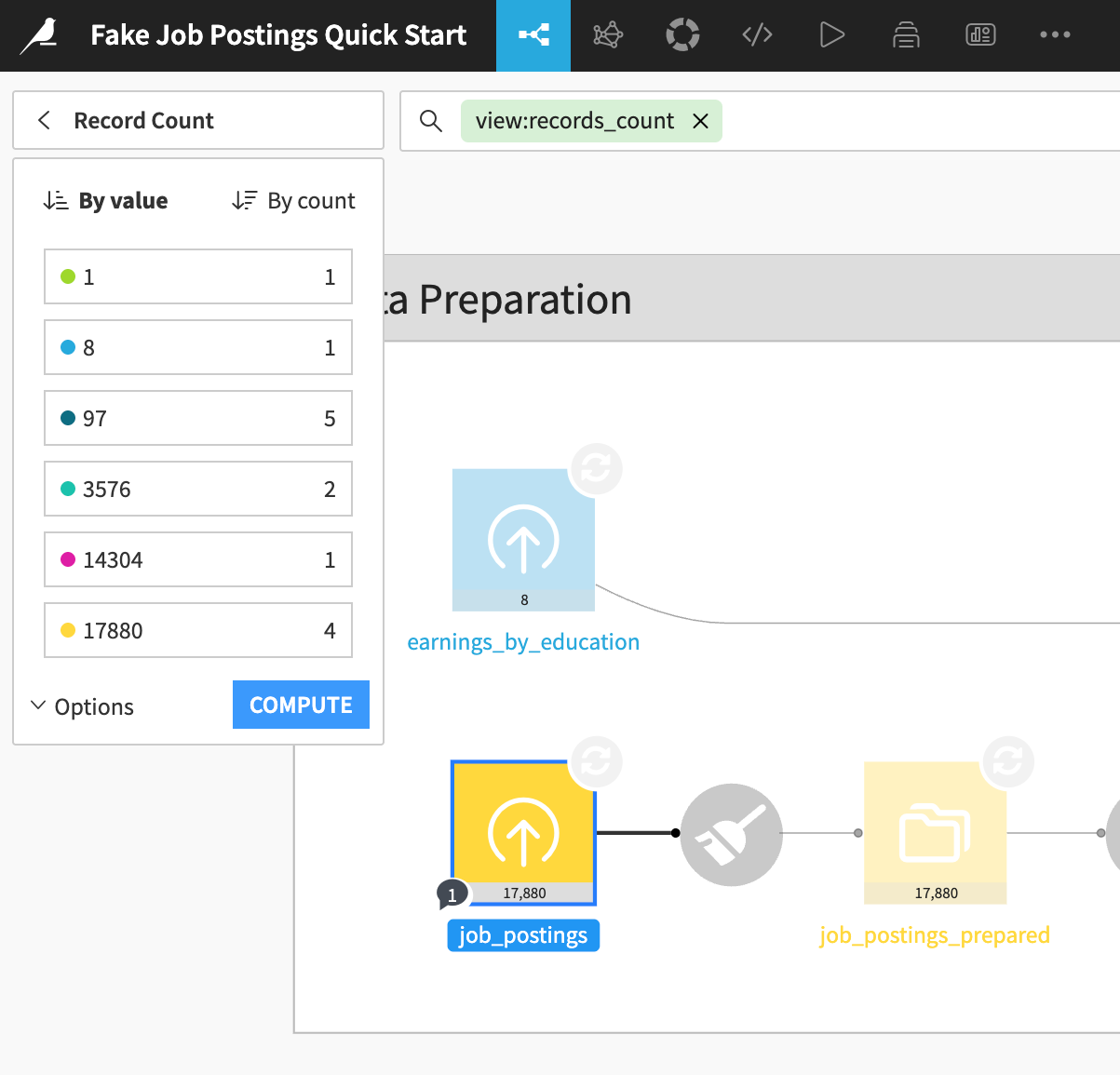
DataikuとAlteryxにおける探索的データ分析(EDA)
データセットのサンプリング
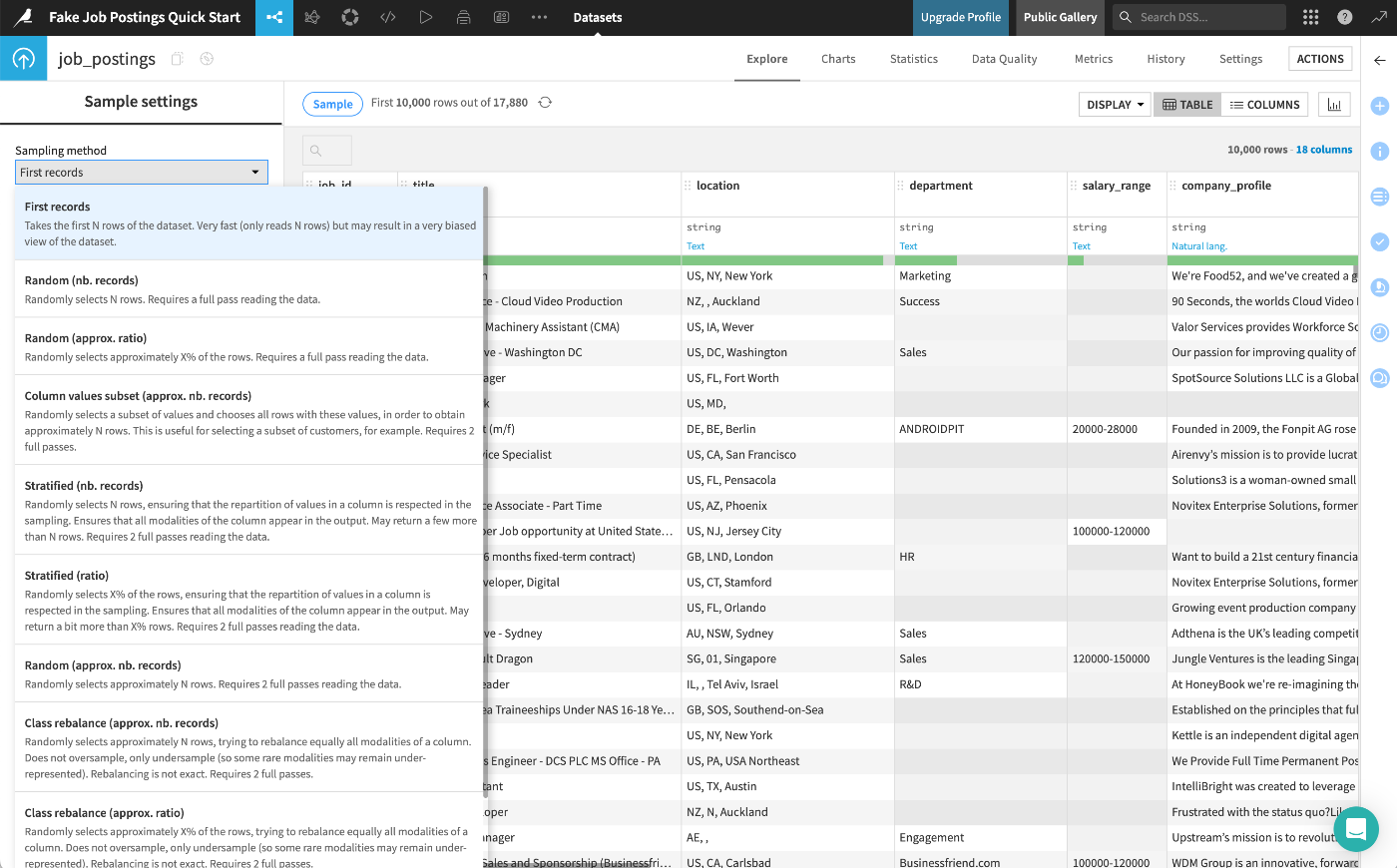
標準ツールを使用してワークフローを実行する際、Alteryxでは接続されたすべてのデータセットをメモリに読み込みます。この動作を回避するため、データストリームのサイズを制限するためにレコード制限を設定し、結果の全体が必要になった際にその制限を解除する可能性があります。
一方Dataikuでは、Flow内のすべてのデータセットにサンプリング機能が組み込まれています。デフォルトでは、Explore タブにはデータセットの最初の10,000行が表示されます。
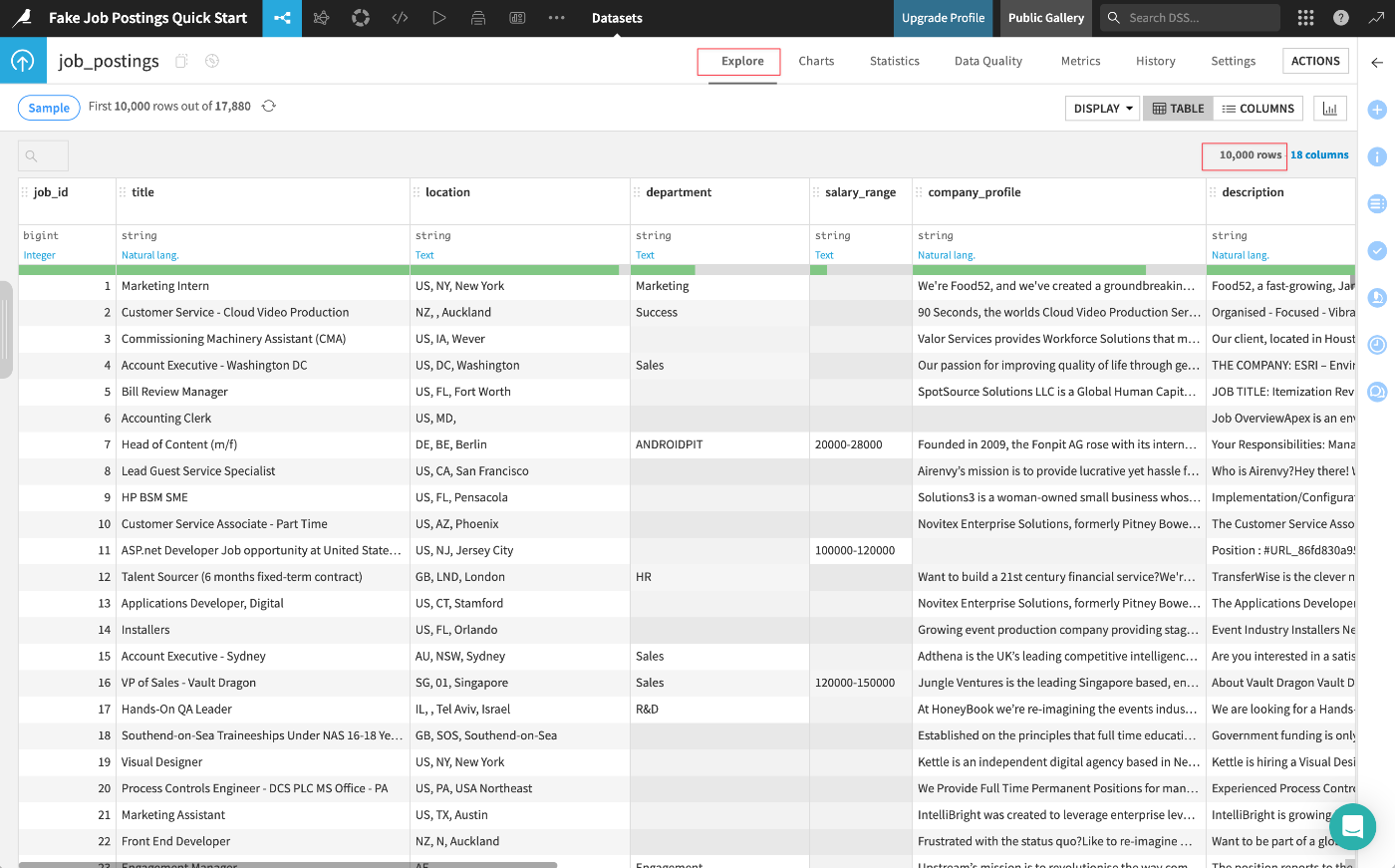
job_postingsデータセットをダブルクリックして、そのExploreタブを開く:

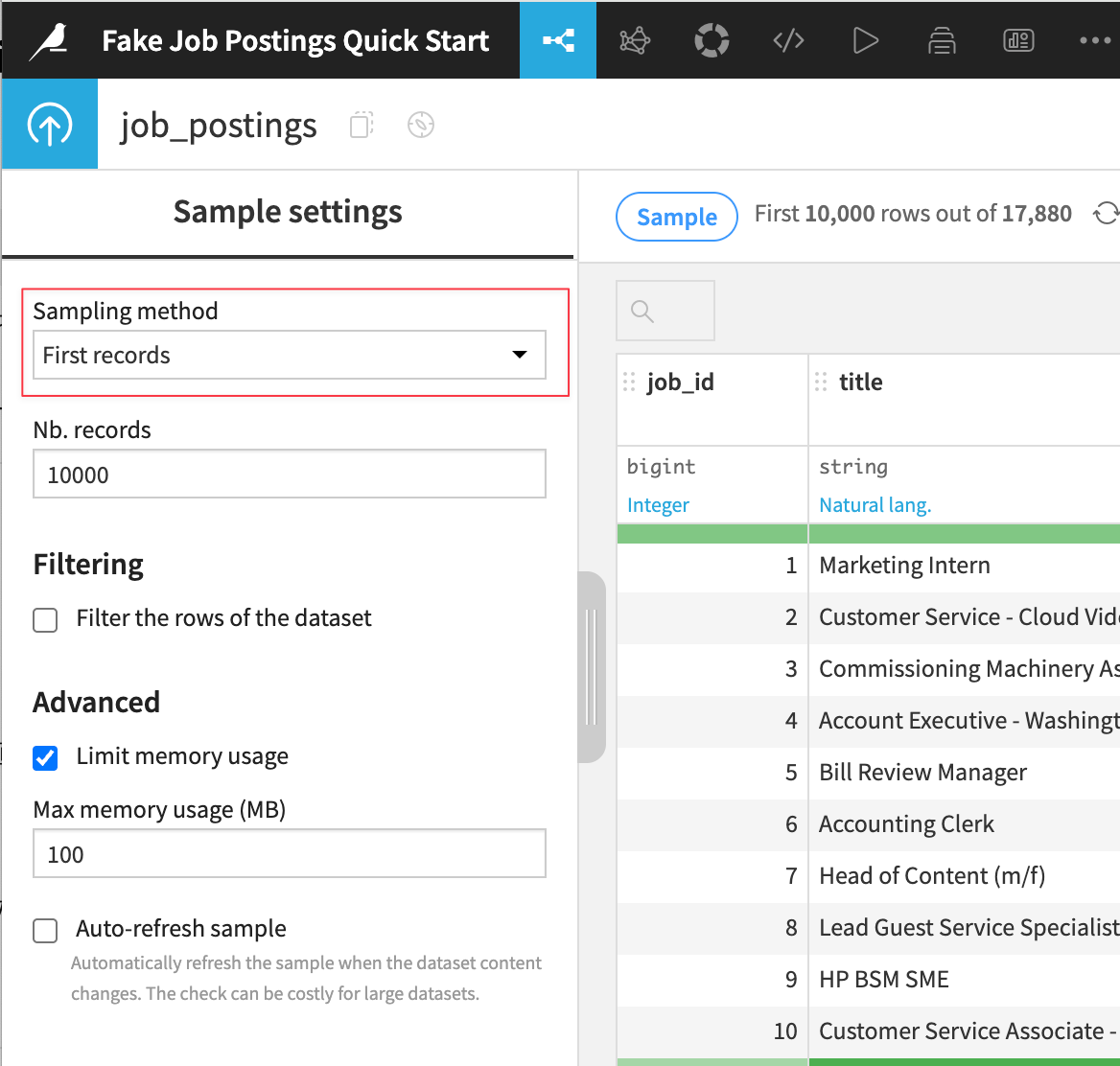
Sampleボタンをクリックして、現在のサンプリング設定を確認:

Sampling methodドロップダウンメニューから他の利用可能な方法を確認可能:
データセットのプロファイリング
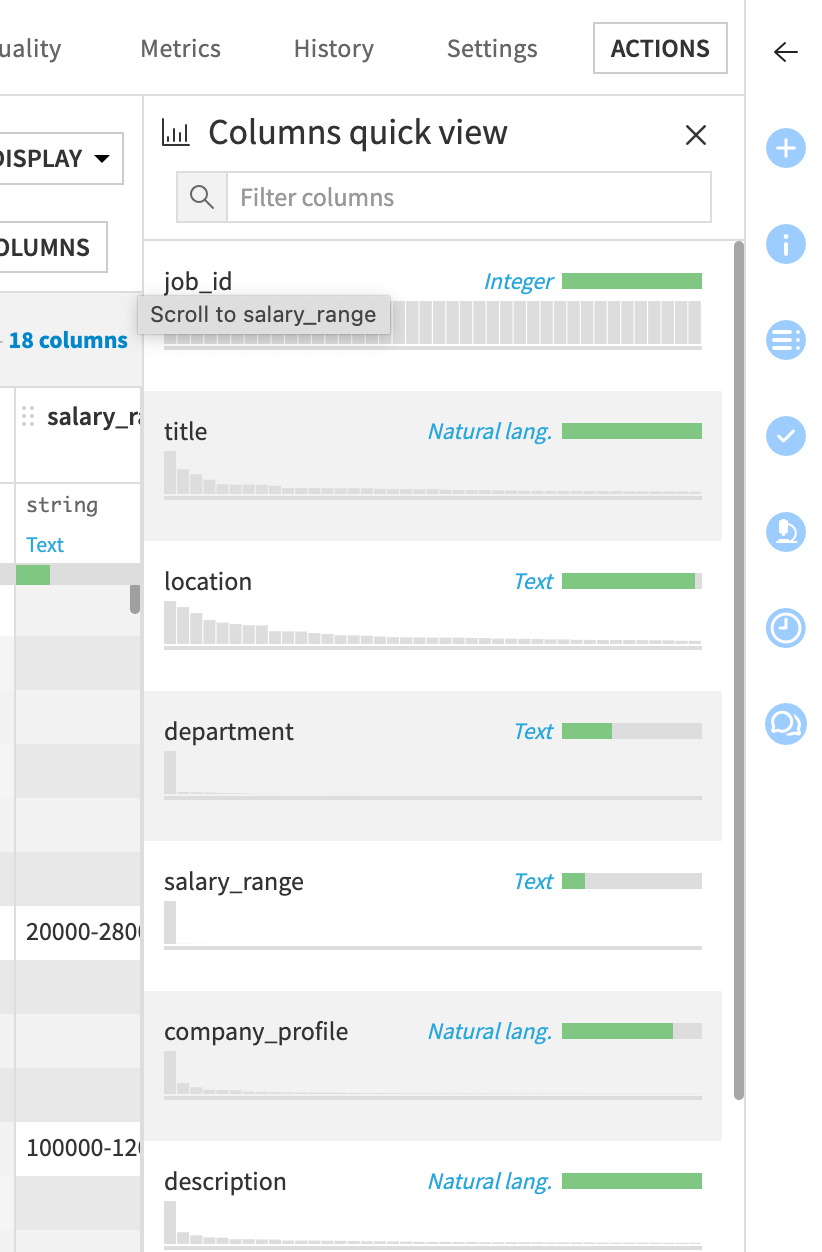
データセットの内容を理解する場合、AlteryxではBrowseツールを追加することがありますが、Dataikuではデフォルトですべてのデータセットからこの種の情報をアクセスできます。これは明示的に指定しない限り、現在のサンプルに基づいて計算されます(最初の10,000行が使用されます)。
データセットの各列の名前の下に、現在のサンプルに基づいて各列の欠損値の割合を示すデータ品質バーが表示される(salary_range などのいくつかの列には多くの欠損値があることがわかる):

Quick column statsアイコンをクリックして、各列の分布を確認可能:

location などの列のヘッダーをクリックし、ドロップダウンメニューから Analyze を選択:

より詳細な統計情報を参照可能:

DataikuとAlteryxにおけるデータ準備
データセット操作
Alteryxでデータパイプラインを構築するには、ツールパレットからツールをキャンバスにドラッグします。Dataikuでは、右側のパネルの「アクション」タブからデータセットにレシピを適用します。

ツールライブラリ
DataikuはPrepare recipeが非常に万能なツールとなっています。結果として視覚的なデータ準備ツールが少なく済んでいます。
データセットの結合
Prepare レシピに加え、Dataikuでは一般的なデータ変換用に多くのビジュアルレシピを提供しています。
例えば、Alteryxでは通常、共通のフィールドに基づいてデータセットを結合するために「Joinツール」を使用しますが、Dataikuでは「Joinレシピ」を使用します。
ワークフロー内のJoinレシピの詳細を表示:
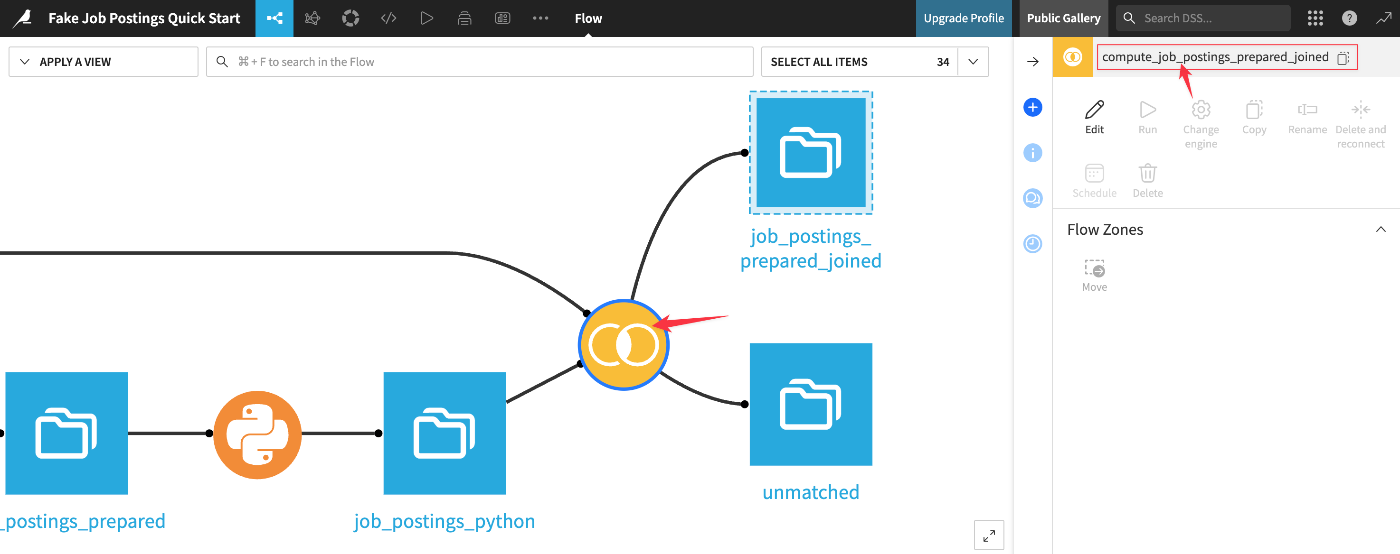
Left joinをクリックして、利用可能な結合の種類を表示。Join操作で一致しなかった行が、unmatchedデータセットに送信されたことを確認出来る:

DataikuとAlteryxのデータ処理
Dataikuの組み込みサンプリング機能は、プロジェクトの設計フェーズでインタラクティブに作業する際の大きな利点です。(フル出力を計算するためにはレシピを実行する必要があります)
計算エンジン
Alteryxは、ローカル処理用の独自のエンジンに加え、データベース内でワークフローを実行できるデータベース内ツールを限定的に提供しています。
一方、Dataikuの計算環境はAlteryxのものとは異なり、クラウドネイティブプラットフォームとして、Dataikuにはリモートサーバー経由で接続します。ITの観点からより安全であるだけでなく、これによりはるかに強力な計算リソースにアクセスでき、大規模なジョブの処理時間を短縮できます。
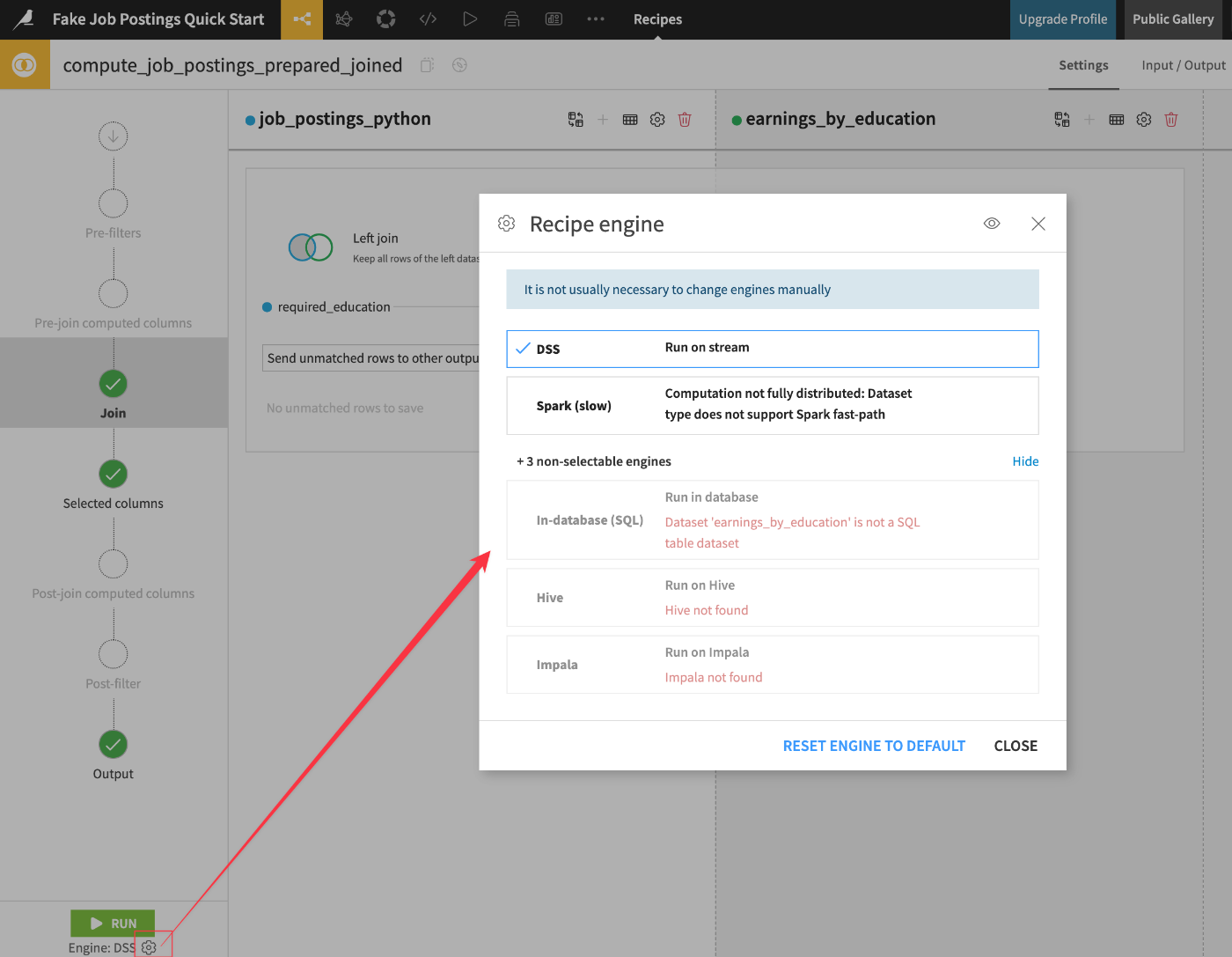
詳細は下記ドキュメント・コンテンツをご参照ください。
データ接続
Dataikuでは、プロジェクトで使用されている接続を一覧表示する便利なフロービューが用意されています。
組織のインフラ投資状況によっては、データは伝統的なリレーショナルデータベースからクラウドデータウェアハウスまで、データエコシステムが移動するあらゆる場所に格納される可能性があります。
ネットワーク経由でデータを転送する代わりに、Dataikuはデータセットの格納場所へのビューを作成します。Flowは、組織の既存のストレージとコンピューティングインフラストラクチャの上に重ねられた視覚的なレイヤーと考えることができます。
データパイプラインの実行
Alteryxでは、プロセスをバイパスする「Detour」ツールや特定のコンテナを無効化する機能を提供していますが、ワークフローの実行方法に関する制御は限定的です。
一方でDataikuはデータパイプラインの実行において、はるかに柔軟なオプションを提供しています。Dataikuではデータセットが「古くなった」状態という概念があります。上流のレシピが変更されると、下流のデータセットは古くなります。Dataikuはフローの依存関係を認識しているため、不要な計算ステップをスキップできます。
次に、Dataikuは上流または下流の参照に基づいてパイプラインまたはパイプラインのセクションを構築できます。今回のプロジェクトでは以下のような処理が考えられます。
- job_postings_prepared データセットのみを、直前の Prepare レシピのみを計算して構築
- Machine Learning フロー ゾーン内の出力のみを構築
- アップストリームの job_postings データセットを選択し、ダウンストリームのすべての出力を構築
- ダウンストリームの test_scored データセットを選択し、最新の出力を取得するために必要なアップストリームの依存関係のみを計算
中間データセット
Dataikuのアーキテクチャの1つの特徴は、フロー内の初期入力(左側)と最終出力(右側)の間にある中間データセットが、主要な懸念事項ではない点です。実際、これらの存在により、フロー内の任意の段階でデータのサンプルを分析するために、アドホックにツールを追加する必要がありません。
中間データセットについて考える際は、以下の点を念頭に置く必要があります。
- サンプルを除き、コンピュータにはローカルにデータが保存されない
- フローのプロトタイピング中は、毎回最初から最後まで全体を構築するのではなく、1つのデータセットまたは1つのゾーンのみを構築する場合がある
- スマートな計算オプションにより、必要ない場合は同じデータを再計算する必要はない
- デスクトップツールを使用していないため、ジョブが実行中でも他のタスクに進むことができる(Dataikuを複数のブラウザタブで開いておくことも可能)
- Dataikuは開発用と本番用の別々の環境を備えており、本番環境に移行する前にフローを効率化するためのリファクタリングが可能
DataikuとAlteryxにおけるオーケストレーションの比較
Alteryxでワークフローを作成した後、次のステップは通常、Alteryx Serverに公開し、そこからスケジュール設定や共有を行うことです。ただし、複数のワークフローをオーケストレーションする(例えば、1つのワークフローが完了した際に別のワークフローをトリガーする)ことは、困難な場合があります。
Dataikuのワークフローオーケストレーションのソリューションは、主に3つのコンポーネントから構成されています:
- アクションを自動化するシナリオ
- データ品質ルール、メトリクス、チェックでデータを検証する機能
- 開発環境外でジョブを実行するためのプロダクション環境
自動化シナリオ
シナリオは、Dataikuでアクションを自動化する方法です。
これらのアクションには、パイプラインの終了時にデータセットを再構築する、モデルを再トレーニングする、ダッシュボードをエクスポートするなどのタスクが含まれます。これらのアクションの実行方法を動的に制御することも可能です。例えば、特定の列の平均値が特定の範囲外の場合、シナリオの実行を停止させることができます。
実行するアクションのセットを定義したら、それらのアクションを実行するトリガーを定義できます。時間ベースのトリガーに加え、データセットの変更時やPythonコードによるトリガーなども定義可能です。また、1つのシナリオの完了が、別のシナリオの開始をトリガーするような連携も可能です。
シナリオにレポーターを添付し、さまざまなメッセージングチャネルを通じてアラートを送信できます。例えば、実行が成功(または失敗)した場合、シナリオは結果(またはエラーメッセージ)をメールで送信する...というようなことも実現可能です。
シナリオ設定は画面上部メニューから遷移可能:

Score Dataシナリオから該当の設定を選択:
Add Trigger をクリックして、シナリオが開始されるタイミングのオプションを表示:

Add Reporter をクリックして、送信可能なアラートの種類を選択:
データ検証
自動スケジュールで実行されているシナリオがある場合、これらのジョブが計画通りに実行されていることを確認するためのツールが必要です。この目的を達成するには、データ品質ルール、メトリクス、およびチェックを使用できます。
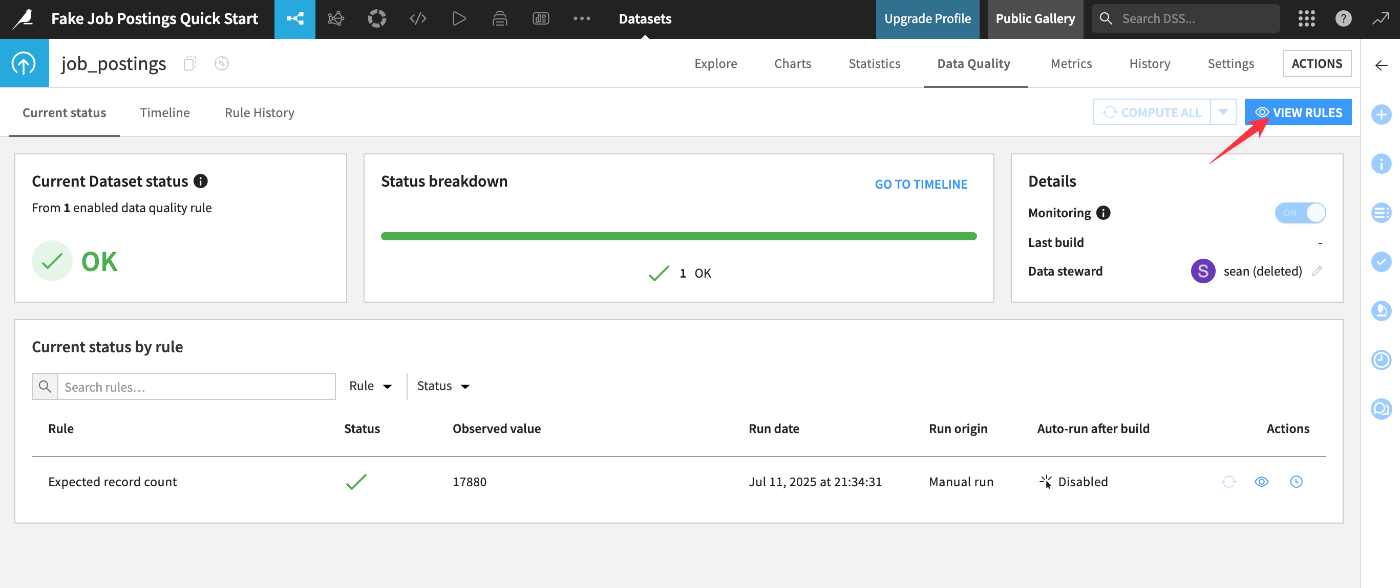
メニュー遷移は画面上部から。プロジェクト内のすべてのルール(エラーや警告を返しているものを含む)の breakdown が表示される:

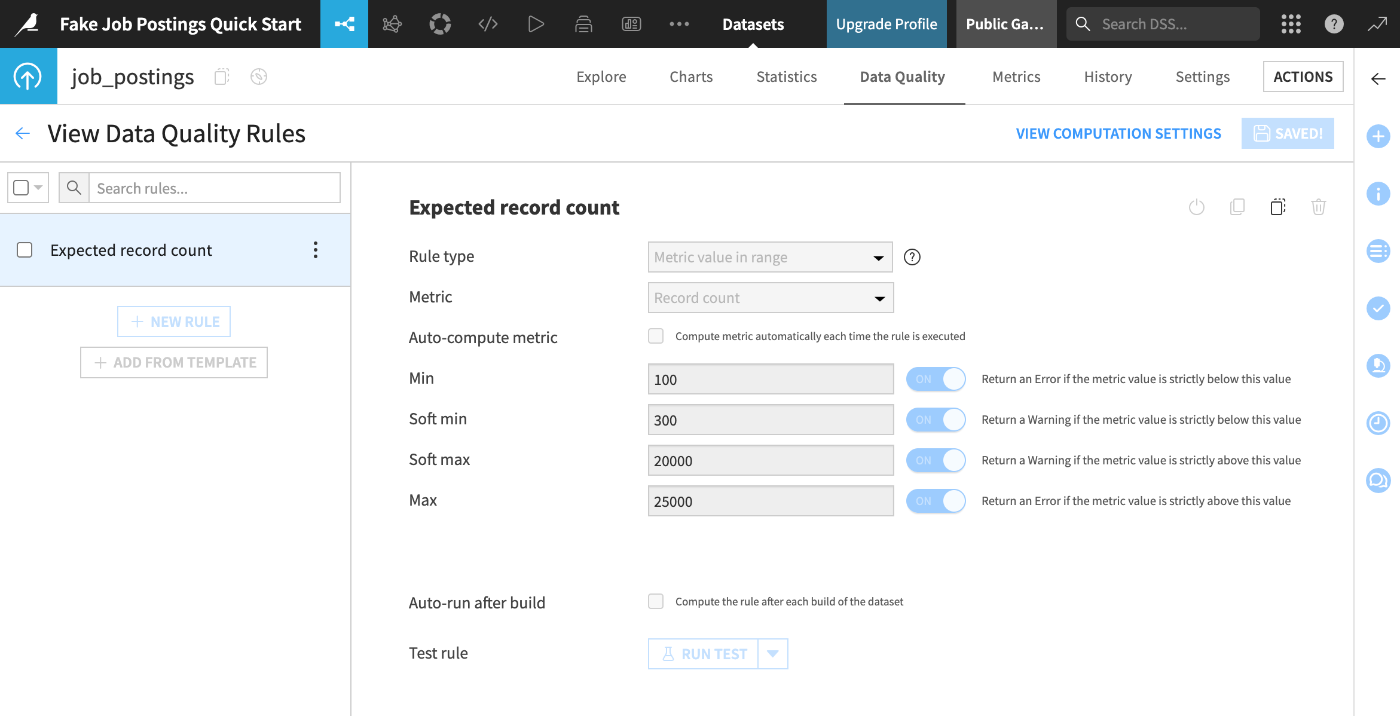
[VIEW RULES]を押下することでデータセットに紐付いたデータ品質ルールが表示される:
本番環境
Dataikuのワークフローオーケストレーションソリューションの最終段階は、Automation node(オートメーションノード:Dataikuのプロジェクトを本番環境で定期的または自動的に実行するための専用サーバーや環境)です。
Alteryx Serverを使用する理由の一つは、ワークフローの計算をデスクトップから外すことです。Dataikuの"シナリオ"は既にリモートで実行されています。ただし、Dataikuプラットフォーム自体は、AIライフサイクルの特定の段階に対応する複数のノードから構成されています。
フローの構築とシナリオの作成が完了したら、次にプロジェクトをAutomationノードにバンドルとして公開します。このタイプのノードに配置されると、シナリオは中断されずに実行されます。
DataikuとAlteryxにおけるコラボレーション
資産の共有
Alteryx Designer では、資産(Asset)をローカルにダウンロードし、出力を手動で同期したり、ファイルをメールで送信して配布する必要があります。
一方、Dataiku では、プロジェクトに加わった変更はページをリフレッシュするだけで変更を確認・共有可能となります。
Dataikuは状況に応じて多様な共有オプションを提供しています。データセットをCSVやExcel形式でエクスポートできますし、「プラグイン」の仕組みを使ってPowerBIやTableauのようなツールと共有することも可能です。
また、作成した資産はダッシュボード、ワークスペース、フィーチャーストア、またはデータコレクションといった形で公開することも可能です。
- Dashboards - Dataiku Knowledge Base
- Workspaces - Dataiku Knowledge Base
- Feature Store - Dataiku Knowledge Base
- Concept | Data Catalog - Dataiku Knowledge Base
変更の追跡
Dataiku プロジェクトには組み込みの Git リポジトリ が用意されています。この Git リポジトリは変更を自動的にコミットするため、プロジェクトを以前の状態に戻すことができます。
セキュリティ
Dataikuにはグループベースの権限管理フレームワーク機能があります。協業や同僚との作業におけるセキュリティ上の課題を解決・カバーリングすることが可能です。
ユーザーは任意の数のグループに所属でき、プロジェクト毎にプロジェクト所有者はグループにさまざまな権限を付与できます。プロジェクトコンテンツの編集、データセットのエクスポート、シナリオの実行などを実現出来るようになります。
AlteryxとDataikuの「コンセプトの比較」
Dataikuのドキュメントでは「Alteryxのこれ、Dataikuではどういう位置づけ、扱いなんだっけ?」というAlteryxユーザーからしてみたらそのものズバリな情報が公開されていました。後学のためにこちらも整理しておきます。
| Alteryx | Dataiku | 説明 |
|---|---|---|
| Workflow & Canvas (ワークフロー・キャンバス) |
Dataiku Project&Flow | 分析アクティビティのすべてのコンポーネント (データ、変換、結果、ドキュメント) を1つのプロジェクトに整理。 プロジェクト内では、Flowのデータセット、 レシピ、モデルといった視覚的な文法を通して、 データが分析パイプラインを どのように移動するかを追跡できる |
| Container tool (コンテナツール) |
Flow zones | 複雑なフローを複数の小さなゾーンに分割し、 大規模なプロジェクトを管理 |
| Browse tool (ブラウザツール) |
Analyze Window | データセットの[Explore]タブで 探索的データ分析(EDA)を実施可能 |
| Sample tool (サンプルツール) |
Sampling on datasets | 必要に応じてデフォルトのサンプリング パラメータを調整し、大規模なデータセットを インタラクティブに操作 |
| Input data tool (入力データツール) |
Data Connections | クラウドストレージ、HDFS、SQL、NoSQL などの さまざまなソースにわたって、一貫した ビジュアルインターフェースを通じて データにアクセス |
| Text input tool (テキスト入力ツール) |
Editable datasets | データセットの行、列、値を直接変更 |
| Comment tool (コメントツール) |
Discussions, descriptions, wikis, etc. | デスクトップ アプリケーションではなく、 ブラウザでのリアルタイムコラボレーションにより、 チームメンバー間で知識を共有し、 新しいユーザーを迅速にオンボーディング |
| Select tool (選択ツール) |
Prepare recipe processors | 列の選択、名前の変更、並べ替えなどの 一般的なデータラングリング操作を実行、 準備レシピのプロセッサライブラリから ステップを追加 |
| Formula tool (数式ツール) |
Formulas | 計算や文字列操作などのために スプレッドシート形式の構文で式を記述 |
| DateTime functions (日時関数) |
Date Management | 日付を解析、日付コンポーネントを抽出、 時間差計算など様々な操作を実行 |
| Join and Append tools (結合・追加ツール) |
Join recipe | SQLを記述せずに、データベース内のさまざまな データセット結合 (左、右、内部、外部、反対、クロス) を 視覚的に実行 |
| Spatial tools (地理関連ツール) |
Geographic processors and recipes | 緯度経度座標からジオポイントを作成等、 様々な地理演算を実行 (※空間結合にはジオ結合レシピを使用) |
| Union tool (結合ツール) |
Stack recipe | SQL UNION ALL と同等のこのビジュアルレシピを 使用して複数のデータセットをさまざまな方法で結合 |
| Score tool (スコアツール) |
Score Recipe | 未知のデータに機械学習モデルを適用して予測を生成 |
| Filter tool (フィルタツール) |
Split recipe | 列値のマッピングやフィルターの定義など、 様々な条件に基づいてデータセットを複数の出力に分割 |
| Results window (結果ウインドウ) |
Data Preparation | Prepareレシピを実行前に、 スクリプトと合わせて結果のサンプルをプレビュー |
| Interactive chart tool (インタラクティブチャートツール) |
Charts | データを様々な種類のグラフにドラッグし データの傾向や関係を視覚化 |
| Render tool (レンダリングツール) |
Dashboards | チャートや主要な指標などの分析情報を ダッシュボードに公開して、ビジネス ユーザーと結果を共有 |
| Assisted Modeling (アシストモデリング) |
Visual ML | AutoML またはエキスパートモードを使用して 予測モデルをすばやく作成・反復処理を実施 |
| Data investigation tools (データ調査ツール) |
Interactive Statistics | 分析ウィンドウを超えてさらに詳しく調べるために データセットの統計タブを参照して、 様々な一般的な統計分析を計算 |
| Schedule Workflows (ワークフローのスケジュール実行) |
Automation Scenarios | 一定期間(毎日)やデータセットが変更された ときなどのトリガーに従って、フローの実行(データセットの構築やモデルのトレーニングなど) を自動化 |
| Analytic Apps (分析アプリ) |
Dataiku Apps | カスタマイズ可能なビジュアルインターフェースの 背後にプロジェクトをパッケージ化することで 消費者が下流のタスクでプロジェクトを独立して 再利用可能に |
| Batch and Iterative macros (バッチ処理・インタラクティブマクロ) |
Dynamic Dataset & Recipe Repeat | データセットの各行を反復処理 データセットとレシピの動的な読み取りと実行 |
まとめ
というわけで、Alteryxユーザー視点で見たDataikuの特徴を、Dataikuギャラリーのコンテンツを使ってダイジェストで見ていきました。Dataikuはデータ分析に関する多種多様な機能や部品を用意提供しており、利用者の技術的習熟度に応じた使い方が出来るプロダクトである、という印象を持ちました。
また、学習習熟のためのコンテンツも非常に豊富でありユーザーに対しても親切なスタンスを保っている印象も合わせて持ちました。Dataikuのざっくり雰囲気を掴んだ感があるので、これを踏まえてDataikuに慣れていき、その先にある「AlteryxワークフローをDataikuに移行」するというステップへの道筋を掴んで行ければと思います。
参考:
